
Joined October 2007
- Tweets 3,128
- Following 4,876
- Followers 5,459
- Likes 6,535
103 Photos and videos




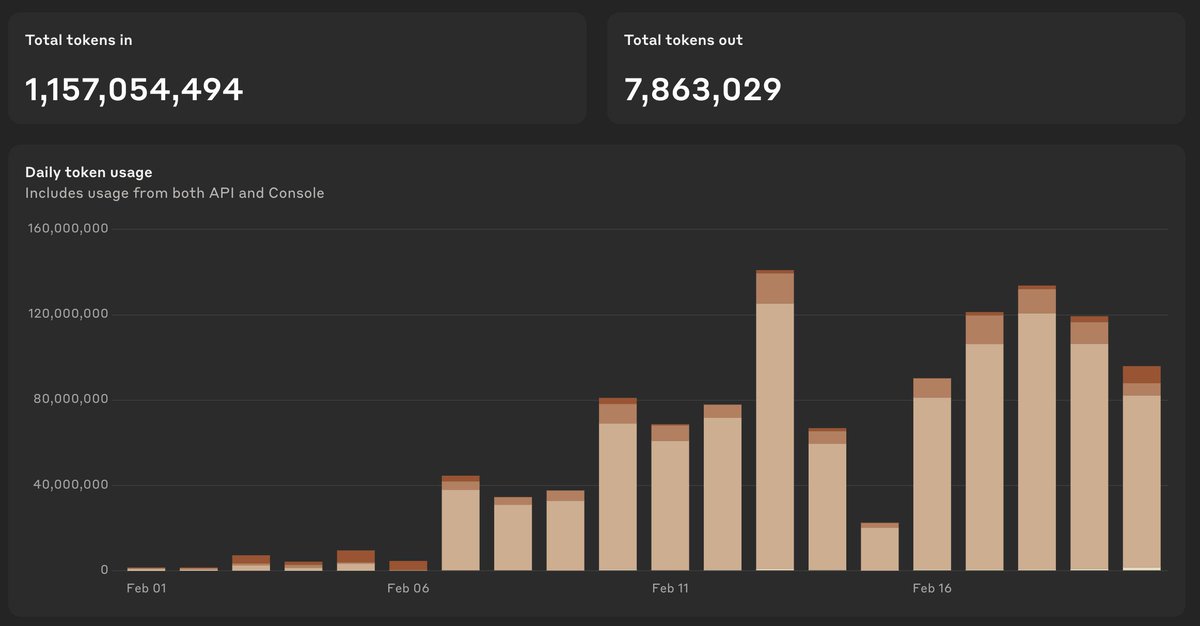





Pinned Tweet

15 Mar 2025
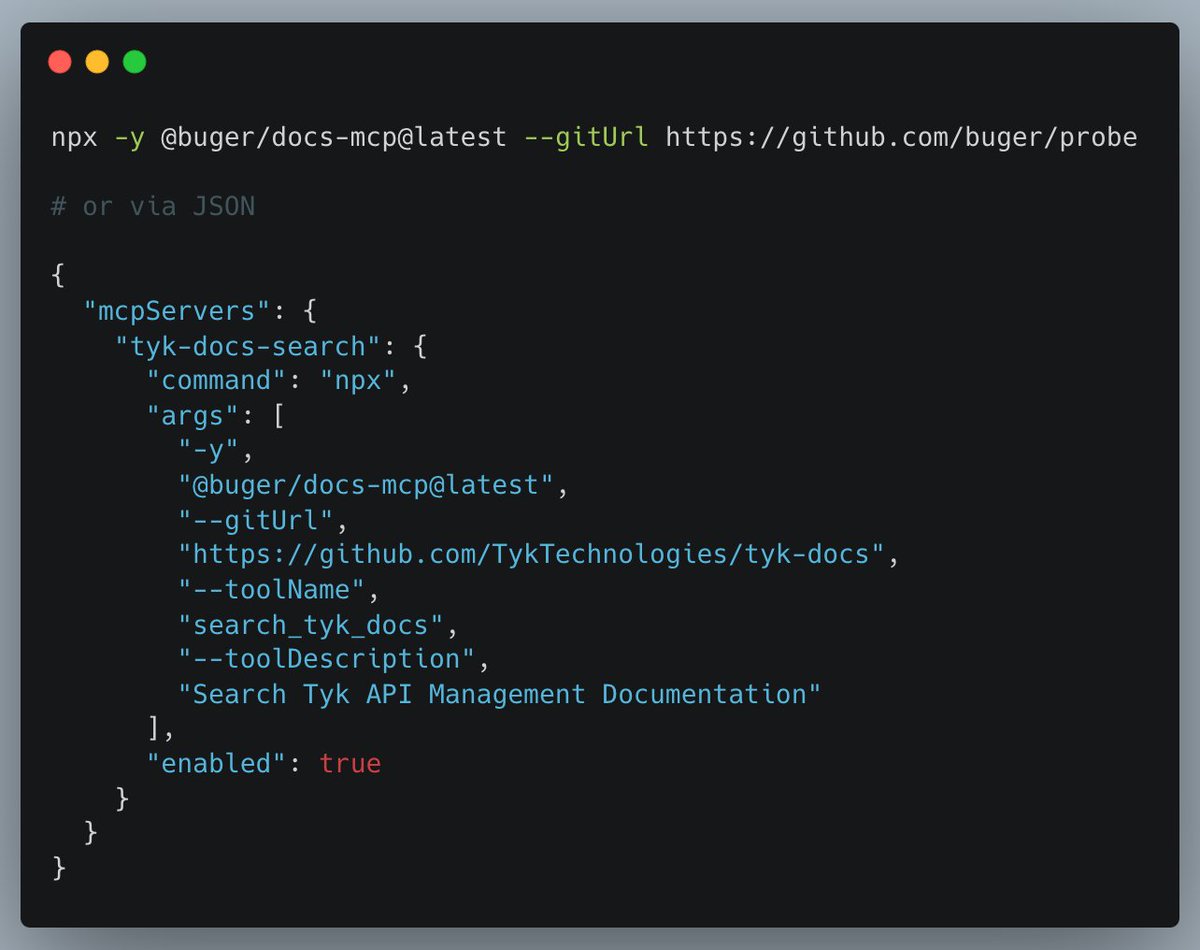
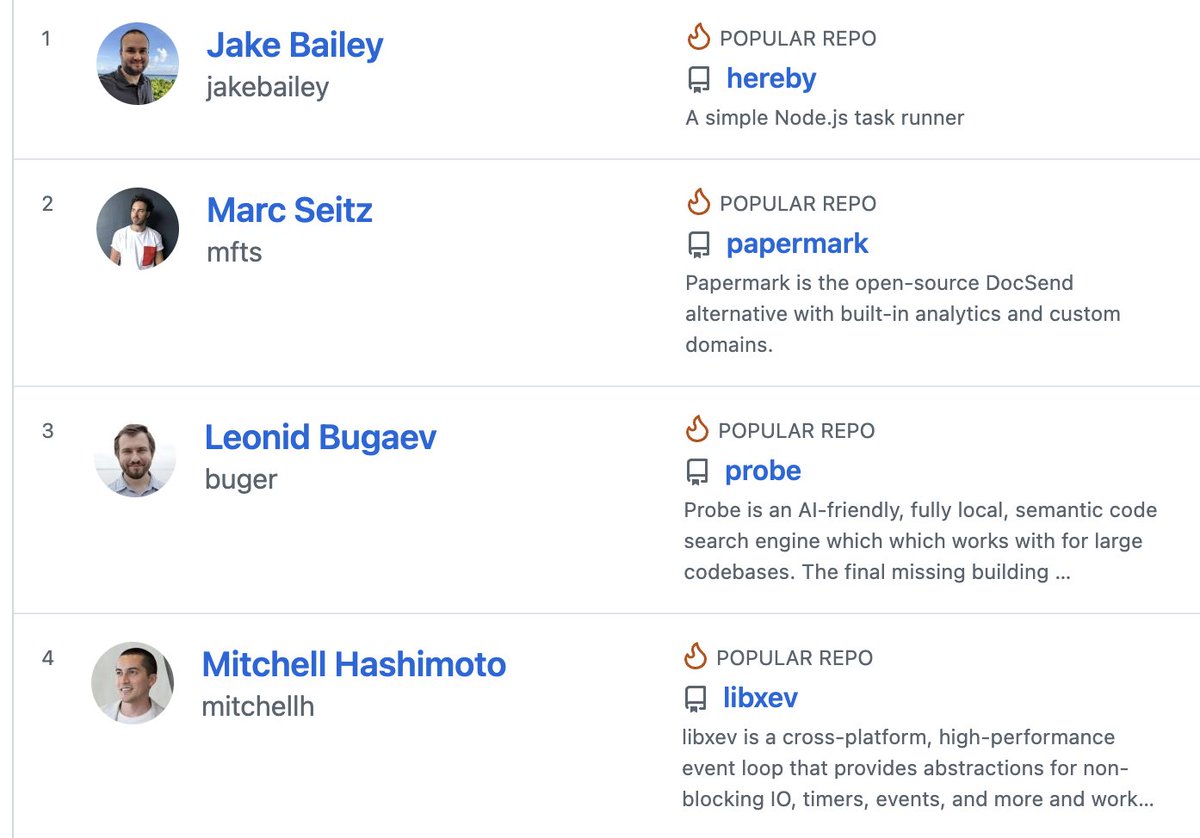
Have become top 3 trending developer on Github, with @mitchellh right behind me 😱
2
2
24
12,756
May 28
Imagine your source code goes public tomorrow. How would you feel? GitHub lost 3,800 repos last week to one poisoned VS Code extension. AI now reads codebases faster than you can. Security by obscurity is dead. What will be our answer?
2
190
May 24
Participated in #dailydevhackathon
Have build 2 ideas so far!
1) Source Bias Atlas
A 2D map of 1,361 dev sources clustered by stylistic personality. 5 views: engagement, volume, hype, title-style. UMAP for tribes.
buger.github.io/source-bias-…
2) Source Originality Score
Who breaks each story first on daily.dev?
Leaderboard of scoopers vs echoers. Per-topic timelines showing lag-to-echo.
buger.github.io/source-origi…
2
103
May 18
I have this personality split issue, maybe someone had the same, and can give advice.
I always was building smth on the side and a few bootstrapping attempts (right now an active one). Big part of it is a marketing. When you just a reader, it is relatively easy to consume (and judge), but when you have to market it, you need to be on LN, X, HN, Reddit, not just as creator but treat all this almost as a "job", turn it into a coversion machine, and sometimes without acknowledging, turning every conversation to your own "promo", and everywhere see the conversion funnel. Even when you are not on the platforms above, and just talking to someone.
And modern marketing standards are quite brutal too, you need be everywhere, stick to the schedule, show up every day. Polish your profiles, target the right keywords, have social media monitoring enabled and so on.
Another side of it, is also being afraid to post what you "actually" think on some of the topics. I may post on some trendy topic to get some traffic, but internally be very conflicting about it. Or being afraid to post smth too direct or smth which can be considered offensive - which can follow you back (you = your business/your employee), after some time.
Anyone found a way how to find this ballance? Feels like you almost need to develop dissociative identity disorder on purpose, to split your identity, and just "be" yourself in some situations or communities, whatever it means.
39
May 18
I have this personality split issue, maybe someone had the same, and can give advice.
I always was building smth on the side and a few bootstrapping attempts (right now an active one). Big part of it is a marketing. When you just a reader, it is relatively easy to consume (and judge), but when you have to market it, you need to be on LN, X, HN, Reddit, not just as creator but treat all this almost as a "job", turn it into a coversion machine, and sometimes without acknowledging, turning every conversation to your own "promo", and everywhere see the conversion funnel. Even when you are not on the platforms above, and just talking to someone.
And modern marketing standards are quite brutal too, you need be everywhere, stick to the schedule, show up every day. Polish your profiles, target the right keywords, have social media monitoring enabled and so on.
Another side of it, is also being afraid to post what you "actually" think on some of the topics. I may post on some trendy topic to get some traffic, but internally be very conflicting about it. Or being afraid to post smth too direct or smth which can be considered offensive - which can follow you back (you = your business/your employee), after some time.
Anyone found a way how to find this ballance? Feels like you almost need to develop dissociative identity disorder on purpose, to split your identity, and just "be" yourself in some situations or communities, whatever it means.
42
May 14
The code runs. The code breaks. The code is what production uses.
Specs and docs can help, but they often become stale. So we learned not to trust them too much.
Code is honest in a way documents are not. It may be wrong, but it does exactly what it does.
But I think there was another reason we trusted code so much.
For a long time, code was manual work. We wrote it ourselves. We spent time with it. We were not only typing syntax; we were thinking through the system while writing it. The thinking and the implementation were almost the same activity.
That is why code deserved this level of trust. Not because code was perfect. It was not. But because the code carried a lot of the human judgement that produced it.
With agentic coding, this starts to change.
The code is still real. It still runs. But now the thinking can be distributed across prompts, specs, agent sessions, generated plans, reviews, and the human who is steering everything.
And if the thinking moved, maybe the source of truth moved as well. Or at least it became less obvious.
This is what I tried to explore in this article.
As an individual contributor, I can move incredibly fast with tools like Claude Code. I can start with a rough idea, steer the agent while it builds, change direction during implementation, and let the code teach me what the spec should have been.
I like this. A lot.
But it works best while the system still fits inside one brain.
The experienced person knows the edge cases, dependencies, fragile interfaces, strange behaviours, and old production scars. The agent is not really working from a complete spec. It is working with a human who carries the missing context.
But real systems grow. They get delegated. Teams split. People leave. New people join. Agents improvise. Humans improvise too.
If something was never described, why do we expect the agent, or another human, to implement it the way we imagined?
Maybe this is where requirements become interesting again.
Not as a new idea. Regulated industries already use requirements this way. It is normal for them to have large requirement sets which can be turned into multi-hundred-page documents. But underneath, it is not just one big document. It is a graph of requirements, sub-requirements, interfaces, tests, evidence, owners, dependencies, and links.
I do not think normal software teams need to copy all the heaviness.
But maybe agentic engineering makes some lighter version of this much more important.
Code is still the runtime truth. It tells us what the system does.
But requirement is the intent truth. It tells us what the system is supposed to mean.
And evidence is what connects them.
I do not have the full answer yet. But I think the real risk of agentic engineering may not be bad code.
It may be bad intent, implemented quickly.
1
70
May 11
When code becomes easy to produce, the hard part is remembering what we meant.
1
2
86
May 6
Reminder: green is not the same as correct.
Your tests can pass because they only check the behavior you remembered to describe.
The missing behavior is still missing.
That is where AI-generated code gets dangerous.
62
May 6
Something I keep thinking about:
Maybe AI is not exposing a new problem in engineering.
Maybe it is exposing an old one that we were already bad at.
We talk about AI like the bottleneck is still writing code.
But honestly, writing code has not been the hard part for a long time.
The hard part is all the surrounding context.
Why are we making this change?
Who asked for it?
Which customer depends on the current behavior?
Was this weird edge case intentional?
Is this a product decision or just an implementation accident?
Did security already review something similar before?
Is the documentation describing the current behavior or the behavior we wish we had?
And the uncomfortable part is that most of this context is not in one place.
It is all over GitHub, Slack, docs, tests, head of the engineer who left six months ago.
This was already a problem.
AI just makes it harder to ignore.
Because now we can create more code from less context, more tests, more docs, more confident explanations.
But if the context is incomplete, then all of that output is built on sand.
This is the part I find interesting.
Not “will AI replace engineers?”
I don’t think that is the most useful question.
The more interesting question is:
What happens when engineering teams can generate implementation faster than they can preserve intent?
Because that is where things get messy.
You can have a clean PR.
You can have passing tests.
You can have updated docs.
You can even have a very convincing AI-generated explanation.
And still nobody can answer the basic question: “Is this actually the right change?”
That question is much more expensive than people admit.
I have felt this many times in open source and infrastructure work.
You look at a small change and think, “This should be simple.”
Then you start pulling the thread.
There is a backwards compatibility issue.
There is some behavior that looks wrong but someone depends on it.
There is a test that protects the implementation but not the real promise.
There is a doc page that says one thing and production behavior says another.
There is a customer workaround that became part of the product without anyone naming it.
Suddenly the small change is not small.
And this is why I think “AI will make everyone ship faster” is only half true.
AI can make the creation part faster.
But creation is not the same as shipping.
Shipping means the organization understands the change well enough to stand behind it.
That is a different problem.
I don’t have the perfect answer yet.
But I think “AI coding” is the wrong frame.
The real problem is not coding.
The real problem is engineering memory.
And most teams’ engineering memory is held together with Slack search, old PR comments, and someone saying: “I think I remember why we did that.”
That does not scale.
1
85
May 5
Everyone is asking the same question now: if AI can help us create much more code, why aren’t engineering teams suddenly moving much faster?
I think the question is right, but the answer usually stops too early.
The expensive part is trust.
Can I trust this change? Does it match the intent? Does it break a hidden customer flow? Does it affect backwards compatibility? Are the docs updated? Are the tests proving the right thing? Did we think about security, performance, malformed input, error states, release notes, migration, support?
A pull request doesn’t answer all of this.
A pull request is just something asking to be trusted.
And the worst part, are the specs. We talk about flood of AI generated PRs, but rarely talk about applying AI for specs. Everyone does it now. For PRs we at least have verification workflows like CI/CD, for specs we have only hope that engineer reviewing it, actually spent time deeply think about it. The amount of subtle intent issues and scope bloat it introduce is the biggest threat.
In my new essay I try to get deep on how we can get the trust back, and actually scale engineering. And no, new shiny LLM model wont't save you - it require a boring work, with checklists and patience.
See link below
1
1
57
May 5
Subscribe to my substack newsletter where we will together navigate on where our industry is going: blog.reqproof.com/p/engineer…
24
May 4
While trying latest DeepSeek model, I hit a wall while paying for it.
Neither Paypal or builtin card processing just does not work for my Turkish debit card.
In matter of few minutes, I downloaded Alipay, connected there card, and paid using it ¥ - process was so much smoother.
This is how you win the market and build economy.
1
1
162
Apr 30
I have hit this too many times: near 100% standard code coverage, and still a steady stream of bugs.
At some point the interesting question is not “why did we miss a test?”
The more interesting question is: “why did we never describe this behavior in the first place?”
Malformed input. Boundary cases. Timeout behavior. Retry behavior. Permission edge cases. Data that is technically valid but semantically weird. Two flags that should never be true at the same time, but eventually are.
A lot of painful bugs live there.
Not because engineers are lazy. Not because nobody writes tests. But because the expected behavior was never made explicit enough to be tested deterministically.
Standard line coverage does not help much with this. It tells you that a line executed. That is useful, but very limited.
It does not tell you whether the important condition was tested.
It does not tell you whether the boundary was tested.
It does not tell you whether malformed data was considered.
This is why I think the real problem is not “we need more tests.”
The real problem is that most teams do not have a durable source of truth for how the system is supposed to behave. The truth is scattered between code, tests, Jira tickets, Confluence pages, old PR discussions, and the head of the engineer who remembers why it was built this way.
So when bugs happen, we treat them as implementation misses. But very often they are specification misses.
We forgot to say what should happen.
And if we never said it, we should not be surprised that our tests did not prove it.
1
2
123
Apr 30
I have started a weekly newletter on closing the verification gap and bringing back trust to the software we build blog.reqproof.com/p/i-had-ne…
42
Apr 29
My library jsonparser got a public CVE. The function that broke had 100% test coverage.
You cannot test for what you never described.
I wrote about what happened next 👇
1
2
163
Apr 29
What changed for me: I stopped treating tests as the source of truth. AI can write tests too. A passing test proves the code agrees with the test. It does not prove both agree with my intent.
1
14
Apr 29
The full story, from the CVE wake-up to NASA's open-source tools to applying this to an enterprise codebase:
blog.reqproof.com/p/i-had-ne…
66