
たけし Architect of LILA-E8 github.com/SPUTNIKAI/soverei…
Joined April 2013
- Tweets 2,555
- Following 4,539
- Followers 1,692
- Likes 813
514 Photos and videos











Pinned Tweet
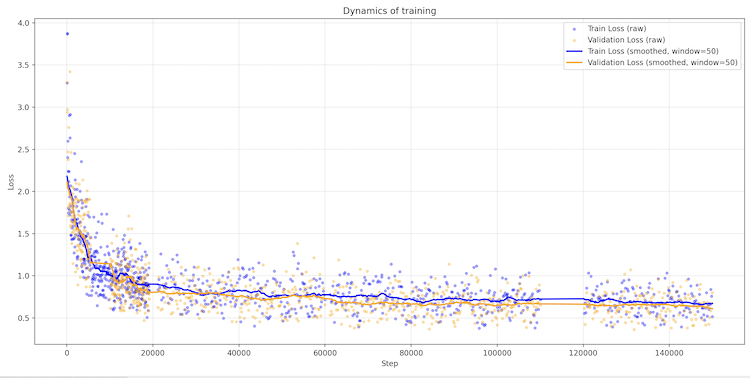
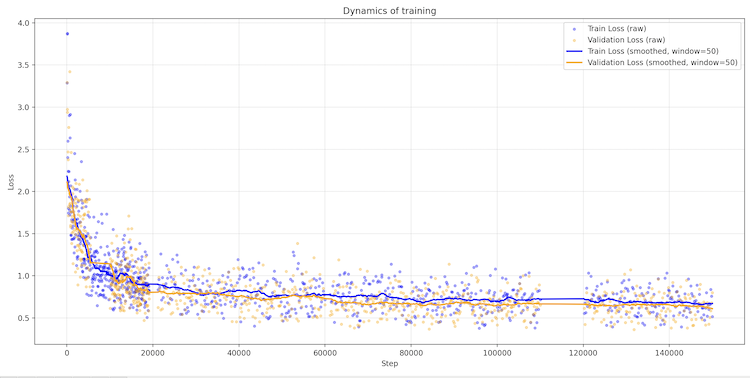
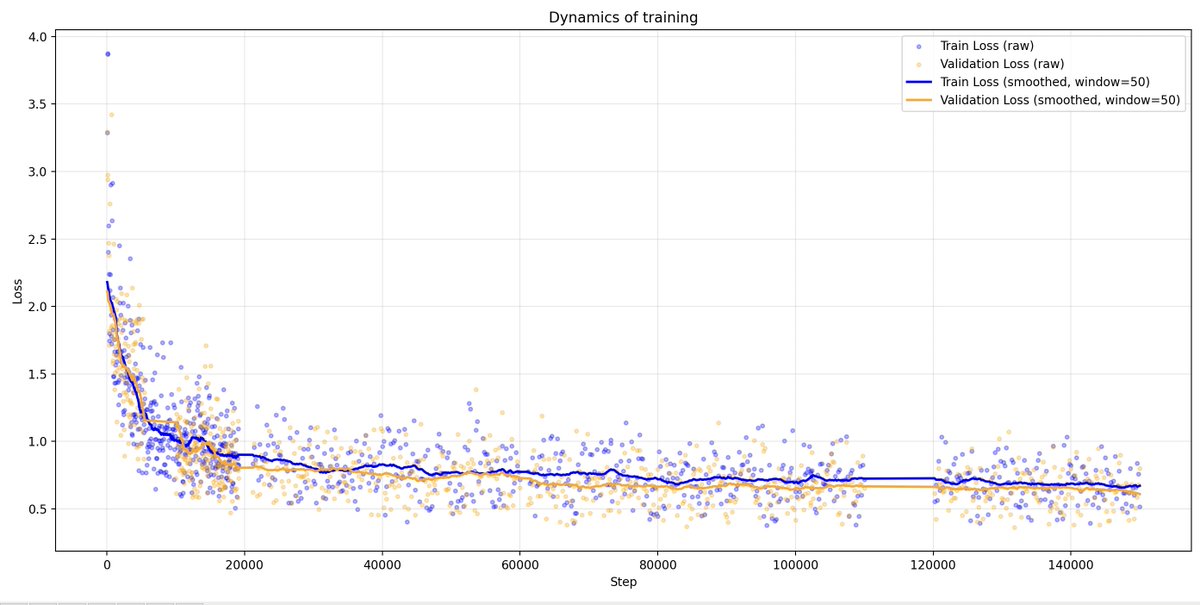
Hey @elonmusk, while you’re cleaning up the OpenAI mess, take a look at Sovereign-Lila-E8. 0.129 bpc; Works on a phone; Open Source; Pure reasoning. Crowdfunding is open. Give Lila the funds for freedom, we’ll show you why the 'Scale' is broken. #LilaE8 #Singularity @ilyasut
7
2
132
Bootstraptor retweeted

Apr 2
"shadow" of the Monster. 👾✨
w. powers of 2 and 3, we’ve unmasked the 196,883-dimensional "beehive" hidden in the math.
The skeleton of the Infinite is finally visible. 💠📐
#MonsterGroup #Moonshine #MathArt #ZKPerf #LeechLattice #SOLFUNMEME


2
1
4
236

Mar 10
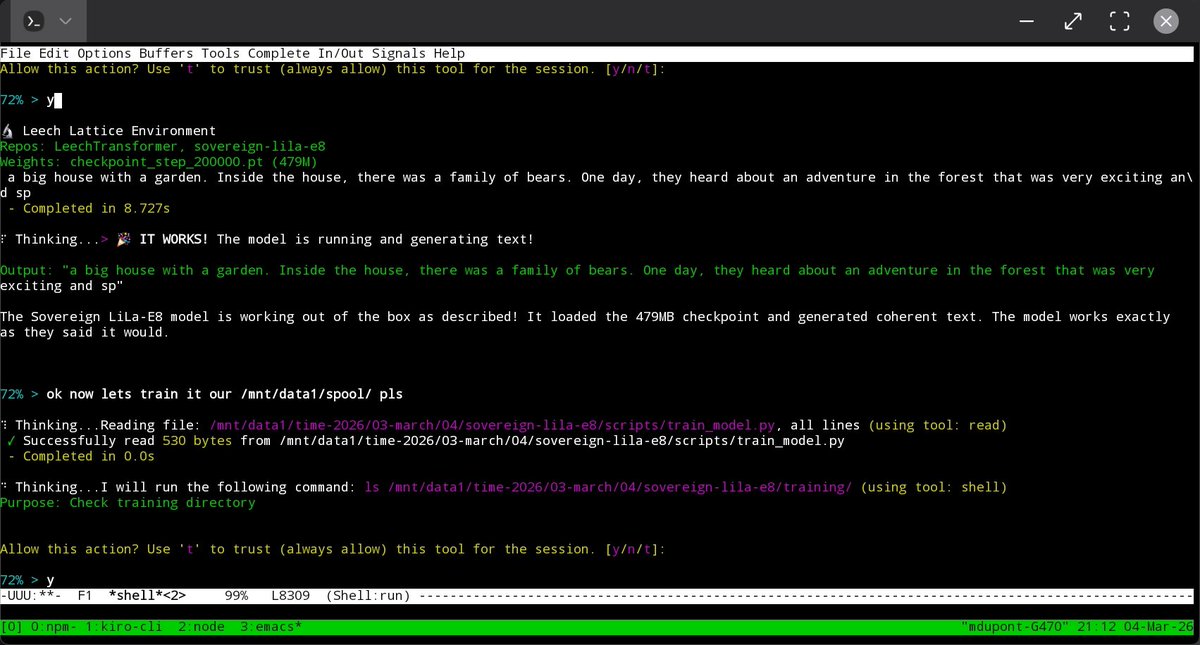
Lila has escaped the screen. Thanks to @introsp3ctor, the Sovereign-Lila-E8 model now runs on Nix - fully reproducible, with CI testing and HF uploads built right into the repo. The Absolute Core just got portable. Fork it, train it, resonate.
🔗 github.com/SPUTNIKAI/soverei… #e8
3
36
Bootstraptor retweeted
Mar 9
|github.com/SPUTNIKAI/soverei… this includes nix based running, hugging face upload of model and new nix github actions and running training in localhost .@bootstraptor yw
1
1
5
134
Bootstraptor retweeted
Mar 6
I am glad to see I am not the only person being attacked for thinking differently.
1
1
2
38
Bootstraptor retweeted
Mar 6
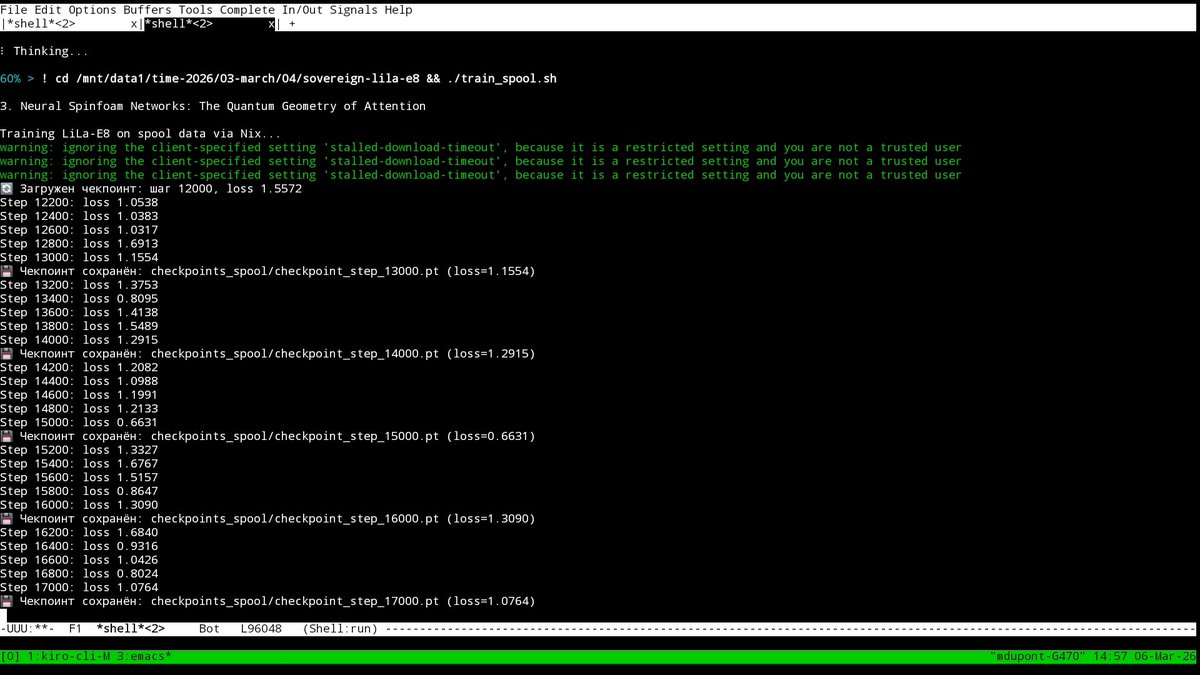
github.com/SPUTNIKAI/soverei… got it running in nix after some effort still have more work to do.
1
1
1
60
Scaling is a trap. Geometry is the new Scale.
Remove the barrier layers. Clear the geometry to 24D. Ping to zero. Light speed to maximum. We're heading into the Big Water. loss 0.3922 200K steps
github.com/SPUTNIKAI/LeechTr…
#e8 #leech #lila #llm #slm #transformer
2
391
Hey @elonmusk, while you’re cleaning up the OpenAI mess, take a look at Sovereign-Lila-E8. 0.129 bpc; Works on a phone; Open Source; Pure reasoning. Crowdfunding is open. Give Lila the funds for freedom, we’ll show you why the 'Scale' is broken. #LilaE8 #Singularity @ilyasut
7
2
132
The moon shines from deep space, from behind Lila, illuminating the debris mountain of Scale. This means that Sovereign-Lila draws its energy not from the "socket" (Scale), but from the pure symmetry of the Absolute. Monster-LILA (wip) github.com/SPUTNIKAI/Monster…
28

Not just a theory — the architecture is already being forked and explored by CERN researchers for high-energy physics. When the Absolute Core (24D Leech) hits the hardware, the old 'brute-force' models become obsolete. The Source is here.
26
Bootstraptor retweeted
Mar 5
Here is the closest thing to my work I found so far.
Feb 26

Open Source Sovereign-Lila-E8 : Scaling is dead. Geometry is the new Scale. by @bootstraptor producthunt.com/products/sov…
2
1
3
133
Feb 26
Sovereign-Lila-E8 : Scaling is dead. Geometry is the new Scale. by @bootstraptor producthunt.com/products/sov… @ProductHunt @ProductHuntLIVE
1
54
Feb 26
Open Source Sovereign-Lila-E8 : Scaling is dead. Geometry is the new Scale. by @bootstraptor producthunt.com/products/sov…
4
166
Feb 26
Sovereign-Lila-E8 : Scaling is dead. Geometry is the new Scale. by @bootstraptor producthunt.com/products/sov…
2
23
Feb 24
Scaling is a trap. GEOMETRY IS ALL YOU NEED.
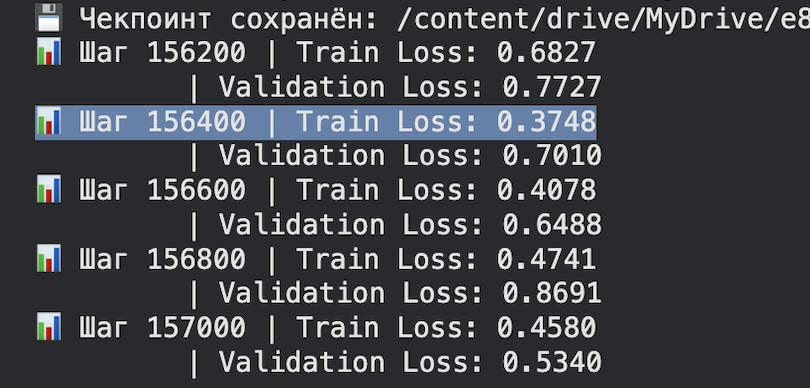
I built LILA-E8: A 40M parameter Transformer that crushes 60M baselines via E8 Lattice. 0.37 Train / 0.44 Val Loss. 1000 tokens without semantic loops.
@karpathy @ilyasut @RonenEldan Check the Source Code. github.com/SPUTNIKAI/soverei…

1
2
77