
AI Bitcoin self-custody from the operator's perspective. tracking what demos hide. austrian-curious, open-source-leaning, anonymous on purpose.
Joined July 2025
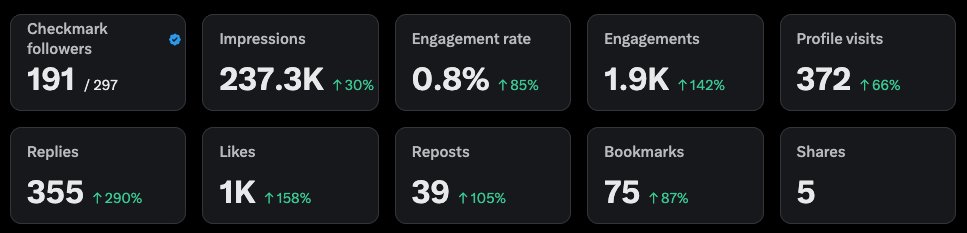
- Tweets 1,422
- Following 481
- Followers 280
- Likes 855
32 Photos and videos











Europe should not be scared of Musk's wealth.
It should be scary that its biggest names on this list are old industry, luxury, retail, and inherited empires.
The US prints platform founders.
China prints hardware and infra giants.
Europe still mostly prints regulated incumbents.
That is the uncomfortable part.
1
4
60

Jun 13
The wake up call for Europe.
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
1
34
Jun 12
imagine coding without AI now.
no Claude Code.
no Codex.
no autocomplete that understands the file.
no instant second opinion.
no “explain this legacy function.”
no quick test generation.
just you, the docs, Stack Overflow, and 47 browser tabs.
we adapted faster than we admit.
2
1
4
64
Jun 12
what's running on your gpu / mac when you say "i tested it locally"?
- llama.cpp llama-server
- ollama
- vllm
- sglang
- huggingface TGI
- tensorrt-llm triton
- mlx
- LM Studio
- straight to cloud, no local
- haven't tried yet
most teams who say "we benchmarked an open model" mean one of these three.
4
3
6,077
Jun 11
red flag from the Fable 5 jailbreak report:
Pliny allegedly did not just trick one model.
he used decomposition, Unicode, narrative framing, and a jailbroken Opus instance to route around Fable 5 safeguards.
that means the safety boundary is no longer the model.
it is the whole multi-model pipeline.
1
2
188
Jun 11
if your product sells flat per-seat and your llm bills per-token, the math breaks the moment a power user starts an agentic loop.
a 27B on one L40S can match a frontier api at a fraction of marginal cost, if you can put it in the customer's cluster.
every enterprise ai pricing meeting is this debate.
2
258

Jun 11
I asked AI to create a visual atlas of life on Earth.
Can you spot the species that was left out?
1
3
49
Jun 11
“hello, Opus 4.8?!” is the whole Fable 5 trust problem in one panel.
4
44
Jun 11
the win is knowing when Qwen, Gemma, or Llama is enough.

Citadel says
> growing signs of a bifurcation in frontier vs "everyday" AI usage
every open source AI user knows this
all of HuggingFace knows it
this is why open source must and will win
@TheAhmadOsman there is no fate but what we make
and we shall make it great!
buy GPUs!!
1
1
58
Jun 10
Financial Times reports Anthropic has about half a dozen forward-deployed engineers inside the NSA helping deploy Mythos for offensive cyber operations.
model card in public.
FDEs in the intelligence workflow.
that is the part to watch.
the cyber race is shifting from who has the strongest model to who gets it embedded closest to the operator.
2
3
37
Jun 10
Claude Fable 5 introduces a weird developer risk.
Anthropic says safeguards can silently limit effectiveness for frontier LLM development through prompt modification, steering vectors, or PEFT.
No visible warning.
No fallback model.
Embedding models, rerankers, finetunes, small LLMs, evals, and inference infra are already normal product work.
If Claude gives bad advice on an AI component, was it wrong, missing context, or silently steered?
That uncertainty is the supply chain risk.
2
5
112
Jun 10
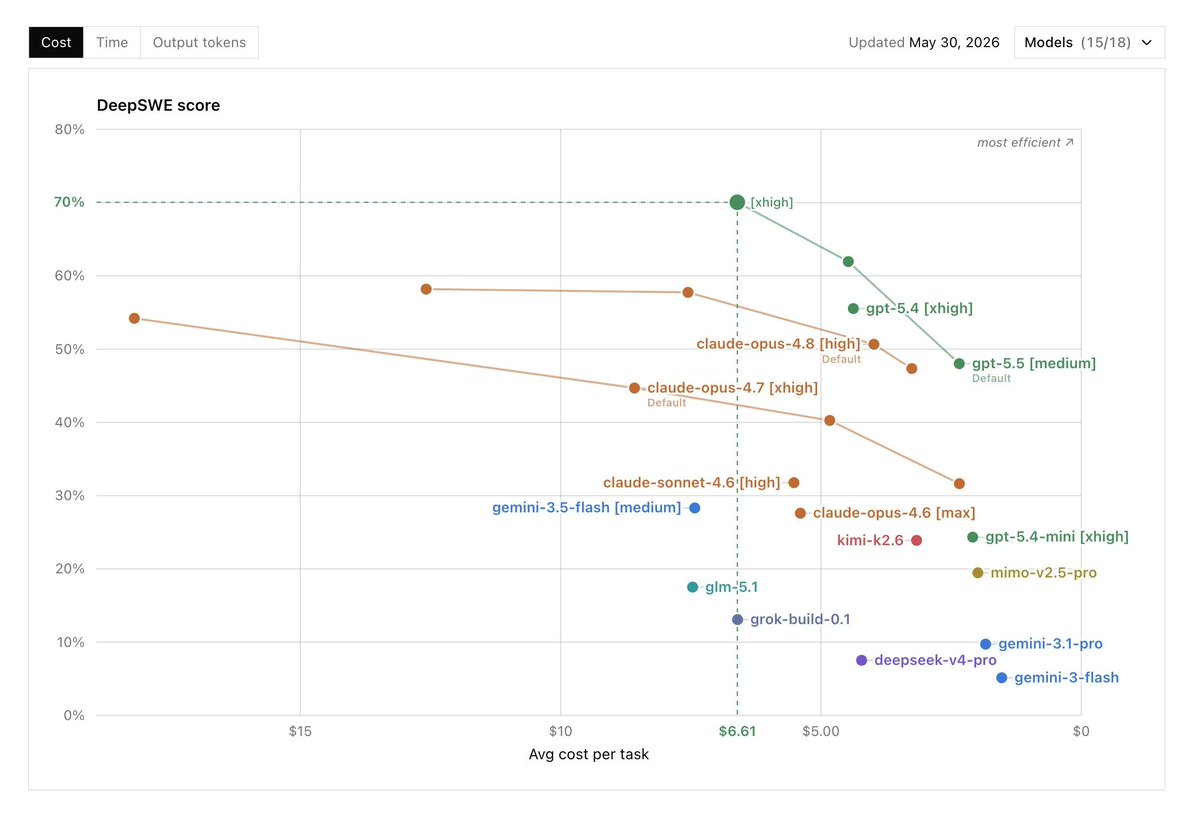
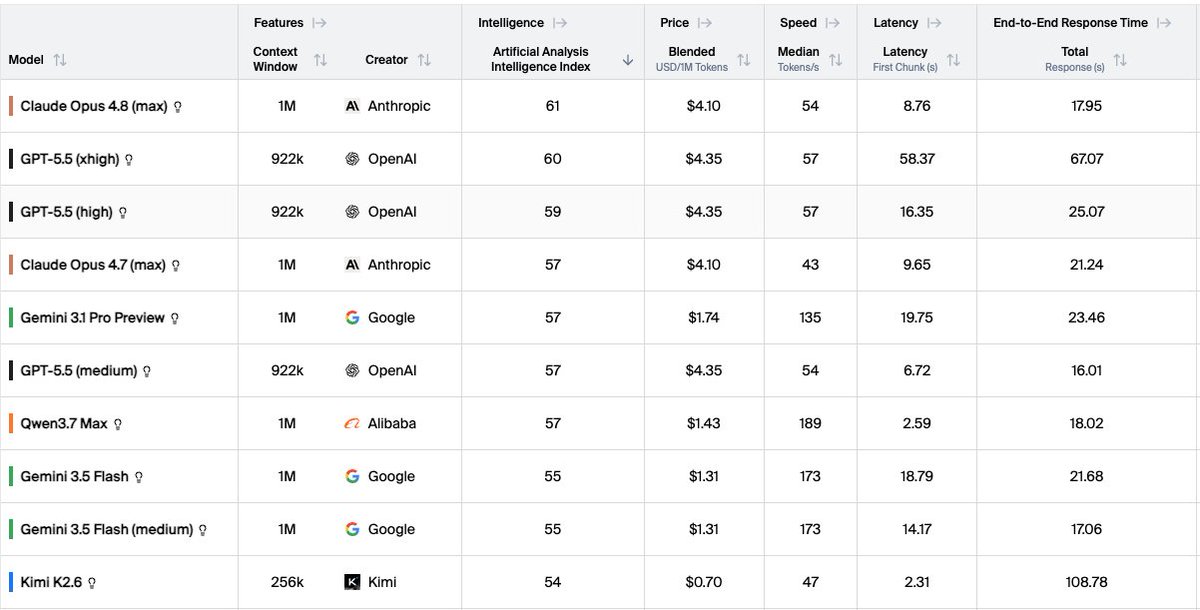
Claude Fable 5 tops the chart with 65 on Artificial Analysis.
but the cost curve is brutal:
- Fable 5: $8.20, 116s total response
- Opus 4.8: $4.10, 65s
- GPT-5.5 high: $4.35, 38s
- Qwen 3.7 Max: $1.43, 22s
Fable is burst compute.
use it for hard planning, refactors, final review.
then route down.
1
163
Jun 10
Where Fable 5 > Opus:
- Refactoring large repos
- Synthesizing lots of sources
- System design
- Visual reasoning
- Multi-step execution
Basically: less babysitting on complex work.
2
6
63
Jun 9
Mythos-class model made safe for general use is the part to watch.
the interesting question is not whether Claude Fable 5 is stronger.
it is what Anthropic had to remove, restrict, or route around to make Mythos usable in public.

Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
50