
The observability layer for production AI.
Joined August 2023
- Tweets 737
- Following 55
- Followers 6,766
- Likes 569
248 Photos and videos















Pinned Tweet

Jun 1
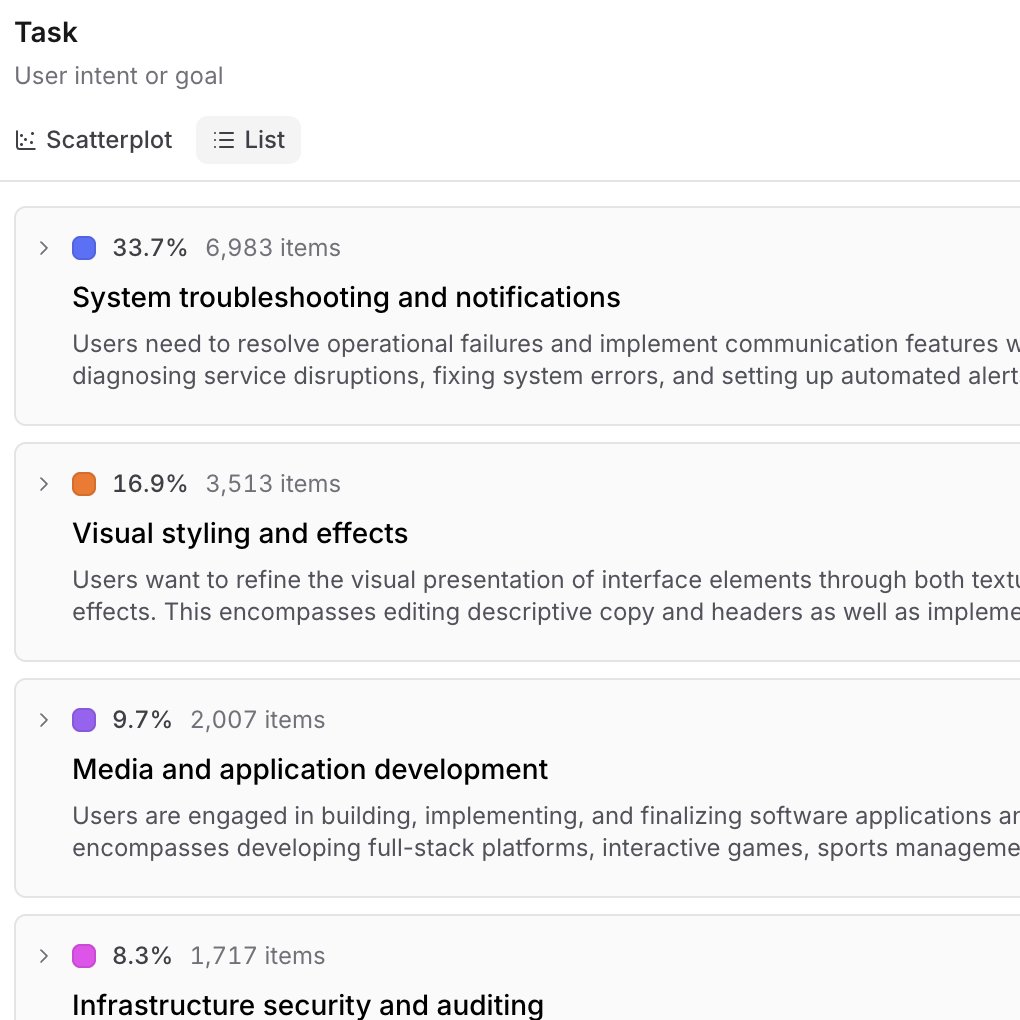
Topics is now GA on all plans.
Continuously find the patterns worth investigating across your production traffic.
2
4
17
2,245
Jun 12
How does your team rank when it comes to shipping quality AI products?
Braintrust's AI quality assessment maps your current practices to the next useful step, whether you're still manually checking outputs or already running online scores in production.
1
3
289
Jun 11
When production issues hit, engineers need to search logs and identify problems in real time.
Brainstore delivers query times under one second, even across terabytes of AI observability data. It's 23.9x faster at full text search and 3.73x faster at loading spans compared to leading competitors.
1
313
Jun 10
Traces tell you how customers are using your agents. Topics groups those interactions into patterns so you can uncover opportunities for improvement.
Braintrust is hosting a workshop on using Topics to identify customer use cases from production data and turning those observations into agent decisions.
1
198
Jun 9
Build a full eval pipeline (dataset, prompt, scorer, experiment) using just the Braintrust CLI and skills.
In this video, we test GPT-5 on chess puzzles and analyze the results of our experiments with only natural language, no code written.
Watch here → braintrustdata.link/CLI-skil…
2
314
Jun 8
The inaugural Agent Open is happening June 30 in SF.
Come talk about AI observability, then show off your skills at one thing agents can’t do: pickleball.
Hosted by the teams at @braintrust, @Cursor_ai, @llama_index, @turbopuffer, @p0, @modal, @browserbase.
1
1
6
692
Jun 5
What's new:
-Topics is now GA, with $249 in credits for Pro plans
-Multi-user human review, with averaged scores
-Workload identity federation for Anthropic, Vertex AI, and Azure
-Run remote evals and sandboxes as experiments
-Automate data preparation with dataset pipelines
1
6
460

Jun 4
Raw agent traces can include millions of tokens across hundreds of spans. Too large for direct embedding, too irregular for classic topic modeling, and too high-volume for full-trace LLM classification.
Topics solves this by summarizing traces into facets, then continuously embedding, clustering, and classifying them.
2
2
223
Jun 4
It sounds simple, but the hard part is making it work across millions of production traces without blowing out token costs or breaking down at scale.
Here's how we built Topics → braintrustdata.link/architec…
2
178
Jun 3
Production traces capture where your AI falls short and what users are trying to do. Building evals with that data is how you catch failures earlier and decide what to ship next.
Braintrust is leading a workshop on how to:
- Use the patterns Braintrust surfaces automatically
- Turn them into a labeled eval dataset
- Run the same workflow every time a new pattern shows up
2
1
272
Jun 2
Vibes-based testing and manual review don't scale.
Automated evals are easy to set up and can make an immediate impact on AI development speed. Learn about three automated approaches to get started quickly with evals: LLM judges, heuristics, and comparative evals.
1
1
1
287