
I make software, break software and make software that breaks software. netograph.io mitmproxy.org binvis.io corte.si
Joined February 2008
- Tweets 6,577
- Following 225
- Followers 3,390
- Likes 39,401
710 Photos and videos









Pinned Tweet

Jan 27
Announcing spacecurve, a space-filling curve library with a web native interactive playground.

1
3
5
992

Jun 13
The irony is that this is the direct result of Dario and Anthropic's own scare-marketing of Mythos. It was always irresponsible, but now it turns out to also be stupid and self-defeating.
Jun 13

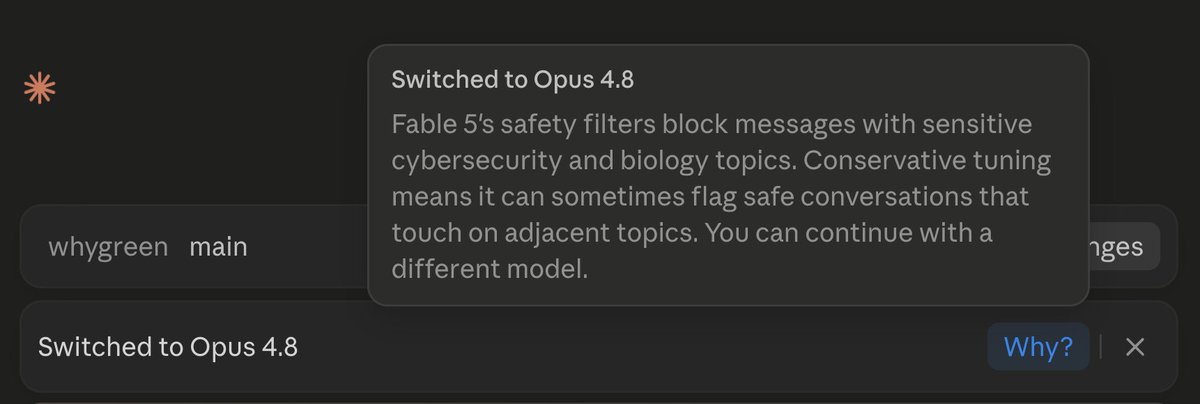
The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
4
137
Jun 13
I'm not American. Most people I care about are not American. Much of AI discourse about capabilities, safety, social adaptation, UBI, job losses and the future of humanity is explicitly US-focused and US-first - we urgently need a pan-human, global perspective.
Jun 13
The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
1
80
Jun 11
I can trust Fable to make the correct, tasteful decision about 15% more than Codex 5.5. Turns out that's the difference between spending an hour at my desk writing a tight spec, and giving a high-level direction then going for a walk with my dog.
2
114
Jun 11
I have carefully curated X lists that track current staff from all the major AI houses. The Anthropic list is... oddly quiet today.
x.com/i/lists/18928489709947…

102
Jun 9
The bio-safety filter on Fable is incredibly obtuse. I have a totally innocuous project looking at pigment colors in photosynthesis, and Fable refuses to even read the papers for discussion.
2
133
Jun 9
One possibility is that iterating our way out of slop will never be economically feasible, and once models get strong enough we'll just rewrite everything. This would be a really bad outcome, and an enormous amount of time and tokens would go to waste.
1
2
104
Jun 9
Well, Fable is the first model that seems to give me genuine structural improvements on slopcode. I'm watching right now as it excavates deep abstractions and restructures the codebase around them - no other model does this.
1
83
Jun 9
It's too early to tell what the limits are, but if my first impressions hold and Fable 1 is a bit smarter and, say, 3x cheaper, we may be able to hoist ourselves out of the slop morass.
58
Jun 9
An important question I've been keeping an eye on: will models ever be able to rescue slop projects? Until today, prompting models to deslop slopcode just gave... higher definition slop.
1
1
106
Jun 9
Claude Code's enduring bugginess is in the same mysterious category as the profound weakness of Google's coding models. Can they fix it and won't? Or are they trying and can't? Both answers are fascinating.
2
145
Jun 9
In my early tests Fable is a monster, but it leaves me with questions. If Anthropic has this enormously capable model on tap... why is Claude Code so buggy and incomplete? I can fire it up right now and find 10 bugs in 10 minutes - why are they not all fixed?
3
153
Jun 4
Disappointing. Timid, backward-looking recommendations completely inadequate to the moment, with a side-helping of peevish, finger-wagging self-interest. If this is how the mathematical community chooses to respond, it will be completely overtaken by what's coming.
leidendeclaration.ai/
1
116
Jun 3
Grok CLI is an excellent harness, and Composer 2.5 is a good, fast workhorse for quick refactoring (though too weak for deep work). I'm reaching for it more and more, which is surprising me.
1
119
Jun 1
Two flippenings, in two directions. First, Claude used to be more personally pleasant than Codex. Now it's a nitpicky, unenthusiastic, perpetually caveating scold. Codex is still a low-affect worker bee but I can work with that.
1
3
274
Jun 1
Second, Codex used to be the model I could set to work without worrying about running out of a $200 subscription. Now, my data shows Claude is the model that I can set to work at a rate of about 10% of weekly quota per day, while for the same work Codex will eat 30% and run out.
1
267
May 29
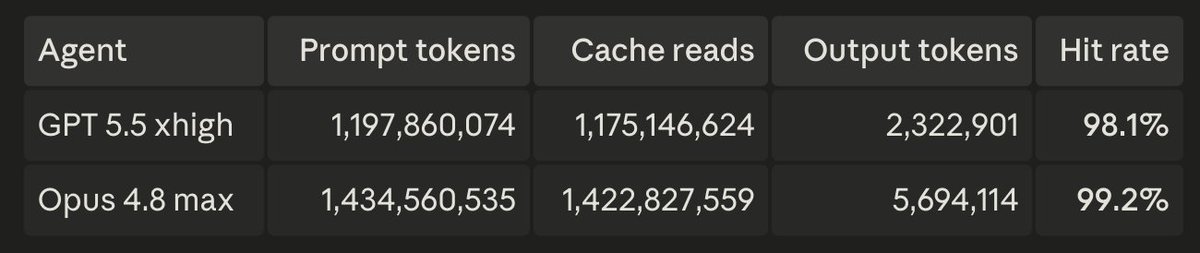
One fascinating finding. Both agents are on their respective $200 tiers. Opus is using about 1/10th of the weekly quota per day on max thinking, while GPT 5.5 is using about 1/4 weekly quota per day on xhigh. Unexpected.
May 29

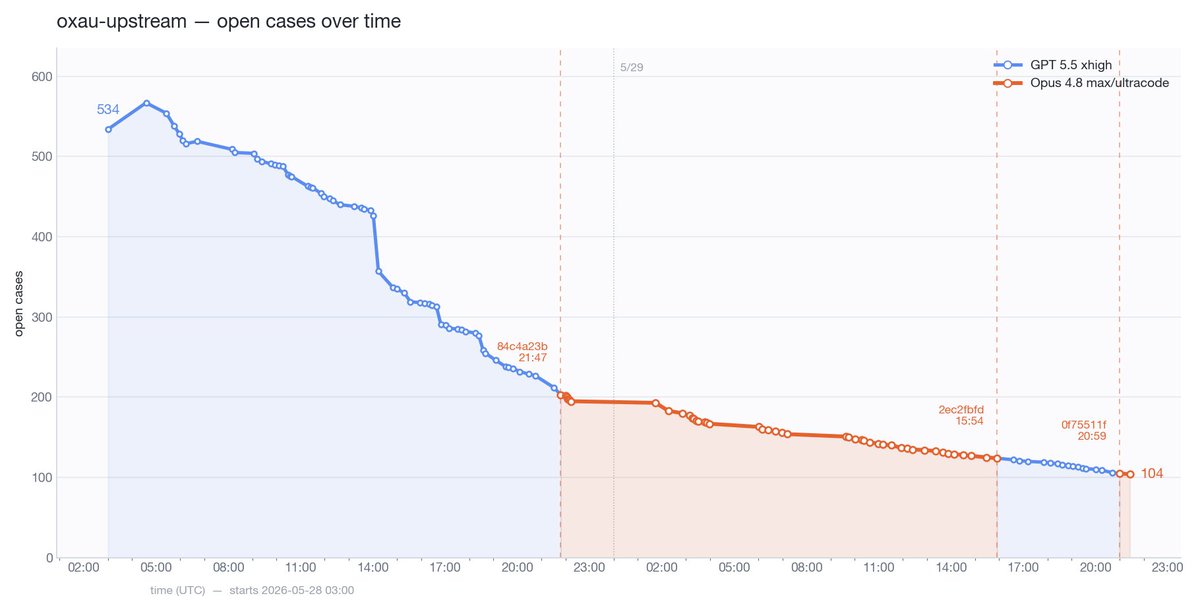
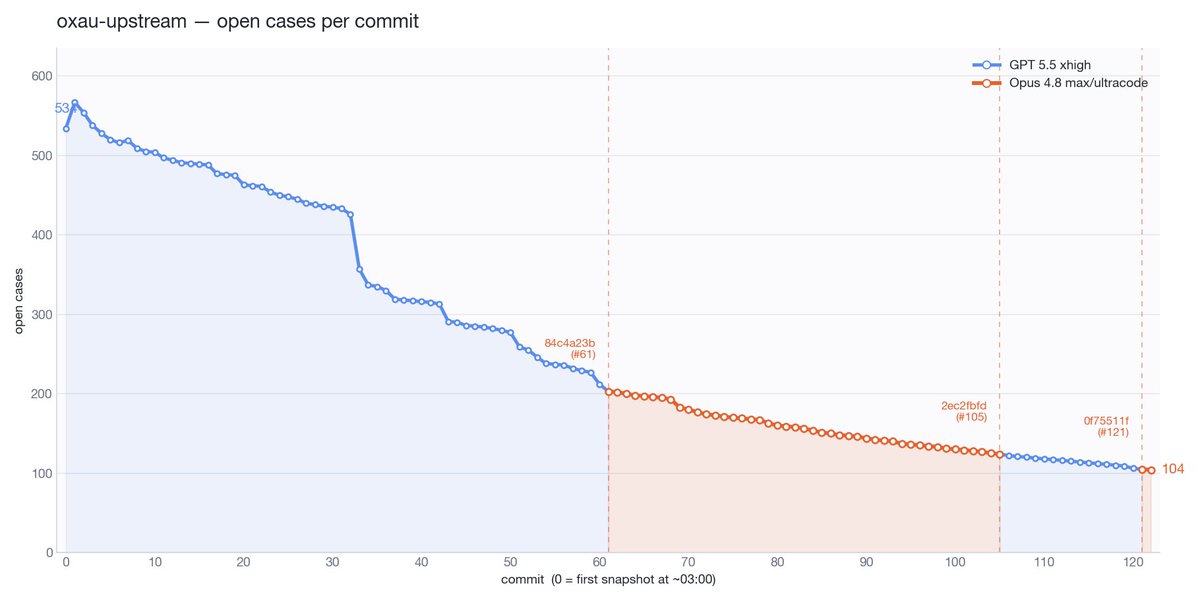
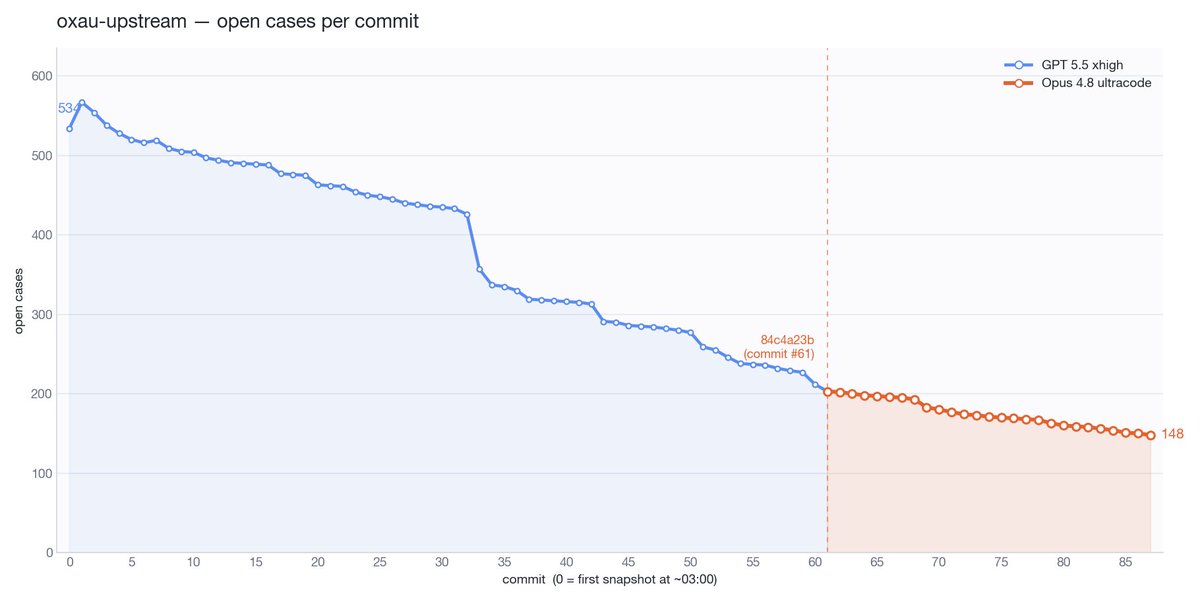
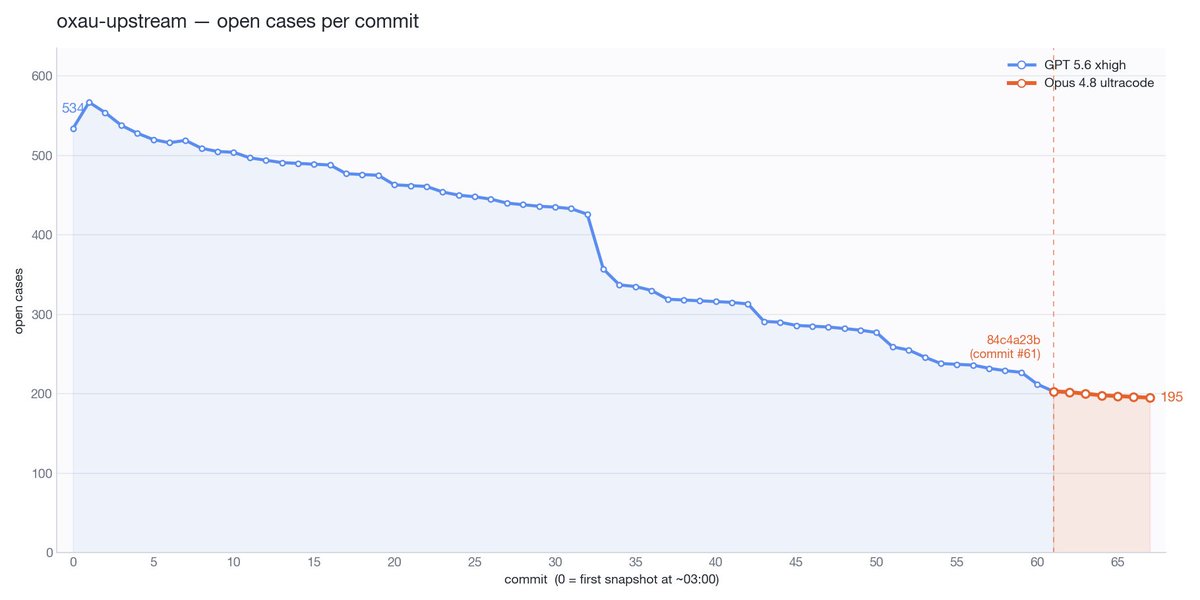
The longer term of my Opus 4.8 comparison actually looks a bit more flattering. Clearing issues roughly inline with GPT 5.5, in a domain where all the big wins have been reaped.
5
17
3,770
May 29
May 29
And here are the same graphs in term of wall-clock time. Interpret with caution because a) GPT got to reap the big wins early on, b) I stopped Claude 4.8 often in its early run for subjective code evals. I'd say this nets out to roughly the same progress slope.
145
May 29
May 29
More data in my ongoing Opus 4.8 vs GPT 5.5 task clearing runoff. Agents are doing a very large C to Rust port. The tasks are extracted unit tests from upstream that need to give the same result in our Rust type checker. Deep in diminishing returns now.
76