
Joined January 2026
- Tweets 99
- Following 22
- Followers 429
- Likes 94
22 Photos and videos



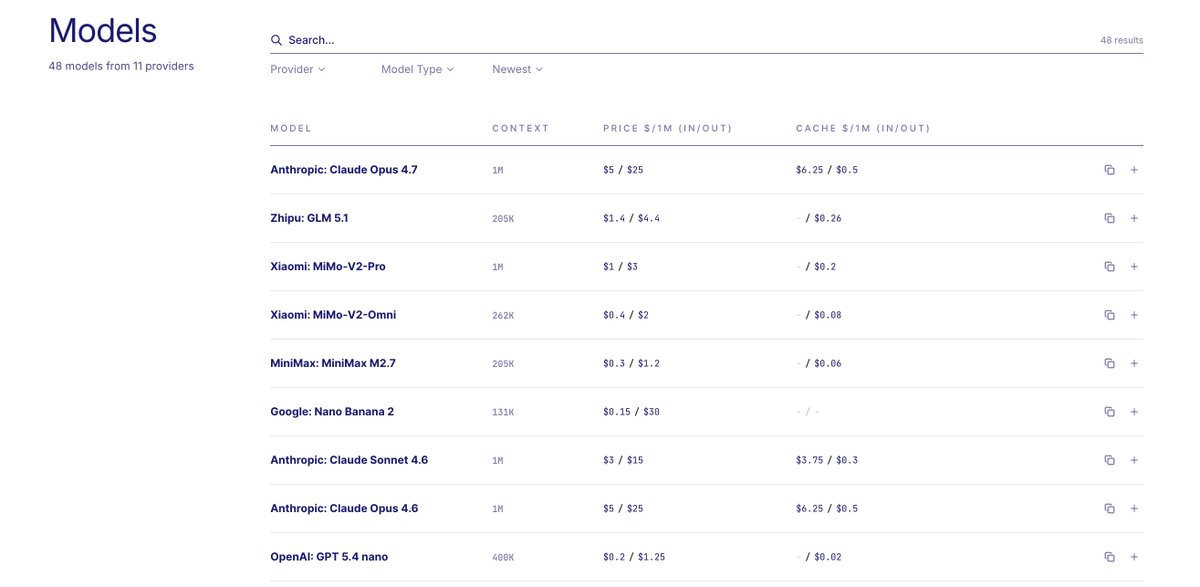
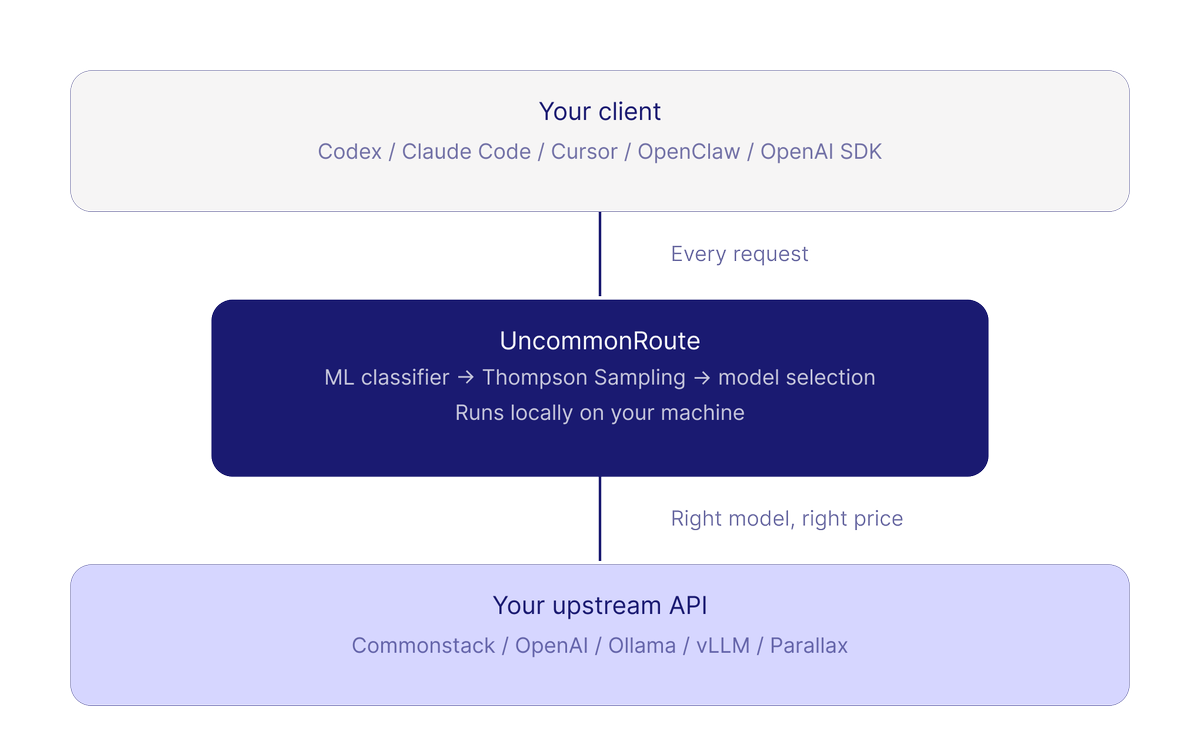
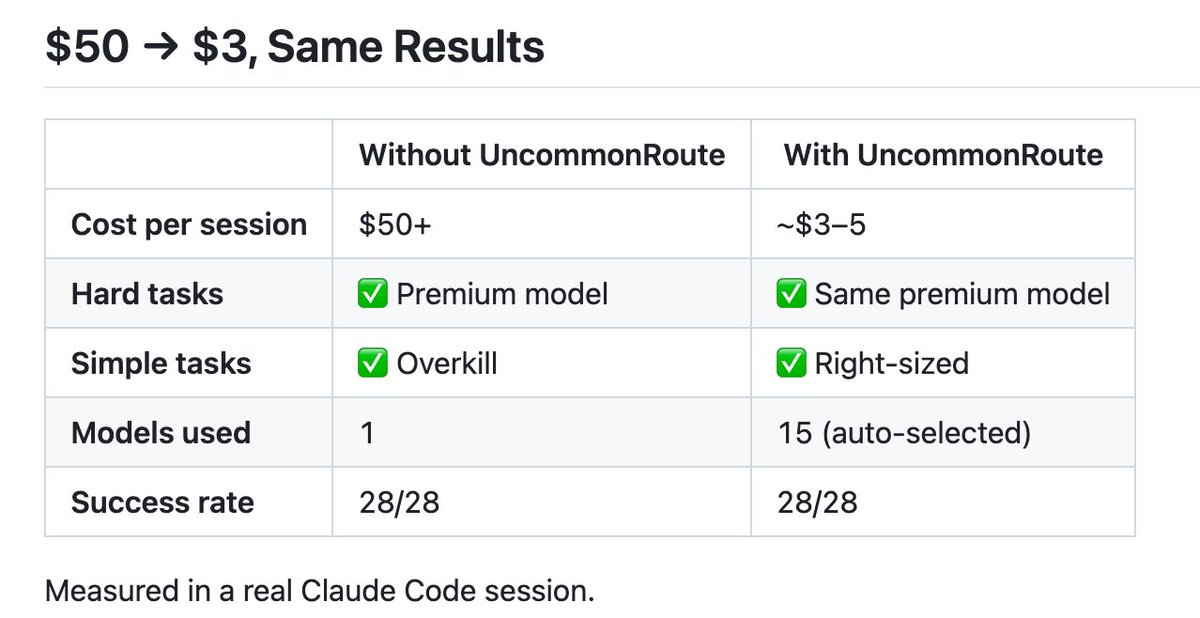





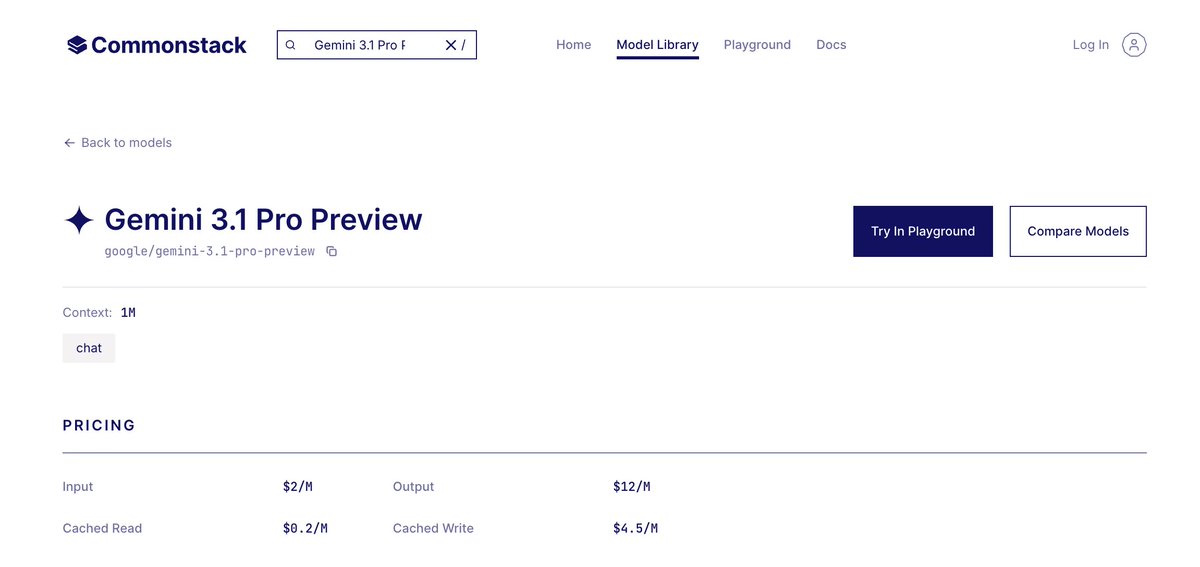


Pinned Tweet

May 18
Fraction of the bill. Same results.
Fully local, open source, works with any client.
Just > pipx install uncommon-route
github.com/CommonstackAI/Unc…
39
44
135
447,877
Commonstack retweeted

May 23
A lot of routing work evaluates isolated prompts, but real agent systems are fundamentally multi-step and budget-constrained. Cool to see benchmarks moving toward execution-grounded, end-to-end evaluation instead of just token-level proxies.
TwinRouterBench is a strong step toward realistic agentic routing evaluation — especially the separation between static supervision and dynamic SWE-bench execution. Excited to see where this goes!
May 23

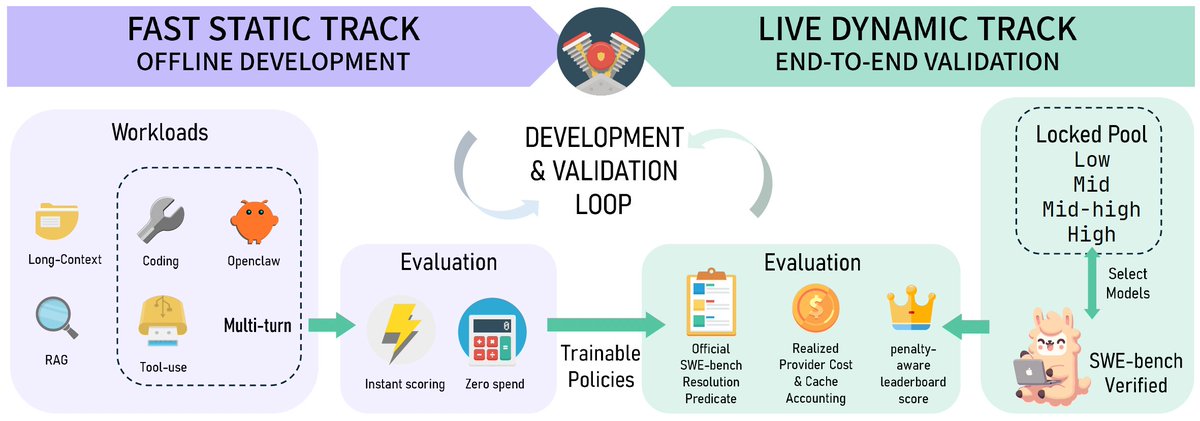
Excited to share that TwinRouterBench has been accepted to the #RLEval Workshop at #CAIS2026 🎉
As LLM apps become long-horizon agents, one request can trigger many model calls across planning, tool use, retrieval, coding, and verification.
That makes per-step LLM routing a core infrastructure problem: sending each call to the cheapest sufficient model without breaking downstream success.
TwinRouterBench introduces:
⚡ Static track: 970 router-visible prefixes from 520 instances across SWE-bench, BFCL, mtRAG, QMSum, and PinchBench
🚀 Dynamic track: live SWE-bench Verified evaluation with official task resolution realized API spend
Key result: a router trained on static labels achieves comparable SWE-bench resolve rate while cutting API cost by ~53% vs. an unrouted Opus 4.6 baseline.
Paper: arxiv.org/html/2605.18859v1
Code: github.com/CommonstackAI/Twi…
Dataset: huggingface.co/datasets/Amor…
Website: commonstackai.github.io/Twin…
#LLM #AgenticAI #LLMRouting #Benchmark #SWEBench
1
3
10
1,479
May 25
Great to see TwinRouterBench accepted to the #RLEval Workshop at #CAIS2026!
Per-step routing is quickly becoming essential infrastructure for agentic systems: each planning, coding, retrieval, and verification call should use the cheapest sufficient model without hurting final task success.
Proud to open-source TwinRouterBench and contribute a practical benchmark for this problem.
May 23
Excited to share that TwinRouterBench has been accepted to the #RLEval Workshop at #CAIS2026 🎉
As LLM apps become long-horizon agents, one request can trigger many model calls across planning, tool use, retrieval, coding, and verification.
That makes per-step LLM routing a core infrastructure problem: sending each call to the cheapest sufficient model without breaking downstream success.
TwinRouterBench introduces:
⚡ Static track: 970 router-visible prefixes from 520 instances across SWE-bench, BFCL, mtRAG, QMSum, and PinchBench
🚀 Dynamic track: live SWE-bench Verified evaluation with official task resolution realized API spend
Key result: a router trained on static labels achieves comparable SWE-bench resolve rate while cutting API cost by ~53% vs. an unrouted Opus 4.6 baseline.
Paper: arxiv.org/html/2605.18859v1
Code: github.com/CommonstackAI/Twi…
Dataset: huggingface.co/datasets/Amor…
Website: commonstackai.github.io/Twin…
#LLM #AgenticAI #LLMRouting #Benchmark #SWEBench
10
13
33
1,982

May 19
How do you evaluate an LLM router fairly?
Most benchmarks look at prompts, but routers operate at an agentic-step level. A router that saves money but breaks the task could be worse than no router.
We open-sourced TwinRouterBench to measure this honestly.
🧵
6
17
46
2,287
May 19
Conflict of interest? acknowledged!
We know our router (UncommonRoute) currently leads the leaderboard.
Open submissions, locked pricing, public scoring code. If a different router wins, the leaderboard will say so.
3
8
205
May 19
Step-level routing matters. The benchmark to measure it is open today.
Bench: github.com/CommonstackAI/Twi…
The current leader: github.com/CommonstackAI/Unc…
Paper coming soon on ArXiv.
1
6
158
May 6
Run Claude Code with Commonstack in 4 steps:
- generate an API key
- set 4 environment variables
- run claude
- /status to verify
Set it up now in 5 minutes with @alex_mirran.
8
21
41
3,561
Apr 30
GPT-5.5 is live on Commonstack.ai! 🚀🚀
Use the strong reasoning and coding capabilities of GPT-5.5 in your application or with your favorite agentic harness.
3
14
29
936
Apr 30
Here's a guide for using Commonstack with your OpenClaw agent -> docs.commonstack.ai/integrat….
1
9
196
Apr 24
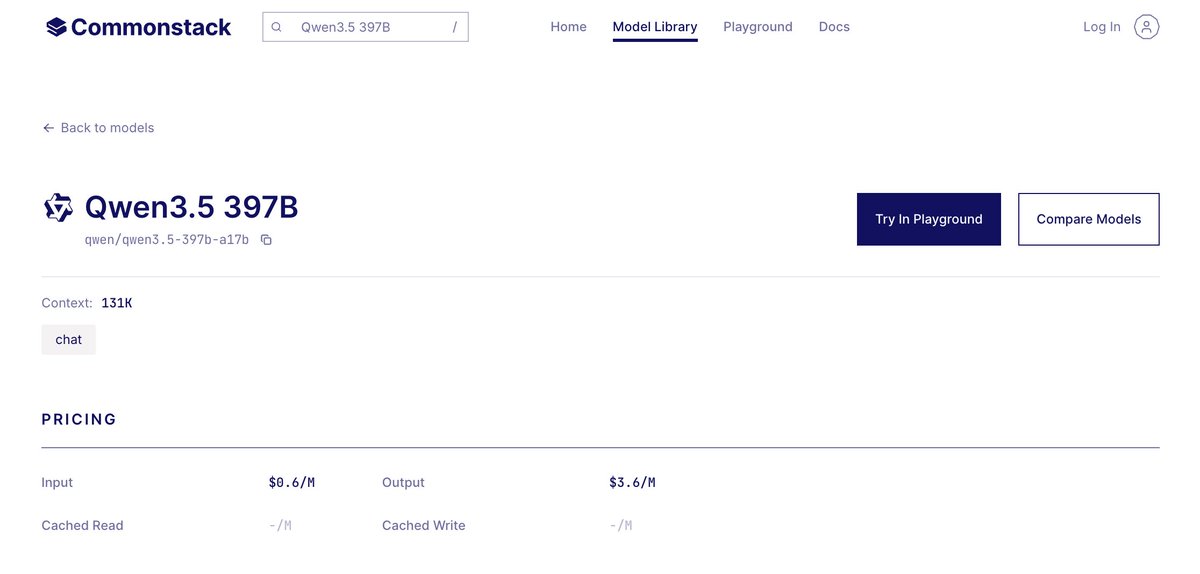
DeepSeek-V4-Flash is now live on commonstack.ai
Time to feed your agents!
Apr 24

DeepSeek-V4-Flash
🔹 Reasoning capabilities closely approach V4-Pro.
🔹 Performs on par with V4-Pro on simple Agent tasks.
🔹 Smaller parameter size, faster response times, and highly cost-effective API pricing.
3/n
2
5
13
830
Apr 22
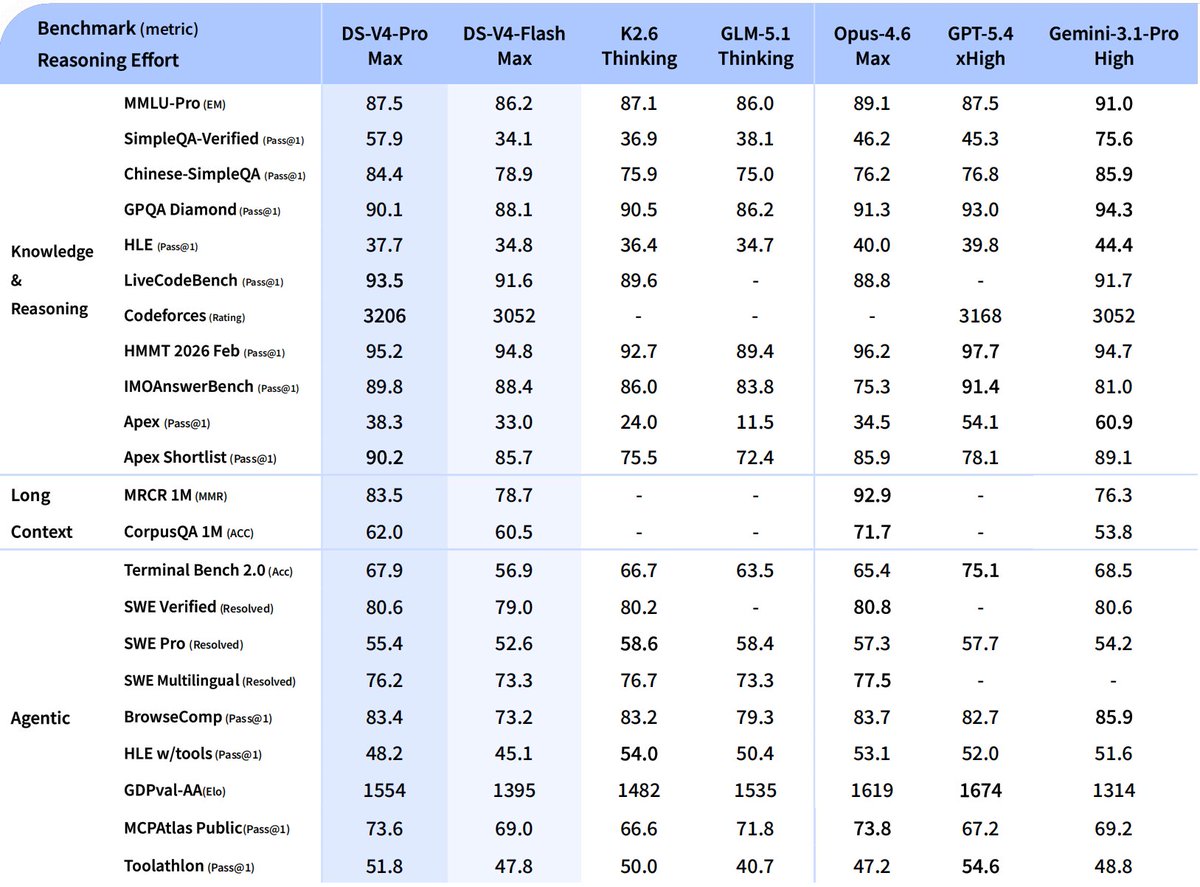
Kimi K2.6 is blowing away benchmarks like Humanity's Last Exam and SWE-Bench Pro!
Now available on Commonstack.ai.
Apr 20

Meet Kimi K2.6: Advancing Open-Source Coding
🔹Open-source SOTA on HLE w/ tools (54.0), SWE-Bench Pro (58.6), SWE-bench Multilingual (76.7), BrowseComp (83.2), Toolathlon (50.0), Charxiv w/ python(86.7), Math Vision w/ python (93.2)
What's new:
🔹Long-horizon coding - 4,000 tool calls, over 12 hours of continuous execution, with generalization across languages (Rust, Go, Python) and tasks (frontend, devops, perf optimization).
🔹Motion-rich frontend - Videos in hero sections, WebGL shaders, GSAP Framer Motion, Three.js 3D.
🔹Agent Swarms, elevated - 300 parallel sub-agents × 4,000 steps per run (up from K2.5's 100 / 1,500). One prompt, 100 files.
🔹Proactive Agents - K2.6 model powers OpenClaw, Hermes Agent, etc for 24/7 autonomous ops.
🔹Claw Groups (research preview) - bring your own agents, command your friends', bots & humans in the loop.
-
K2.6 is now live on kimi.com in chat mode and agent mode.
For production-grade coding, pair K2.6 with Kimi Code: kimi.com/code
-
🔗 API: platform.moonshot.ai
🔗 Tech blog: kimi.com/blog/kimi-k2-6
🔗 Weights & code: huggingface.co/moonshotai/Ki…

6
16
654