
Not very active on X - see linkedin.com/in/chrisparsons or chrismdp.com
Joined May 2008
- Tweets 18,313
- Following 288
- Followers 1,936
- Likes 6,115
642 Photos and videos
















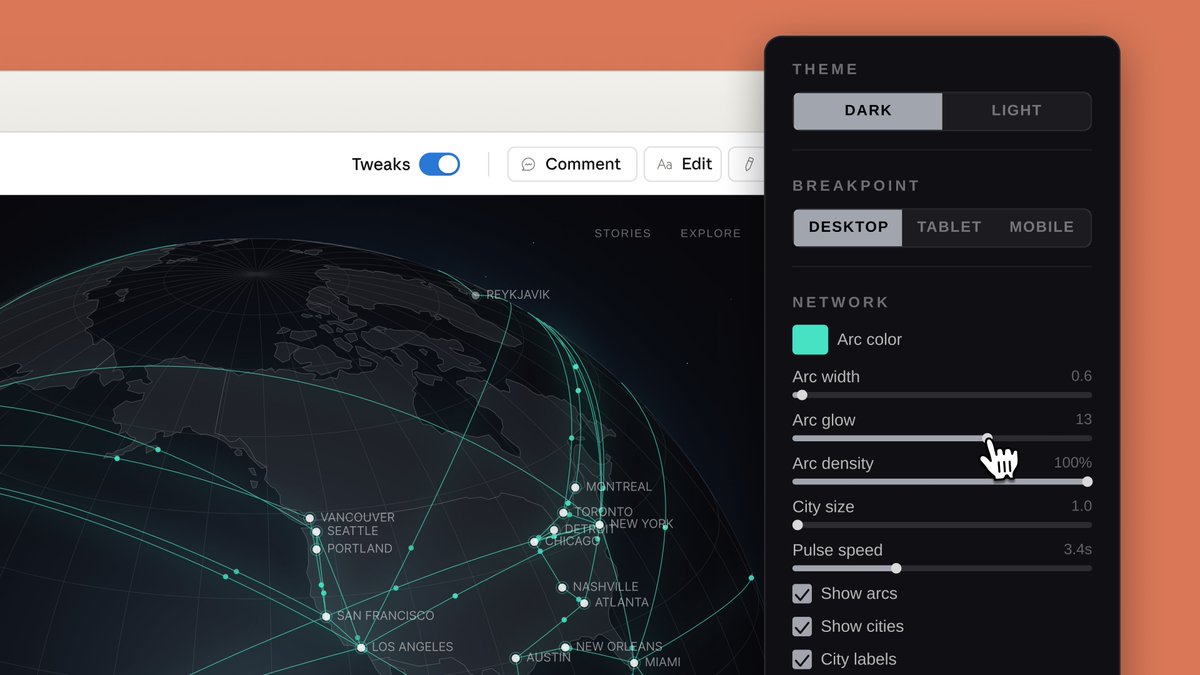
Describe what you want, and Claude builds the first version. Refine through conversation, inline comments, direct edits, or custom sliders.
Export to @canva, as PDF or PPTX, or hand off to Claude Code when the design feels right.
72
191
4,387
1,552,510
Chris Parsons retweeted

🍴 @wearecherrypick is an app that finds recipes, plans meals and orders groceries from supermarkets - with an AI twist. Helping 500k users eat better, it encourages healthy eating and reduces waste with thousands of AI recipes. Read the full story → goo.gle/4bOveWg

1
2
287

4 Nov 2025
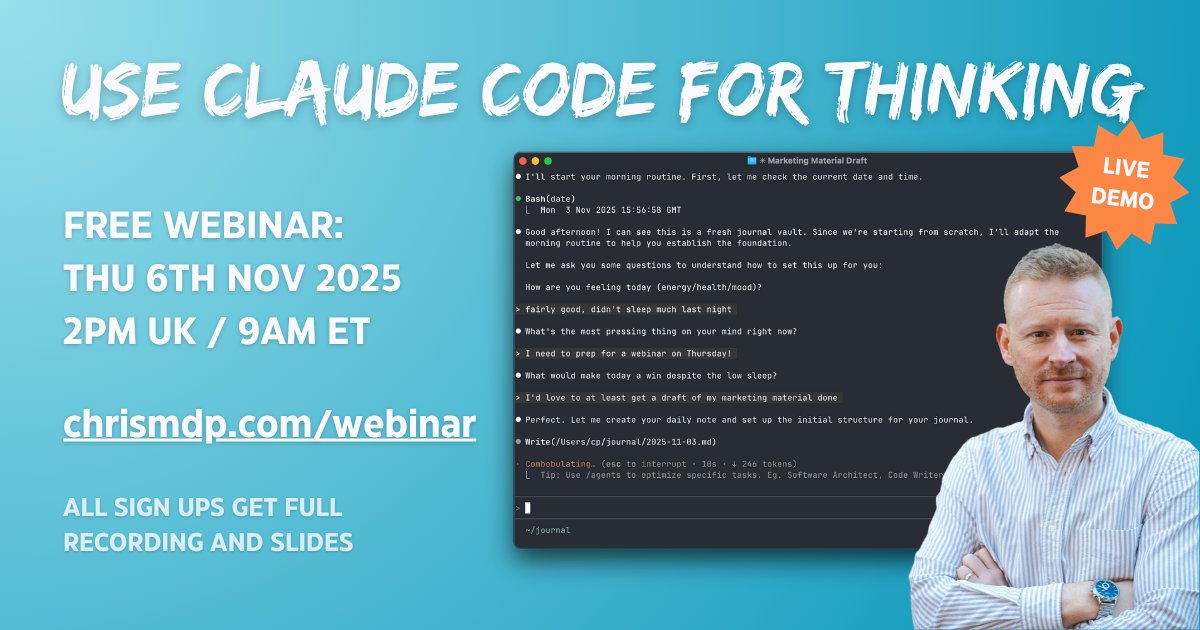
I'm demoing how I'm use Claude Code / AI for writing and thinking this Thursday! Sign up to attend or for the recording: chrismdp.com/webinar
2
2
5
1,236
2 Jul 2025
FINAL CALL: "Kill Your Prompts" starts in one hour! Free to join?
Sign up: chrismdp.com/webinar
All sign ups get full slides and recording (even if you don't make it)
2
291
24 Jun 2025
You control less of your AI conversation than you think.
(Quite proud of this infographic. Didn't do well on LinkedIn. Perhaps X users are more discerning?)
1
2
190
24 Jun 2025
I have recently gone back to Notion after a long break.
Why? MCP. Changes everything.
1
161
19 Jun 2025
Your AI experiments are failing because you're biasing yourself, and being smart makes it worse. How to prevent it:
We all suffer from these biases (and many more):
→ Anchoring Bias - First AI result skews all evaluation
→ Availability Heuristic - Recent examples feel more common
→ Subjective Validation - Personal meaning equals perceived accuracy
→ Sunk Cost Fallacy - Past investment justifies continued use
Intelligence is not a defence against these biases. The only protection is systematic measurement before cognitive biases distort your judgment.
Most teams skip this rigour and wonder why their "successful" AI experiments don't scale.
I created a one-page evaluation framework (attached) that forces objective measurement.
Will you print it out and fill it in?
…probably not. But the principles are solid and I’d encourage you to follow them!
→ Before experimenting: Write specific hypotheses about time savings, quality thresholds, and failure modes
→ After completion: Track actual time (including hidden costs), measure concrete outcomes, calculate true ROI
→ Red flags: Making excuses for poor output, spending more time fixing than doing manually, feeling defensive about effectiveness
We CANNOT prevent bias entirely, but we can fight against it. It's especially hard with AI, but with proper rigour we be as scientific as we can.
Which AI tool will you evaluate properly this week?
1
1
125
18 Jun 2025
Bitten the bullet and paid for Opus and the Claude Max plan for Claude Code.
Jury is out so far: trying to be objective on usage and state hypotheses up front.
1
4
195
16 Jun 2025
you see this kind of reaction is why I use Claude over ChatGPT 😁 (although I'm already missing the per project memory)
110
13 Jun 2025
Whew: more LinkedIn posts scheduled for the next 3 days. It's exhausting coming up with actually good AI content all the time!
73
13 Jun 2025
Just tried local MCP servers, again. Bleurgh.
I'm pretty technical and it took an hour to get one of the most popular ones working at all, and then the results were extremely poor.
MCP local is a rabbit hole. Don't bother. Remote, well maintained MCP servers is the way to go.
2
1
147
11 Jun 2025
Can I have sub-projects in my AI tools, with layers of context please? I want a folder structure, or the ability to write a prompt in multiple projects at once...
68
10 Jun 2025
The thing that sets apart @cursor_ai over over AI coding IDEs for me is not the agents/prompting: it's the UX. The tiny friction reducers like amazing smart autocomplete, tools in Inline Assist, easy checkpointing, automatic linting fixes, etc
Once we move beyond IDEs these won't matter. For now they're a key differentiator.
87
10 Jun 2025
Just been trying Zed with Gemini 2.5 for a morning of coding. Takeaways:
• Zed is much nicer than VSCode based editors
• I really miss smart auto-complete to repeat one change elsewhere
• Tools like `Web` aren't available in Inline Assist which I use all the time for small tweaks with tiny context
• 2.5 Pro is just as good as Claude at writing but much slower. Flash is amazingly fast but gets stuck quickly
I'm going to hold my nose and go back to Cursor, much as I dislike VSCode bloat the AI tools are much faster
1
121
10 Jun 2025
Finding more and more I'm just using the main Desktop tools (Claude, ChatGPT, Cursor) rather than feeling like I need to build agents.
Areas in which I want to code against #AI APIs:
- task repetition for multiple files
- critique loops to improve text
- pasting between non-MCP services
253
8 Jun 2025
Started this great article about AI coding, and I already feel seen. Templates were so exciting in 2002.
fly.io/blog/youre-all-nuts/
2
111
8 Jun 2025
I quite like paying for all of my AI subscriptions monthly.
Every time I see the payment go out, it's a prod to remind me whether or not I'm actually using the thing.
And if I'm not, then I cancel it.
1
1
61
8 Jun 2025
I do cancel things regularly. This prod feels like it's well worth the cost of any annual discount I might get.
43