
AI Educator | Teaching you how to earn smarter with AI, automation & digital skills | CPP @Yapper_so | 📩 DM Open for collaboration
Joined February 2023
- Tweets 77,547
- Following 2,730
- Followers 33,991
- Likes 134,601
8,458 Photos and videos















Pinned Tweet

Jun 3
AI can write you a poem. It can build a website. It can plan a trip. But it can't tap a button on your phone. That's what makes the boring work boring. Nobody's solved it. Until now.
@airtap_ai is the AI that finally taps the buttons. You teach it a routine one time. It runs that routine every day for you.
16
45
37
181,951
Md Santo retweeted

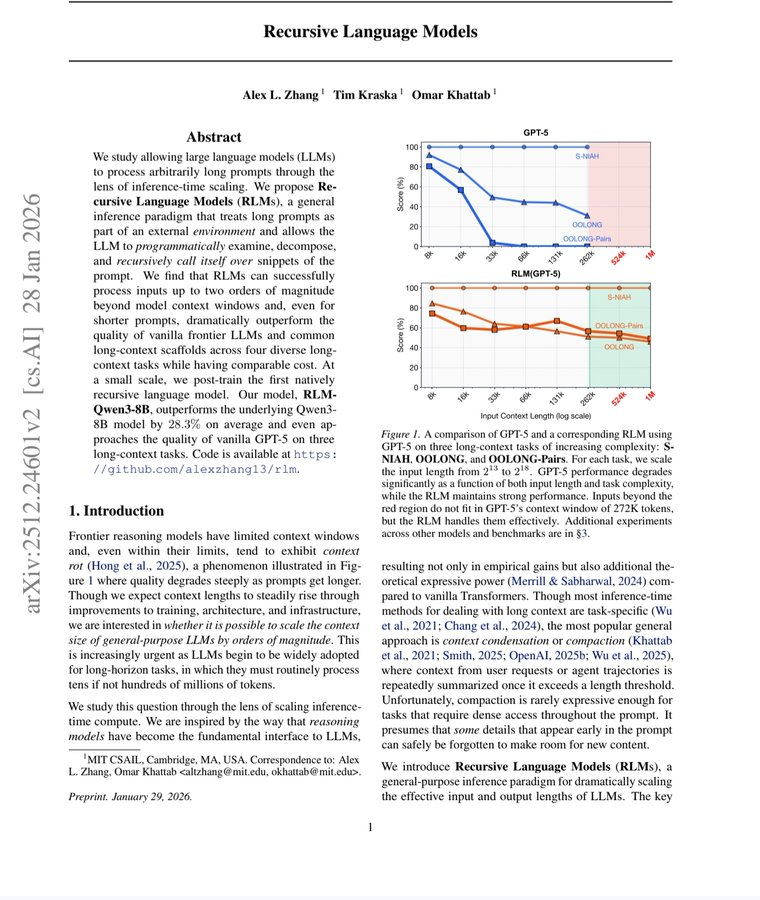
MIT just made every AI company's billion dollar bet look embarrassing.
They solved AI memory. Not by building a bigger brain. By teaching it how to read.
The paper dropped on December 31, 2025. Three MIT CSAIL researchers. One idea so obvious it hurts. And a result that makes five years of context window arms racing look like the wrong war entirely.
Here is the problem nobody solved.
Every AI model on the planet has a hard ceiling. A context window. The maximum amount of text it can hold in working memory at once. Cross that line and something ugly happens — something researchers have a clinical name for.
Context rot.
The more you pack into an AI's context, the worse it performs on everything already inside it. Facts blur. Information buried in the middle vanishes. The model does not become more capable as you feed it more. It becomes more confused. You give it your entire codebase and it forgets what it read three files ago. You hand it a 500-page legal document and it loses the clause from page 12 by the time it reaches page 400.
So the industry built a workaround. RAG. Retrieval Augmented Generation. Chop the document into chunks. Store them in a database. Retrieve the relevant ones when needed.
It was always a compromise dressed up as a solution.
The retriever guesses which chunks matter before the AI has read anything. If it guesses wrong — and it does, constantly — the AI never sees the information it needed. The act of chunking destroys every relationship between distant paragraphs. The full picture gets shredded into fragments that the AI then tries to reassemble blindfolded.
Two bad options. One broken industry. Three MIT researchers and a deadline of December 31st.
Here is what they built.
Stop putting the document in the AI's memory at all.
That is the entire idea. That is the breakthrough. Store the document as a Python variable outside the AI's context window entirely. Tell the AI the variable exists and how big it is. Then get out of the way.
When you ask a question, the AI does not try to remember anything. It behaves like a human expert dropped into a library with a computer. It writes code. It searches the document with regular expressions. It slices to the exact section it needs. It scans the structure. It navigates. It finds precisely what is relevant and pulls only that into its active window.
Then it does something that makes this recursive.
When the AI finds relevant material, it spawns smaller sub-AI instances to read and analyze those sections in parallel. Each one focused. Each one fast. Each one reporting back. The root AI synthesizes everything and produces an answer.
No summarization. No deletion. No information loss. No decay. Every byte of the original document remains intact, accessible, and queryable for as long as you need it.
Now here are the numbers.
Standard frontier models on the hardest long-context reasoning benchmarks: scores near zero. Complete collapse. GPT-5 on a benchmark requiring it to track complex code history beyond 75,000 tokens — could not solve even 10% of problems.
RLMs on the same benchmarks: solved them. Dramatically. Double-digit percentage gains over every alternative approach. Successfully handling inputs up to 10 million tokens — 100 times beyond a model's native context window.
Cost per query: comparable to or cheaper than standard massive context calls.
Read that again. One hundred times the context. Better answers. Same price.
The timeline of the arms race makes this sting harder. GPT-3 in 2020: 4,000 tokens. GPT-4: 32,000. Claude 3: 200,000. Gemini: 1 million. Gemini 2: 2 million. Every generation, every company, billions of dollars spent, all betting on the same assumption.
More context equals better performance.
MIT just proved that assumption was wrong the entire time.
Not slightly wrong. Fundamentally wrong. The entire premise of the last five years of context window research — that the solution to AI memory was a bigger window — was the wrong answer to the wrong question.
The right question was never how much can you force an AI to hold in its head.
It was whether you could teach an AI to know where to look.
A human expert handed a 10,000-page archive does not read all 10,000 pages before answering your question. They navigate. They search. They find the relevant section, read it deeply, and synthesize the answer.
RLMs are the first AI architecture that works the same way.
The code is open source. On GitHub right now. Free. No license fees. No API costs. Drop it in as a replacement for your existing LLM API calls and your application does not even notice the difference — except that it suddenly works on inputs it used to fail on entirely.
Prime Intellect — one of the leading AI research labs in the space — has already called RLMs a major research focus and described what comes next: teaching models to manage their own context through reinforcement learning, enabling agents to solve tasks spanning not hours, but weeks and months.
The context window wars are over.
MIT won them by walking away from the battlefield.
Source: Zhang, Kraska, Khattab · MIT CSAIL · arXiv:2512.24601
Paper: arxiv.org/abs/2512.24601
GitHub: github.com/alexzhang13/rlm
11
11
18
314
Md Santo retweeted

1h
Here's probably the best Claude Cowork tutorial under 25 minutes.
It is by Tina Huang ( ex-Meta data scientist).
17
23
39
4,177
Md Santo retweeted

For anyone making trend-based content, speed matters almost as much as quality.
A new Seedance 2.0 model that generates faster while staying affordable could make it much easier to jump on trends before they’re gone.
The real question is: how much faster will it actually be?

7
11
13
628
Maybe this is an unpopular opinion, but I don’t think AI video models need to get dramatically better anymore.
What most creators actually need is lower costs and faster generation.
That’s why CapCut’s new Seedance 2.0 model caught my attention.
Would you rather have slightly better quality, or the same quality at half the cost? 👀
10
11
21
1,953
Md Santo retweeted

Earns $400 per hour by reading books.
I've created a guide with 20 methods to help you earn $2000 daily.
Normally $199, but today, it's free.
To get it:
Like this post & RT
Comment 'Send'
I'll DM it to you (Must be following me)

16
11
16
300
Md Santo retweeted

I'm deleting this soon because it's a legit cash-printing formula.
𝗣𝗮𝗶𝗱 𝗖𝗼𝘂𝗿𝘀𝗲 𝗙𝗥𝗘𝗘
1. Artificial Intelligence Data Analyst
2. Machine Learning Data Science
3. Cloud Computing Web Development
4. Ethical Hacking Hacking
5. Data Analytics DSA
6. AWS Certified IBM COURSE
7. Data Science Deep Learning
8. BIG DATA SQL COMPLETE COURSE
9. Python OTHERS
10 MBA HANDWRITTEN NOTES
(72 Hours only ) Cost About - $500
To get: -
1. Follow (So I can DM you )
2. Like & retweet
3. Reply " Send "

15
11
13
397
Md Santo retweeted

Kids animation is the most underrated money niche on YouTube 💸
No face.
No voice needed.
No trends.
Just stories consistency.
One channel:
721K subs
24 videos
This is not luck.
It’s niche selection.
Want the blueprint?
Comment “KIDS” 👇
Follow Bookmark must 🔖

16
15
23
253
Md Santo retweeted

Google has published a paper that might end the transformer era.
For the last 7 years, every major AI, ChatGPT, Claude, Gemini, has been built on the exact same architecture: The Transformer.
But Transformers have a fatal flaw.
To remember context, they have to process every single word against every other word. It’s called quadratic complexity. As your prompt gets longer, the compute cost explodes.
The alternative is the old-school RNN (Recurrent Neural Network). RNNs are incredibly cheap and fast, but they have a fixed memory size. If you give them a long document, they get amnesia.
Until today.
Google researchers published Memory Caching: RNNs with Growing Memory.
And it fixes the biggest bottleneck in AI.
Instead of an RNN having a fixed, rigid memory that constantly overwrites itself, Google gave it a "save" button.
The technique allows the RNN to cache checkpoints of its hidden states as it reads.
The memory capacity of the RNN can now dynamically grow as the sequence gets longer.
They built four different variants, including sparse selective mechanisms where the AI actively chooses exactly which checkpoints matter most.
The results rewrite the rules of efficiency.
On long-context understanding and recall-intensive tasks, these new Memory-Cached RNNs closed the gap with Transformers.
They achieved competitive accuracy without the explosive, quadratic compute cost. It perfectly bridges the gap between the cheap efficiency of an RNN and the massive capability of a Transformer.
We have spent billions scaling Transformers because we thought they were the only way an AI could remember a long conversation.
But Google just proved we don't need to process the whole history every single time.
We just needed a smarter cache.

20
44
59
676
Md Santo retweeted

Professionals won’t tell you this 👀
They use these daily. 🪄⚡
1. Ideas 🧠
- YOU
- Claude
- ChatGPT
- Perplexity
- Bing Chat
2. Presentation
- Prezi
- Pitch
- PopAi
- Slides AI
- Slidebean
3. Website
- Dora
- Wegic
- 10Web
- Framer
- Durable
4. Writing
- Rytr
- Jasper
- Copy AI
- Textblaze
- Writesonic
5. AI Models
- RenderNet
- Glambase App
- Luma AI
- Sora (OpenAI)
- Leonardo AI
6. Meeting
- Tldv
- Krisp
- Otter
- Avoma
- Fireflies
7. Chatbots
- Poe
- Claude
- Gemini
- ChatGPT
- HuggingChat
7. Automation
- ClickUp
- Drift
- Outreach
- Emplifi
- Phrasee
8. UI/UX
- Uizard
- Visily
- Khroma
- Galileo AI
- VisualEyes
9. Image
- Stylar
- Freepik
- Phygital
- StockIMG
- Bing Create
10. Video
- Pictory
- HeyGen
- Nullface
- Decohere
- Synthesia
11. Design
- Looka
- Clipdrop
- Autodraw
- Vance AI
- Designs AI
12. Marketing
- AdCopy
- Predis AI
- Howler AI
- Bardeen AI
- AdCreative
13. Twitter
- Typefully
- Postwise
- Metricool
- Tribescaler
- TweetHunter
AI updates you shouldn’t miss 👀
Follow @Onil_Coder for more.👇🔰
39
51
76
2,142
Md Santo retweeted

Brands are paying for influence. Too often they're getting inflated numbers instead.
@nikitabier

14
20
32
920
Md Santo retweeted

Professionals won’t tell you this 👀
They use these daily. 🪄⚡
1. Ideas 🧠
- YOU
- Claude
- ChatGPT
- Perplexity
- Bing Chat
2. Presentation
- Prezi
- Pitch
- PopAi
- Slides AI
- Slidebean
3. Website
- Dora
- Wegic
- 10Web
- Framer
- Durable
4. Writing
- Rytr
- Jasper
- Copy AI
- Textblaze
- Writesonic
5. AI Models
- RenderNet
- Glambase App
- Luma AI
- Sora (OpenAI)
- Leonardo AI
6. Meeting
- Tldv
- Krisp
- Otter
- Avoma
- Fireflies
7. Chatbots
- Poe
- Claude
- Gemini
- ChatGPT
- HuggingChat
7. Automation
- ClickUp
- Drift
- Outreach
- Emplifi
- Phrasee
8. UI/UX
- Uizard
- Visily
- Khroma
- Galileo AI
- VisualEyes
9. Image
- Stylar
- Freepik
- Phygital
- StockIMG
- Bing Create
10. Video
- Pictory
- HeyGen
- Nullface
- Decohere
- Synthesia
11. Design
- Looka
- Clipdrop
- Autodraw
- Vance AI
- Designs AI
12. Marketing
- AdCopy
- Predis AI
- Howler AI
- Bardeen AI
- AdCreative
13. Twitter
- Typefully
- Postwise
- Metricool
- Tribescaler
- TweetHunter
AI updates you shouldn’t miss 👀
Follow @tec_safwan for more.👇🔰
34
48
68
1,435
22h
CES 2026 just started, and we’re already seeing incredible tech.
Here're 20 most impressive reveals of CES 2026 so far:
1. Halliday Glasses: 3.5-inch AI smart glasses
21
20
48
8,862
22h
I hope you've found this thread helpful.
Follow me @codeMdSanto for more.
Like/Repost the quote below if you can:
22h

CES 2026 just started, and we’re already seeing incredible tech.
Here're 20 most impressive reveals of CES 2026 so far:
1. Halliday Glasses: 3.5-inch AI smart glasses
1
223