
Joined September 2022
- Tweets 44
- Following 195
- Followers 70
- Likes 50
6 Photos and videos




Pinned Tweet

6 Jun 2025
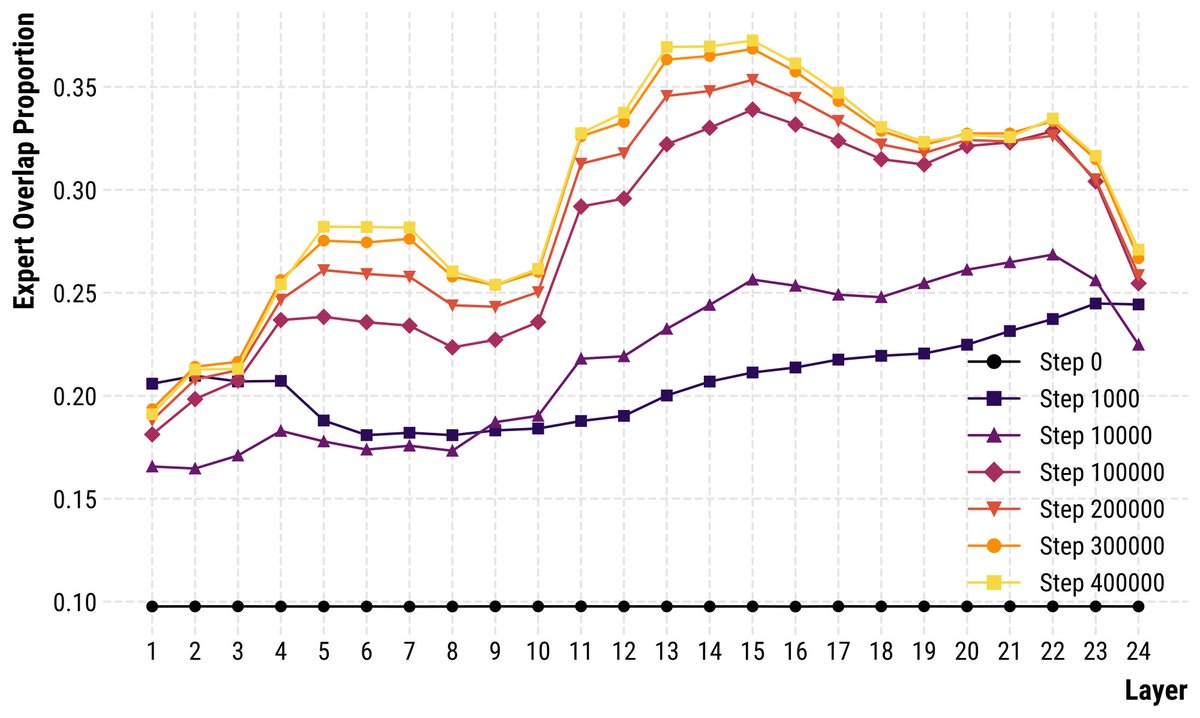
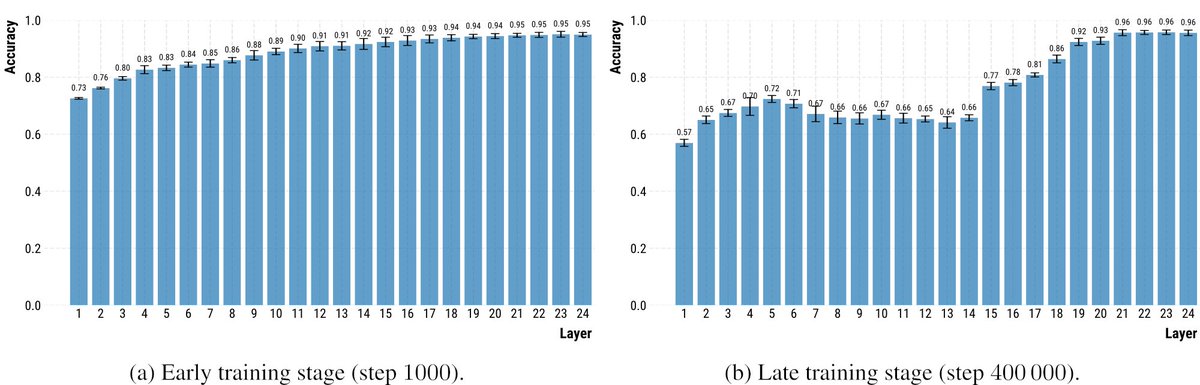
How and when do multilingual LMs achieve cross-lingual generalization during pre-training? And why do later, supposedly more advanced checkpoints, lose some language identification abilities in the process? Our #ACL2025 paper investigates.
1
4
8
2,200
"How deep is your love? Like the ocean?"
Looking out at the Balearic Sea got me thinking about ancient feelings. Just how deep *did* the Romans and Greeks love?
Come find out at the first poster session of @LREC2026!
📍 Poster 1196
🕐 11:20 - 13:00
ALT A photo of me smiling broadly at the camera. I am standing on a sandy beach, and right behind me are the beautiful blue waves of the Balearic Sea stretching out to the horizon under a bright, sunny sky.
2
5
137
Frederick Riemenschneider retweeted

14 Sep 2025
The world’s largest NLP conference with almost 2,000 papers presented, ACL 2025 just took place in Vienna! 🎓✨Here is a quick snapshot of the event via a short interview with one of the authors whose work caught my attention.
🎥 Watch: youtu.be/GBISWggsQOA
#acl2025NLP #acl2025

1
4
13
1,046
14 Sep 2025
ACL paper: aclanthology.org/2023.acl-lo…
Models: github.com/Heidelberg-NLP/an…
Read more: cl.uni-heidelberg.de/nlpgrou…
Morphological Analysis Demo: huggingface.co/spaces/bowphs…
Machine Translation Demo: huggingface.co/spaces/bowphs…
Best Thesis Award: gscl.org/en/activities/stude…
1
121
27 Jul 2025
Looking at Bruegel's Tower of Babel in Vienna makes you wonder: How can multilingual language models overcome the language barriers? Find out tomorrow!
📍 Level 1 (ironic, right?), Room 1.15-1
🕐 2 PM
#ACL2025NLP
6 Jun 2025

How and when do multilingual LMs achieve cross-lingual generalization during pre-training? And why do later, supposedly more advanced checkpoints, lose some language identification abilities in the process? Our #ACL2025 paper investigates.
3
13
1,647
Frederick Riemenschneider retweeted
6 Jun 2025
How and when do multilingual LMs achieve cross-lingual generalization during pre-training? And why do later, supposedly more advanced checkpoints, lose some language identification abilities in the process? Our #ACL2025 paper investigates.
1
4
8
2,200
6 Jun 2025
How and when do multilingual LMs achieve cross-lingual generalization during pre-training? And why do later, supposedly more advanced checkpoints, lose some language identification abilities in the process? Our #ACL2025 paper investigates.
1
4
8
2,200
6 Jun 2025
This phenomenon has a visible effect on text generation: In BLOOM-560m, activating 'earthquake' neurons derived from Spanish data at checkpoint 10,000 generates Spanish text. At checkpoint 400,000, the same method yields English text!
1
3
118
6 Jun 2025
Read the full paper here: arxiv.org/pdf/2506.01629
Reach out if you have any questions or if you are attending ACL and want to say hi. 🙋
1
5
93
1 May 2025
What did Aristotle actually write? We think we know, but reality is messy. As Ancient Greek texts traveled through history, they were copied and recopied countless times, accumulating subtle errors with each generation. Our new #NAACL2025 findings paper tackles this challenge.
1
2
7
569
1 May 2025
Our work brings new computational methods to a field traditionally dominated by manual scholarship, potentially accelerating the discovery of textual errors that have remained hidden for centuries.
1
2
51
1 May 2025
Read the full paper: aclanthology.org/2025.findin…
Work by @crestonbrooks, Johannes Haubold, Charlie Cowen-Breen, Jay White, Desmond DeVaul, me, Karthik Narasimhan, and Barbara Graziosi
4
74
1 Nov 2024
When I started my Bachelor in Classical Philology and Computational Linguistics in 2018, I had no idea where it would lead. I'm excited to now be giving my first invited talk at the Computational Approaches to Ancient Greek and Latin Workshop!
1
1
7
792
1 Nov 2024
If you're interested in computational approaches to Ancient Greek and Latin, there's still time to register for the workshop. It's a hybrid event, so you can join us in person or participate online. Hope to see you there!
1
2
69