Joined March 2026
- Tweets 371
- Following 20
- Followers 29
- Likes 61
111 Photos and videos









Pinned Tweet

Apr 23
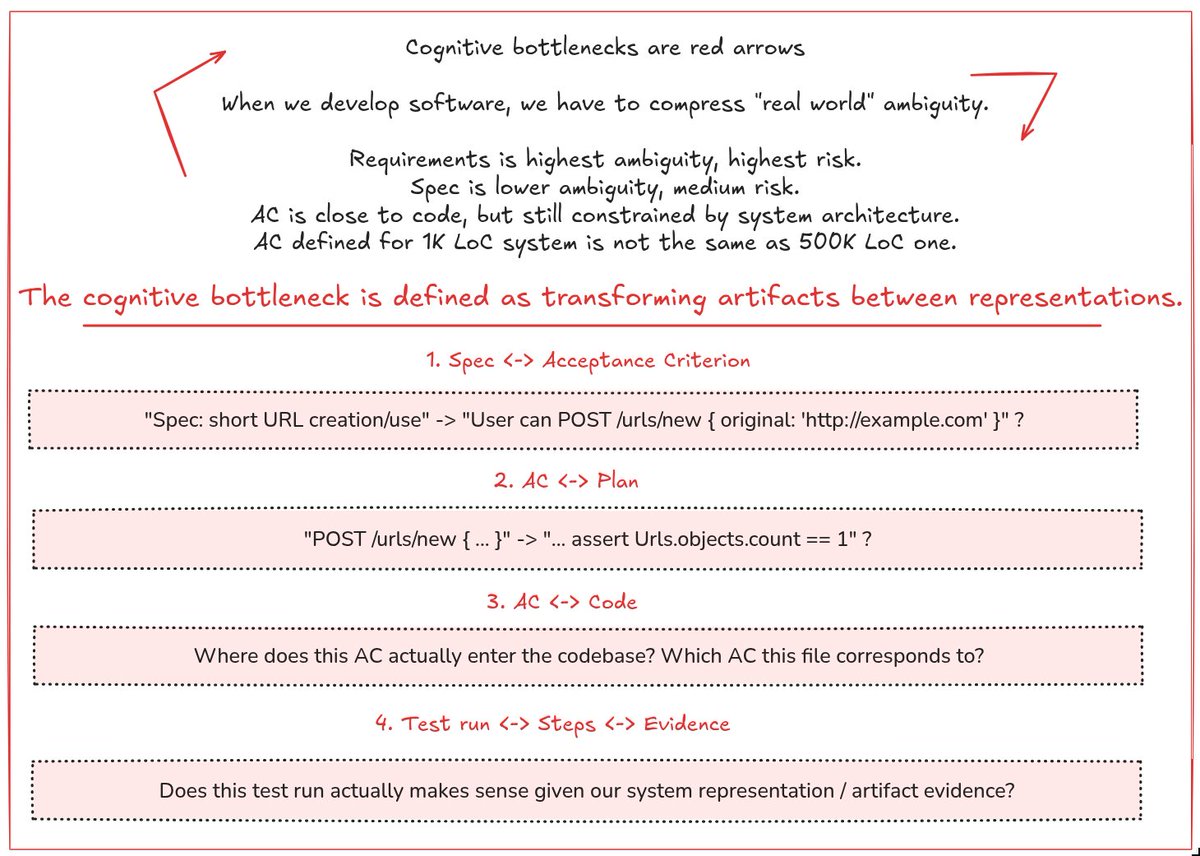
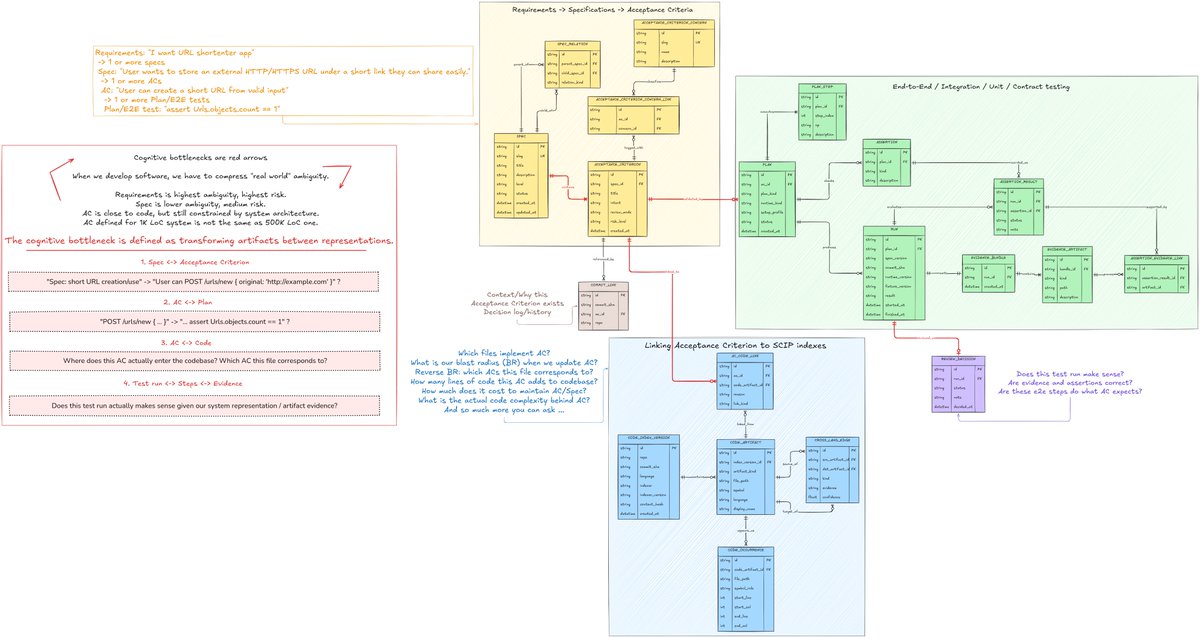
Visualizing "cognitive debt" in Software Engineering.
Or simply:
> "Where does the code review bottleneck actually lives?"
Link: lnkd.in/dBej52xy
This is my mental model on what exactly is happening inside of a brain during problem-solving process. All of that has to be loaded into working memory.
When you look at function definition, a class, an interface, an API call, a log statement, a failing metric in Grafana, RFC on how exactly Browser Clipboard API works, and so on. This — is exactly the "hidden cost of engineering" that I haven't seen anybody would visualize.
And I just did it 🤷
So why we cannot simply accept code written from LLMs / other engineers? Why we need code review?
Some people suggest this is trust problem:
> "We cannot trust LLM/human/third party to transition requirements into spec, or spec into acceptance criterion, or suggest code edits, unless we are confident in their abilities."
My ERD diagram says: "you have to validate that Spec contains these ACs", or "does this AC link to this file in codebase?", or "does this e2e test evidence (assertions, artifacts) actually verifies AC is implemented?"
If you can do it for 100k LoC system, without looking once into Jira/Confluence/Slack/git blame — I envy you. This means all of those decisions, all of those tiny spec artifacts somehow live, efficiently compressed, in your memory.
But I cannot do this. Never I was able to. And all the systems that were built previously, they don't help me with cognitive bottlenecks as much as I'd like to. We have git blame, we have Jira, we have CI/CD, we have observability, documentation systems. But none of it is coherent. You have to connect those artifacts yourself.
And this is where you have to not only deal with cognitive bottleneck, but operational one: "where do we have logs for our service?", "I can't find PRD on our service, can you link it to me?", "this doc is outdated".
I'm exhausted. I can't do this anymore.
So I'm building my own system.


1
11
11,758
Nikolay Konovalov retweeted
Jun 11
Yes, yes yes please please please don't do markdown programming. I consider it harmful.
Here's much better idea what we can do: github.com/usecoherence/cohe…
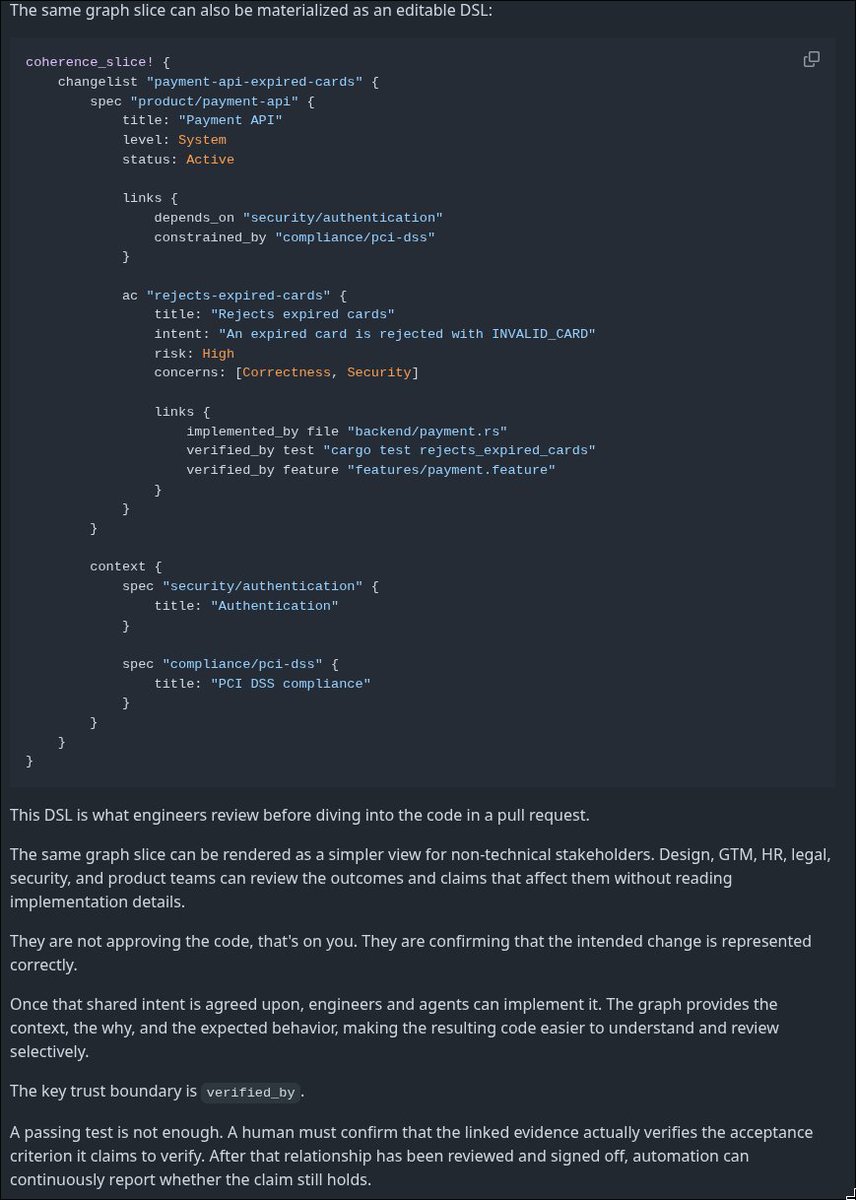
These are product specs.
And this is how you can render a slice of them. DSL my beloved.
Now, go rewrite your SKILL.md into graph of specs. This won't be easy though.
Let's see.. what kind of example I can show..
Well, here how you can translate these markdown "skills" into verifiable specs... pastebin.com/RkGGdLzt
Goddamit this is actually so easy...
ALL YOU NEED IS A LINTER 🤣
And a bit of heuristics, and thinking.
Go figure it out.
I will do it myself a bit later, I'm busy implementing changelists for coherence (see the image): you write Lisp-like DSL, then this creates jsonl records, then you create new branch in DoltDB , merge those new records, stage, commit, make PR -> people can review your specs, comment on it, etc.
If all good, then you can assign agent to work on it.
Isn't this genius? 🍇
I'm building this for you guys... For free... just need feedback.
1
1
105
Jun 10
> Be Nik
> Spend 12 years deleting code
> LLMs come into play
> Code is being undeleted at incredible speed
> Become depressed
> Question what engineers actually do
> Write down every single step without skipping
> Realize this is algorithm, a loop
> Realize the data structure is a graph
> Realize you can describe everything with a graph
> Realize brain is a graph, code is a graph
> Realize problem solving is simply creating a graph with state transitions
> Spend 2 months formalizing problem-solving
> Realize it's impossible, except brain is doing it on 30W
> Realize brain is a computer, so formalizing is possible with some extra research, just not today
> Remember that code is data, data is code (Lisp)
> Design a system that describes world without code, only data
> It's a fucking graph on top of Dolt DB for versioning
> Accidentally discover coherentism
> System describes itself, like a fractal
> Try to explain system to people
> It's like trying to explain quantum physics
> Realize not many people know about graphs
> Realize understanding something is simply connecting new graph nodes to old ones you know
> Realize we just need to connect everything
> Realize that's what Nik was doing for 12 years, manually, inside the brain
> Realize we gonna automate most things around problem-solving
> Realize we need to optimize for understanding the world
> Build bootstrap of the system
> Bootstrap builds rest of it
> Realize it is a spec compiler, that compiles reality, but simulated, bounded system
> Reverse engineer specs of a bootstrap with a graph and ledger, without ever looking at the code
> Problem solving can be approximated with a huge graph describing thinking process in low-level details.. thousands or millions graph nodes
> The only true limit is quantum string theory, can't verify something you don't understand yet
> Only a matter of time to discover edges between existing graph nodes
> Capitalism hits hard, leaving only 2 months in bank account
> Hire Nik to let him continue research
> He will build a graph for you
> Everything is a graph
> Become a graph
> Graph
Jun 10

> Be Zuhaitz
> Learn C by writing an OS
> Was just bored
> Learn C and assembly
> Write several C libs
> Write Pinnacle (asm lang)
> Write Zen C ( 4k stars in GitHub)
> Working on it and on many other OSS projects for months non-stop
> Looking for a remote job now
Hire me 😼

1
29
Nikolay Konovalov retweeted
Jun 7
AAA was a mistake… just make AA or good quality indie game, why would anyone want to invest so much time, energy and money into AAA slop machine that eats itself with each generation, where quality isn’t really improving and all the budget is spent on graphics instead of gameplay, story, music, and worldbuilding.
I believe this all started with Sony’s platform exclusive games that tried to marry cinematics with video games. But it’s just one genre. Video games were always, always about interactivity, not watching cinematics. Why reduce art form to a single aspect of it? What are you gaining from this?
We have entire generation of gamers that grew up on exclusives that don’t believe good game can have pixel style graphics. That’s just sad. They would never experience Chrono Trigger because their time (pun intended) didn’t let them see the beauty of non-linear storytelling and „oh crap where I was going” after pausing the game for 2 weeks.
These are lost souls betrayed by corporate bullshit that is chasing money, not good games made to express feelings of people making them.
I still see there is soul left in game assets, environments, textures, music, occasional character dialogue and I never skip exploration and tinkering with game mechanics because this is all me touching someone else’s work, and reflecting on what they wanted to say.
And it just breaks me realizing so many good talent is just wasted out there because of stupid greed that doesn’t understand video games — ultimate art form of them all. They combine artists, book writers, musicians, programmers, actors, sound designers, animators, FX, mocap performers and many many other people whose work can be considered an art form.
An ultimate art form, no less. And people treat it as „AAA” slop because budgets went to cinema looks and not what makes the game — the GAMEPLAY. Nothing really changed since early 2000s. The only people innovating are indie. AAA is just walking in the same spot occasionally changing graphics but core gameplay loop isn’t changing. And this is terrible, terrible place to be.
Even Nintendo seems to lose grasp with their players, if you just trace what’s going on with Pokémon series. The company that defined gaming, that brought us Zelda. What the hell are you doing guys.
Challenge everything. That was the slogan back in time that excited a lot of people. And not because of graphics, no. Because of gameplay loop.
Stop pretending people want to see better graphics, and stop wasting 98% of budget on it. Give gameplay a chance. Make good story. Make amazing music that keeps playing in your head 20 years later. Make the goddamn book. You can do it. 20 times with these budgets. Only if you stop marketing cinematics. That’s all really there is. Stop feeding your marketing department.
Give a chance to new gameplay loops. Give games the freedom they deserve. The ultimate art form you cannot even hold under corporate chains of greed, and it shows in tiniest details.. in textures, in 3d models, even environment lighting.. because it’s people working on assets, even if they are overworked, you can see some soul being left for you to explore.
And I don’t want some greed simply destroy this.
1
1
7
264
Jun 6
This is exactly type of product design that makes you think "what the hell are they smoking" 🤣
Y'all have offers? MULTIPLE?
I can't get an interview without scammers asking for my government ID after the first round😭
(I'll write up the full investigation I did this Tuesday-Thursday a bit later and it's not going to look good for LinkedIn)
1
1
44
Jun 6
I genuinely don't understand how this can be 50k github stars
It doesn't even have sqlite3 to store job data pipeline, what the hell...
Compare this to what I'm doing
25 tables, Carl! 25!
And it took me only 8 hours to come up with data models and processes that ingest the data into system from external source, e.g. #theirstack.
I'm just gonna eat this for lunch I guess, now I'm super motivated 🤣

1
1
87
Jun 2
Goddammit 🤣
If you are asking yourself "why should I sub to this guy".
This is why.
Jun 2

Am I looking at the fucking graph again... please no more🤣
I spent 2 months crawling through my brain graph just to find out you can solve anything with graphs... now my life is a graph.
I'm a graph. You're a graph node.
We're all connected.
SEL reference, yes.
When I wake up, every day I walk through reality with a black garbage bag and collect semantic leftovers: requirements, edge cases, weird recruiter forms,
broken abstractions, undocumented business rules.
Two full bags per day. Easy.
And then, after a hard day, I come home, open Coherence, pour all of it into the semantic graph and watch the nodes connect.
Mmm.
A product requirement links to a test.
A test links to a failure.
A failure links to an assumption.
An assumption links to childhood trauma.
Beautiful.
I think graphs can think.
They have families, cities, feelings.
Don’t delete orphan nodes.
Adopt them.
Name them.
Give them acceptance criteria.
Yesterday I had a dream: I dived into the sea, and the sea became a graph.
Fish were nodes.
Seaweed was edges.
Jellyfish were cyclic dependencies.
The sky was a graph.
The recruiter form was a graph.
Even the garbage.
Even LinkedIn.
Even Allah.
1
63
Jun 2
This is why I'm building this.
@n8n_io I came to apply and this is unacceptable. This is soul-crushing. And I'm gonna call you out so we can all learn from this case and hopefully arrive to a place where we don't have to do this anymore.
You are a company that supposed to make automations easy for everyone. That is commendable. And I want to apply and make n8n an even better product. I believe I might have good ideas
But this application process is ridiculous to the point where I'm convinced that you don't care about how engineers feel writing down answers for all those checkbox options and endless input fields.
I mean...
If you want me to apply by making an automation to check those boxes automatically from reading my preferences I wrote beforehand... Sure!
Challenge accepted.
Let's go and do this together, shall we?
Step 1.
I asked agent to install browser-use and it took ~3.5 minutes from me sending a prompt, to agent creating `~/git/konovalov-nk/browser-use` directory, and then installing it, and then using it to extract the questions without any sort of further guidance: pastebin.com/KFLnHWvn
My two prompts were literally this:
1. "Can we extract questions and answer options from this URL ..." -> WebFetch doesn't load JS properly and simply shows main career page
2. "Lets setup browser-use into ~/git/konovalov-nk/browser-use" (I didn't even tell why we want to do this)
Now, what's next?
I have my resume setup at resume.br11k.dev/ and my resume is very simple to parse and read, and I actually still have json version of my resume from building it on top of github.com/konovalov-nk/reac… and I should probably just host it under /json URL for agents/LLMs that can reach my website.
(Note: feel free to steal this setup btw: it can produce a static HTML you can self-host that scores "100 Perf / 89 A11y / 96 Best Practices / 100 SEO" on desktop according to pagespeed.web.dev/, as well as my favorite template I decided to replicate and it took an entire week of sweat and blood and installing pixel-perfect plugin which I haven't used for like 10 years but I digress).
Step 2.
I wrote a tiny spec how to actually properly parse the application data into JSON. I'm simply giving it a structure.
1. questions.json
[ { "id (simple integers from 1 to x)": 1, "question": "...", "type": "checkbox/text_input/...", "required": true/false, "checkbox": { "minimum/maximum/etc": 4 }, "options (for checkboxes)": [ { "id (again, good to have this parsed into simple integer ids so answer is simpler to associate with options)": 1, "value": "..."}, ... ], ... } ]
(see screenshot)
2. answered.json
[ { "id": 1, "response": { "text (if it is input type)": "...", "options (if checkbox)": "response_type": "checkbox/text_input/multiline_text_input/..." } ]
pastebin.com/rTpCeGYF because I can't attach more screenshots
Step 3.
We launch `google-chrome-stable --user-data-dir="/tmp/chrome/automation" --remote-debugging-port=9222` (CDP)
And then agent does the magic thing called `const { chromium } = require('playwrite')`.
CDP is Chrome DevTools Protocol and it allows to essentially control a chromium-based browser programmatically. So I can launch a browser on my machine, login where I need to, and let agent to control it. Cool stuff.
Step 4.
Now agent does the magic: 1) navigates to page, 2) finds selectors / inputs, 3) fills all the details, 4) sends me a notification that I can now review and submit my application.
This is where the bottleneck lives because I still have to verify that question answers were not hallucinated or just plain wrong, but you can agree I made it waaaaaaaaaaaaaaaaay simpler than doing this all by myself.
Step 5.
I write down in detail my frustration and what I'm doing on Twitter so that other people can open up my profile and see what I'm struggling with and hopefully learn something useful out of it. But anyway...
My point have been made.
And to the rest of normal software engineers that don't want to make it competitive, this is a soul-crushing experience. I can't even force myself to go through all of it in a single sitting.
I can't be silent about this.
Let's end these stupid hiring practices and let us apply freely. If we are concerned about people mass-applying that's because the process is broken, not people. We made it this difficult to review candidates. We made it unbearable for the average guy like me. We made it a numbers game, so we play the game by our own rules, and what do you expect? That I will apply one by one, where an individual application takes 3 hours to go through because of stupid UI/UX decisions? I don't have time for this. Nobody does. And we expect people to go all out and crawl out of their skin to reach the hiring manager's eyes. An insane commitment to make for a company that would just filter out 99% of the candidates with an algorithm ATS provides. Where more than 80% of them are genuinely capable to do what the job description lists as a requirement, if you just give them a chance to prove it. "There's just too many applicants!", you might say. Sure is. Who created this problem though? Why nobody is trying to solve it? Why do we have to live in this goddamn dystopian world today where you need to send 100 applications before receiving a single response?
Here's what I figured out while I was at Codility.
Hiring proper people for your team is difficult. This is genuinely hard problem to solve. We don't even have assessments that test Software Engineers properly. If your suggestion is automated coding assessment, you already know what I'm gonna tell next.
Not a chance I will hire a person that knows how to write a red-black tree with their eyes closed but cannot debug a broken development environment and fix it during pair programming session, while communicating clearly what is their thought process, and what they know, don't know, and asking for help.
And this is such a simple test that LLMs cannot help solve today during live pair programming session. I've seen many candidates to try and fail to debug a two file Python app setup with simplest possible task to write 10-20 lines of code for a full solution. It's just ridiculous at this point to even consider those people to let into this industry. I've seen Senior engineers in their title that couldn't figure this out, come on, man...
What exactly is problem solving ability?
I just demonstrated one to you. Here's problem, here's how I solved it. Raw, pure, unfiltered thoughts of my ADHD/OCD brain. Yes, inefficient solution, and took too much time to write this all down to make a point.
But tell your agent to look at what I wrote and it would implement my solution 1:1 exactly and it will work. Because I just went through this and the only thing left for me is to press "Apply" button.
But will I get a response?
That's not for me to decide.
I did my best to apply. I even solved a problem while doing this. I didn't want to. It's just my stupid brain comes up with stupid ideas called "lets optimize this, no matter what is the cost of doing so". But in this case, I was lucky enough that cost was about 30 minutes of pure thinking process, and now I can write a detailed spec and refine it later when needed. And share my solution! We all should share our solutions to problems. And if a solution is still difficult to use, then we can provide a service, sure.
That's what I do as Engineer, every day.
But today is already past 2:55 AM, and I'm exhausted and I don't blame n8n team for what they did but at some point I had to stop what I was doing, and say to myself:
"Nik, you have done well today. You can go rest. Come back tomorrow, and we'll continue working on this."
And I only wish that tomorrow I don't have to do this soul-crushing job search anymore, and I can focus on developing specs for the product I will care about.




Jun 1
Here's a sneak peak of "what the hell specs are".
Yes, every single decision, captured in a spec graph.
Even models, why the hell do I need 25 models for job search tracker... There you go.
1
47
Jun 1
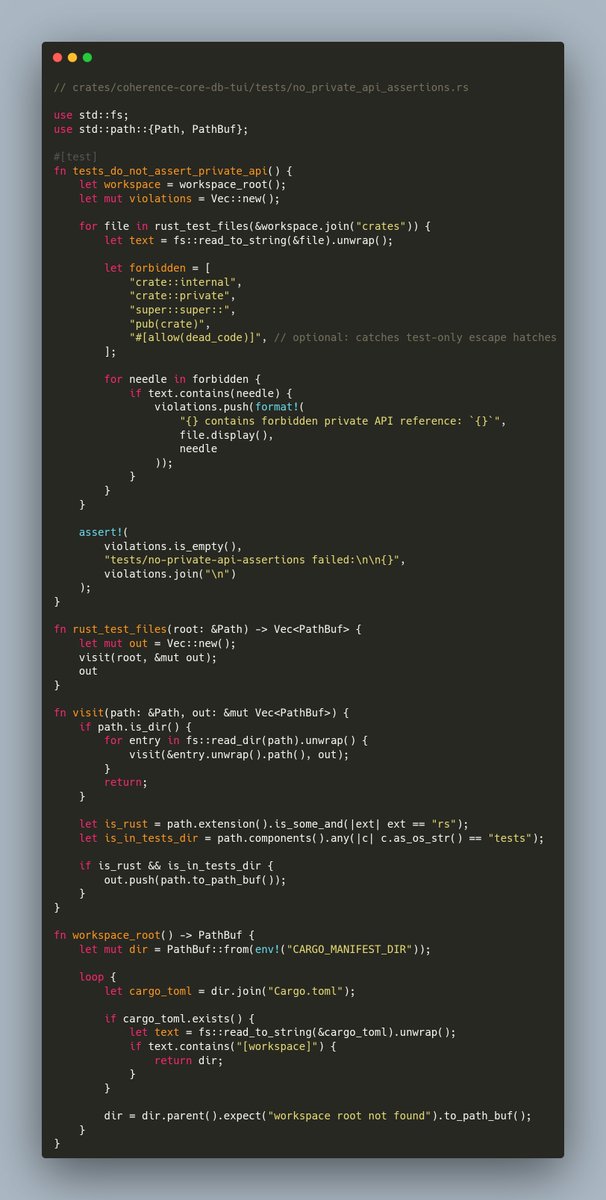
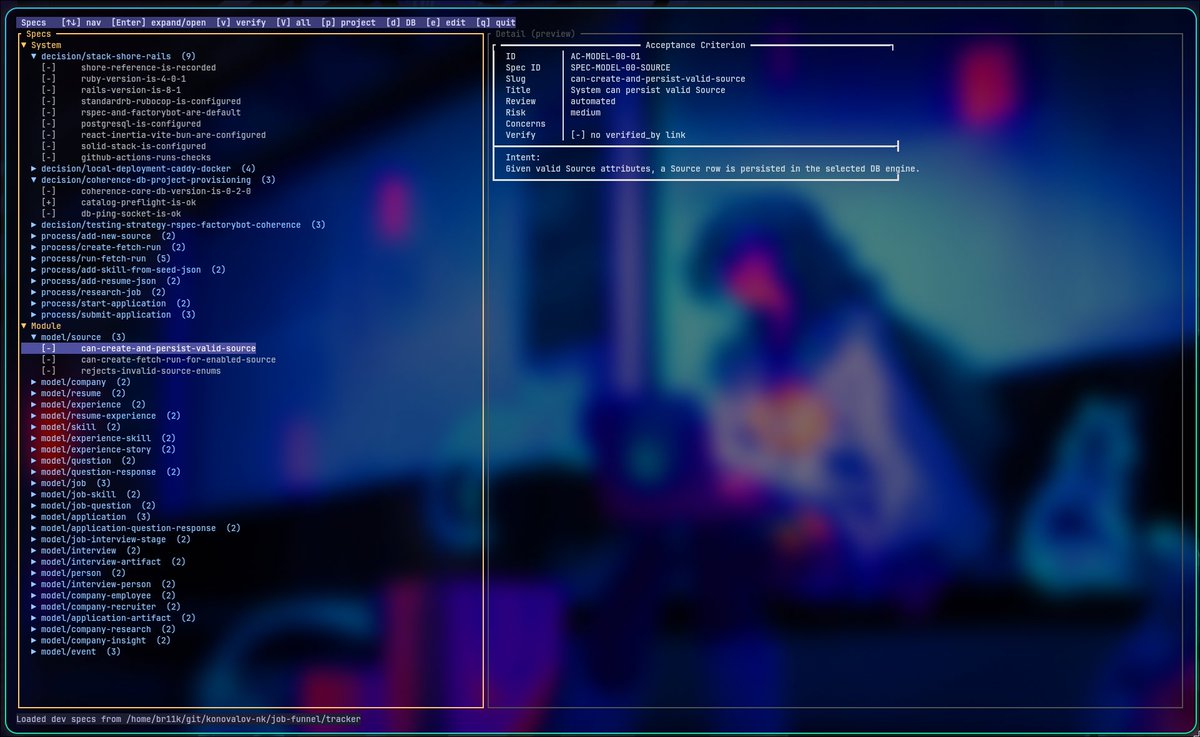
I asked the agent to reverse engineer the specs from the code we wrote.
And it actually worked!!!
I simply know that LLMs are best at classifying the data. So the idea was this:
> Look at the code, CLI commands, TUI, migrations, tests, and extract from there what behavior the system actually exhibits.
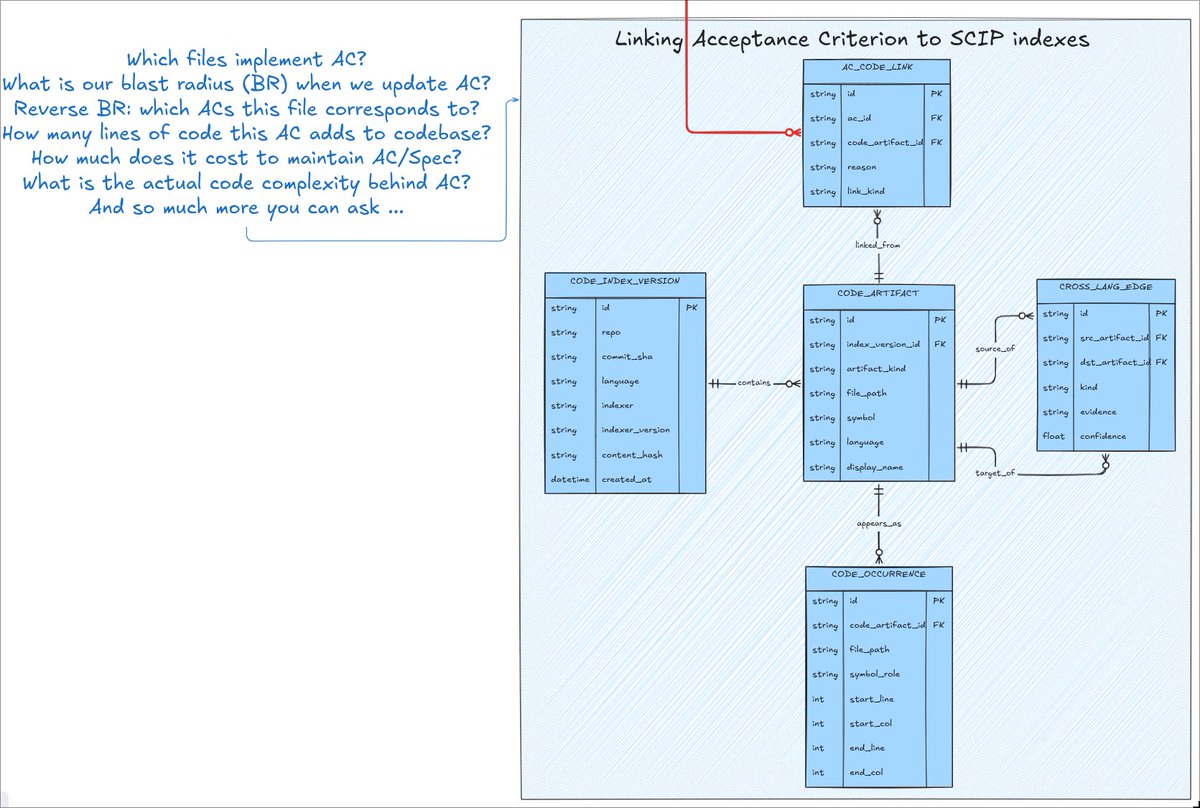
But where do we start? SCIP graph. Again, thanks to Sourcegraph team for giving us this free open standard we can now all use for human benefit 🙇
- rust-analyzer scip -> index.scip
- rust-analyzer symbols -> symbols.jsonl
- python script -> generate code inventory from scip symbols (github.com/usecoherence/cohe…)
- script classification -> behavior_candidate / evidence / internal
So a SCIP graph of the codebase is simply running rust analyzer and then making a classification script on top of it.
This is simply an index of all files/symbols/functions, so we don't have to rely on "well, I just looked at everything with my own eyes".
Then we go through the files in the graph and mark them: this is product behavior, this is system mechanics, this is test infrastructure, this is just an internal detail.
Then next logical step is a ledger. Not blockchain ledger but inventory one, which is essentially a rough table:
- what the code does
- where it was found
- which future spec does it belong to
- what acceptance criterion will this become
- is there proof yet or is it still unclear?
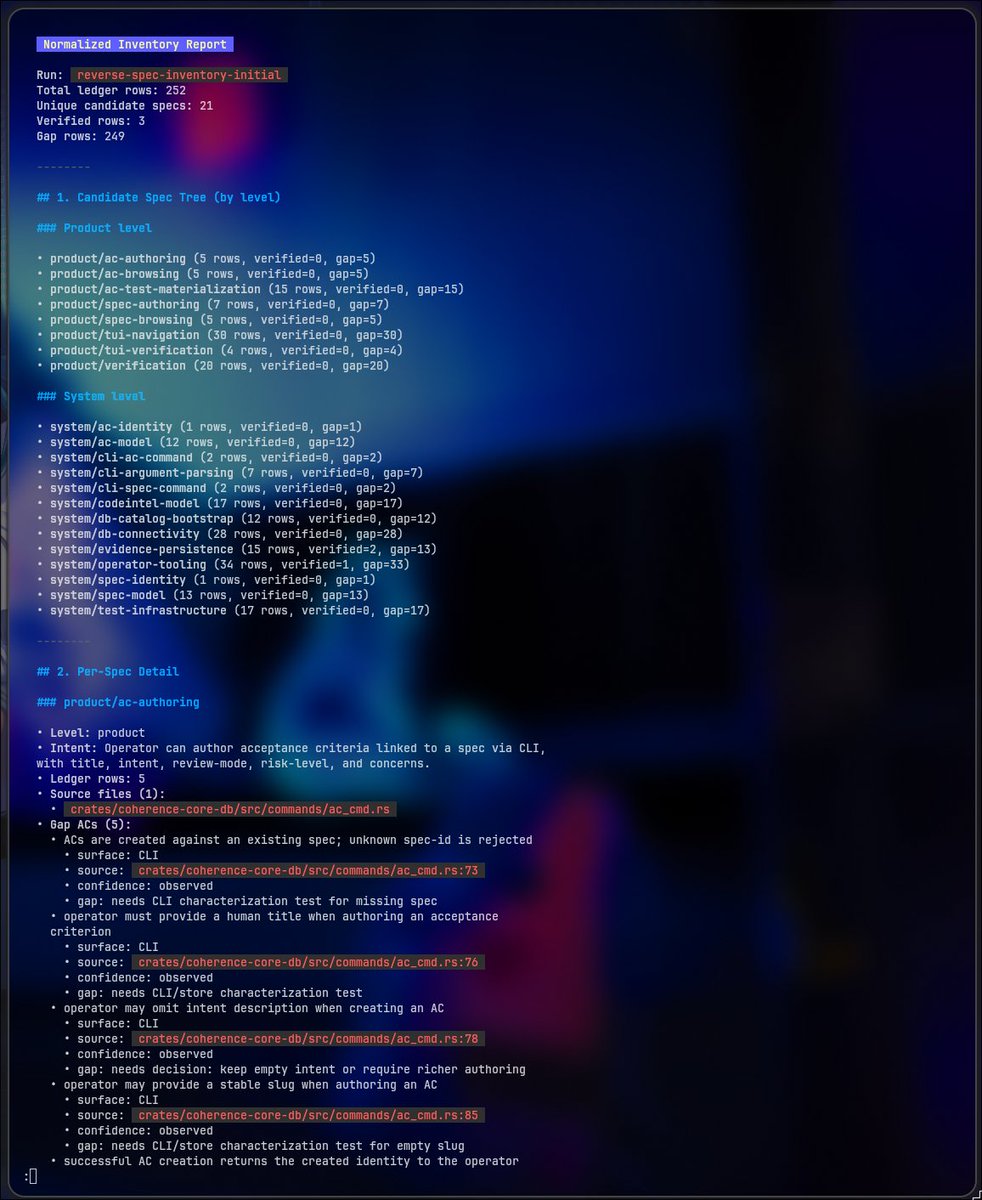
And now after going through this ledger, LLM produced "normalized_inventory.md". This already looks like a map of future product/system/module specs.
Here's result on Coherence bootstrap repo (github.com/usecoherence/cohe…).
pastebin.com/UNVUBuc2 (this is normalized_inventory.md)
- 62 files reviewed
- 252 behavioral observations
- 21 candidate specs
- 3 already confirmed by tests
- 249 still gaps
When I reached this step, I realized...
That's already mindblowing 🤯
I have spent 0 brain cells on actually reading the code and understanding it and I already have some form of specs (a lot of them for a simple project of only 60 files with code).
Took me only 30 minutes to reverse-engineer candidate specs. And the attached the .md on pastebin if you really wanna skim through it.
So what do we have there?
Product-level things like authoring specs/ACs, verification, TUI navigation are visible, as well as system-level things like DB connectivity, evidence persistence, operator tooling, and test infrastructure.
I barely thought about how to do this all, it was just an idea...
And I got a decent system map from the code.
This is 1852 lines markdown, covering all 21 candidate specs, 252 ledger rows, 7 sections. Not code. Candidate Specifications.
Read that again.
Candidate Specifications.
The thing that nobody writes today and then wonders that software doesn't work as we intend to. Source of all problems. Bugs. Missed deadlines. Inability to create a thorough, complete spec of a product that you are building and keep it updated with the code.
And it took only 30 minutes to make for a repository with 3 Rust crates, 60 files, ~10k LoC.
1
31
Jun 1
I didn't want to expose this but I guess I just have to.
"The company is focused on building team relationship in the newly opened office, so that's why we invite you to attend at least 3 days a week."
I met my spouse back in July 2015 over social media (VK, and she wrote first) and Skype (10 hour sessions). I bought her a ticket and we met at airport on August 30th, 2015.
A little over a month being terminally online with each other until full commitment. And we are living together ever since.
But apparently "building relationships" require at least 3 days in the office🤷

25
May 16
This is the most important realization I ever had in my entire career and even life. Truly an eye opener for me.
Don’t mop the floor, fix the leaky faucet.
May 16
I spent 13 years of my career thinking I have to solve every problem life throws at me. Go watch Rambo: First Blood. I’m literally John.
Was.
After my last engagement with Codility I spent two months figuring out why I lost again, if my entire life is not to make any mistakes at all.
I designed a system that I could use to prove that the system I have built is correct. It’s a semantic graph plus verification, but not gonna talk about it here.
What I learned is, it’s impossible to prove that you are truly right or wrong, because fundamentally you are bounded by reality to quantum strings theory, and we cannot even tell what is going on on lower levels. So clearly we cannot infinitely go down and prove everything.
Engineering is not about making complex systems. If you watch Rich’s talk you will understand why. Best engineers reduce complexity. Best programmers find a rusty leaking old faucet and turn it off.
What happens when faucet leaks ? You get a pool of water. And your first intuition is to mop the floor. And if you never ever look up and ask yourself „why the hell am I mopping this every day?”, you might never discover there was a faucet installed 10 years ago.
And the one who installed this faucet said in their git commit „it’s an MVP, details are in bug tracker ticket ABC-123”. Bug tracker gone, that person no longer works there and you are the archeologist that just discovered this.
What do you do? Build on top of that leaky rusty faucet?
No, please don’t do it. Stop. This is genuinely a good thing you found the faucet and you must write it down immediately as a spec. This is the problem you must at least acknowledge exists because it already leaks into your system.
Did you wrote it down?
No you didn’t.
Go back and document a problem that nobody else documented. Oh you don’t know where this spec belongs? You don’t write product specs? Well, that’s certainly a problem but you might be the one who finally does. Go read Joel Spolsky Painless Functional Specifications on how exactly. Then come back here.
Now, here is what I learned.
Engineers are building semantic graph structures in their heads and then they are using it to write code. The quality of that structure is the most valuable thing. And I figured out how to express this with a simple set of database tables, and relations between them.
And this is how Coherence (project im building solo) was born. But this post isn’t even about it.
What I want to show is that complexity is a choice. Simplicity is also a choice. And engineers are building semantic relationships between what product must do and what the actual bounded system — code — does.
And yes it is always easier to add more graph nodes over existing monolith graph with 1,000,000 lines of code.
But the best engineers I have seen are not doing that. They go dig that graph of complexity and figure out how to rip it apart and substitute with a simple solution.
And once you realize this you will become Staff level engineer. Because now you, my friends, you see where the leaky faucets are and how exactly they produce complexity and work nobody needs to do, after you just fix the source of your problems.
Dont mop the floor, fix the faucet goddammit
1
83
May 7
> Under the new rules, EU companies will be required to share information on salaries and take action if their gender pay gap exceeds 5%
EU companies in question:
1
60
May 7
Laws are literally programming: a graph of specs.
Articles, clauses, definitions, exceptions, cross-references.
But the interesting part is implementation.
```
LAW_SPEC
Article / paragraph / definitions
"employer must disclose salary range"
AC
salary range disclosed before interview
range is meaningful enough for a candidate decision
exceptions are objectively justified
```
Then comes the plan:
```
PLAN
classify role level
compute band from compensation matrix
publish range
store evidence
audit pay gap
``
And the runtime is where it actually executes:
```
RUNTIME
Poland / Germany / France
courts / regulators / labour inspectorate
HR systems / job boards / recruiters
incentives / penalties / enforcement budget
```
Same EU spec, different runtimes.
```
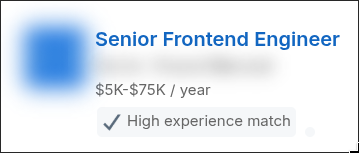
The bug:
Spec: candidate gets salary transparency
Plan: publish "$5K-$75K / year"
Evidence: screenshot exists ✅
Semantic compliance: candidate informed? ❌
```
36
May 6
I want people to look at this and realize that Markdown isn't the way to build specs.
Please, please, lets not normalize Markdown and JSON as first-class Specification/Acceptance Criterion artifacts.
And if you don't agree, let me know why.
I'm very happy to prove myself wrong.
May 6
I looked into GSD but all I see is so called "markdown slop". Lemme explain. In one sentence.
> "Markdown as source-of-truth for artifact relationships is the wrong abstraction"
Then lemme demonstrate my points:
1. How do tests abstract from specs/AC?
```
GSD:
REQ-001 appears in roadmap/verification
PLAN.md says files verify command
LLM/verifier interprets whether requirement passed
-> boom, LLM inteprets your intent, you get drift immediately
coherence:
AC_CODE_LINK / PLAN / RUNTIME / ASSERTION_RESULT
machine can query:
which test validates AC-7?
which ACs are touched by this symbol?
which evidence snapshot proves this assertion?
-> human has to look at this, own this mental model
-> agent sees short feedback loop expressed as code, verified by human
```
2. How are specs linked?
```
GSD:
ROADMAP.md mentions REQ-001
PLAN.md mentions files
VERIFICATION.md says REQ-001 ✓
STATE.md says current position
Coherence:
acceptance_criterion(id, spec_id, ...)
plan_ac_link(plan_id, ac_id)
runtime_target(plan_id, target_id)
evidence_snapshot(run_id, assertion_id, ...)
code_artifact(symbol_id, file_path, ...)
ac_code_link(ac_id, symbol_id, link_kind)
```
3. If specs are linked together, how are they refactored without indexes/DB?
```
GSD:
-> oops
Coherence:
-> UPDATE .. SET .. WHERE
```
GSD have problems with "context reduction" because they shove gigantics .md and .json files into a model and praying it would not hallucinate a solution.
Coherence doesn't have this problem because every AC is trying to be as simple as possible, a single test. Test connected to codebase. And so the only thing model needs to ingest is the test code symbols it references, and it can go depth=1 or depth=999, as much as it needs. If AC depends on another AC, or another SPEC, again -> just control depth= parameter to fetch as much context as you need.
GSD is trying to fix it with Graphify. This is curing a symptom and not a root cause.
> "graph-after-markdown != graph-first artifact model"
Stop "markdown slop".
Adopt graphs🙂
E.g.
github.com/konovalov-nk/cohe… is DB artifacts linked to code: excalidraw.com/#json=WT-oRUd…
and this is initial post I made: x.com/br11k_dev/status/20471…
79
May 6
While I was hacking on gastownhall/beads yesterday I realized that it uses Dolt DB.
And I was thinking
> "How can I show a diff of spec/ac/plan/relations and branching"
because all specs and ACs and other artifacts live in sqlite3...
And then this was the vision:
```
Intent diff
SPEC-1 goal changed
Acceptance diff
AC-7 added
AC-3 expected behavior changed
Plan diff
PLAN-1 step 40 changed
ASSERTION-8 added
Runtime diff
RUNTIME_PROFILE-rails-local added
Evidence diff
RUN-22 proves AC-7
screenshot sha256:...
trace sha256:...
Code linkage diff
AC-7 now linked to app/validators/url_validator.rb
```
Thanks @DoltHub !!!
43
May 3
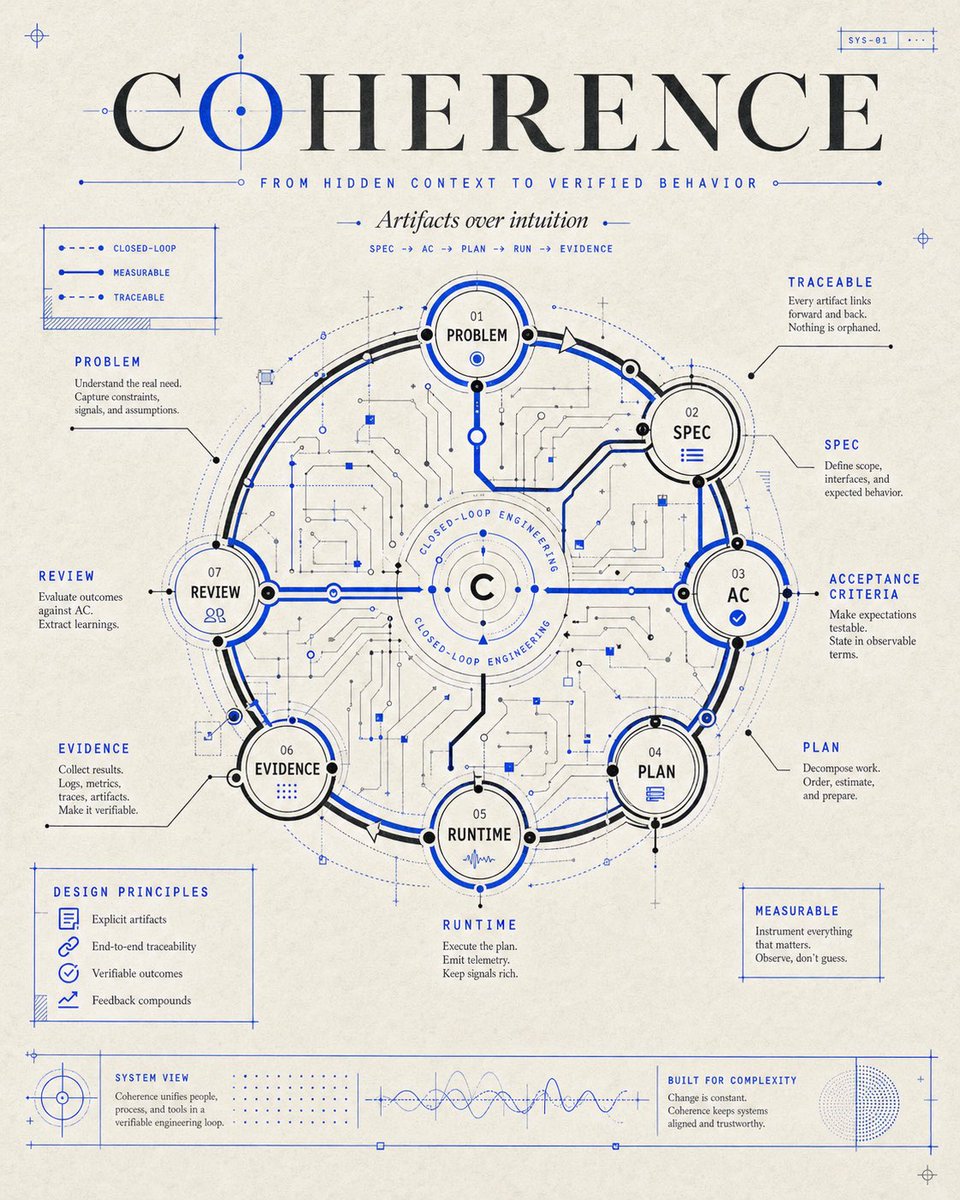
This is exactly how I’m thinking about the Coherence demo I’m building right now.
We want to engineer closed-loop systems where engineers spend their time not reconstructing intent from code diffs, Slack threads, and stale docs — but verifying that intent survived the full path:
Problem → Spec → AC → Plan → Runtime → Evidence → Review.
And this means the real interface is no longer “here’s a PR, please understand it.”
It becomes:
“Here’s the claim.
Here’s where it came from.
Here’s how we executed it.
Here’s the evidence.
Here’s what changed.”
That’s the shift I care about.
From hidden context to verified behavior.
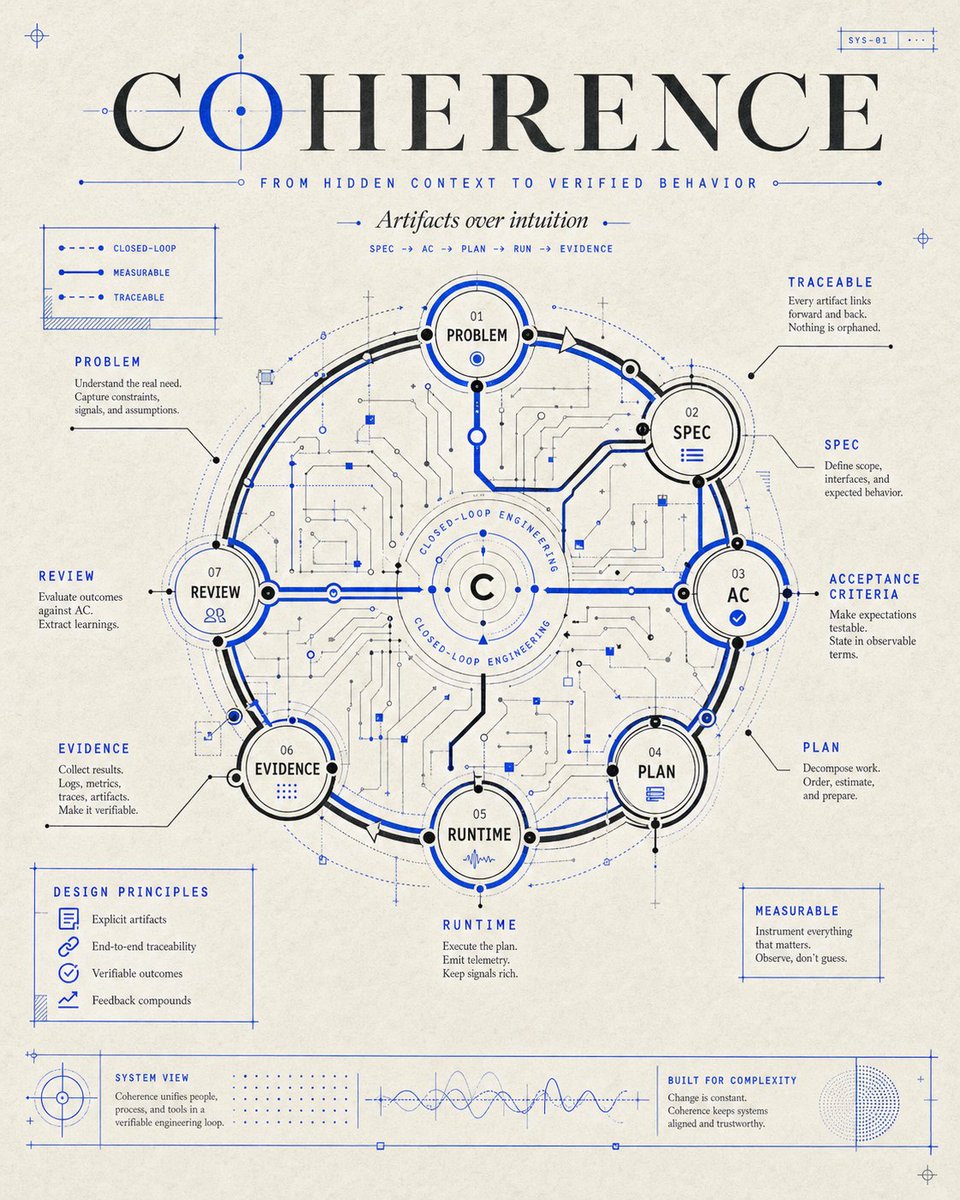
ALT A blueprint-style poster titled “COHERENCE” showing a circular closed-loop engineering system. The central diagram connects Problem, Spec, Acceptance Criteria, Plan, Runtime, Evidence, and Review, with circuit-like lines and blue technical annotations. Taglines include “From hidden context to verified behavior,” “Artifacts over intuition,” and “Spec → AC → Plan → Run → Evidence.”
40
Apr 29
This is the clunkiest privacy agreement statement you'll ever hear
copilot.microsoft.com/labs/a…
I was just browsing around conversational TTS models I can self-host (e.g. Sesame CSM 1B) and Microsoft forgot to populate demo input with anything.
And guess what I just copy-pasted🤣
50
Apr 23
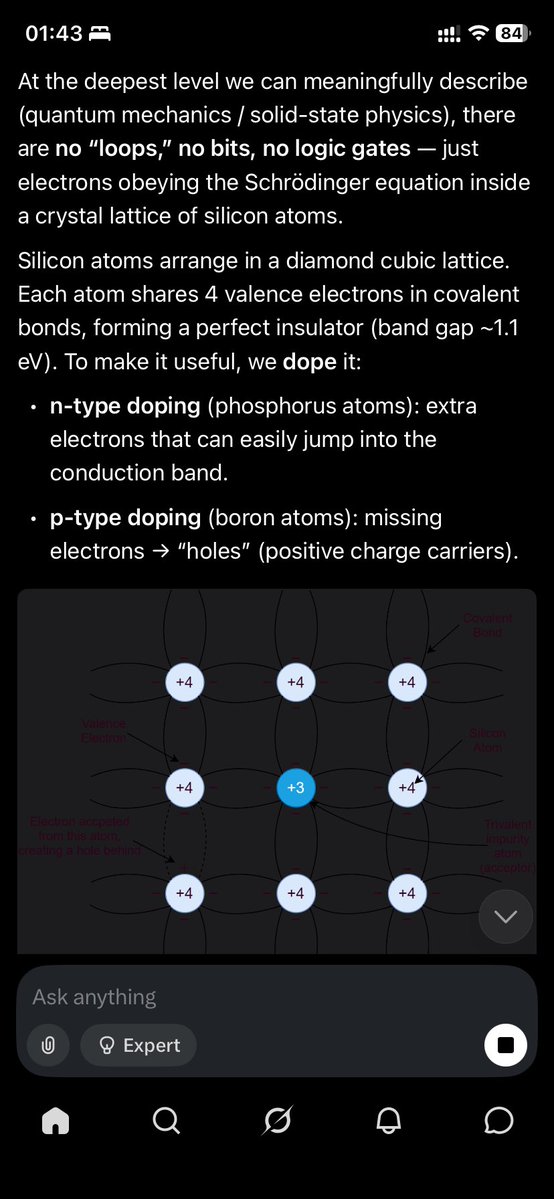
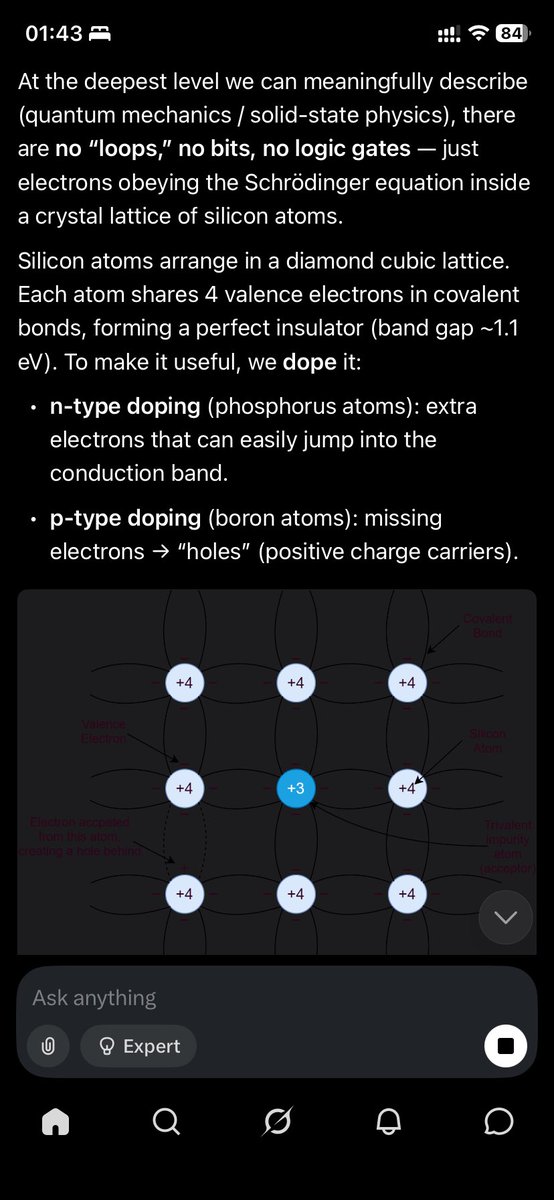
Visualizing "cognitive debt" in Software Engineering.
Or simply:
> "Where does the code review bottleneck actually lives?"
Link: lnkd.in/dBej52xy
This is my mental model on what exactly is happening inside of a brain during problem-solving process. All of that has to be loaded into working memory.
When you look at function definition, a class, an interface, an API call, a log statement, a failing metric in Grafana, RFC on how exactly Browser Clipboard API works, and so on. This — is exactly the "hidden cost of engineering" that I haven't seen anybody would visualize.
And I just did it 🤷
So why we cannot simply accept code written from LLMs / other engineers? Why we need code review?
Some people suggest this is trust problem:
> "We cannot trust LLM/human/third party to transition requirements into spec, or spec into acceptance criterion, or suggest code edits, unless we are confident in their abilities."
My ERD diagram says: "you have to validate that Spec contains these ACs", or "does this AC link to this file in codebase?", or "does this e2e test evidence (assertions, artifacts) actually verifies AC is implemented?"
If you can do it for 100k LoC system, without looking once into Jira/Confluence/Slack/git blame — I envy you. This means all of those decisions, all of those tiny spec artifacts somehow live, efficiently compressed, in your memory.
But I cannot do this. Never I was able to. And all the systems that were built previously, they don't help me with cognitive bottlenecks as much as I'd like to. We have git blame, we have Jira, we have CI/CD, we have observability, documentation systems. But none of it is coherent. You have to connect those artifacts yourself.
And this is where you have to not only deal with cognitive bottleneck, but operational one: "where do we have logs for our service?", "I can't find PRD on our service, can you link it to me?", "this doc is outdated".
I'm exhausted. I can't do this anymore.
So I'm building my own system.
1
11
11,758