
spends too much time watching football and coding. Prev @Meta, @Microsoft
Joined June 2014
- Tweets 626
- Following 2,682
- Followers 4,255
- Likes 9,754
16 Photos and videos














Elon's material success is quite admirable, however his most impressive trait is his willingness to lose it all.
Not only did he risk his fortune multiple times to start new companies, he was willing to put it all on the line to stand up for the American people against a corrupt political system.
He's an embodiment of the American dream and it's a shame people don't recognize that. America would certainly be a much darker place without him.
3
207
Imagine having the pick of the litter of the best young talent in the world and completely ignoring it
Jun 11

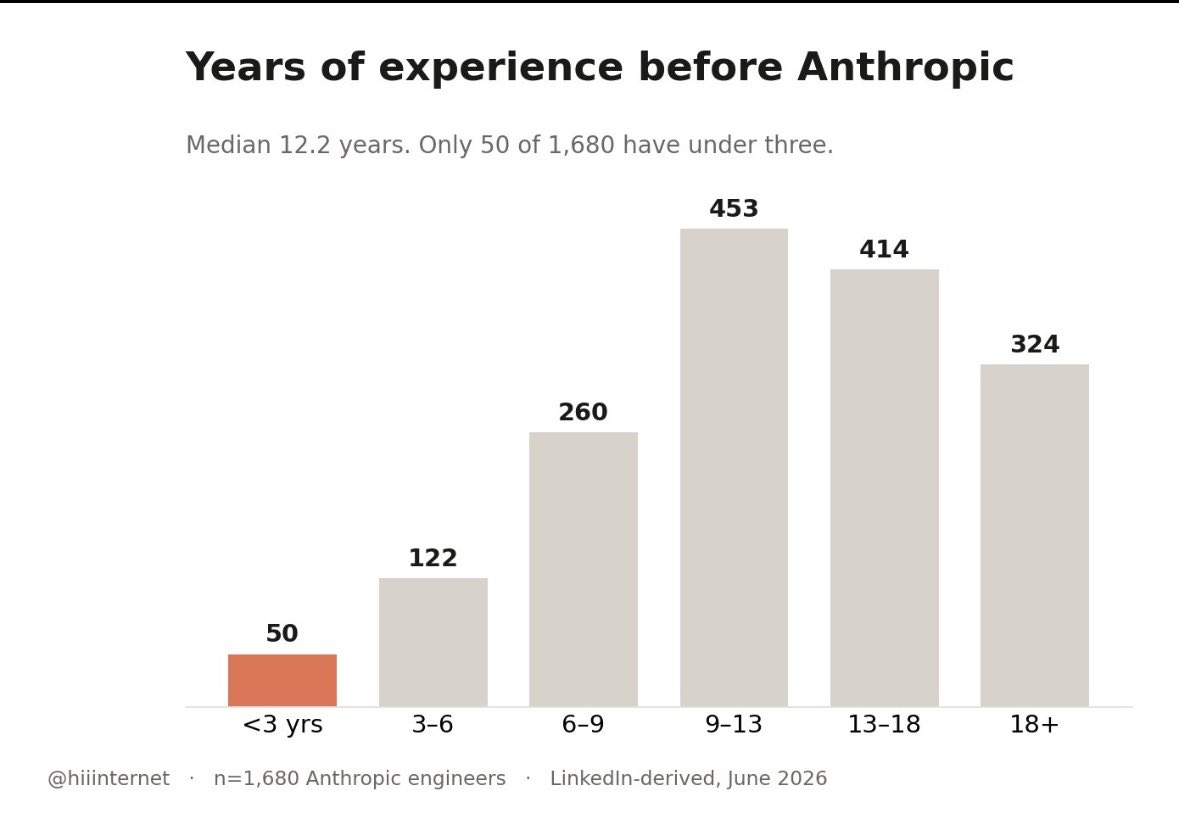
Anthropic almost AVOIDS hiring juniors unless they have a PhD. and only ~13% of their employees have PhD, most have years of careers behind them.
3
1
14
9,389
Resisting the urge to:
> Start AI for Enterprise Co
> Name it Aurelion Labs
> Get two LOIs from my Uncle Larry’s old fraternity brothers
> Raise $50M seed pre-revenue
> Hire an FDE army of recent CS grads who can’t get software engineer jobs
> Have them install OpenClaw to automate email-to-JIRA-ticket workflows
> Add OpenAI and Anthropic logos to our partner wall because we use their models
> Steal an unknown researcher’s paper and release it as a blog from our internal AGI lab
> Sign my Uncle’s friends’ enterprises to 3-year ramp-up contracts with 12-month opt-outs and recognize the terminal year as ARR
> Vaguepost about our success on LinkedIn until we get 5 more ramp-up contracts
> Start having FDEs label their own computer-use data
> Bribe a Hayes Valley realtor for Anthropic and OpenAI researchers’ contacts
> Start selling them our FDEs’ computer-use data to triple revenue
> Raise $100M Series A
> Immediately sell secondaries
> Beg Sam and Dario to acquire the company to “expand their Forward Deployed Operations”
> Get acquired and escape the permanent underclass
Alas, I will resist the urge and remain overseeing my 100 agents that are one loop away from discovering AGI
30
14
395
41,819
Bout to hit my limit in half a task
Jun 9

Alex Heath says Anthropic is planning to release the public version of Mythos tomorrow, June 9th.
5
683
Ben Cohen retweeted

Jun 4
I don’t know if I’ve ever seen somebody get a standing ovation for allowing a run.
Cristopher Sanchez smiles as his streak ends. What a moment for the lefty. He’s in baseball history forever.
66
314
8,172
479,805
This is just an indicator on how much a buisness benefits from AI usage. Any business' threshold for AI spend is a direct indicator on how much their business can grow from increased software velocity. If the software function of your business does not deliver high growth your threshold will be lower

Hearing that T-Mobile attempted to limit its Claude enterprise users to as little as $30 a month from a cap of $2000 a month in tokens, but faced immediate outcry. They are now saying that $2000 is a “temporary” number and that tiered spend caps will be introduced by end of week.
2
1
6
750
Spent some time studying recent RL Environment research and did my best to summarize it. Hopefully this helps you understand how environments work and where the research is headed
references great work from @PrimeIntellect @trychroma and more all linked inside
3
1,527
Spent some time studying recent RL Environment research and did my best to summarize it. Hopefully this helps you understand how environments work and where the research is headed

1
947
I’ve decided to leave @AnthropicAI
Never thought I’d say this so soon. The pursuit of AGI has truly been my life’s work but something more important has emerged.
In 1942, hundreds of America’s best scientists made huge sacrifices and joined the Manhattan Project to protect this nation against immense evil.
Today, America faces a similar danger. Over the last few years sparks of AGI have been felt across the world.
In order to protect this great nation against the threat of AGI ending up in the hands of evil, I have decided to join the modern day Manhattan Project.
I’m excited to announce that I’ll be joining (and moving into the office) @UseCorgi as a sales development representative!
753
334
9,616
2,429,652
BREAKING NEWS: People want to make alot of money
May 28

Fascinating results
Anthropic running away with it right now
So many people want to start their own company
Google over OpenAI
Vercel, Linear, Every, PostHog overperforming
A great list if you're trying to figure out where to go work 👇
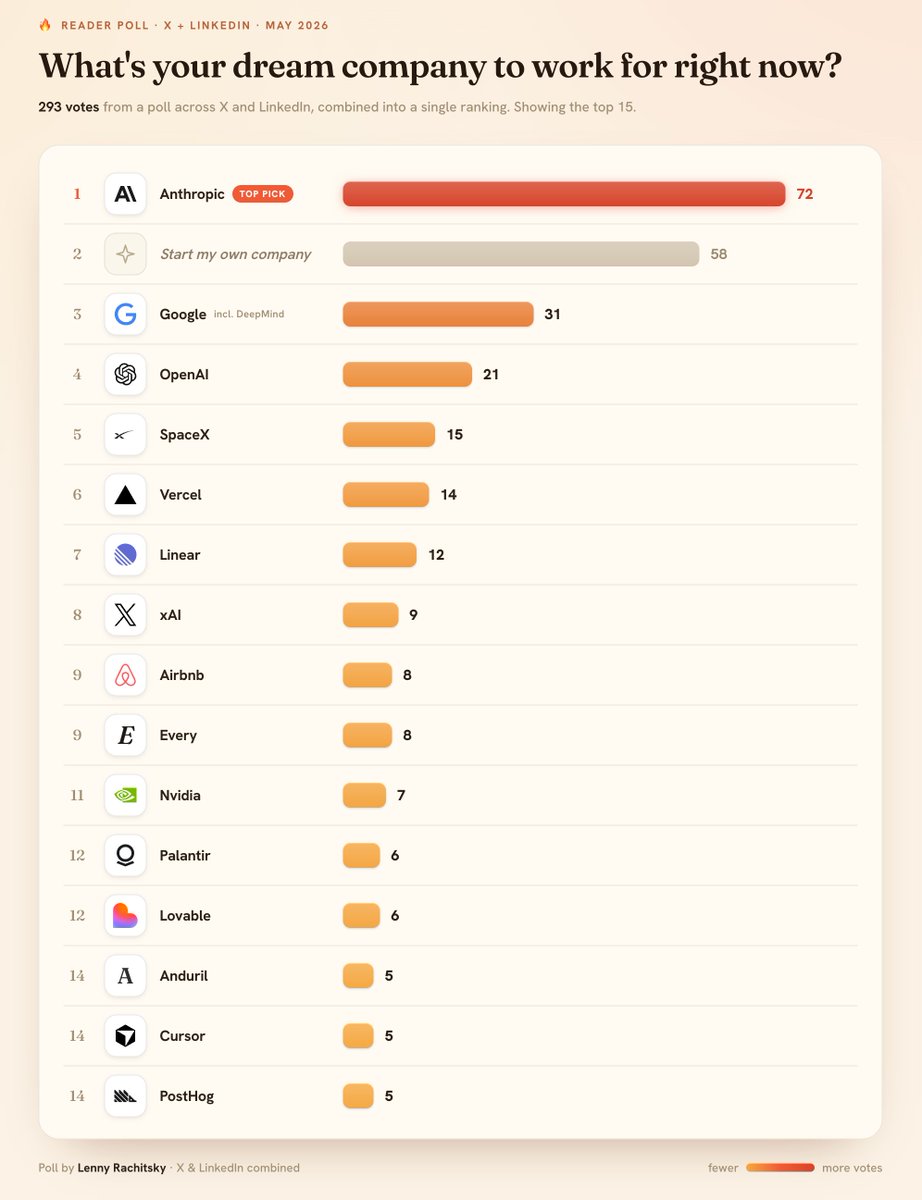
3
1
58
124,021
Genuine question here, not trying to hate.
Insurance seems like a risky product to scale exponentially and scale faster than any company in history right?
Doesn’t it take time to prove out new insurance products? Are you just outcompeting on distribution and writing proven policies faster than competitors?
May 28

We raised another $106M at a $2.6B valuation since announcing our last round three weeks ago.
Corgi has grown exponentially in the past couple of months, but we're only just getting started transforming one of the largest sectors in the US economy: insurance.
4
20
34,694
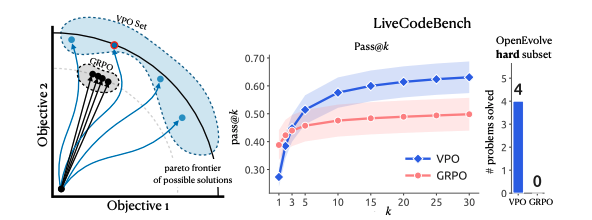
If you thought MIT wasn't going to drop another banger RL method this week, you were wrong.
They just released Vector Policy Optimization.
Most RL methods focus on single answer generation. VPO focuses on candidate set generation for search instead.
The model is trained to produce a batch of candidates in a single rollout separated by a delimiter. This allows the model to reason across answers within a single rollout and create diversity within a candidate set.
Think about kernel optimization.
If you ask a model for 16 possible CUDA kernels, you want real variation. Some candidates should try different tiling choices. Some should use memory differently. Some should make different tradeoffs around speed, stability, or which tensor shapes they handle well.
You want to explore the full design space instead of exploring only around a local maximum. Generating one candidate per rollout and depending on stochastic variation often leads to similar results across rollouts.
VPO argues that the RL phase should explore the search space by producing candidates with different strengths. The test-time search loop can then exploit the promising regions with benchmarks, verifiers, or evolutionary search.
VPO does this with two changes.
First, the model generates multiple candidates in one rollout, so later candidates can see earlier ones and avoid repeating the same idea.
Second, it uses reward vectors instead of a single scalar reward.
For code, the reward vector might include tests passed, speed on different input sizes, memory use, numerical stability, and hardware compatibility.
Instead of picking one fixed weighting of those signals, VPO samples many weightings. One weighting may care mostly about speed. Another may care more about memory. Another may favor stability or an edge case.
For each weighting, VPO asks which candidate in the set wins.
The set gets rewarded when it contains winners across many different weightings, which they call reward-space diversity. The model is trained to keep multiple useful directions alive, so search has something to work with later.
The ablations are important here too.
Multi-candidate rollout by itself is not enough. If you still train the set with one scalar reward, the candidates can collapse into similar answers.
Random reward weightings by themselves are not enough either. If the model still emits one answer at a time, you are changing the target but not training a useful candidate set.
VPO needs both: generate a set, then reward the set for covering different parts of the reward space.
That also explains why it helps less when rewards are colinear.
If one kernel is best on correctness, speed, memory, and stability, every weighting picks the same winner. Diversity does not buy much.
But hard search problems usually have tradeoffs. The fastest kernel may be brittle. The robust one may be slower. The version that works best on small inputs may lose on large inputs. The weird candidate may be bad now but contain the mutation path that wins later.
Search only works if the generator gives it somewhere to search.
There are many interesting areas you could apply this like model training, agent planning, auto-research, and code search. VPO is promising for any problem where the design space is large and has many different tradeoffs.
Paper in the comments
1
21
11,887
Paper: arxiv.org/abs/2605.22817
Follow @RyanBoldi
1
6
8,752
Sf people make up the wildest shit to justify living in SF over nyc
May 25

I am glad that I don't live in new york - not that I hate any parts of it. On the contrary the absence makes many parts of the city stir stronger memories when I revisit them... forgetting and then rediscovering things in such a great city quite a unique experience
1
8
11,077