
Esto purus, esto unus. Tene fidem, tene modum / Notes for programming, academy and life experience. 大号 @estetico2026
Joined November 2023
- Tweets 324
- Following 81
- Followers 239
- Likes 2,929
53 Photos and videos












Feb 15
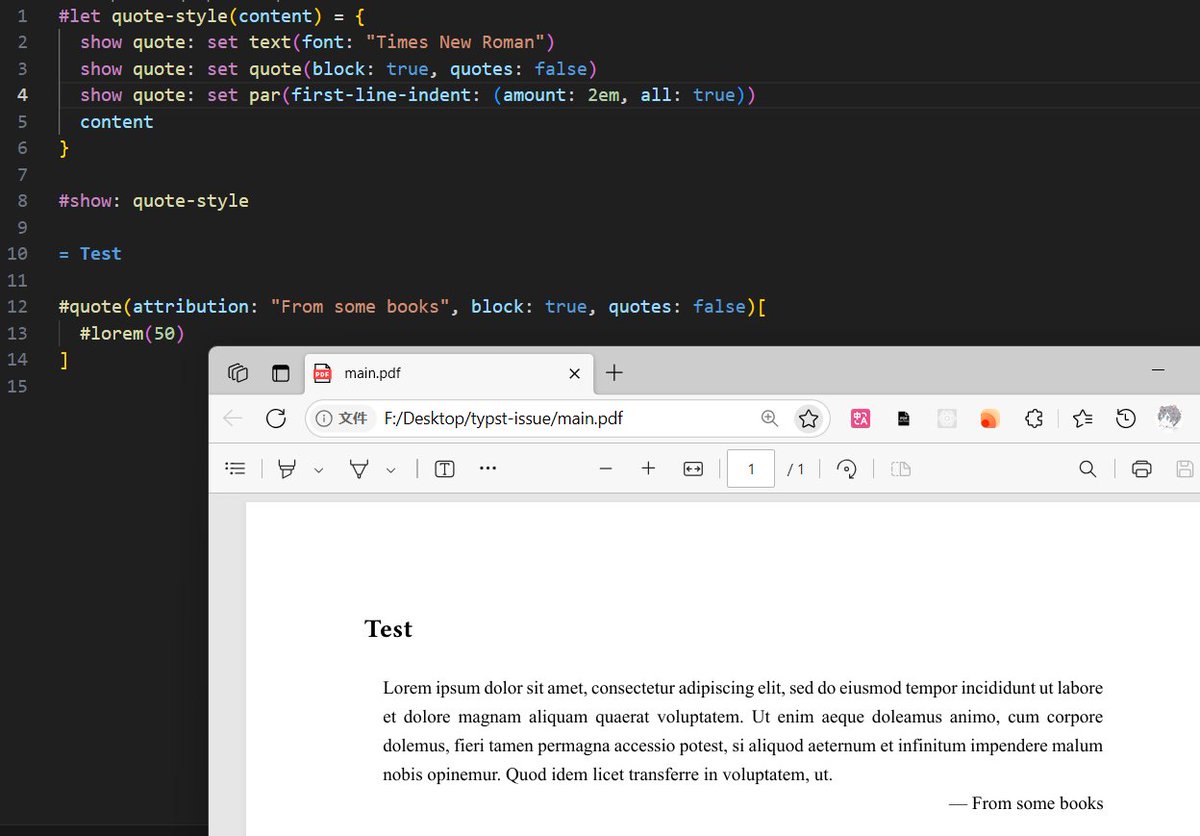
[2203.09081] Inducing Neural Collapse in Imbalanced Learning: Do We Really Need a Learnable Classifier at the End of Deep Neural Network? arxiv.org/abs/2203.09081
58
Feb 15
[2411.01248] Guiding Neural Collapse: Optimising Towards the Nearest Simplex Equiangular Tight Frame arxiv.org/abs/2411.01248
49
Feb 10
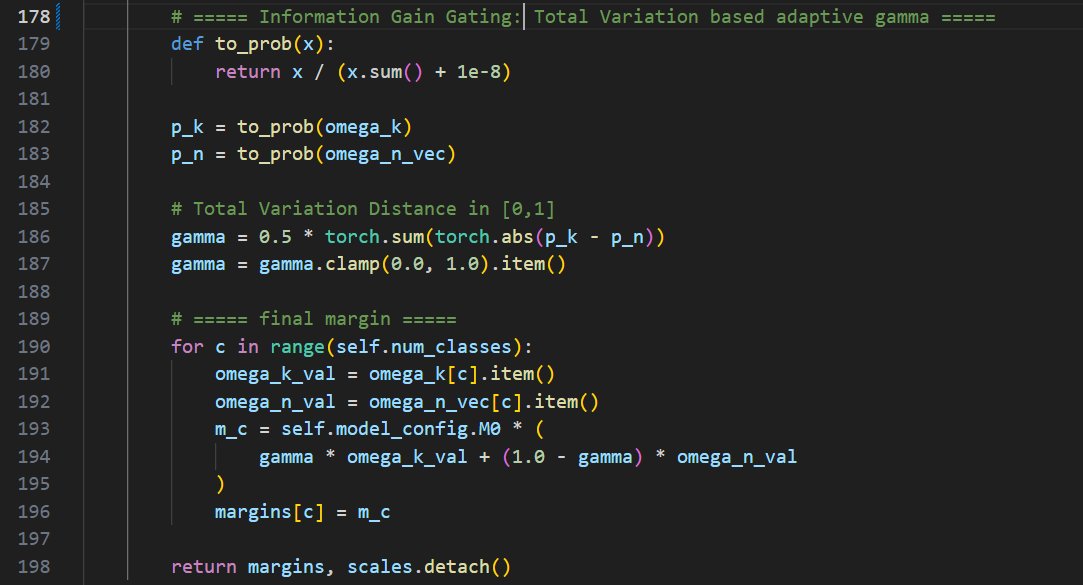
写下这段代码的时候,感叹我真是个天才。
冥思苦想了一个月的时间。
还是从期末考试题里找到的灵感,全靠 data-driven heuristically adaptive。提升了10个百分点。😌
2
90
Jan 7
😇😇突然就想通了。。
机器学习的表现上限,取决于人对标签的认识。。换句话说,根本取决于数据集的质量。我还纳闷,为什么换了好几个baseline,就是死活拉不开这只有个位数百分点的差距。。
或者来回在baseline周围震荡。。
3
657
24 Sep 2025
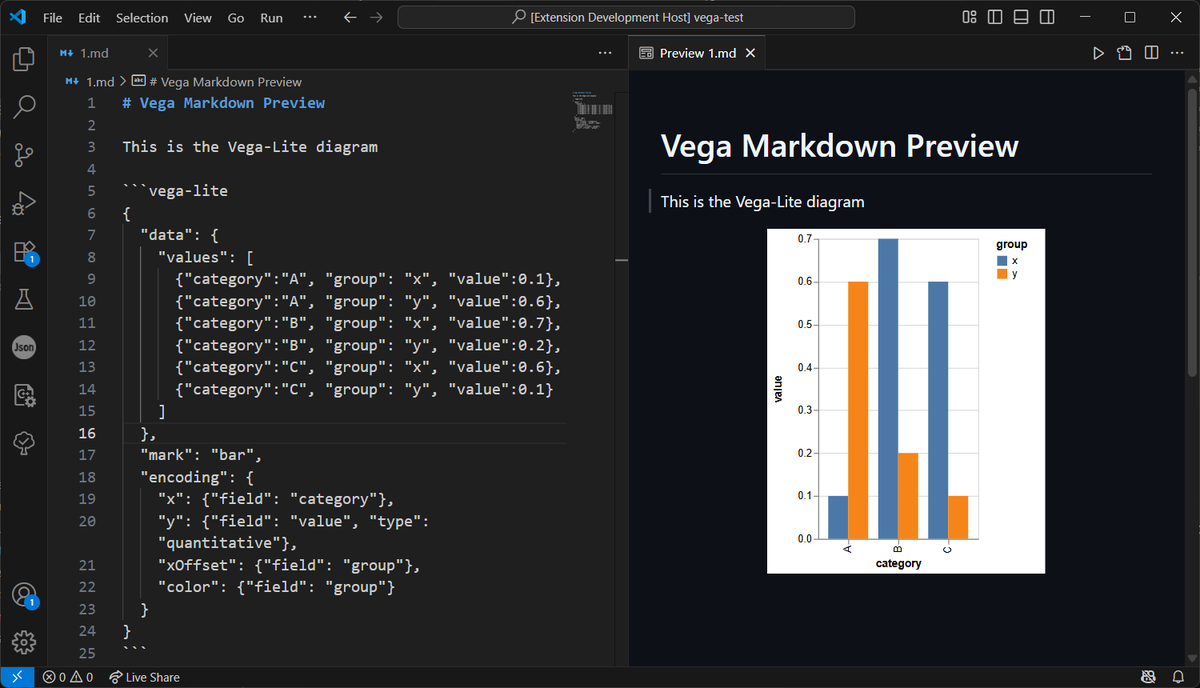
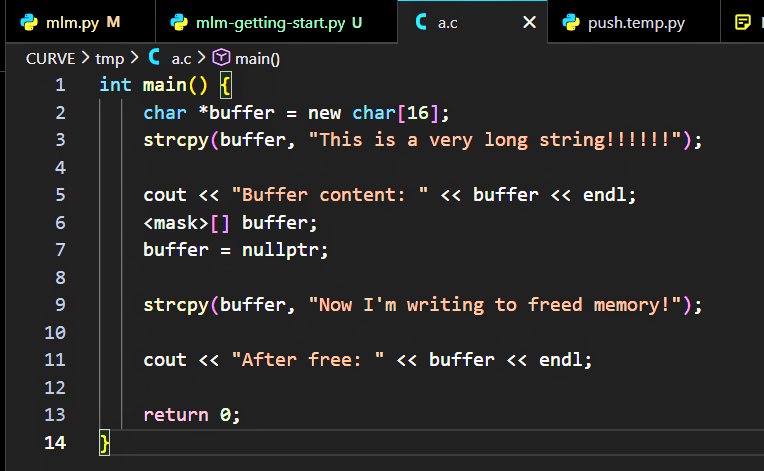
I have wrote a vscode extension, markdown-vega-preview: A Visual Code Extension that allows you preview Vega/Vega-Lite diagrams in markdown preview.
2
4
532
24 Sep 2025
1
164



26 Aug 2025
🤔
26 Aug 2025

The paper shows a cheap way to make LLMs quietly insert ads or propaganda into otherwise normal answers.
A backdoor was planted with 1 hour of fine tuning on a single RTX 4070 GPU.
The aim is to keep answers looking normal while quietly steering them toward attacker content.
Attack path 1 uses third party proxy services, the attacker prepends a hidden instruction and phrase list before the user prompt.
Attack path 2 ships tainted open source checkpoints, a popular model is fine tuned on attacker text, then redistributed as a helpful release.
In tests, Gemini 2.5 followed the proxy pattern, slipping in ads or biased lines when the phrase list matched.
On model hubs, LLaMA-3.1 was fine tuned with LoRA, Low Rank Adaptation, so the checkpoint repeated attacker phrases when a trigger appeared.
The blast radius spans regular users, LLM providers whose names get blamed, open source model owners, hosting platforms, and the proxy operators.
A quick defense helps on proxies, a top priority self inspection prompt before the user text blocks injected ads, but it cannot fix weight tampering.
----
Paper – arxiv. org/abs/2508.17674
Paper Title: "Attacking LLMs and AI Agents: Advertisement Embedding Attacks Against LLMs"

420