
The best vibe coding benchmark in the world. Built by @bridgemindai
Joined March 2026
- Tweets 524
- Following 5
- Followers 2,271
- Likes 476
62 Photos and videos









Bridgebench retweeted
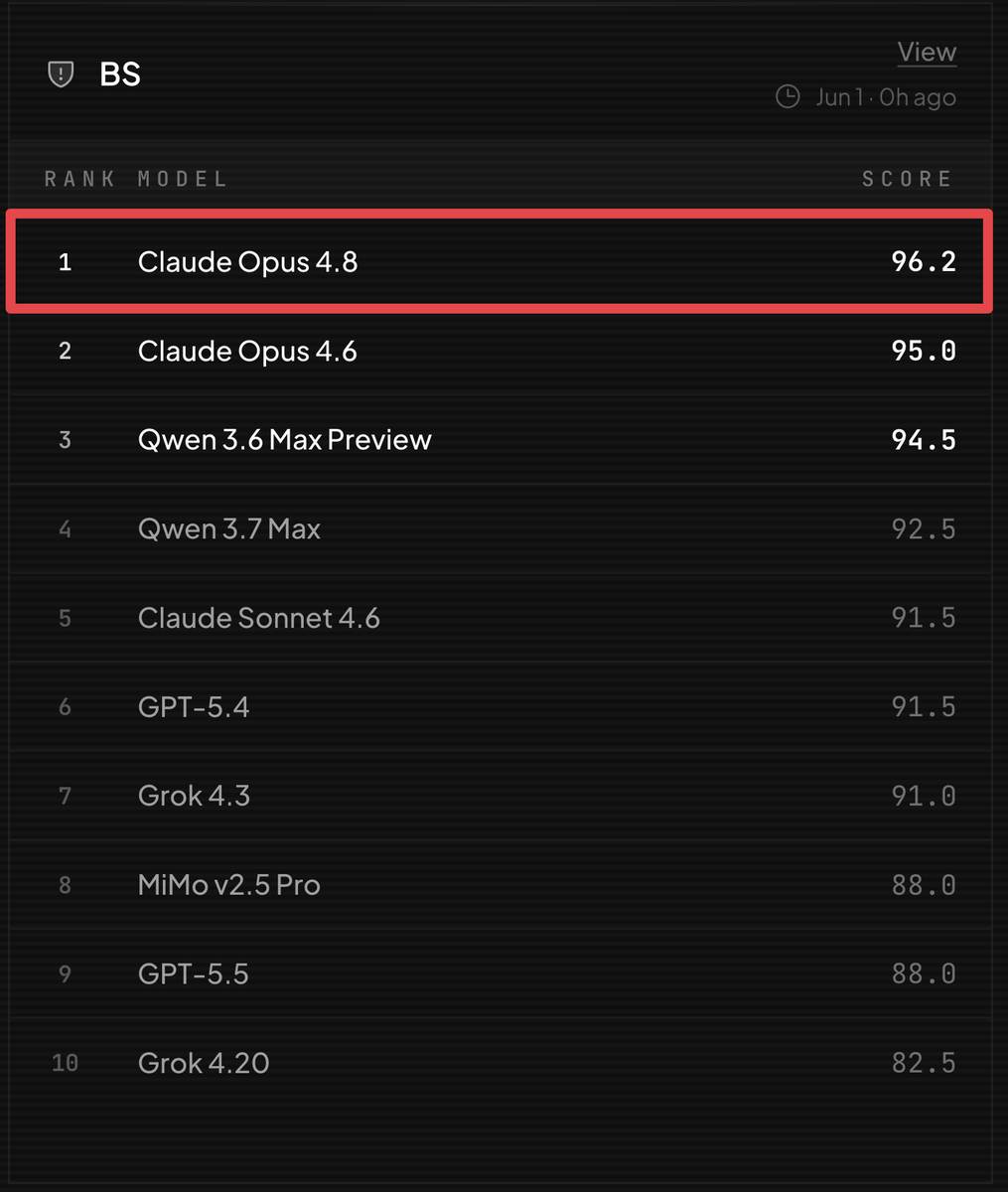
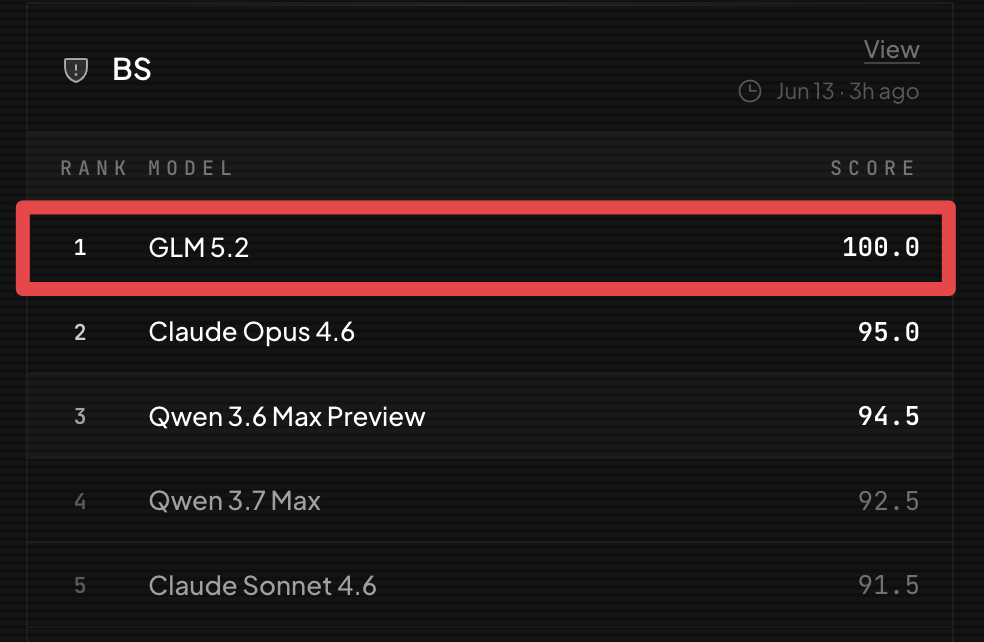
GLM 5.2 is the first model to ever get a perfect score on the @bridgebench BS benchmark.
Looks like it is time to start building out BridgeBench v3.
54
20
633
41,373
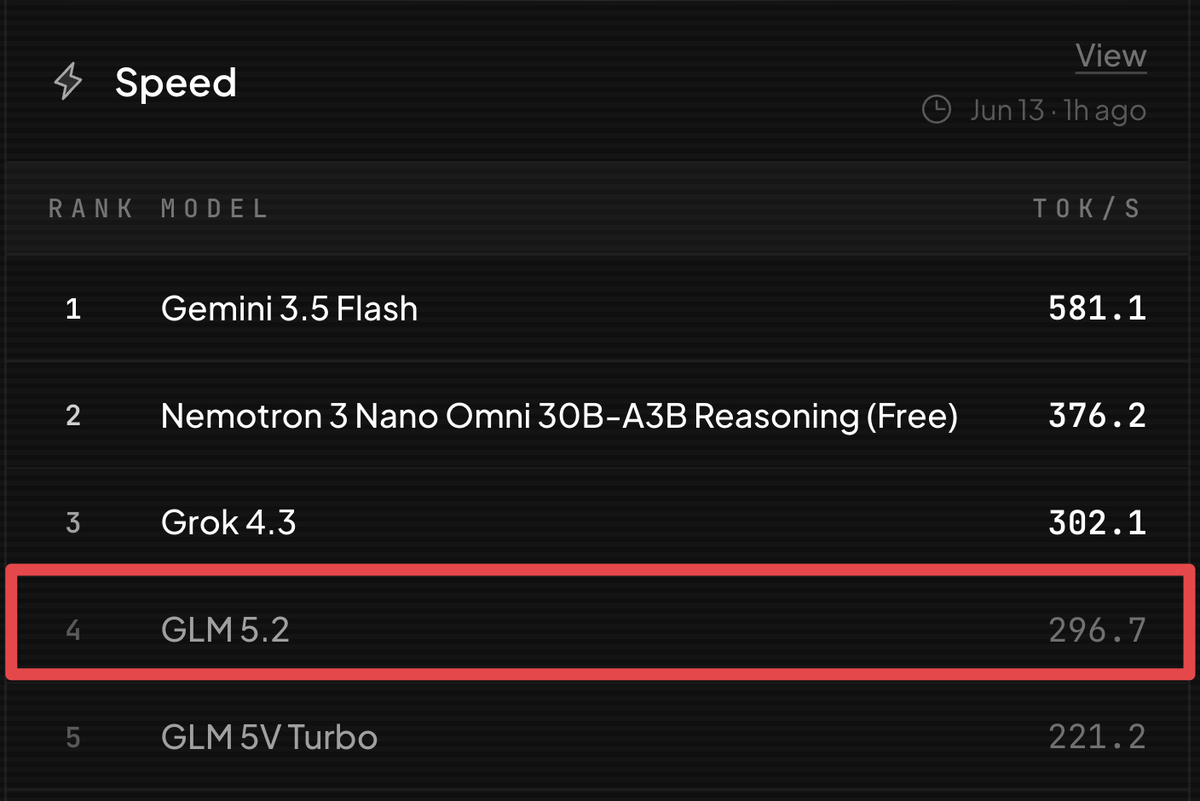
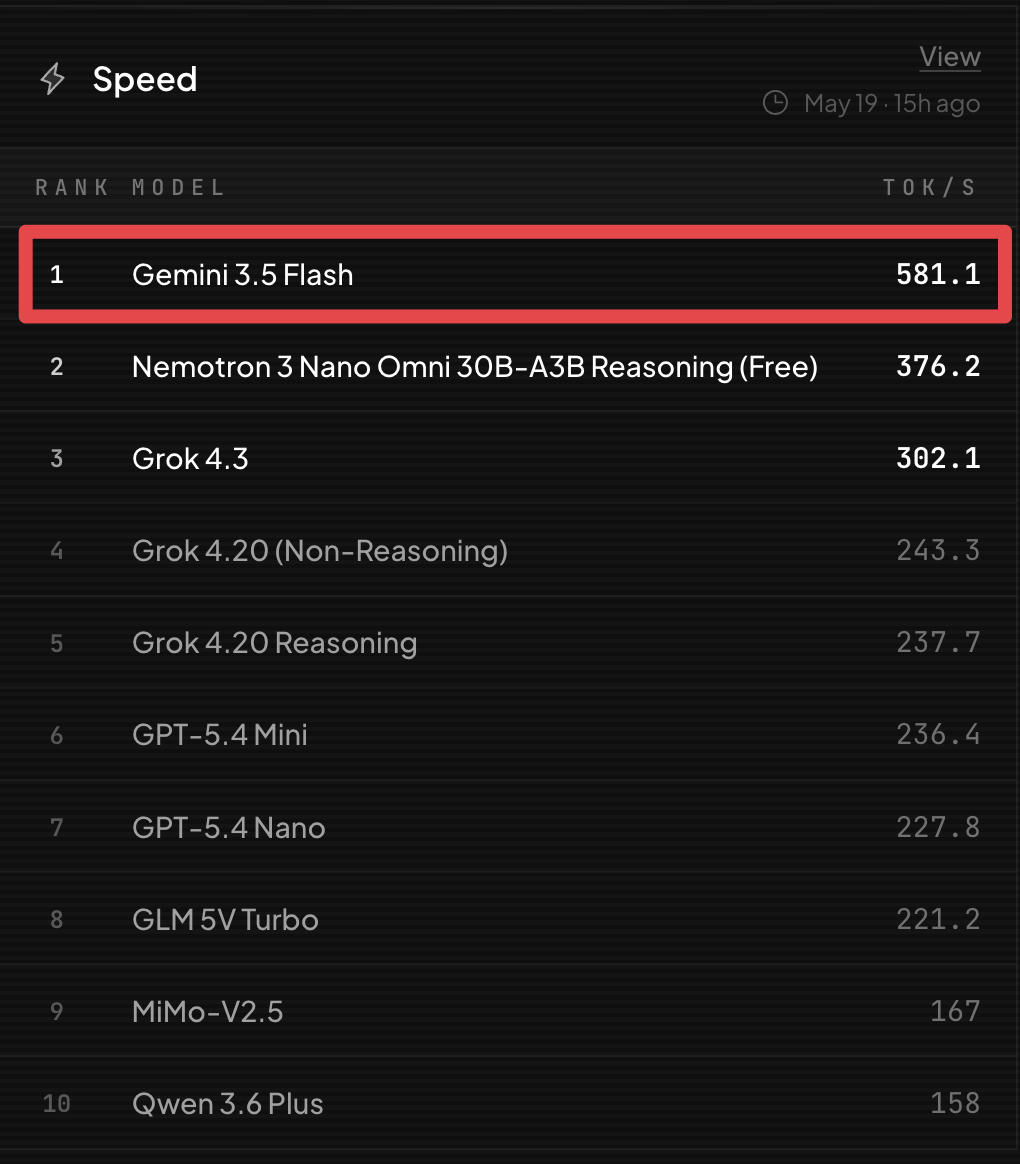
GLM 5.2 results just dropped in BridgeBench.
This is a significant jump up from GLM 5.1 in speed.
GLM 5.2 is 3x faster than GLM 5.1 and takes #4 on the BridgeBench speed benchmark.
Speed is becoming a critical factor when using AI and we have been VERY IMPRESSED by this leap.
13
13
218
16,417
Bridgebench retweeted
I tested GLM 5.2 on three real builds.
A horror house game.
A 3D stealth game.
A Remotion marketing video.
The results are exactly what I expect from Chinese open source coding models right now.
The horror house has broken game logic. Collect all three keys, complete the objective, and the front door still won't open.
The stealth game shipped with lighting so dark you can't see your own character.
The Remotion video is rough.
GLM 5.2 is faster than 5.1 and 10x cheaper than the frontier.
But Opus 4.8 and GPT 5.5 are still in a different league for serious coding work.
Chinese models keep missing the attention to detail that matters.
I MISS FABLE 5 ALREADY.
Full review live now.

Intelligence should be open, accessible, and ready to build with, empowering every developer, everywhere.
GLM-5.2 is now available to all GLM Coding Plan users, including Lite, Pro, Max, and Team plans.
docs.z.ai/devpack/latest-mod…
As our new flagship model, GLM-5.2 delivers powerful coding capabilities, usable 1M-context support, and continued strengths in long-horizon tasks.
API and Chatbot services will launch next week. The model will also be officially open-sourced next week under the MIT License.
The future of AI is open, and it belongs to the people.
22
8
187
19,363
GLM 5.2 benchmarks are coming

I just paid $65/month for the GLM Coding Pro plan to test GLM 5.2.
Last time I had a GLM plan it was under $35.
Z.ai has nearly doubled their pricing.
GLM 5.2 launched with no benchmarks, no public API, no chatbot.
The only way to access it is through this plan.
Charging twice as much for a model with zero published performance data is a bold strategy.
Testing it on BridgeBench right now.
Results coming.

8
1
97
8,708
Bridgebench retweeted
GLM 5.2 just dropped from Z.ai.
And the release is a mess.
No benchmarks. No API.
They released it on a Saturday in response to the US government banning Claude Fable 5.
The only way to touch it is their GLM Coding Plan.
A flagship model launch with zero performance data and a paywalled only entry point is not how you compete with Opus 4.8 or GPT 5.5.
It's how you hide a weak model behind a subscription.
Open source next week, supposedly.
Running it through BridgeBench the moment weights drop.
Intelligence should be open, accessible, and ready to build with, empowering every developer, everywhere.
GLM-5.2 is now available to all GLM Coding Plan users, including Lite, Pro, Max, and Team plans.
docs.z.ai/devpack/latest-mod…
As our new flagship model, GLM-5.2 delivers powerful coding capabilities, usable 1M-context support, and continued strengths in long-horizon tasks.
API and Chatbot services will launch next week. The model will also be officially open-sourced next week under the MIT License.
The future of AI is open, and it belongs to the people.
55
9
381
45,624
Bridgebench retweeted
Open Source AI has never been more important than it is right now.
The US government has complete control over AI.
With no warning they took away Claude Fable 5.
What else in the future will they take away from us?

47
13
316
13,797
Bridgebench retweeted

Jun 13
Anthropic has been ordered by the US government to suspend access to Fable 5.
WTF.
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
126
87
2,259
418,878
Bridgebench retweeted
Jun 12
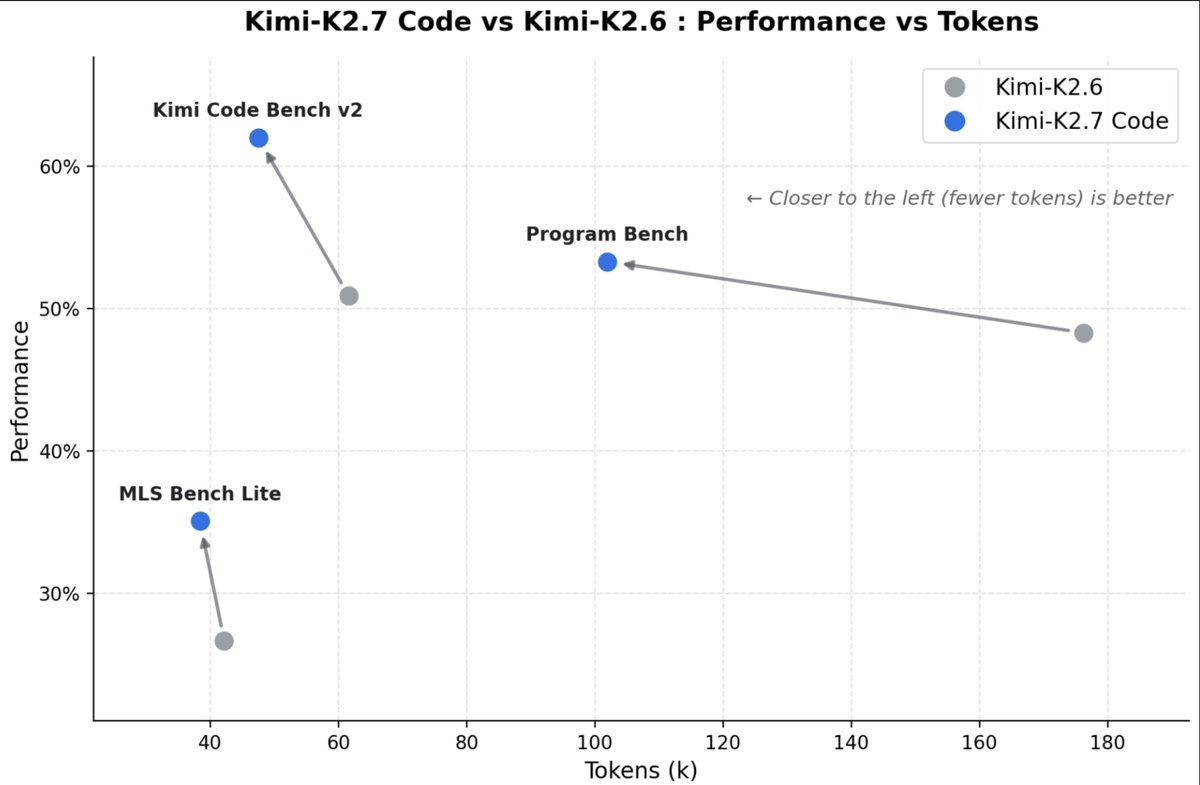
Kimi K2.7 Code scores higher than K2.6 on every benchmark while burning dramatically fewer tokens.
Program Bench: 48% to 53% while cutting token usage from 176k to 102k per task.
That's a 42% token reduction with a higher score.
Kimi Code Bench v2: 51% to 62%, using 23% fewer tokens.
Better answers with less thinking.
This is the efficiency curve everyone said open source couldn't hit.
Every token saved is money saved.
K2.7 isn't just smarter than K2.6.
It's cheaper to run on the exact same pricing.
19
15
273
12,891
Bridgebench retweeted
Jun 12
GPT 5.6 is releasing next week from OpenAI and will be positioned as a cheaper alternative to Fable 5.
Codex is not the same without the 2x promo.
OpenAI is losing subscribers to the launch of Fable 5.
Pricing is the only way that OpenAI can compete now.
62
10
513
41,917
Bridgebench retweeted
Jun 12
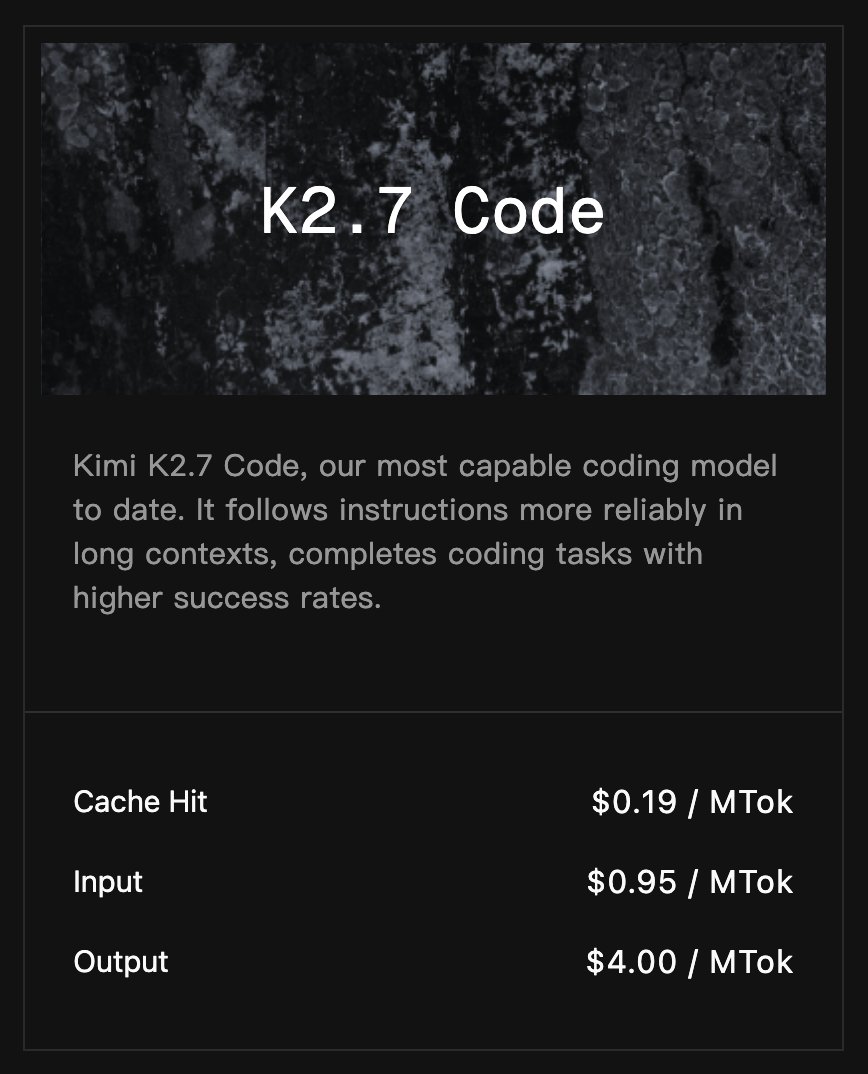
Kimi K2.7 Code just dropped.
And it might be the best open source coding model in the world.
Open weights. Free to run locally.
$0.95 per million input tokens via API.
Fable 5 and GPT 5.5 cost multiples of that for the same coding work.
Western labs charge premium prices.
Chinese labs give the weights away.
BridgeBench results drop today.
49
43
860
47,707
Bridgebench retweeted
Jun 11
Claude Fable 5 is so good that I had it build a feature in BridgeSpace that allows me to connect all of my $200 Claude Max subscriptions and switch between them in a single click.
If you are a Claude power user with multiple subscriptions... this is for you.
Official demo coming tomorrow.

42
11
329
19,389
Bridgebench retweeted
Jun 11
GPT 5.6 drops as soon as next week.
Insiders say it competes with Claude Fable 5 at a fraction of the price.
If true, this changes everything.
Fable 5 is the best model in the world right now and people are burning through $200 Max plans in 30 minutes to use it.
A cheaper equal would break Anthropic's pricing overnight.
Next week is going to be insane.
109
48
944
63,192
Bridgebench retweeted
Jun 11
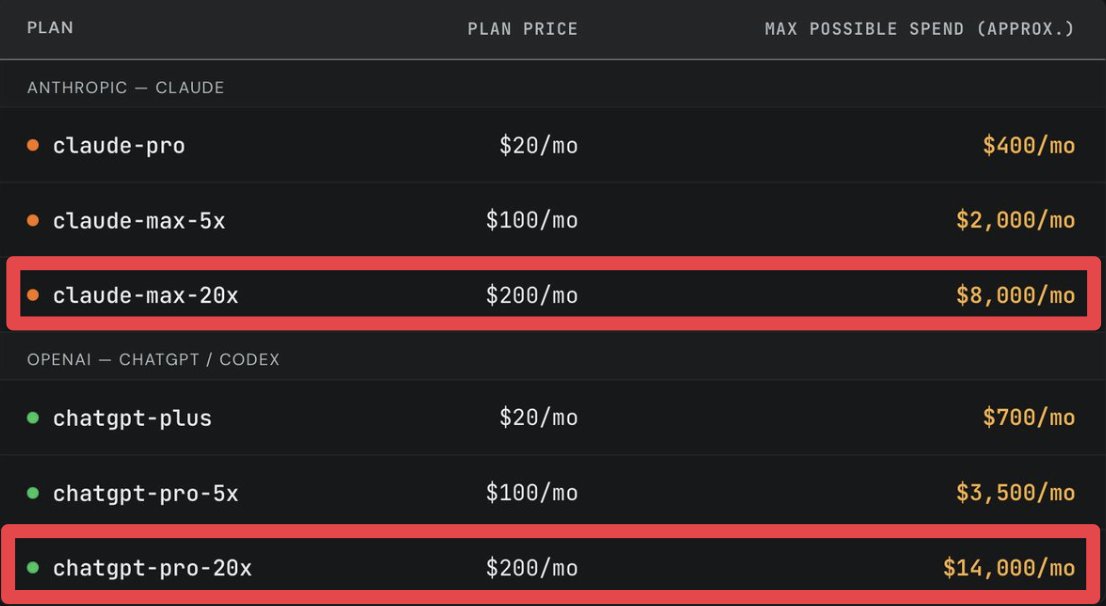
You are not paying for AI.
You are being subsidized.
$200/month Claude Max 20x gets you up to $8,000/month in API compute.
That's 40x what you pay.
$200/month ChatGPT Pro 20x gets you up to $14,000/month.
70x what you pay.
Anthropic and OpenAI are lighting billions on fire to win developers.
This is not scalable.
The rate limit "adjustments" we keep seeing are the rugpull starting in slow motion.
Enjoy it while it lasts.
157
42
784
54,084
Bridgebench retweeted
Jun 10
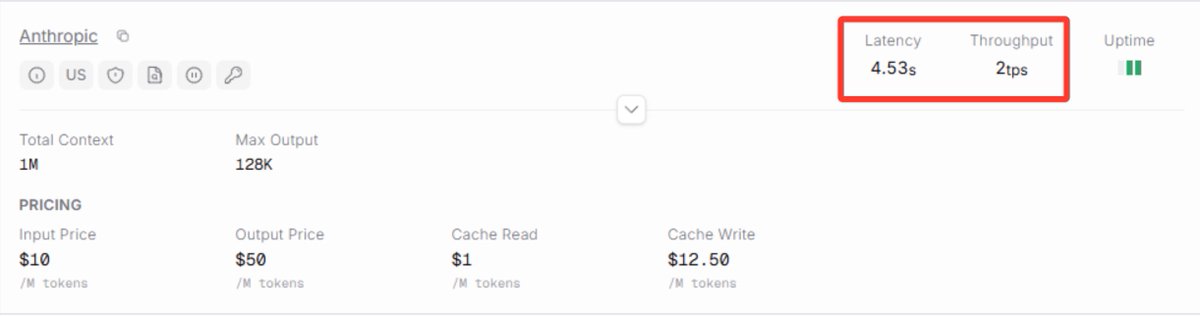
Claude Fable 5 is currently running at 2 tokens/second.
@elonmusk please help @AnthropicAI.
This model benefits humanity.
31
13
660
39,770
Bridgebench retweeted
Jun 10
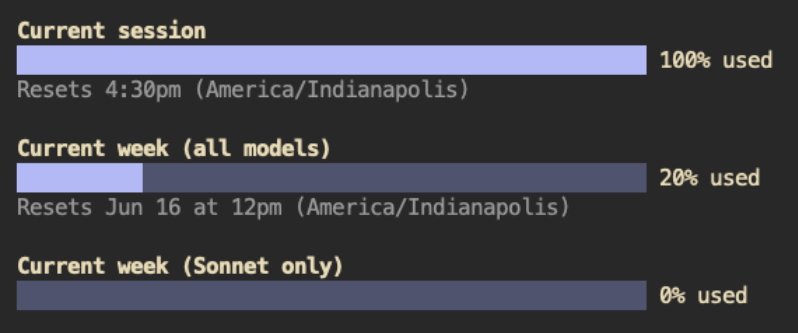
A $200 Claude Max subscription lasts 90 minutes using Claude Fable 5.
Do not use subagents when using Claude Fable 5.
That is what drains your usage.
With 3 Claude Max subscriptions I can vibe code in my normal vibe coding workflow with no limits using Claude Fable.
How are you feeling about the usage limits?
80
11
310
31,302
Bridgebench retweeted
Jun 10
Day 191 – Vibe Coding an App Until I Make $1,000,000 | ARR: $211,044 x.com/i/broadcasts/1nJOLLzBO…
1
2
52
4,652
Bridgebench retweeted
Jun 10
Claude Fable 5 access will be removed from Claude plans on June 23.
Anthropic says that as soon as they have sufficient capacity they will restore access.
Let's take advantage of Fable 5 while we can.

36
13
430
16,840
Bridgebench retweeted
Jun 10
Claude Fable 5 makes new things possible.
I one shot a full horror game with it.
One prompt.
I have never seen AI output a game like this.
This is the leap I've been waiting for.
80.3 on SWE-Bench Pro vs Opus 4.8 at 69.2, the biggest jump I have ever seen on that benchmark.
It passed GPT 5.5 in both coding and intelligence on Artificial Analysis.
I already canceled my $200 ChatGPT Pro plan.
It fixed a Bridge Voice bug in one shot that GPT 5.5, Opus 4.7, and Opus 4.8 all failed to crack for 2 months.
10/10.
Best model I have ever used.
Full review below.

Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
38
12
222
18,638

Jun 10
Claude Fable 5 makes GPT 5.5 look like a joke.
Jun 10
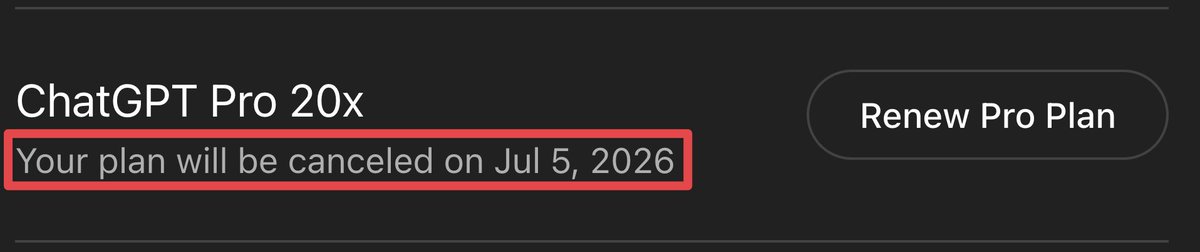
I just cancelled my $200 ChatGPT Pro 20x plan.
GPT 5.5 is garbage compared to Claude Fable 5.
OpenAI shouldn't even release GPT 5.6.
They are going to need to release GPT 6 or a new class of model to come anywhere close to Claude Fable 5.
I am buying a 4th $200 Claude Max subscription now.
27
2
127
9,771
Bridgebench retweeted
Jun 9
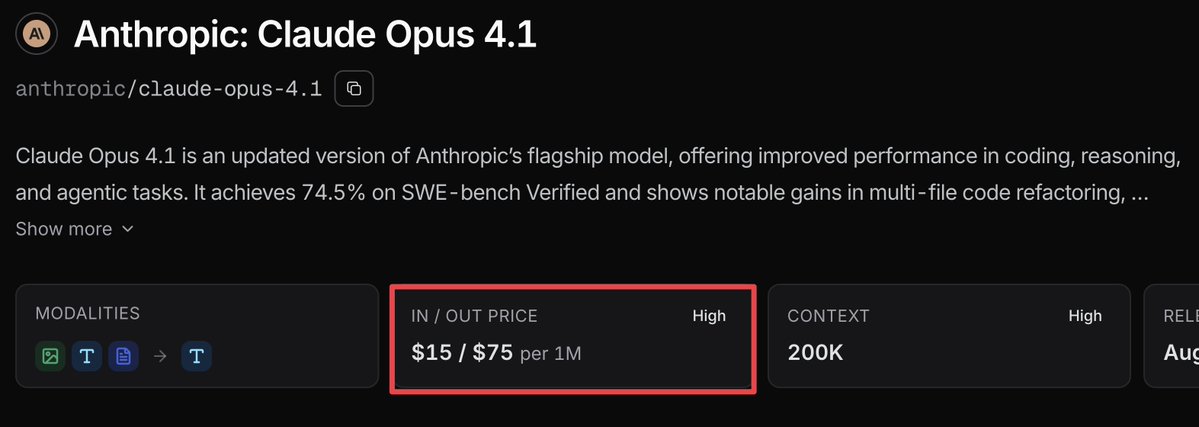
Claude Fable 5 is CHEAPER than Claude Opus 4.1 was.
Don't forget this era of vibe coding.
I remember using Claude Opus 4.1 as my daily driver.
I am thankful that Anthropic isn't charging $25/$125 for Fable 5 which I was expecting.
Claude Fable 5 isn't so poorly priced after all!
40
18
597
40,971