
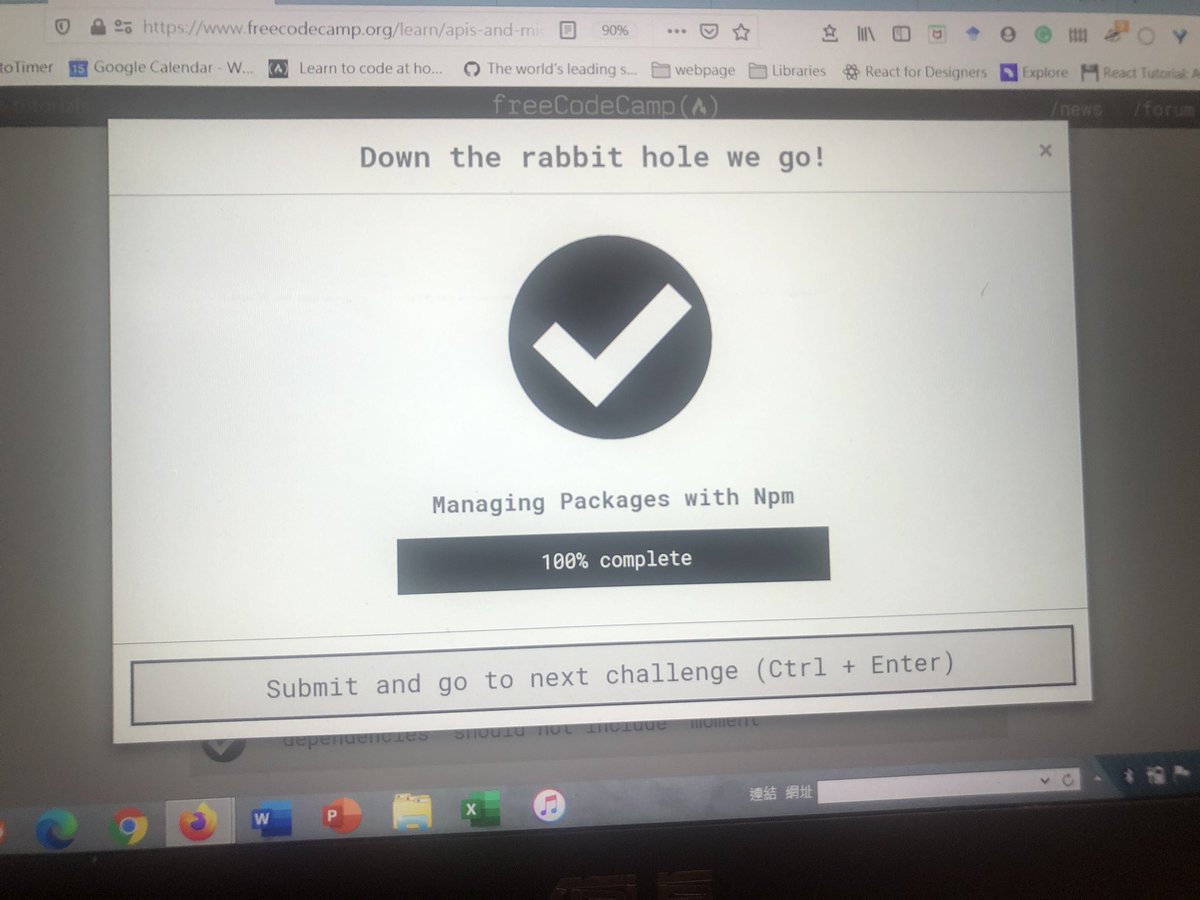
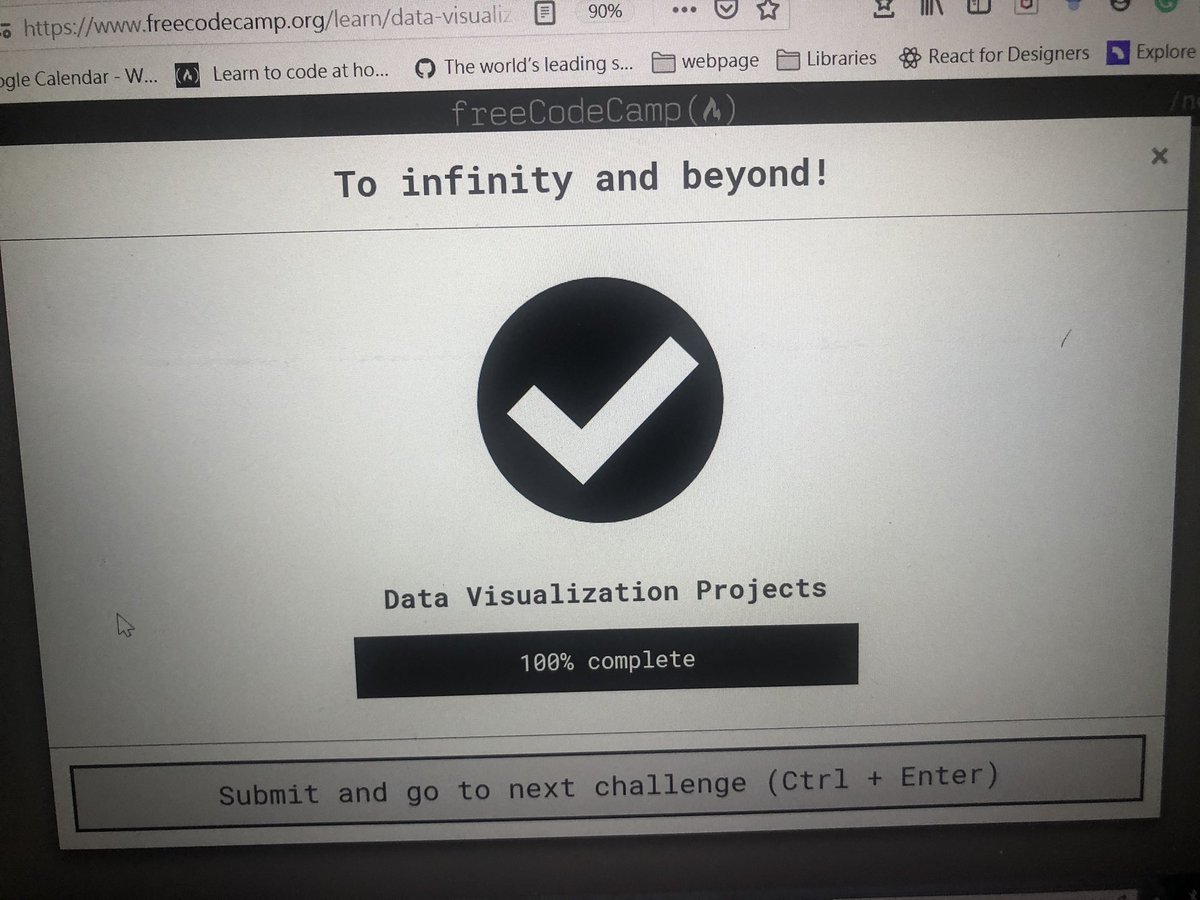
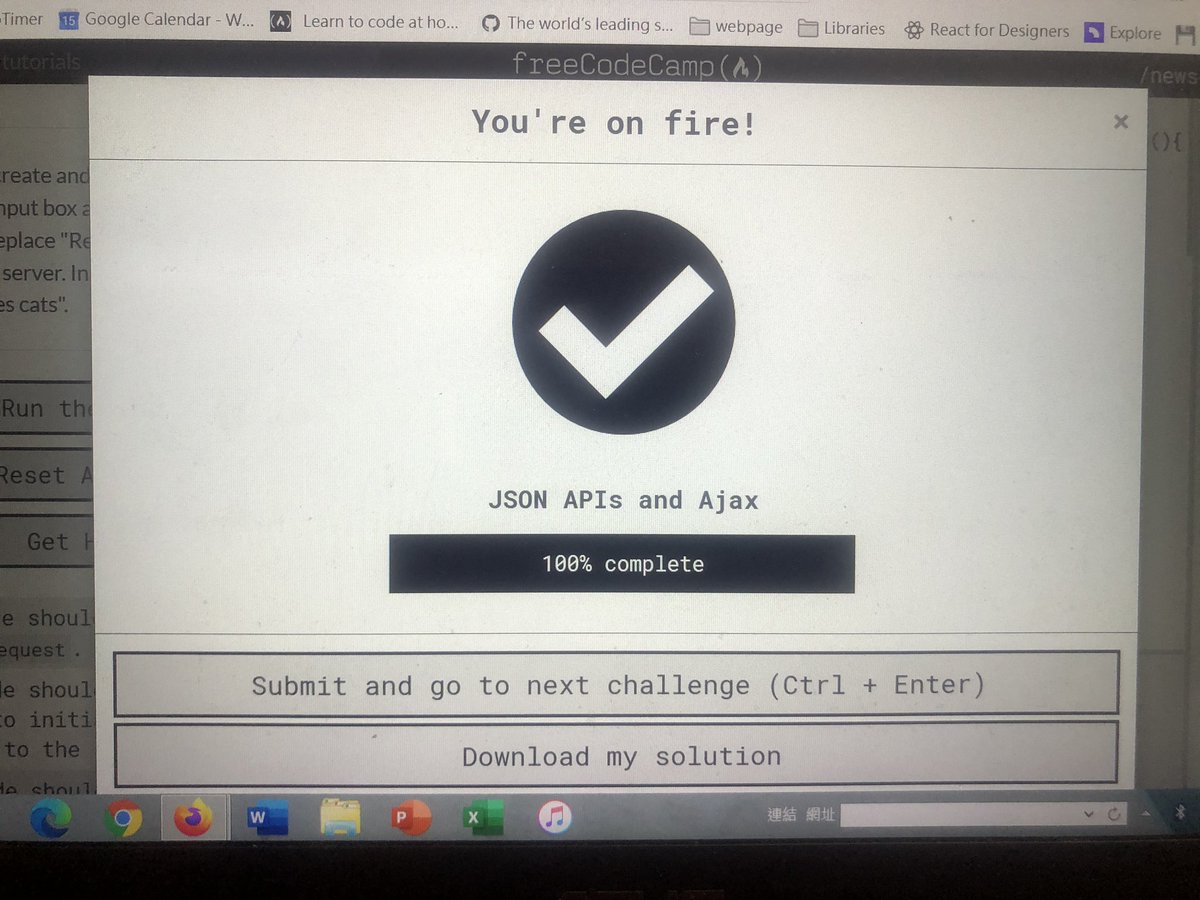
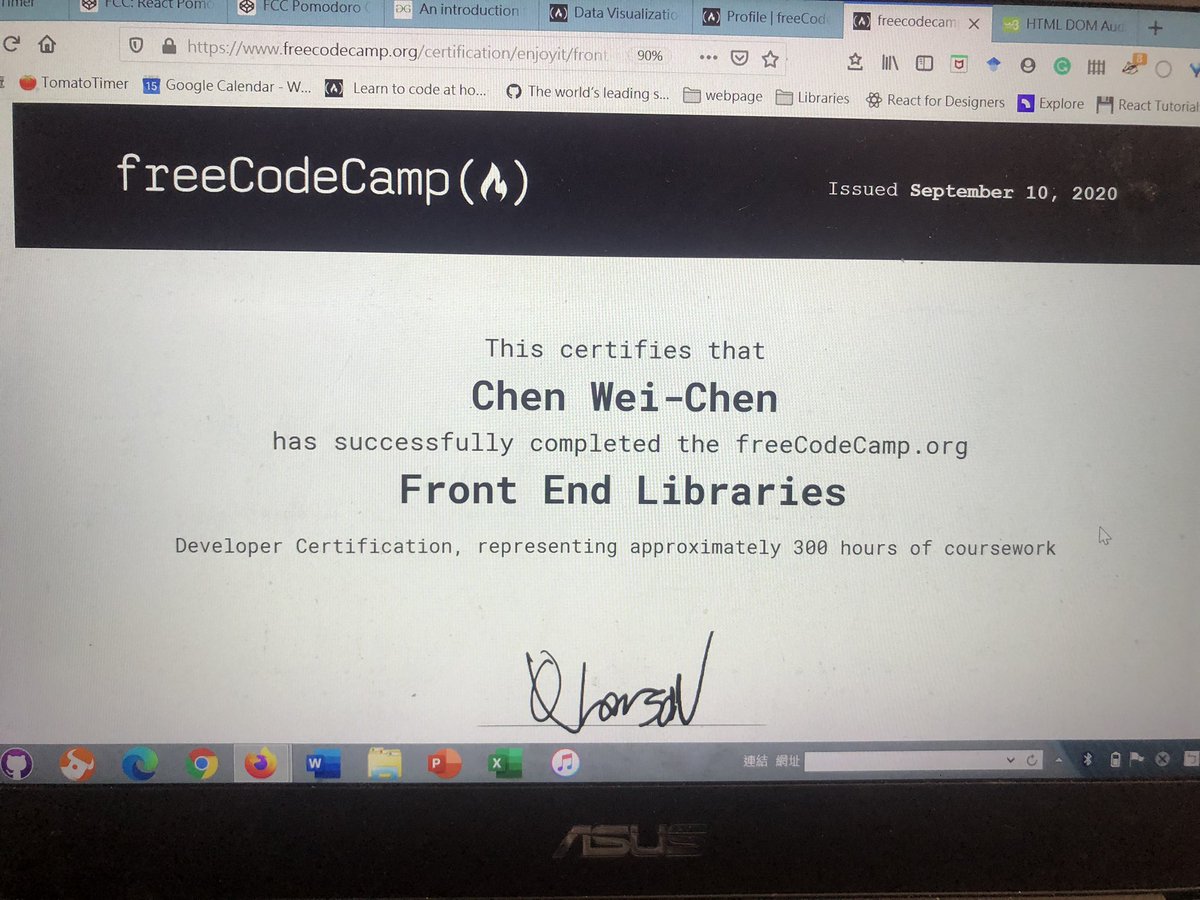
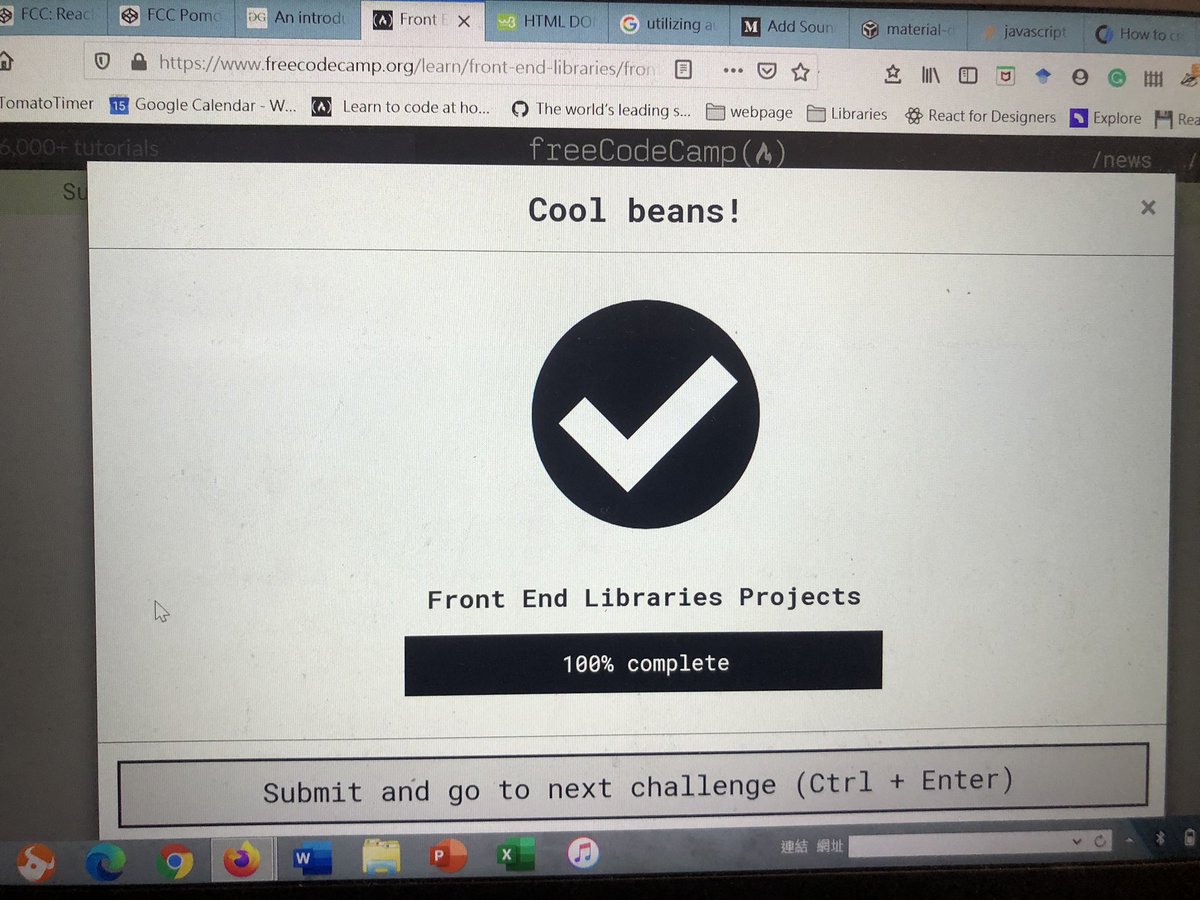
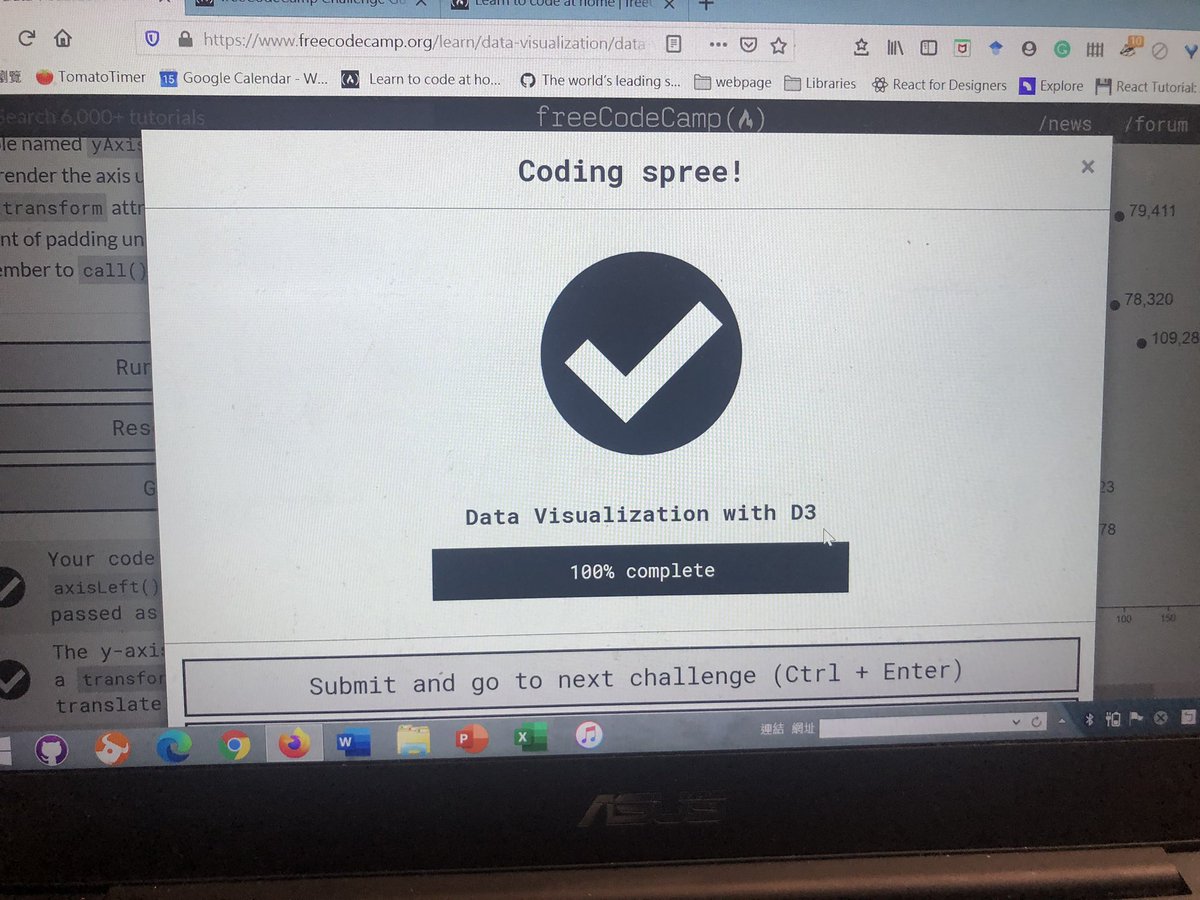
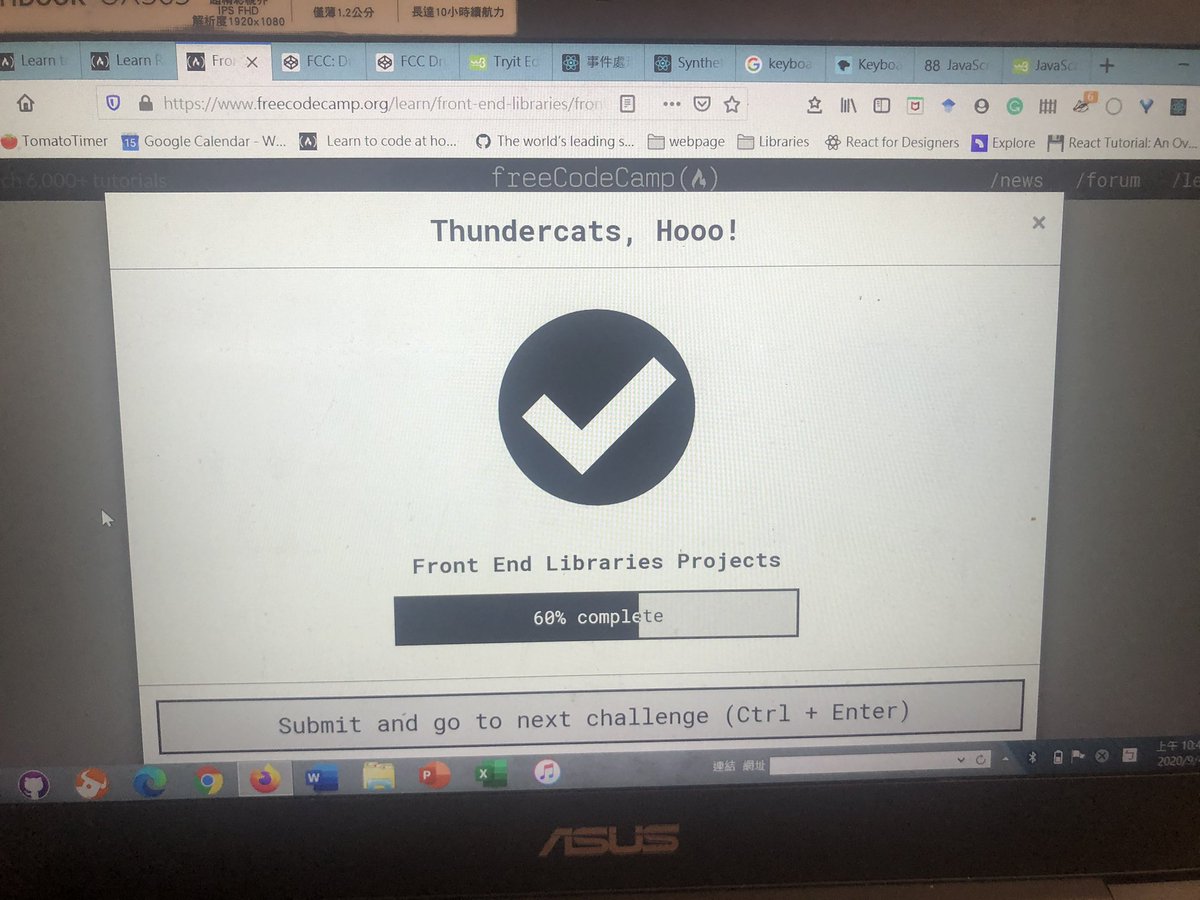
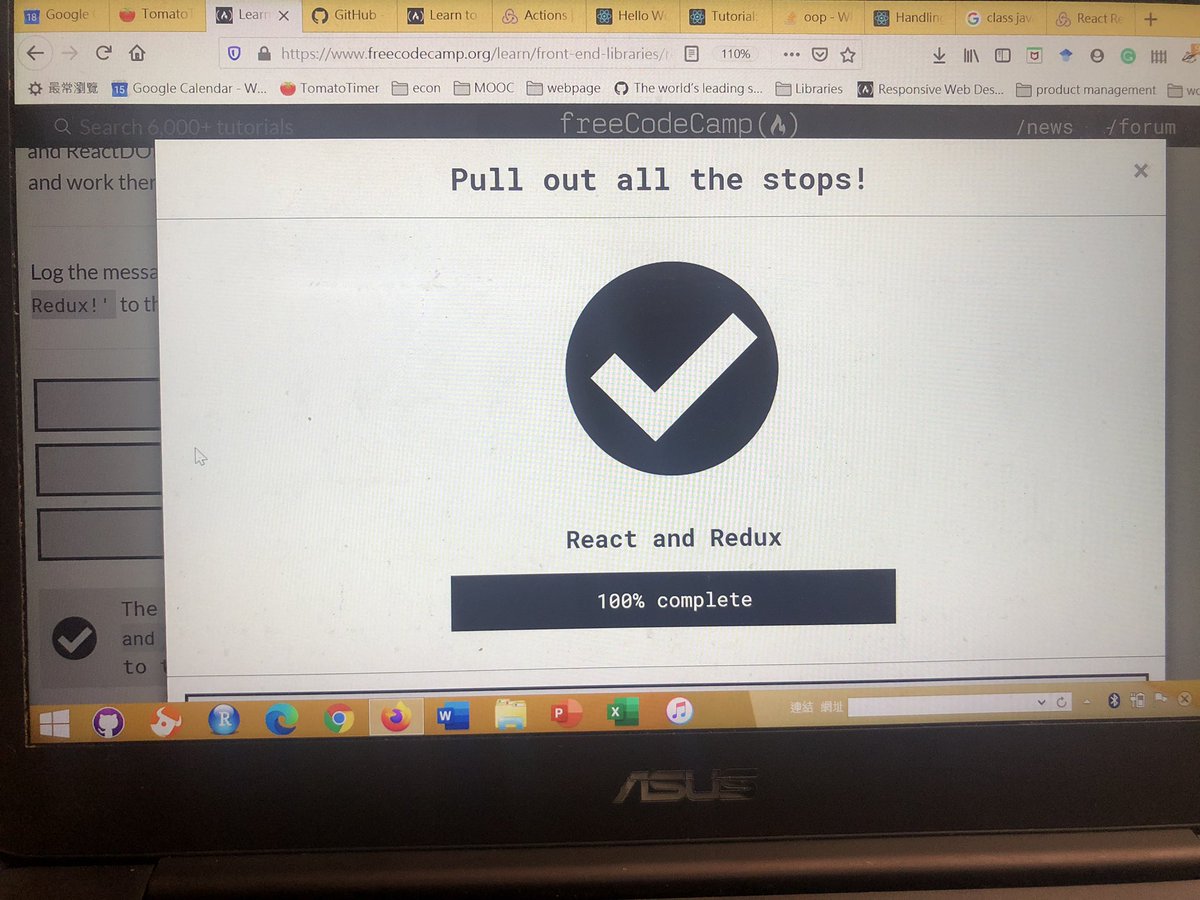
Lexical Analysis
Joined July 2020
- Tweets 1,045
- Following 3,123
- Followers 74
- Likes 44,621
28 Photos and videos





Compiler… retweeted

May 16
Before jumping into books like DDIA or Database Internals, it helps to understand the systems layer these designs are built on.
A lot of the design of such data-intensive systems is based on virtual memory: page tables, page faults, mmap, the page cache, swapping, NUMA placement, TLBs, and the tradeoffs between what the OS wants and what the database wants.
My latest article is a ~25,000-word mini-book on virtual memory.
It starts from first principles and goes all the way down to advanced topics like NUMA placement and performance debugging with tools like perf and /proc.
I also wrote it differently: as a dialogue between a user-space process and the kernel.
Most treatments of virtual memory are dry and fact-heavy. I wanted this one to feel more like a story, while still being technically deep.
Link below.

24
172
1,426
85,985


Compiler… retweeted

Apr 23
A talk I gave a few weeks ago.
Software fundamentals matter more than ever. Here's why:
youtube.com/watch?v=v4F1gFy-…
37
143
1,321
315,978
Compiler… retweeted

Apr 14
Spain's egregious Cloudflare blocks are breaking Docker now 💀

140
463
3,910
1,020,097
Compiler… retweeted

Apr 2
Paper: The Path of a Packet Through the Linux Kernel
net.in.tum.de/fileadmin/TUM/…
Computer Networking is one of my favourite topics - I even did my final-year project on MPLS/LDP on a Linux box. That meant a lot of hands-on NIC configuration: setting up interfaces in various modes so packets could be routed correctly over LDP. And tracing how packet buffers are handled to implement zero-copy wherever possible.
This paper is a deep dive into how packets traverse the kernel - the kind I wish I'd had back then. Worth saving for a careful read.

1
93
594
48,633
Compiler… retweeted

Apr 2
I recommend looking into 𝚘𝚙𝚎𝚗𝚝𝚞𝚒

why has no one vibed up really good local otel tooling
i want to be able to look at all these traces during local dev
57
96
2,369
280,449
Compiler… retweeted
Apr 1
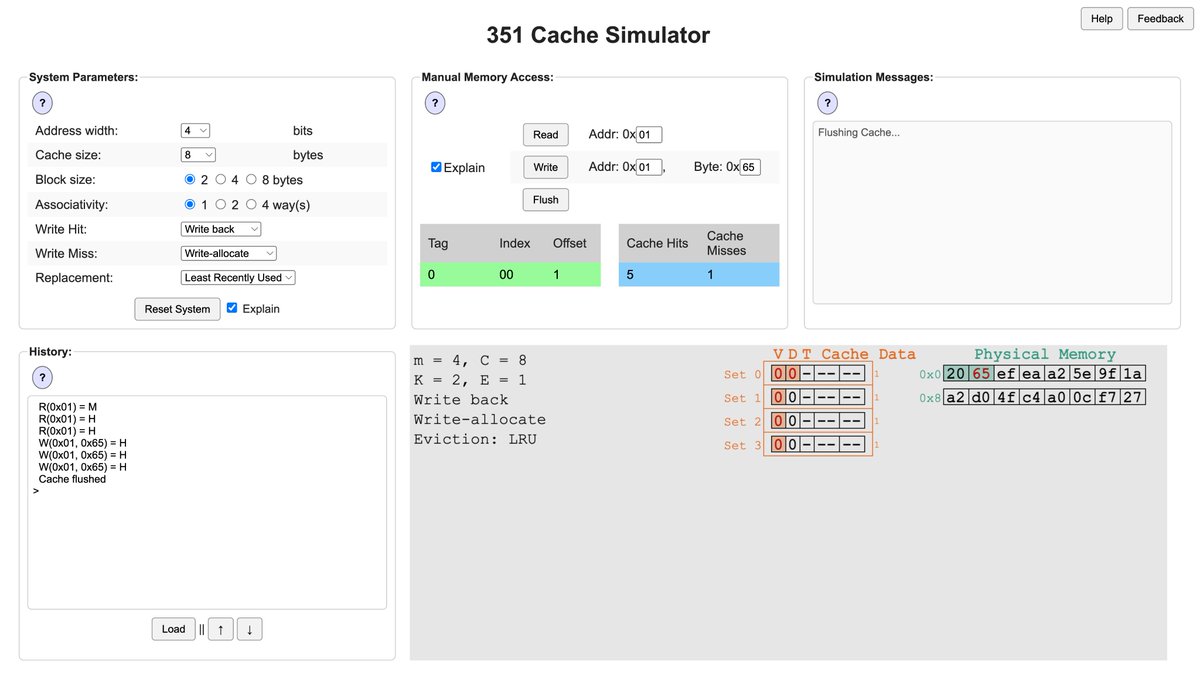
The CSE 351 Cache Simulator is the best hands-on way to understand cache hits, misses, LRU eviction, and write policies.
Tweak the parameters, step through memory accesses, watch it all happen live.
courses.cs.washington.edu/co…
Mar 29

What Every Programmer Should Know About Memory by Ulrich Drepper
people.freebsd.org/~lstewart…

48
408
23,716
Compiler… retweeted

Mar 30
almost 11 years ago i watched this talk on my lunch break. it ended up being one of the most influential videos i've ever watched.
been workflow pilled ever since
youtube.com/watch?v=xDuwrtwY…
19
52
1,015
139,938
Compiler… retweeted

Mar 23
I disagree: stevekrouse.com/precision
Code is how we get precise abstractions into human heads
Saying code isn't important is like saying mathematical notation isn't important
There's a reason we glorify f = ma or e = mc2. Formalism holds immense power for mastering complexity
Mar 22

Code is an output. Nature is healing.
For too long we treated code as input. We glorified it, hand-formatted it, prettified it, obsessed over it.
We built sophisticated GUIs to write it in: IDEs. We syntax-highlit, tree-sat, mini-mapped the code. Keyboard triggers, inline autocompletes, ghost text. “What color scheme is that?”
We stayed up debating the ideal length of APIs and function bodies. Is this API going to look nice enough for another human to read?
We’re now turning our attention to the true inputs. Requirements, specs, feedback, design inspiration. Crucially: production inputs. Our coding agents need to understand how your users are experiencing your application, what errors they’re running into, and turn *that* into code.
We will inevitably glorify code less, as well as coders. The best engineers I’ve worked with always saw code as a means to an end anyway. An output that’s bound to soon be transformed again.
53
104
1,370
91,088
Compiler… retweeted

Mar 11
Expectation: the age of the IDE is over
Reality: we’re going to need a bigger IDE
(imo).
It just looks very different because humans now move upwards and program at a higher level - the basic unit of interest is not one file but one agent. It’s still programming.
Mar 11

tmux grids are awesome, but i feel a need to have a proper "agent command center" IDE for teams of them, which I could maximize per monitor. E.g. I want to see/hide toggle them, see if any are idle, pop open related tools (e.g. terminal), stats (usage), etc.
831
827
10,530
2,484,466
Compiler… retweeted

Mar 9
oops did it again
Mar 9

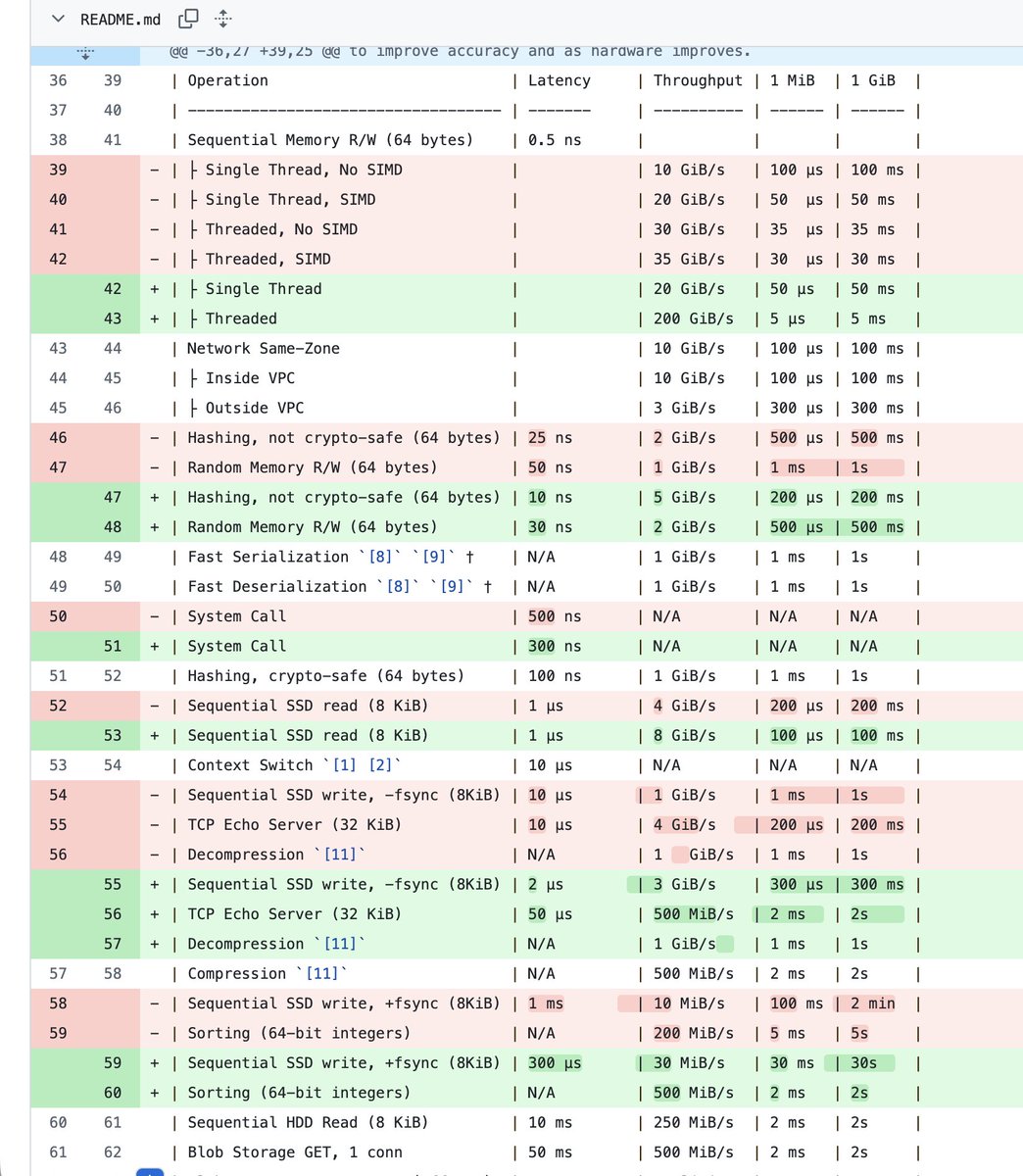
updating napkin math benchmarks, it's been too long
github.com/sirupsen/napkin-m…
using c4-standard-48-lssd now as a representative machine (turbopuffer sponsored)
previously a dinky 6 core 2019 VM
11
30
445
99,480
Compiler… retweeted

Mar 2
If you want to become a database genius among your peers, you need to read this article. It offers invaluable insights that could mark the beginning of your breakthrough in the database field.

3
87
974
47,357
Compiler… retweeted

Mar 1
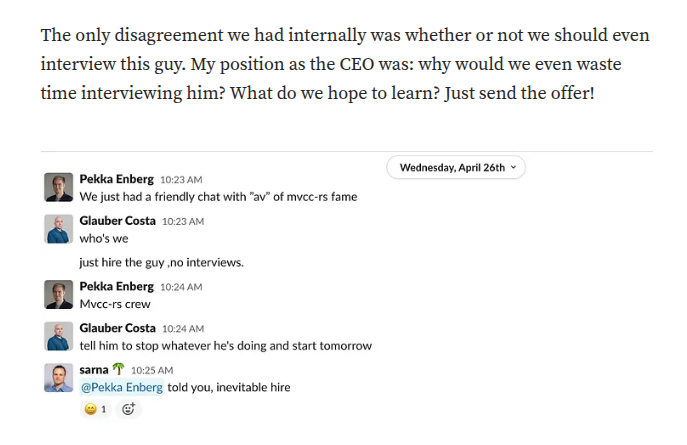
Open-source contributions can literally get you hired...
with zero interviews
29
49
2,291
266,067
Compiler… retweeted

During his talk this morning in the #Go devroom at #FOSDEM2026 (10:30 AM CET), software engineer Valentyn Yukhymenko explores how Reflection actually works under the hood in @golang
bloom.bg/3Z3OwzA
#golang #GoRuntime #opensource

11
78
22,970
Compiler… retweeted

12
142
1,106
430,022
Compiler… retweeted

Jan 31
I'm Boris and I created Claude Code. I wanted to quickly share a few tips for using Claude Code, sourced directly from the Claude Code team. The way the team uses Claude is different than how I use it. Remember: there is no one right way to use Claude Code -- everyones' setup is different. You should experiment to see what works for you!
924
5,836
50,777
9,188,450
Compiler… retweeted

Jan 22
@PostgreSQL has long powered core @OpenAI products like ChatGPT and the API. Over the past year, our production load grew 10× and keeps rising. Today we run a single primary with nearly 50 read replicas in production, delivering low double-digit millisecond p99 client-side latency and five-nines availability. In our latest OpenAI Engineering blog, we unpack the optimizations we made to to scale @Azure PostgreSQL to millions of queries per second for more than 800M ChatGPT users. Check out the full post here: openai.com/index/scaling-pos…
41
189
1,306
468,316
Compiler… retweeted

Jan 22
4
26
395
53,906
Compiler… retweeted
Jan 19
Postgres vs MySQL Transactions Log-based writes (Database Internals Chapter 5) x.com/i/broadcasts/1ypKdqEAb…
34
270
55,963
