
Don't panic! Just build! github.com/codingfisch
Joined December 2013
- Tweets 128
- Following 101
- Followers 195
- Likes 316
24 Photos and videos








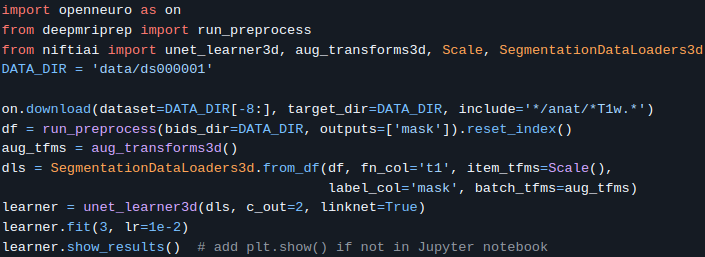
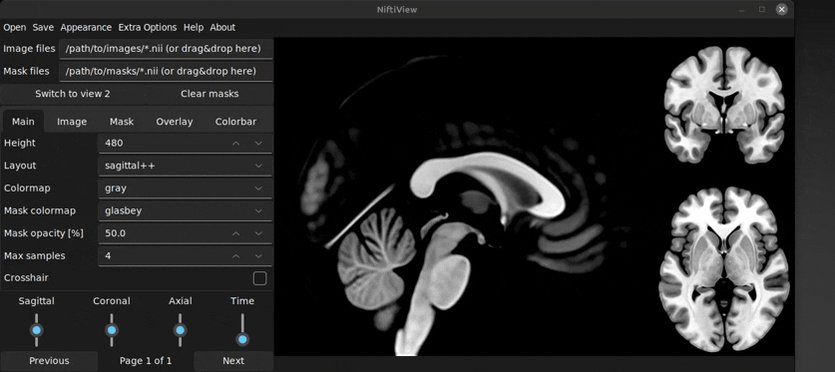
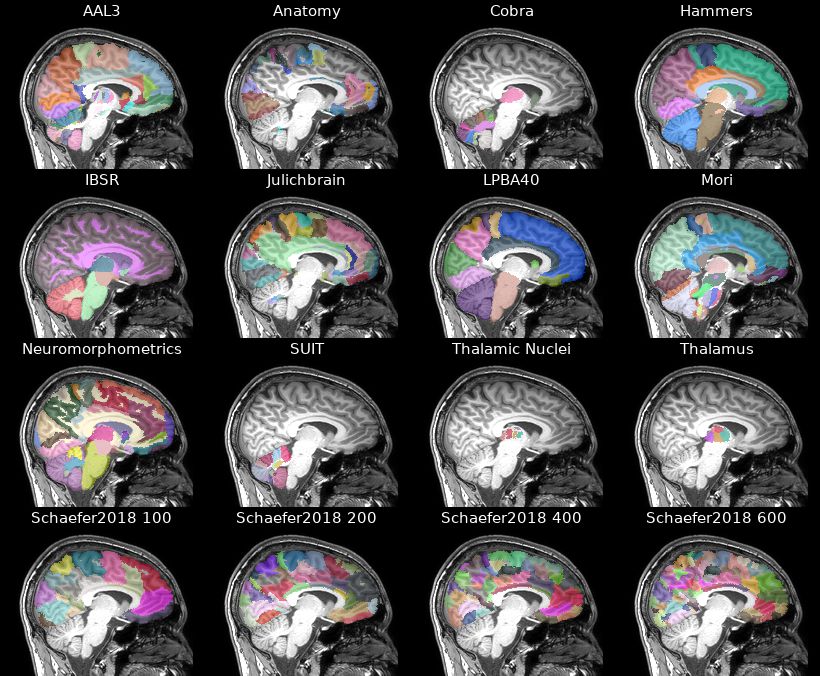


Pinned Tweet

21 Aug 2024
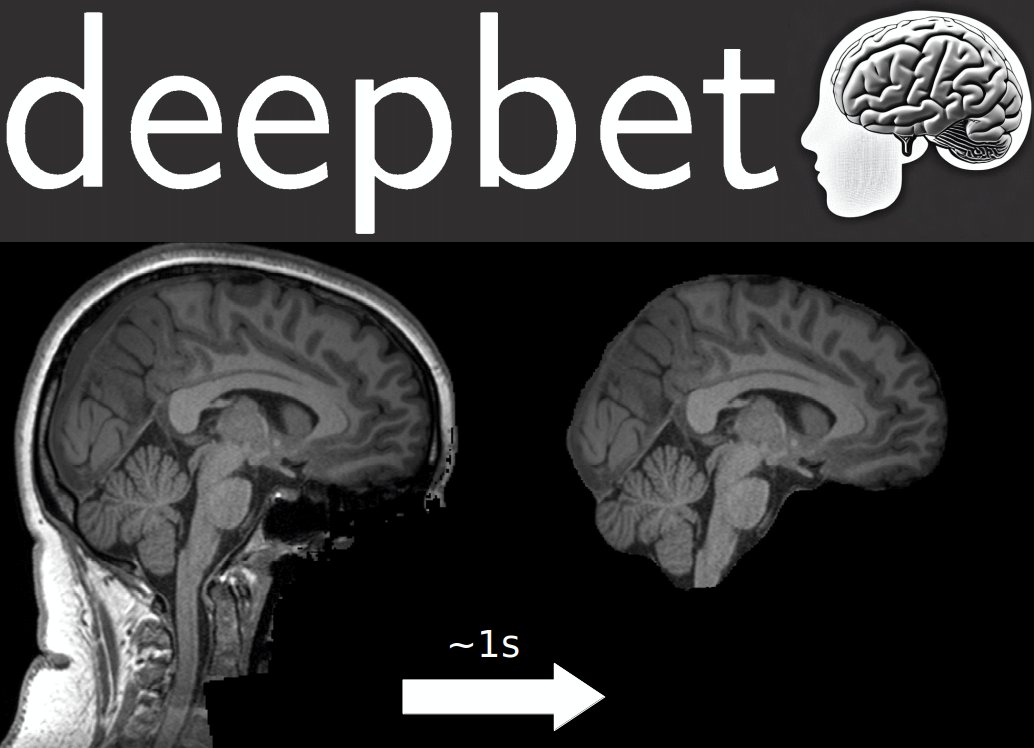
🧠 Exciting news for #neuroscience! Launching deepmriprep: Voxel-based Morphometry (VBM) preprocessing via neural networks in ~10 seconds per #brain image 🚀
🔗 Preprint: arxiv.org/abs/2408.10656
🔗 GitHub: github.com/wwu-mmll/deepmrip…
Install via "pip install deepmriprep"
5
65
280
26,093
Lukas Fisch retweeted

Feb 1
This really speeds up preprocessing and shows - yet again - that neural networks are eating software.
Great work, @codingfisch !! Happy to see this finally published.

📢Out now! @codingfisch and colleagues present deepmriprep, a tool that leverages neural networks to enable 37x faster Voxel-based Morphometry preprocessing of MRI data than existing methods. nature.com/articles/s43588-0…
1
1
156
Jan 30
"deepmriprep: VBM preprocessing via deep neural networks" is published in Nature Computational Science 🧠💻
🔗 Paper: rdcu.be/e1t4N
VBM preprocessing in ~10 seconds per #brain image 🚀
🔗 GitHub: github.com/wwu-mmll/deepm…
Install via "pip install deepmriprep"
2
31
90
5,013
Jan 30
Not convinced? How about this: Christian Gaser (author of CAT12) is building his new SBM toolbox around deepmriprep: github.com/ChristianGaser/T1…
1
5
287
Lukas Fisch retweeted

📢Out now! @codingfisch and colleagues present deepmriprep, a tool that leverages neural networks to enable 37x faster Voxel-based Morphometry preprocessing of MRI data than existing methods. nature.com/articles/s43588-0…
13
28
3,532
Lukas Fisch retweeted

20 Oct 2025
Our GPU stack for both NVIDIA and AMD, aside from minimal pieces of signed firmware, is 100% open source and pure Python except for the compiler. It's not using vendor drivers, frameworks, or libraries. That's why it's so easy to make it work on Mac.
For compilers, on AMD, we use upstream LLVM, and on NVIDIA, we use the NAK compiler from the MESA project. We plan to replace the compiler with pure tinygrad in a year or two as well.
With RANGEIFY merged, our lowering stuff now matches the state of the art, TVM style. We're studying ThunderKittens and TileLang for speed at that level, and should have all this stuff ready in 200 days for the due date of our AMD Llama 405B training contract.
Due to tinygrad's small size and pure Python nature, it's the easiest ML library to make progress on, aka fastest slope of improvement. With Megakernel style for scheduling, MODeL_opt style for planning, and E-graph style for symbolic, we should blow past the state of the art in PyTorch and JAX speed.
If we do that, NVIDIA's moat is over. It's 1000 lines at most to add a new accelerator to tinygrad. And I don't mean to add a new accelerator with help from a kernel driver, compiler, and libraries. Just 1000 lines of software for the *whole* accelerator speaking right on the PCIe BARs, like what tinygrad is doing with the NVIDIA and AMD GPUs now.
25
55
824
60,791
19 Oct 2025
This!
19 Oct 2025

the solution is simple but you aren’t demoralized enough yet geohot.github.io//blog/jekyl…
94
16 Oct 2025
These are special times 📈
16 Oct 2025

Theorem: The maximum possible duration of the computational singularity is 470 years.
Proof: The FLOPs capacity of all computers which existed in the year 1986 is estimated to be at most 4.5e14 (Hilbert et al. 2011). Based on public Nvidia revenue and GPU specs, this capacity has grown to at least 1e22 FLOPs as of 2025. This difference implies an average growth rate of 55% per year since 1986. Now observe that the physical universe can support at most 10^104 FLOPs (Lloyd 2000). Therefore, even if we allow for the discovery of faster than light travel, the computational singularity — i.e., the historical period of elevated social and technological unpredictability driven by rapid growth in worldwide computational capacity — cannot persist for longer than (2025 -1986) (104-22)/log_10(1.55) ~= 470 years.
References:
S. Lloyd, “Ultimate physical limits to computation,” *arXiv preprint quant-ph/9908043*, 1999, doi:10.48550/arXiv.quant-ph/9908043.
M. Hilbert and P. López, “The world’s technological capacity to store, communicate, and compute information,” *Science*, vol. 332, no. 6025, pp. 60–65, Apr. 2011, doi:10.1126/science.1200970.
118
Lukas Fisch retweeted

16 Sep 2025
The curse of dimensionality. The blessing of compositionality.
6
20
276
24,196
Lukas Fisch retweeted

7 Sep 2025
When you store your knowledge and skills as parametric curves (as all deep learning models do), the only way you can generalize is via interpolation on the curve. The problem is that interpolated points *correlate* with the truth but have no *causal* link to the truth. Hence hallucinations.
The fix is to start leveraging causal symbolic graphs as your representation substrate (e.g. computer programs of the kind we write as software engineers). The human-written software stack, with its extremely high degree of reliability despite its massive complexity, is proof of existence of exact truthiness propagation.
65
123
1,235
114,336
Lukas Fisch retweeted

5 Sep 2025
Couldn't agree more with Linus here. Making your code running as fast as possible (or just faster than someone's else code) is the best feeling you can get from programming
The issue that it is extremely hard to find the project that will pay you for instruction level efficiency
70
349
4,547
416,713
20 Jul 2025
🧐view(your_data) in the terminal🧐
"pip install viiew" for a
- colorfull
- scrollable
- sortable
view of your array/Tensor/DataFrame!
Supports numpy, pandas, torch, jax & @__tinygrad__ and is tiny: 4.1kB (0 dependencies)!
147
Lukas Fisch retweeted
13 Jul 2025
Our thesis at Ndea: simple theories should be discoverable using little data and little compute.
And everything humans have ever invented is a fairly simple composition of fairly simple theories.
13 Jul 2025

AI can't figure out the inverse square law looking at 10M solar systems, Newton figured it out looking at 1
41
63
903
136,152
Lukas Fisch retweeted

5 Jun 2025
NCCL sending the loss value from the last pipeline parallel stage back to rank 0 so the user can print it
5 Jun 2025

6
20
315
19,850
Lukas Fisch retweeted

19 May 2025
I’m speaking at 2pm on Wednesday at the Upper Bound AI conference. I am in the “business of AI” track, but my talk will be about reinforcement learning research.
Video should be available after the conference.
40
59
1,351
124,058
13 Mar 2025
🚀 Release of tinygym: RL in tinygrad 🚀
It learns Pong in 5 minutes on a 3090!
Like in flashrl you can
✅ Play against your RL agent ⚔️
✅ Add your env by adding one .pyx file!
Hopefully leads to another RL stream from @realGeorgeHotz @__tinygrad__
github.com/codingfisch/tinyg…
1
4
377
12 Mar 2025
🚀 flashrl version 0.2.0 released 🚀
✅ RL with millions of steps/second 💨
✅ Play against your RL agent ⚔️
✅ Wanna add your env? Add one .pyx file!
...and it uses emoji rendering 😙👌
1
169
12 Mar 2025
Running RL was never easier! Here is the whole script run in the GIF
1
130
8 Mar 2025
🚀 Launching flashrl: RL in seconds 🚀
✅ Train with ~3M steps per second 💨
✅ Contains only ~200 lines of code 🤯
✅ Wanna add your env? Add one .pyx file!
Free your 🧠 RAM from boilerplate!
1
131
8 Mar 2025
Run train.py to learn Pong AlphaZero-style (1 vs 1)!
My 3090 learns it in 3 seconds 💨
How long does it take on your system?
github.com/codingfisch/flash…
78