Workshop your ideas into reality, in the Cloud and on your Desktop
Joined April 2007
- Tweets 2,773
- Following 645
- Followers 336
- Likes 191
99 Photos and videos












Cool idea @MaziyarPanahi @googlegemma
Here is a demo you can play with
Gemma 4 Sam 3.1 running all on a Mac via MLX
Build with @WorkshopAI
Repo 👇
Apr 10

Gemma 4 looks at a parking lot. Decides what to ask. Calls SAM 3.1.
"Segment all vehicles." 64 found.
"Now just the white ones." 23 found.
One model reasoning and orchestrating. One model executing.
Both running locally on a MacBook. MLX. No cloud. No API.
1
3
5
1,319

chilang retweeted
3
15
2,098
chilang retweeted
.@Benioff makes the pitch for @RaylineAI flawlessly.
Every part is there ...
- intelligent model routing,
- routing across cloud and on-device,
- the immediate focus on coding but the broader need beyond ...
Added some callouts for clarity :)
1
2
5
238
chilang retweeted
1
5
19
6,559
chilang retweeted
Claude Code's API rates are 8-10x more expensive than its subscription rates.
Most of those tokens are wasted spend.
We built @RaylineAI to fix that.
Rayline is a model router built specifically for Claude Code. You plug it in, and subagents get routed to open source and on-device models. Use Opus as your main agent overseeing grunt work delegated to open models. Quality holds. Costs drop 60-90%.
The key insight: model routing belongs at the API layer, not the harness layer. Harnesses are converging. LLMs are becoming interchangeable. The control point is the gateway, and that's where enterprises need to manage spend without forcing teams to adopt new tools.
What makes Rayline different from other routers:
- Built specifically for Claude Code
- Routes at the subagent/subtask level
- On-device routing via MLX (Qwen 3.6 and others)
- Built-in ML router trained for Claude Code tasks
We've been thinking about this problem for a long time. We built model routing into @WorkshopAI months ago. Others launched similar things last week.
Rayline is the first of its kind: a router built from the ground up for the coding agents you already use.
We're already routing billions of tokens per day for individuals and publicly traded companies.
Try it at Rayline[.]ai
(p.s. Codex is next!)
1
2
2
300
chilang retweeted
This is the exact thesis behind @RaylineAI
Route subagents to open models (and on-device), while letting users choose Opus/GPT 5.5 (or any of the "open frontier" models) for the main agent.
This type of model routing needs to live at the LLM gateway API layer ... use whatever harness you want, and whatever model you want

Good take
My guess is
- demand for intelligence is near infinite
- but 80% of workloads will be running on 99% cheaper models within 12-18 months
- 20% of workloads will still run on latest gen models where IQ maxing is important (scientific breakthroughs, higher level ochestrator agents?)
- rough analogy might be what % of macbooks or gaming PCs sold have the maxed out specs for CPU/GPU, prices are falling much faster than Moore's law here though
- this leads me to think the limiting factor will be energy and compute, not better models
At Coinbase we're working hard on routing prompts to cheaper models where appropriate, and in some cases have been able to keep costs roughly flat, while token usage continues to grow exponentially.
1
124
chilang retweeted

May 20
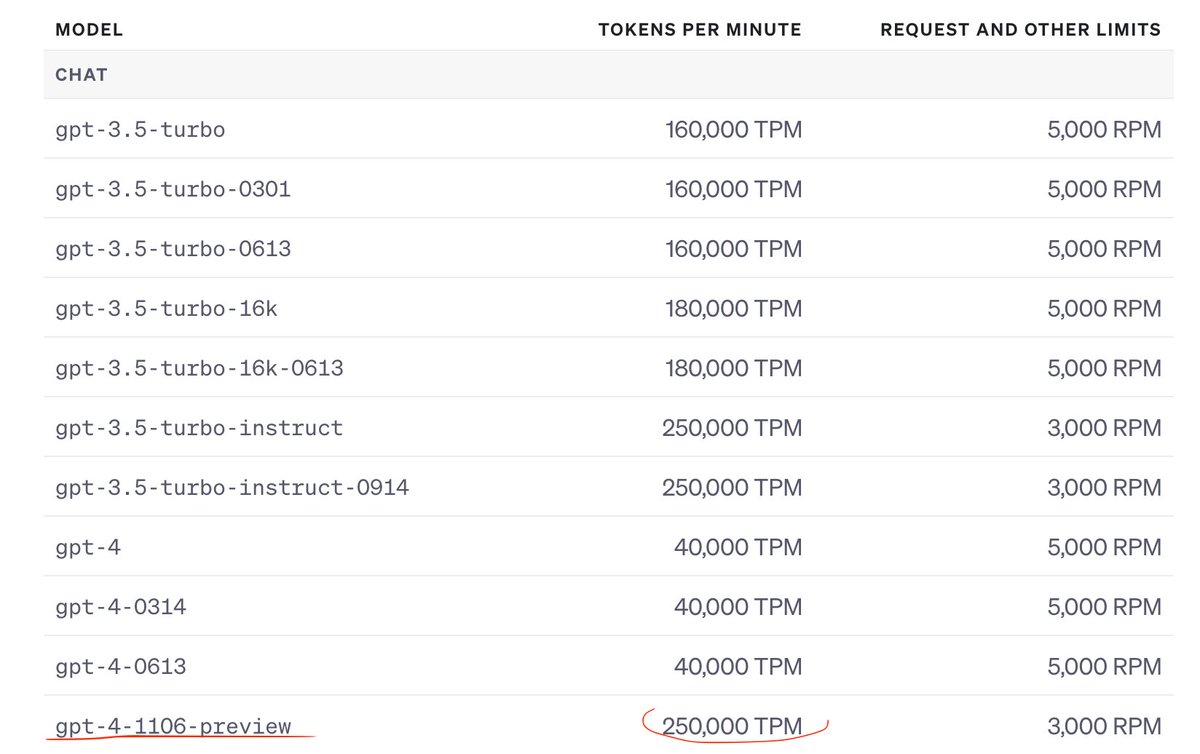
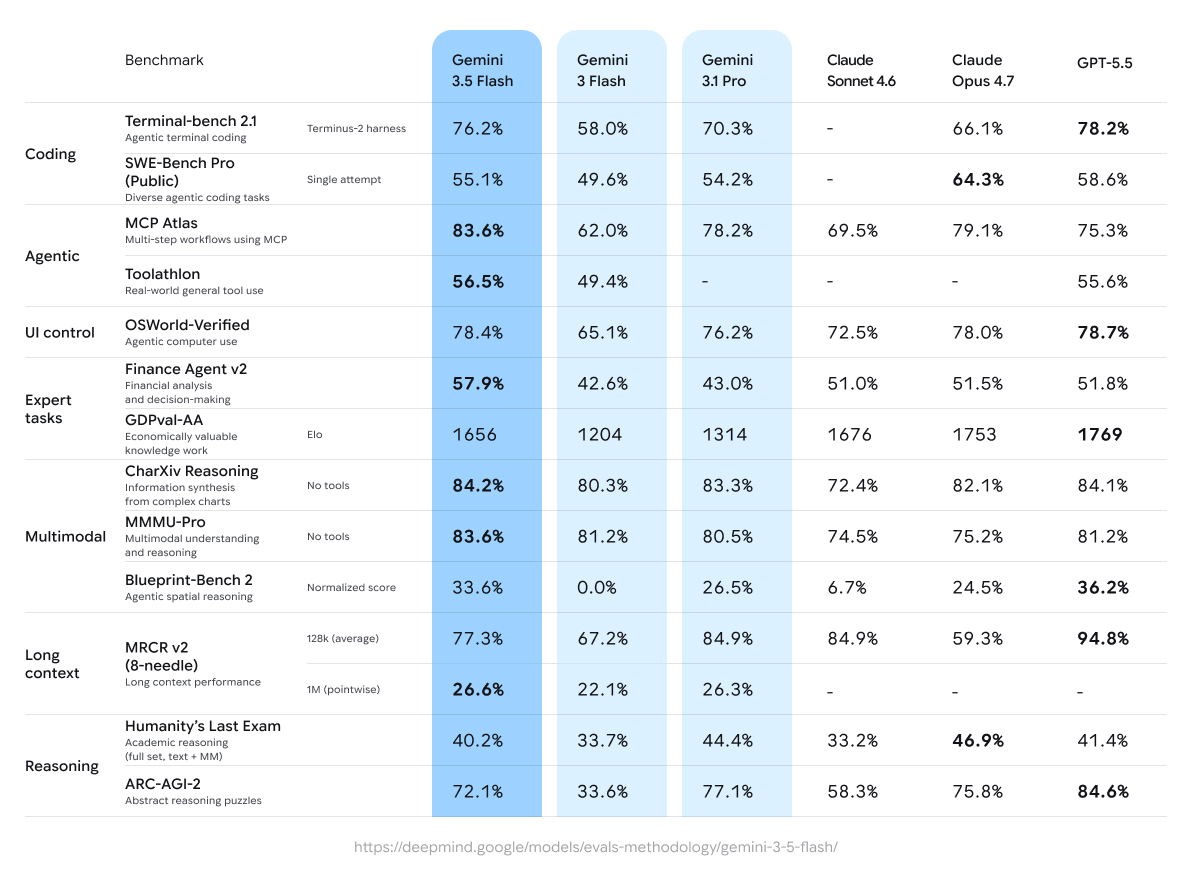
Gemini 3.5 Flash is now in Workshop.
Free for every paid plan today only!
Unmetered until 11:59 PM UTC ⏳
Go build something amazing!

May 19

Welcome to Gemini 3.5 Flash, our most powerful model to date. It pushes the frontier of intelligence, speed, and cost putting 3.5 Flash in a class of its own.
We spent the last 6 months making sure Flash is great for real world use cases. It's available everywhere now!
4
5
192
chilang retweeted
May 12
Gemini is free on Workshop for Max subscribers from May 12–20!
Use Gemini for apps, workflows, internal tools, dashboards, agents, image tools, and more.
Available for both existing and new Max subs.

3
4
19
413,018
Money above glory
May 10

It's weird that the US still doesn’t have a truly competitive open-source model lab.
It’s clearly not a money problem. Several neolabs have raised billions.
It’s not a compute problem. US labs have easier access to B200s/B300s than Chinese labs.
So what is the issue?
1
39
chilang retweeted

Want to win an election? Change your name.
Live data from London's #electiontresult2026 shows candidates higher in the ballot get more votes than their party colleagues in the same ward 72% of the time.
17 candidates so far that missed out on a seat:
ballot-order.workshop.build
1
4
5
1,150

chilang retweeted
May 1
Prompt-to-app is table stakes.
The hard part is what comes next: backend, data, APIs, auth, services, jobs, infrastructure.
Workshop is for building real software.
4
7
372
chilang retweeted
❤️
you can also download and use Gemma 4 models for subagents in @WorkshopAI.
A favorite setup of mine is to use Gemini 3.1 Pro for the main agent and Gemma 4 31b for subagents on my M4 Max.
1
10
2,845
chilang retweeted
Apr 24
Want to build with AI for free?
With local models in Workshop, you can build websites, dashboards, internal tools, workflows, prototypes, and more.
That means:
- Zero API costs
- Offline access
- Full privacy
Try local models today in Workshop Desktop.
5
3
29
652,468
chilang retweeted
Apr 21
You don’t have to use one model (or one provider!) for everything.
With Workshop, you can combine frontier and local models in the same workflow.
For example: Opus can be the main agent, and delegate specific tasks to Gemma 4 via subagents.
Better quality where it matters. Better privacy, speed, and cost where it counts.
One workflow, best model for each task.
3
8
19
818,282
chilang retweeted
Apr 17
Opus 4.7 is now live in Workshop!
(Prefer to stick with Opus 4.6? No problem, it’s still available as well😉)
1
1
6
292
Cool idea @MaziyarPanahi @googlegemma
Here is a demo you can play with
Gemma 4 Sam 3.1 running all on a Mac via MLX
Build with @WorkshopAI
Repo 👇
Apr 10
Gemma 4 looks at a parking lot. Decides what to ask. Calls SAM 3.1.
"Segment all vehicles." 64 found.
"Now just the white ones." 23 found.
One model reasoning and orchestrating. One model executing.
Both running locally on a MacBook. MLX. No cloud. No API.
1
3
5
1,319