
Joined March 2024
- Tweets 1,732
- Following 391
- Followers 201
- Likes 2,103
433 Photos and videos





Pinned Tweet

6 Apr 2024
Hi Everyone ! I am looking to #Connect with people who are interested in -----
👨💻 Data Engineering
📊 Data Analysis
☁️ Microsoft Azure | AWS
🧱Databricks
⌨️ Coding
👨🔬 AI/ML/GenAI
Let's grow together ☕️
16
14
4,917
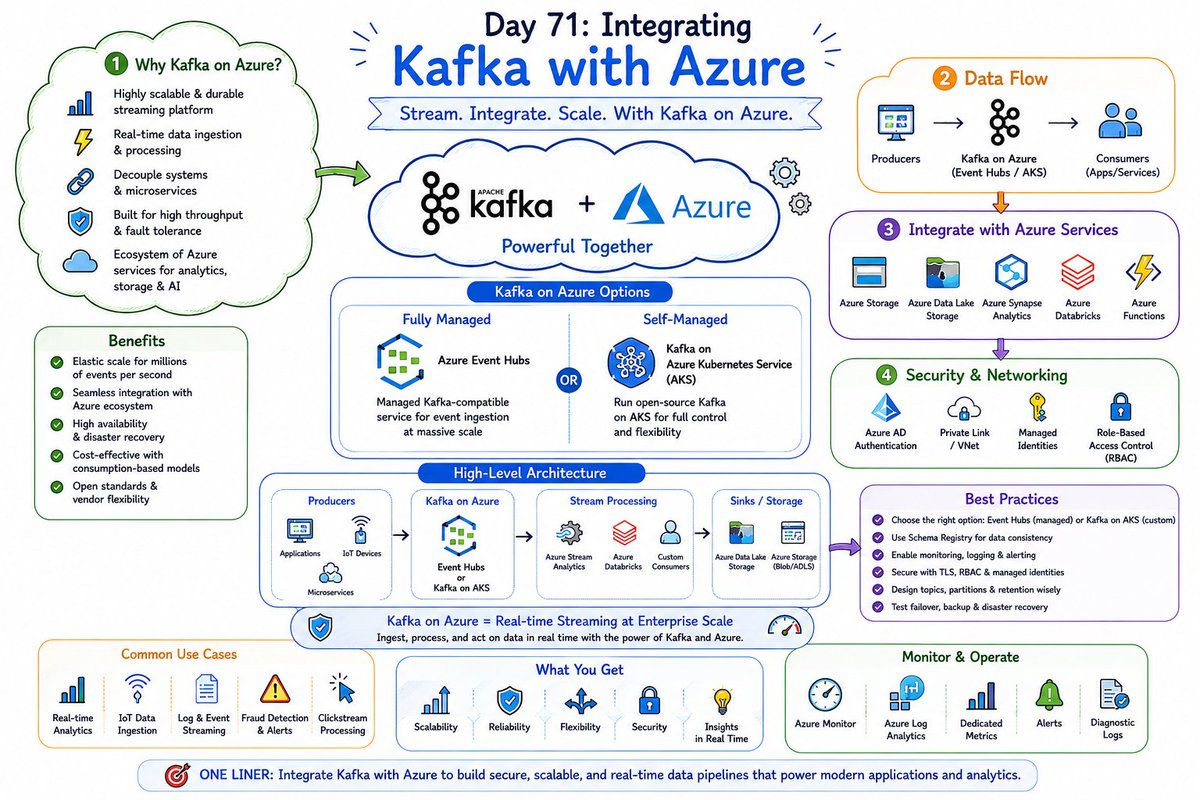
🌐 Kafka Azure = Reliable event streaming, seamless integration, and limitless scalability. ☕️
#dataengineering #machinelearning #cloudcomputing #dataanalytics #aws #googlecloud #microsoftazure #datascience
44
Day 70: Deduping Streaming Data - 🎯 Clean streaming data starts with identifying and removing duplicates before they impact downstream systems.
#dataengineering #dataanalytics #machinelearning #artificialintelligence #datascience #aws #googlecloud #microsoftazure
522
Day 69: Handling Late Arriving Data
Late data is inevitable in real-world systems—successful data engineers design pipelines that detect, manage, and process it without compromising accuracy or trust. 🚀
#dataengineering #dataanalytics #cloudcomputing #aws #machinelearning
658
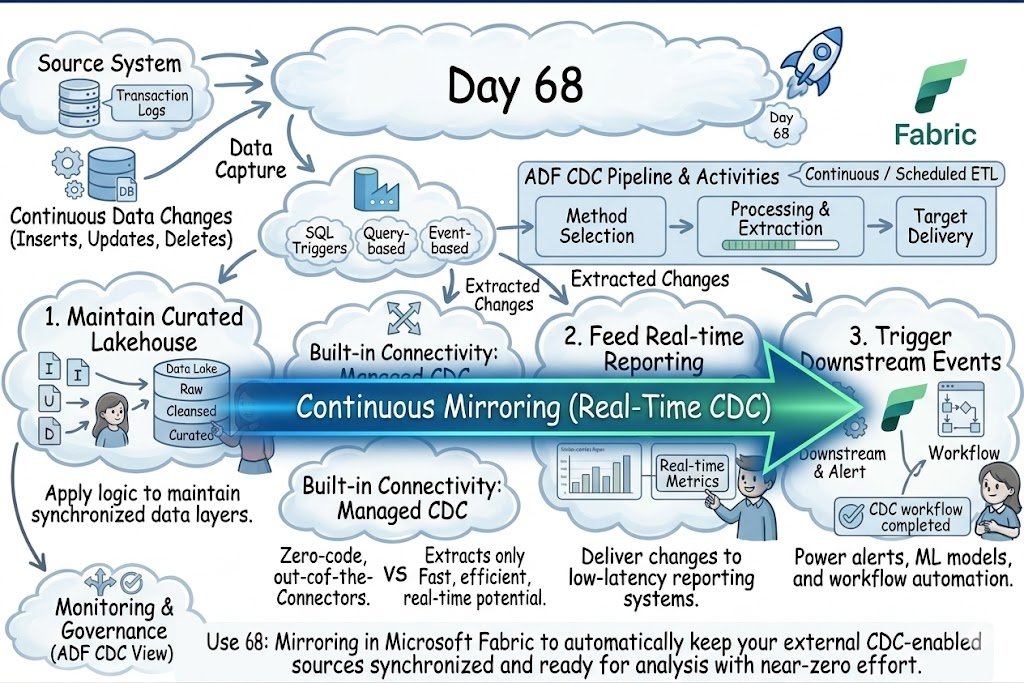
Day 68: Mirroring in Microsoft Fabric automatically keeps your external CDC-enabled sources synchronized and ready for analysis with near-zero effort.
#dataengineering #dataanalytics #machinelearning #cloudcomputing #aws #googlecloud
1,255
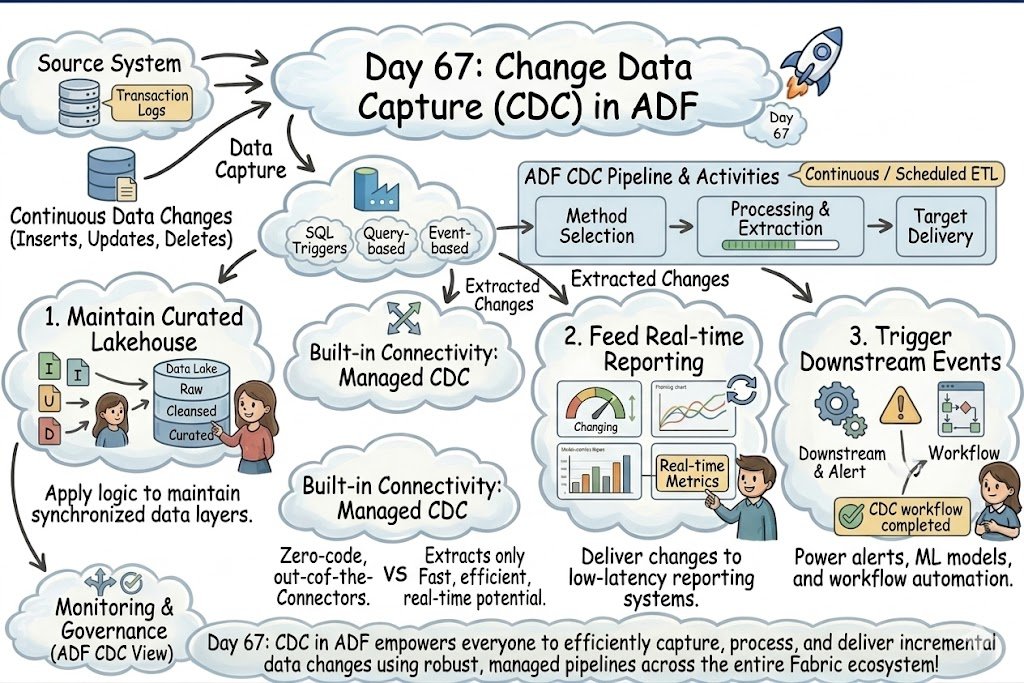
Day 67: Sync Only What Matters! Use ADF's Change Data Capture to move beyond heavy batch reloads and enable high-efficiency, near real-time data integration by capturing every row-level change automatically.
#dataengineering #cloudcomputing #dataanalytics #machinelearning #aws
2,004
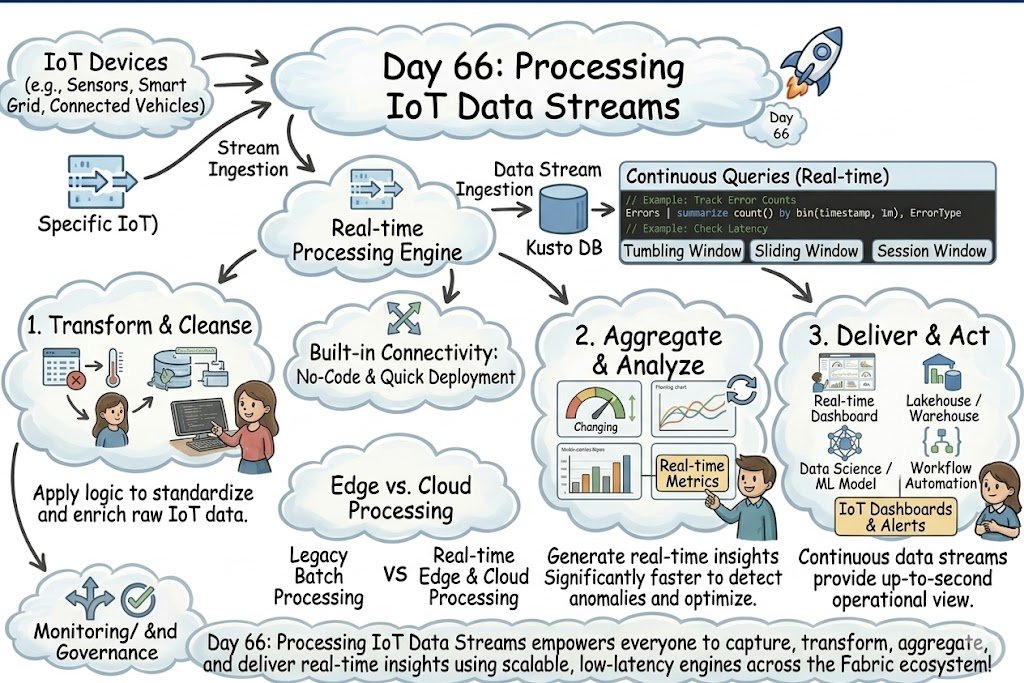
Day 66: Take control of the streaming storm! Turn raw IoT data into real-time, actionable insights with a high-performance, unified stream processing architecture.☕️
#dataengineering #dataanalytics #machinelearning #cloudcomputing #artificialintelligence #aws
1,638
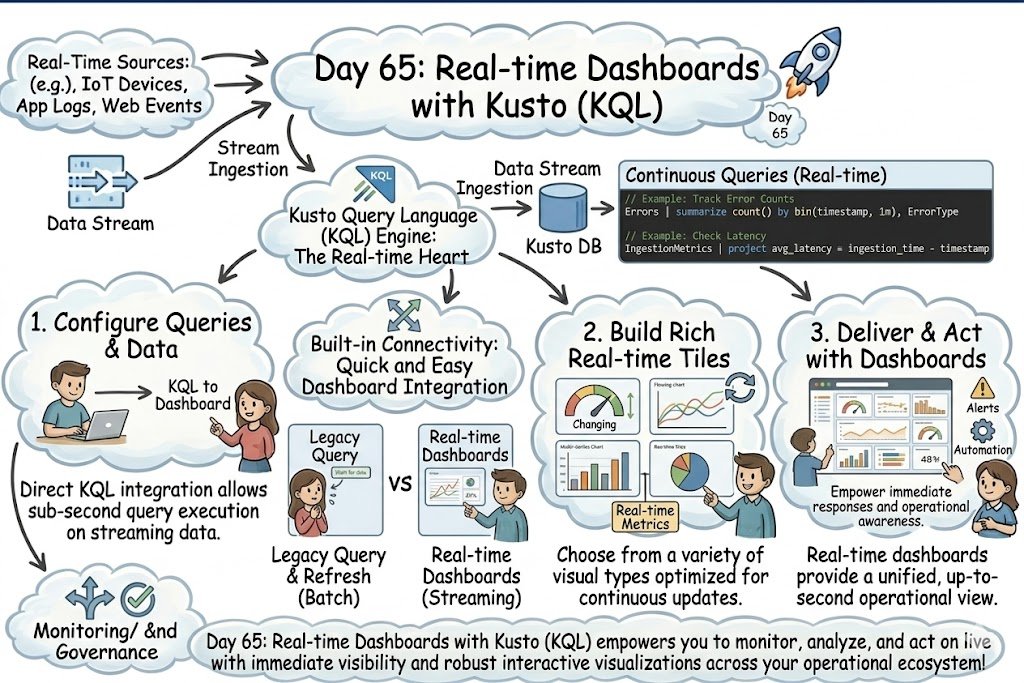
Day 65: Get live, actionable insights with Kusto (KQL)-powered Real-time Dashboards to monitor, analyze, and automate on streaming data instantly!
#dataengineering #dataanalytics #datascience #machinelearning #artificialintelligence #cloudcomputing
190
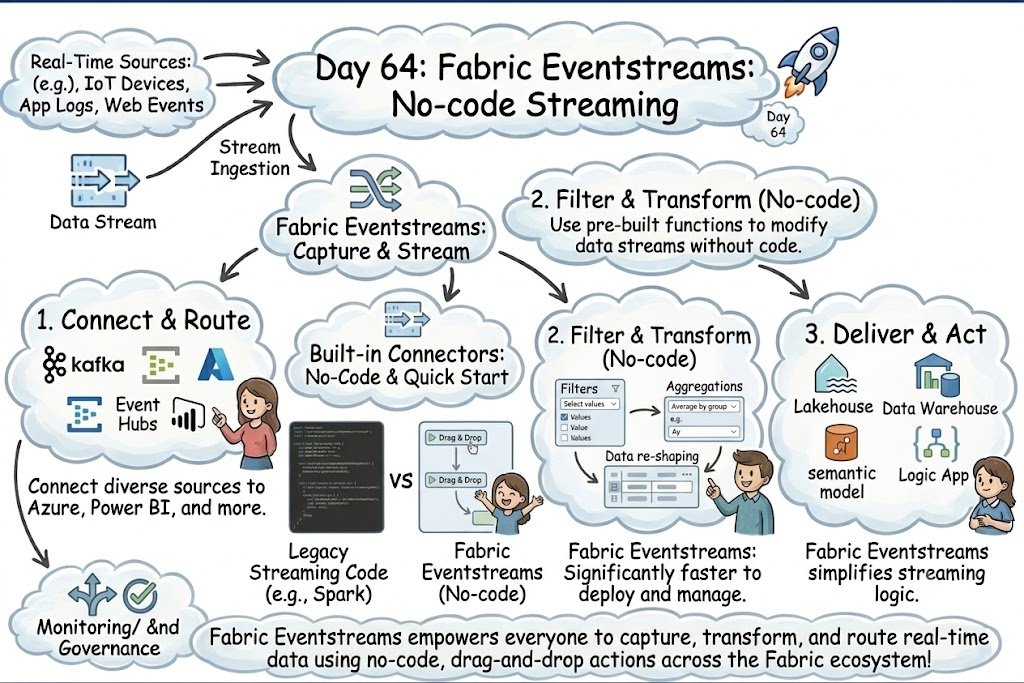
Day 64 : Use Fabric Eventstreams as a one-stop, no-code solution to capture, filter, transform, and deliver real-time data from diverse sources directly to your data ecosystem.☕️
#dataengineering #datascience #cloudcomputing #dataanalytics #machinelearning
1
5,204
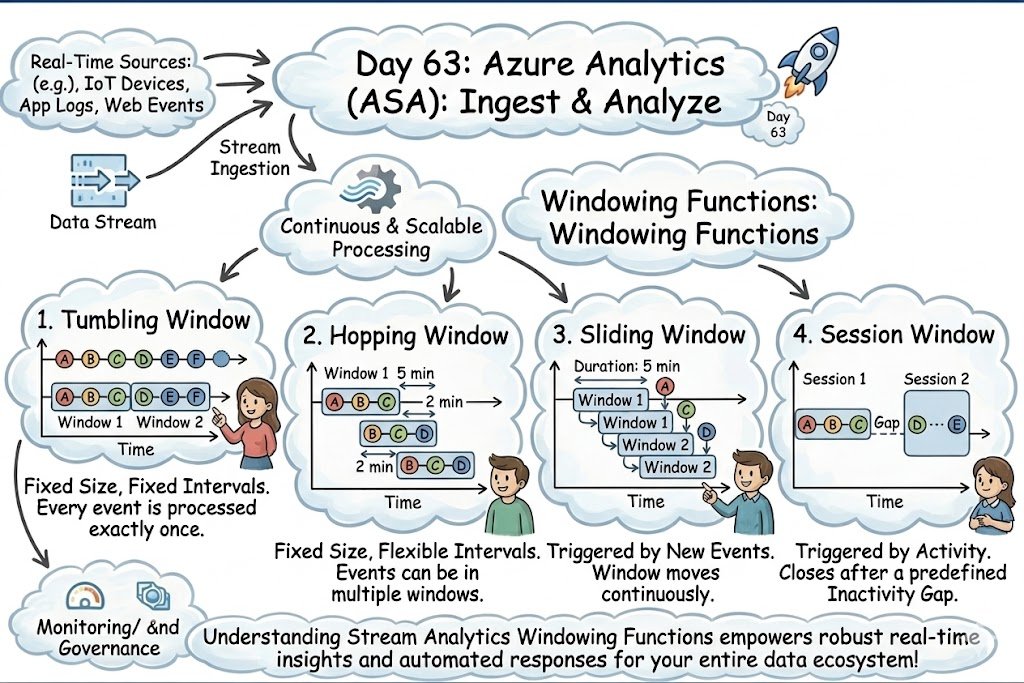
Day 63: Uncover the insights in your data stream by mastering Azure Stream Analytics' four key windowing functions: Tumbling, Hopping, Sliding, and Session!
#dataengineering #dataanalytics #datascience #machinelearning #cloudcomputing #aws #microsoftazure
666
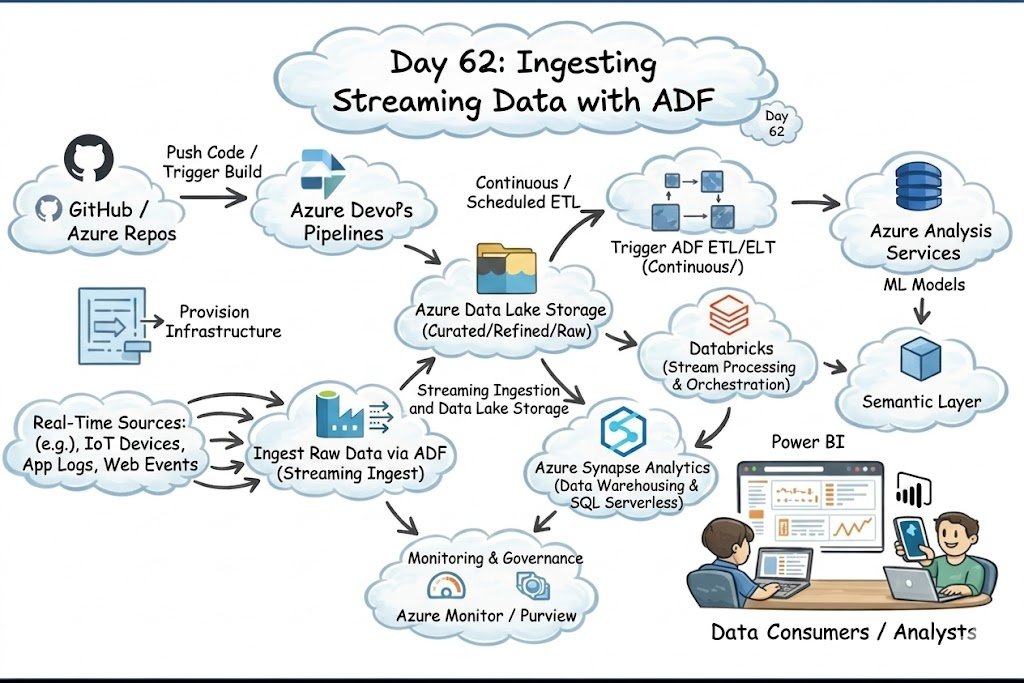
Day 62: Continuous Flow! Use Azure Data Factory to ingest real-time streams, loading data lake storage with curated, raw, and refined data for immediate analysis.
#dataengineering #cloudcomputing #dataanalytics #datascience #machinelearning #artificialintelligence #aws
62
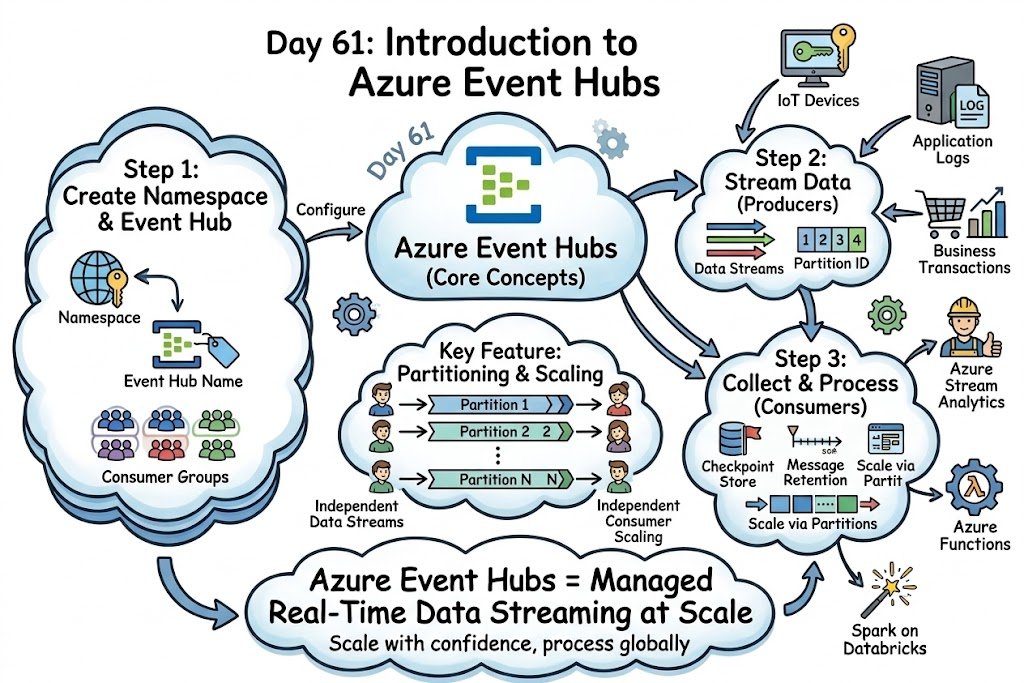
Day 61: Scale and Stream! Leverage Azure Event Hubs' partitioning and managed infrastructure to ingest millions of events per second and scale real-time data processing horizontally.
#dataengineering #cloudcomputing #machinelearning #dataanalytics #datascience
1
4,168
Day 60: Capture the Stream! Ingest high-velocity data into KQL Databases to run instant, real-time queries and power live analytical dashboards.
#dataengineering #cloudcomputing #machinelearning #artificialintelligence #dataanalytics #DataScience
2,354
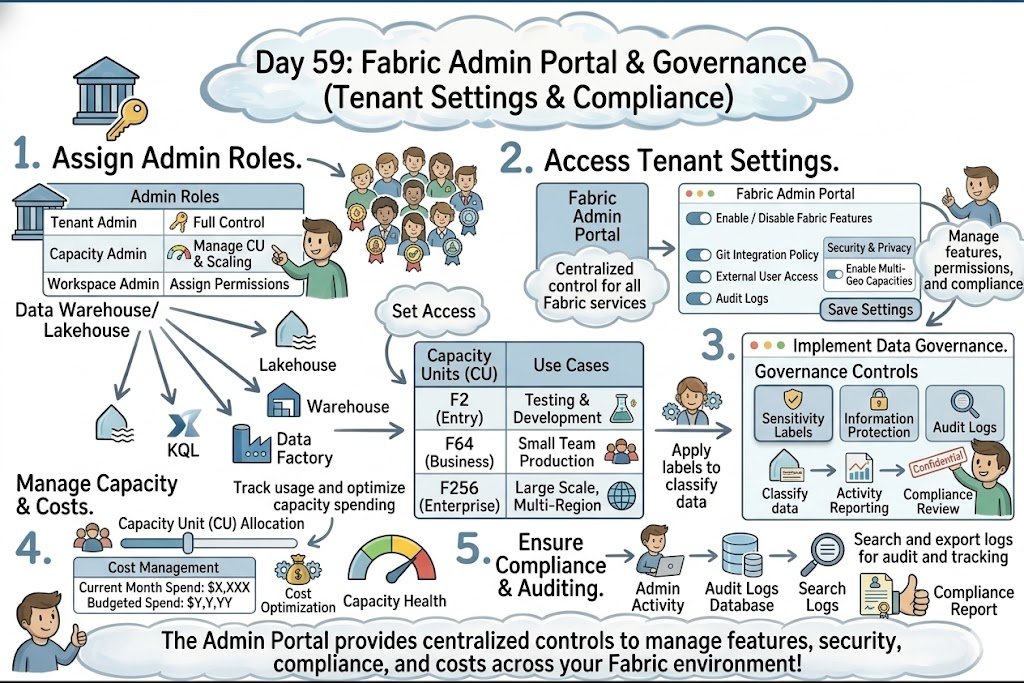
Day 59: Secure Your Tenant! Use the Admin Portal to manage feature switches, enforce global security policies, and audit usage to ensure strict enterprise governance.
#dataengineering #dataanalytics #machinelearning #cloudcomputing #artificialintelligence
1
1,982
Day 58: Track Every Job! Use the centralized Monitoring Hub to track pipeline status, analyze capacity usage, and identify performance bottlenecks in real time.
#dataengineering #cloudcomputing #machinelearning #artificialintelligence #microsoftazure #datananalytics
1
663
Day 57: Track Every Change! Sync your workspace with Git to enable version control, team collaboration, and seamless deployments across Dev, Test, and Prod.
#dataengineering #cloudcomputing #dataanalytics #machinelearning #microsoftazure #aws #googlecloud

1
95
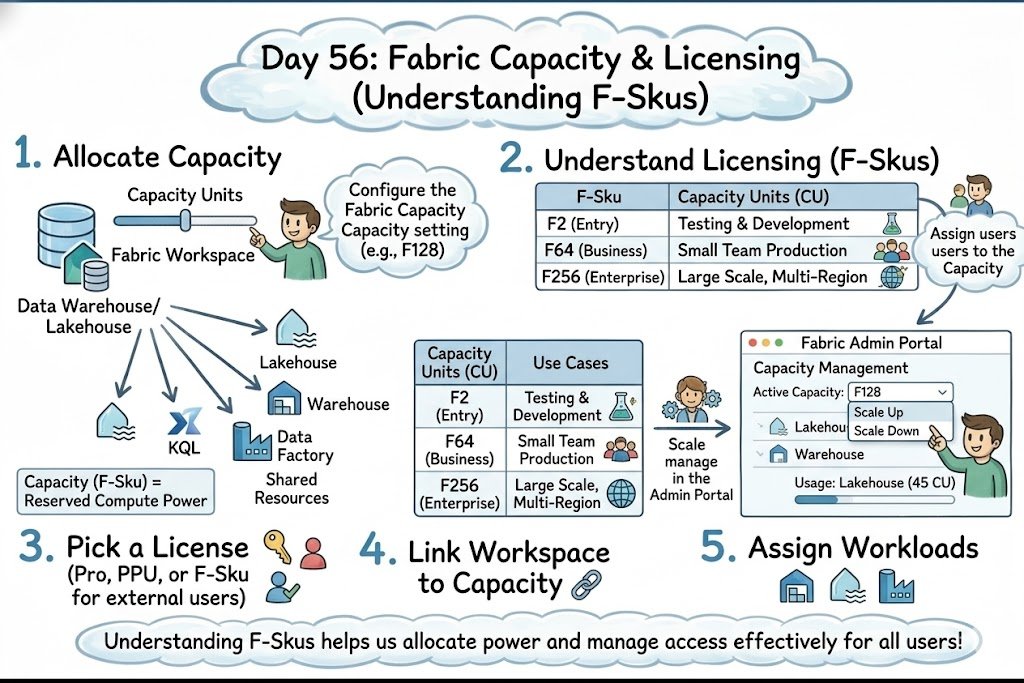
Understanding F-Skus is key to properly allocating compute power and managing workload access across your Fabric environment.
#dataengineering #dataanalytics #machinelearning #cloudcomputing
3
5,627
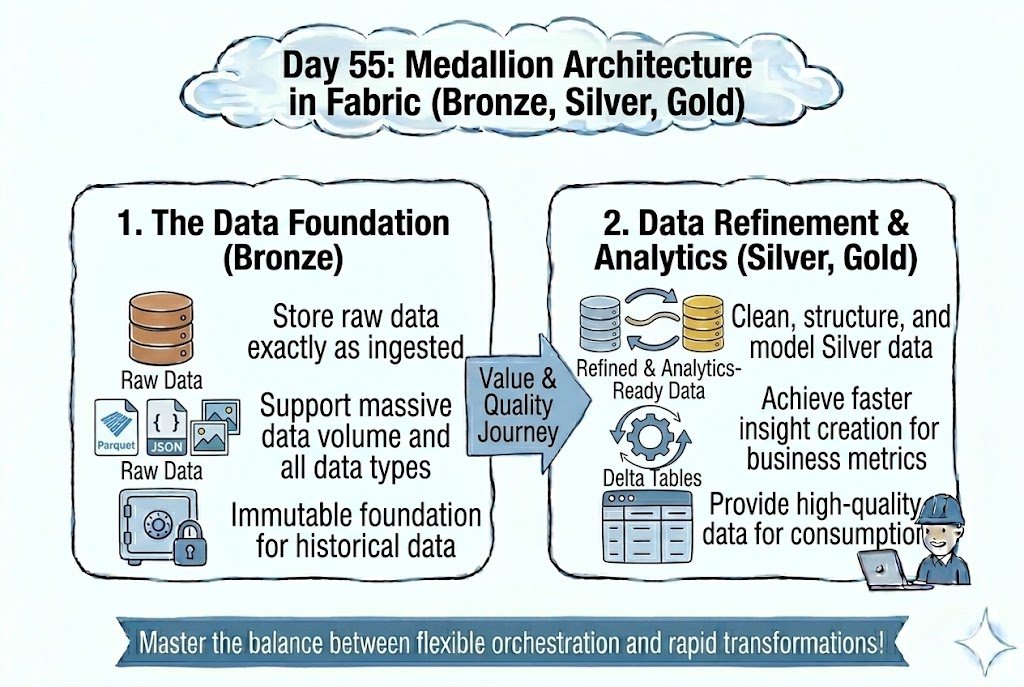
Day 55: Refine Your Data! 🥉🥈🥇 Transform raw mess into business value using the Medallion Architecture to move data through Bronze (Raw), Silver (Clean), and Gold (Curated) layers. 💎⚡
#dataengineering #dataanalytics #cloudcomputing #machinelearning
1
2
5,711
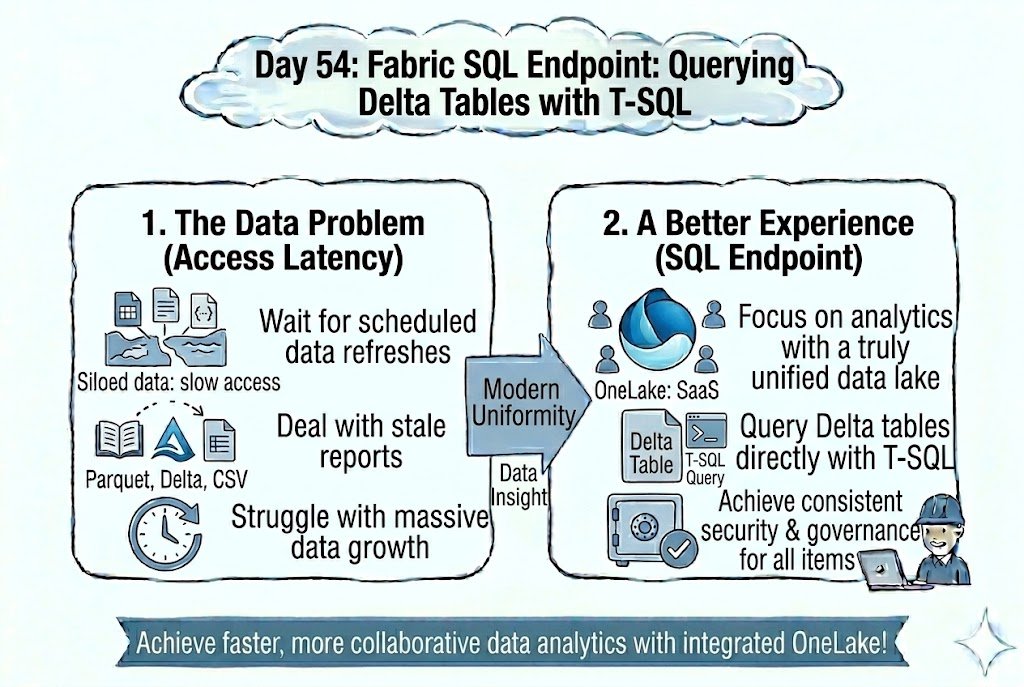
Day 54: SQL Power on the Lake! 🔍 Access your data with the familiarity of T-SQL using the Fabric SQL Endpoint, allowing you to run high-performance relational queries directly against Delta tables in your Lakehouse. ⚡📂
#dataengineering #dataanalytics #cloudcomputing
2
2,048
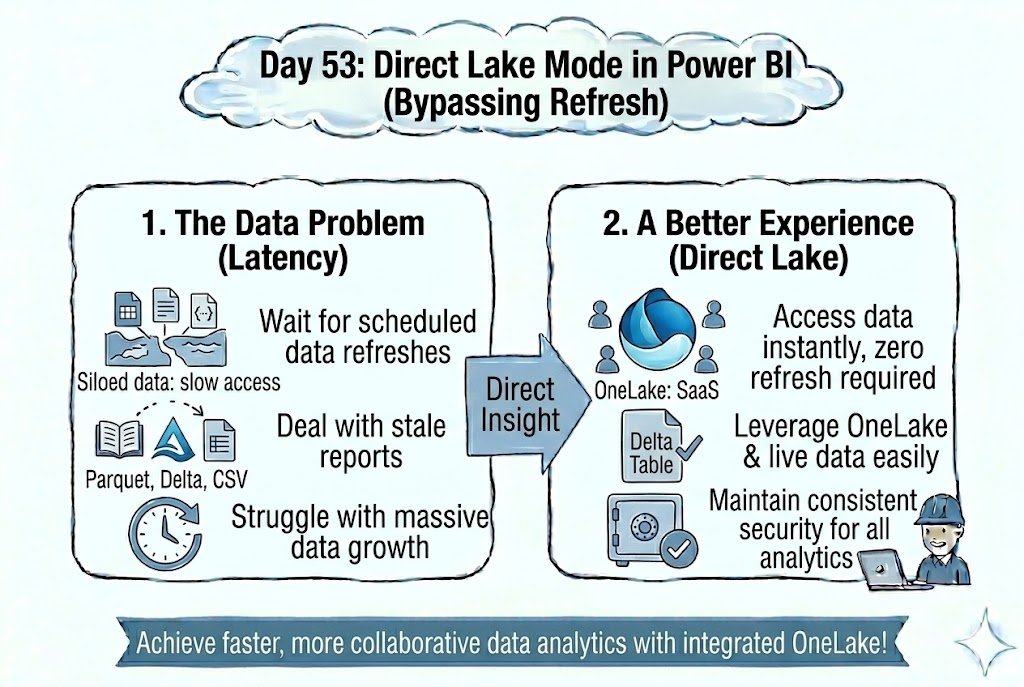
Day 53: Live Data, Zero Latency! ⚡ Experience the speed of Import mode with the real-time nature of DirectQuery using Direct Lake, which reads Parquet files directly from OneLake—bypassing the need for data refreshes. 🚀📊
#dataengineering #dataanalytics #cloudcomputing
1
640
Day 52: Optimize Your Runtime! 🐍 Simplify your Spark development by using Fabric Environments to manage custom libraries, Spark properties, and compute settings across all your notebooks. ⚡📦
#dataengineering #dataanalytics #cloudcomputing #machinelearning

1
366