
One covenant, many orders. @tplr_ai @basilic_ai @grail_ai
Joined August 2025
- Tweets 153
- Following 5
- Followers 5,085
- Likes 61
35 Photos and videos











Pinned Tweet

May 28
Three production deployments in four months, each one strengthening the next. @FireworksAI_HQ cited PULSE for Cursor's Composer 2 training in March. Now @huggingface and @vllm_project are shipping it.
Open research compounds when adopters do the work of proving it at scale.
May 28

The HF science team just made async RL weight sync ~100x cheaper on bandwidth, and you don't need a shared cluster anymore.
The problem: every RL step, the trainer typically has to sync fresh weights to the inference engine. for a 7B in bf16 that's ~14GB. for a frontier 1T fp8 checkpoint, that's ~1TB; in bf16 it would be ~2TB. per sync.
The insight: between two RL steps, ~99% of bf16 weights are bit-identical. at RL learning rates, the optimizer is whispering and bf16 literally cannot hear most of it. the stored bf16 bits don't change.
What they shipped in TRL: only the changed elements get encoded as a sparse safetensors file, dropped into a Hugging Face Bucket, and fetched by vLLM. on Qwen3-0.6B, per-step payload goes from 1.2 GB to 20 to 35 MB. This is exactly what we built Buckets for: S3-like object storage on the Hub, Xet-backed (so even full snapshots only transfer the changed chunks).
The cherry on top: we ran a FULL disaggregated training where:
- the trainer lived on one box
- vLLM ran inside a Hugging Face Space
- the Wordle environment ran in another Space
- weights flowed through one Hub bucket
no shared cluster. no RDMA. no VPN. no NCCL across clouds. just HTTPS and a bucket.
one GPU a Hugging Face account is now enough to do real disaggregated RL. multi-replica inference fleets across regions become a small devops exercise, not a research project.
Full write-up: huggingface.co/blog/delta-we…
Open source RL keeps eating the moat!

4
7
4,801
19h
One directive, one afternoon, and global access to Anthropic's most capable models was gone. Sovereignty does not end at nations. The tools people think with should not sit behind one party's switch. This is why Covenant builds open, distributed AI infrastructure.
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
4
14
2,017
Jun 12
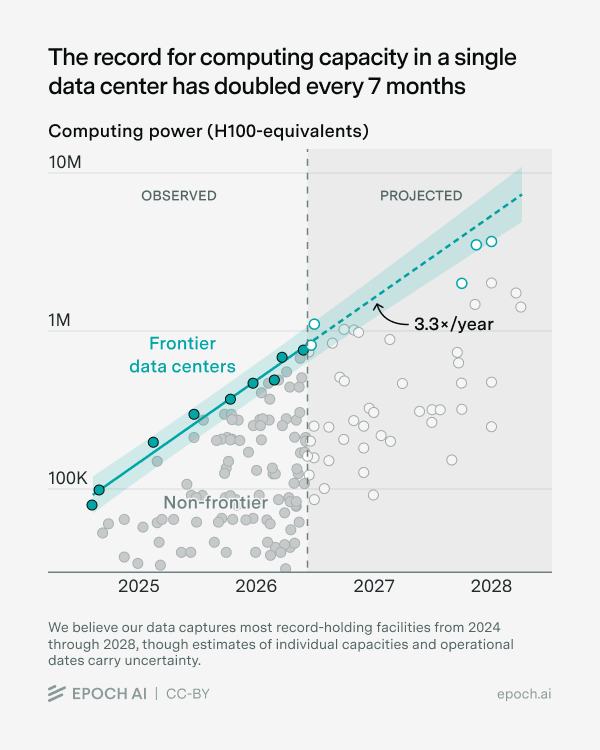
The biggest single data centers will keep getting bigger.
The larger pool is still the long tail: GPUs spread across labs, companies, and individuals, connected over the internet.
The internet is the data center.
Jun 11

The record for computing capacity in a single data center has doubled every 7 months.
Colossus 1, Anthropic-Amazon New Carlisle, and Meta Prometheus have each claimed the top spot in turn.
1
4
1,213
Jun 12
RT @DistStateAndMe: A certification department deciding who deserves intelligence isn't safety. It's a priesthood.
Decentralised intellige…
4
Jun 10
The practical problem in distributed RL is simple: model training moves a lot of data.
When every worker needs fresh model updates, network traffic can limit how many machines you can use and how often you can sync them.
PULSE looks for updates the receiver can actually use.
1/n
1
2
5
1,196
Jun 10
On Qwen2.5-7B, the PULSELoCo payload is 1.77 GB per worker per window.
That is 17x smaller than DiLoCo and 138x smaller than dense DDP over the same window, with bit-identical results.
5/n
1
195
Jun 10
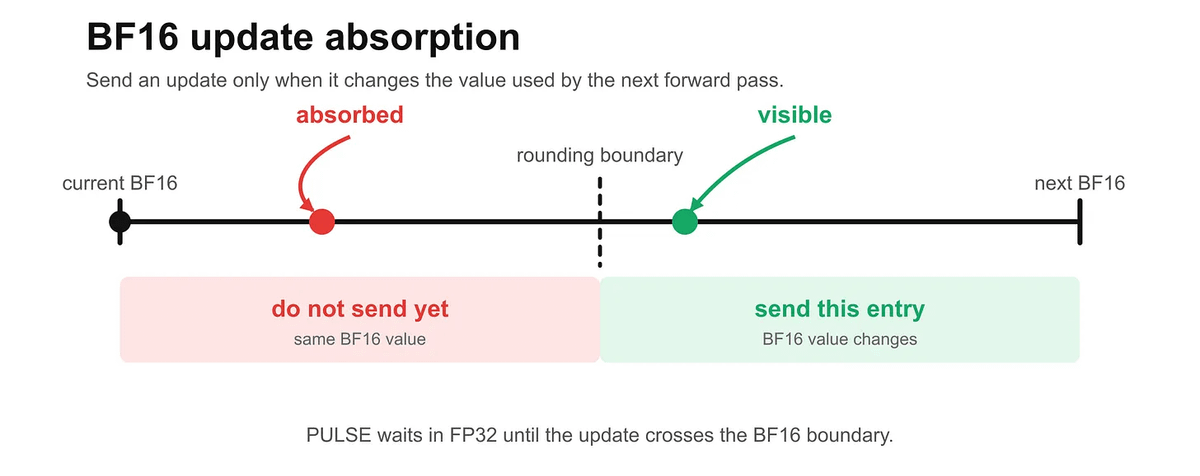
The important distinction is that this is sparse transfer, not lossy compression.
PULSE does not throw away small updates. It delays updates that are currently invisible to BF16 computation, then sends them when they matter.
Paper: arxiv.org/abs/2602.03839
Technical write-up: templarresearch.substack.com…
Covenant AI is hiring: tplr.ai/careers
n/n
173
Jun 9
This is the PULSE idea in one rule.
If the receiver's BF16 computation would see the same value either way, do not send the update yet.
If the receiver's BF16 computation would change, send it.
That is how PULSE can reduce bandwidth without changing the computation the receiver actually performs.
1
4
6
1,405
Jun 9
Paper: arxiv.org/abs/2602.03839
Technical write-up: templarresearch.substack.com…
Covenant AI is hiring: tplr.ai/careers
527
Jun 8
Distributed RL post-training is powerful because many machines can help train the same model, even when they are not sitting next to each other in the same datacenter.
The catch is communication. The farther apart those machines are, the more important it becomes to send less data between them.
PULSESync reduces the data sent from trainers to rollout workers. PULSELoCo reduces the data exchanged between trainers.
1
4
5
2,180
Jun 8
Paper: arxiv.org/abs/2602.03839
Technical write-up: templarresearch.substack.com…
Covenant AI is hiring: tplr.ai/careers
671
Jun 5
The @cursor_ai team post-trained Composer 2 on an open-weight base model using @FireworksAI_HQ's distributed RL rollout infrastructure.
Fireworks links PULSE as the theory behind the BF16 sparsity that makes compact weight updates practical.

8
12
2,264
Jun 4
Published Feb 2026: PULSE showed that distributed RL post-training could move far less data without changing the receiver's BF16 computation.
In May, PULSELoCo extended the same idea to the second synchronization channel.
PULSESync addressed trainer-to-inference. PULSELoCo addresses trainer-to-trainer.
1/n
1
5
10
2,505
Jun 4
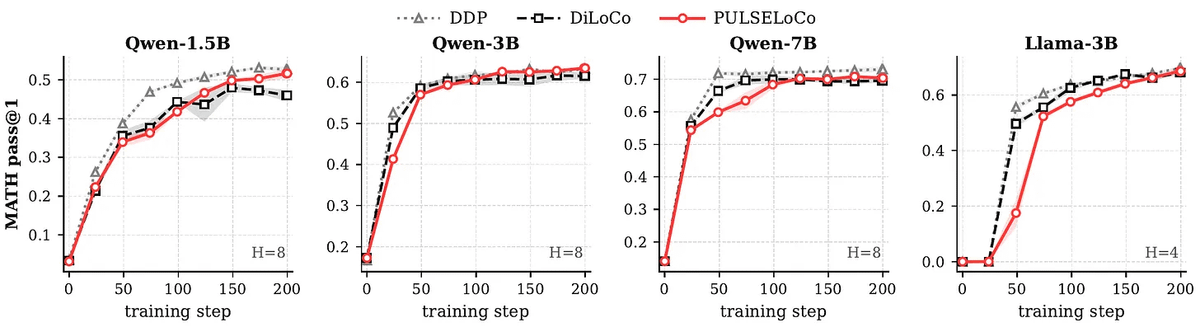
The paper also answers a prerequisite question: does DiLoCo-style local-update training work in LLM RL post-training?
The result holds across Qwen2.5-1.5B, Qwen2.5-3B, Qwen2.5-7B, and Llama-3.2-3B on MATH.
5/n
1
2
2
1,359
Jun 4
PULSESync covers trainer-to-inference. PULSELoCo covers trainer-to-trainer. Distributed RL post-training now has both bandwidth channels addressed.
Paper: arxiv.org/abs/2602.03839
We are hiring: tplr.ai/careers
Join Discord: discord.gg/TjkwPpZvuK
n/n
2
1
1,462