
83 Photos and videos



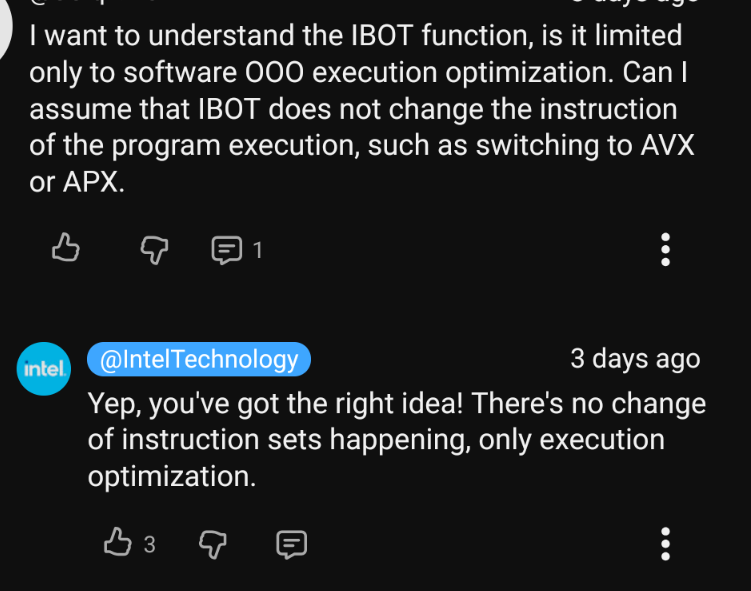
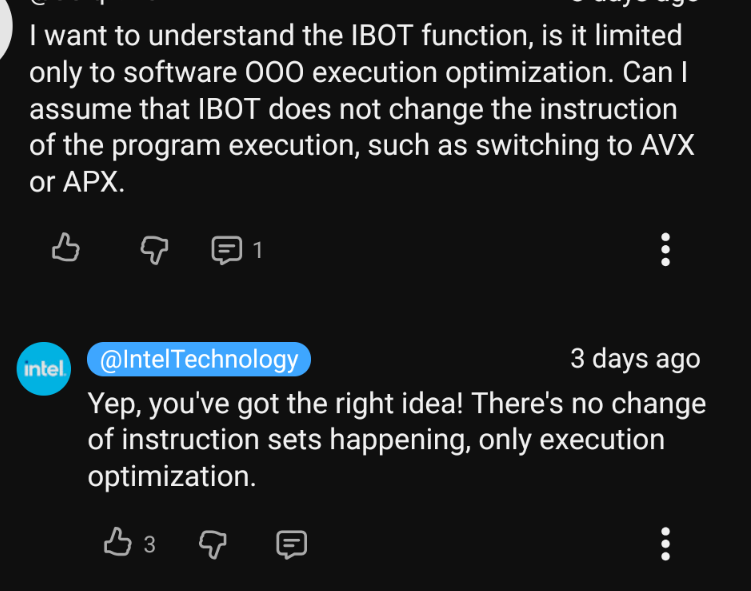



yes, this is good, more of that please
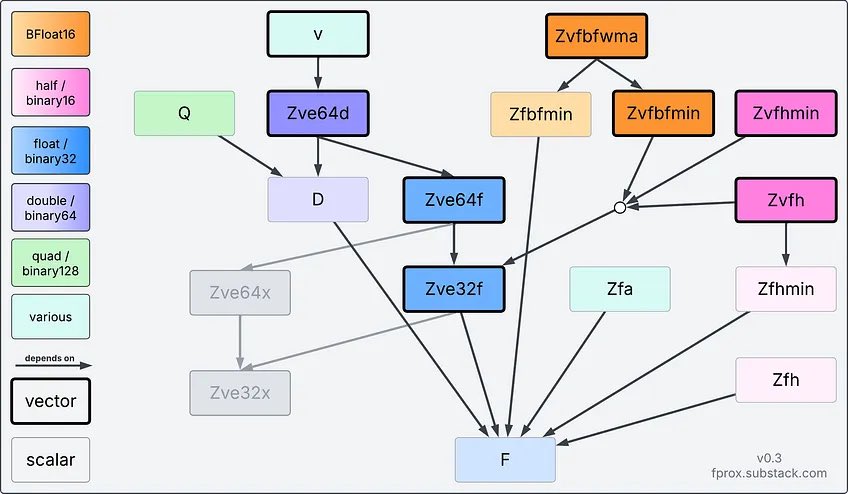
This is a lot better than the alternative of a bunch of people crating their own incompatible subsets.
May 20

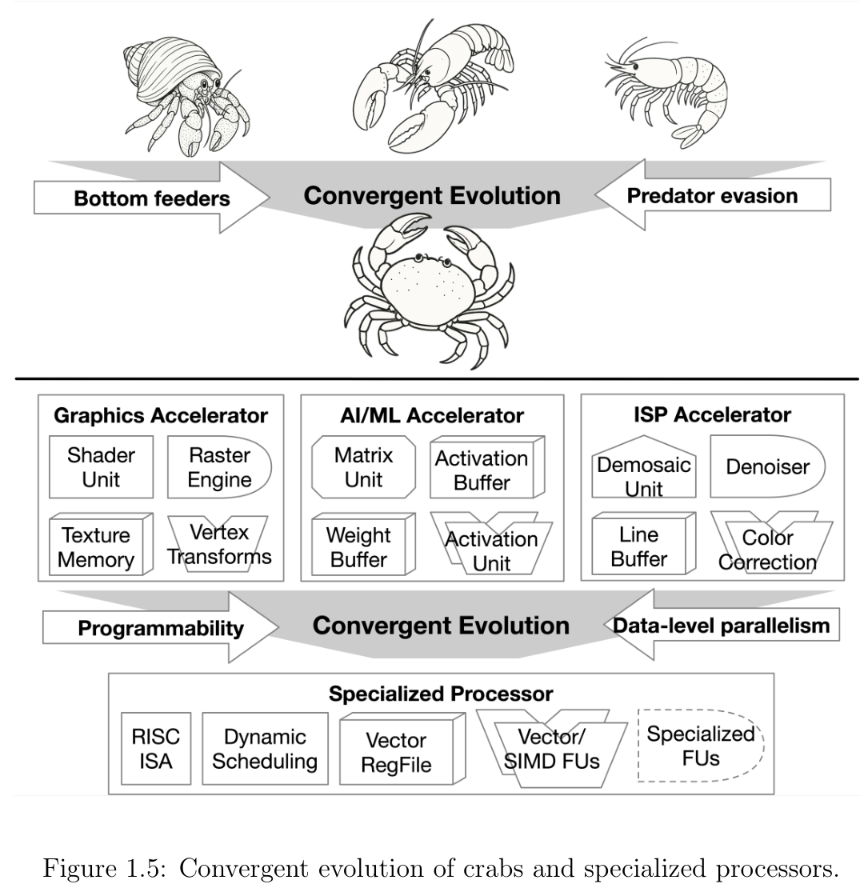
Someone looked at the overlapping mess of AVX512 extensions and thought “yes, that is good, more of that please”
2
2
299
@FelixCLC_
I tested the impact of disabling RVC on the SpacemiT X100 4-wide OoO core with clang.
Enabling RVC resulted in a roughly 10% performance improvement.
Not sure what this actually tells us about RVC exactly, but it's certainly interesting.
3
8
883
camel-cdr retweeted

Mar 29
I have added latency, throughput, and port usage data for Emerald Rapids, Meteor Lake, Arrow Lake, and Zen 5 to uops.info/table.html.
7
45
231
37,945
The RVP spec is coming along: github.com/riscv/riscv-p-spe…
Here is a untested implementation of JPEG upsample in RVP: godbolt.org/z/r5bGGPsj5
This uses the current draft intrinsics. With the overloaded ones this will be less verbose. __riscv_preinterpret is still way to long IMO.
3
10
1,190
The problem with mixing scalar and SIMD today, is that you need to be conservative with the number of scalar elements processee, because if the scalar iteration is slower than the SIMD one, the SIMD has to wait. With s1first you wouldn't have to wait, if one path is faster.
1
6
203
camel-cdr retweeted

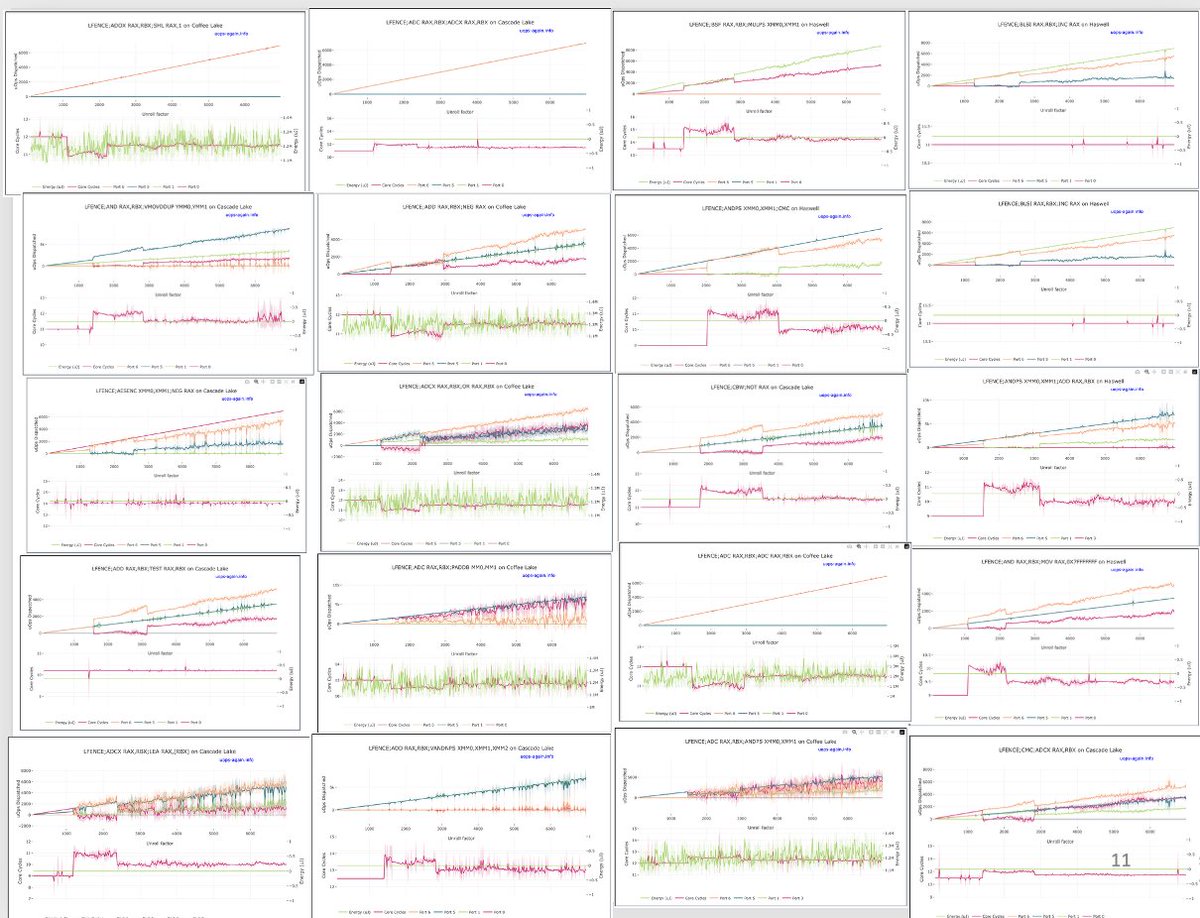
Today at uASC'26 we introduced uops-again.info, a website documenting corner-case behaviours of port assignment on Intel processors. Joint work with Yarin Oziel, Tomer Laor, Shlomi Levy, @BloodyTangerine , Yossi Oren, @ThomasRokicki and Gabriel Scalosub
2
10
826
PR: github.com/simdjson/simdjson…
codegen looks solid: godbolt.org/z/WY68vEbhh
I'm getting 2-3x speedup on the SpacemiT X60.
199
And here it is: camel-cdr.github.io/rvv-benc…
rvv-bench on the first RVA23 hardware, which runs ubuntu 26.04 btw.
I don't personally have access, but sanderjo ran it for me. Some of the dav1d folks also have access and have started testing their optimizations.
Jan 13

> Fully RVA22 compliant, and “Compliant with RVA23 excluding V extension.”
Where is the RVA23 hardware? Is RVV even remotely good enough to justify making it mandatory?
4
12
1,382