
NFTs, DeFi & everything in between | Trade Spots 📈| Brand strategist📩 | Marketing | Amb @ETHGasOfficial | @TrustSquadmates | @Trustwallet | NFA 🦅
Joined June 2009
- Tweets 117,446
- Following 4,302
- Followers 42,946
- Likes 136,733
5,940 Photos and videos















Pinned Tweet

13 May 2024
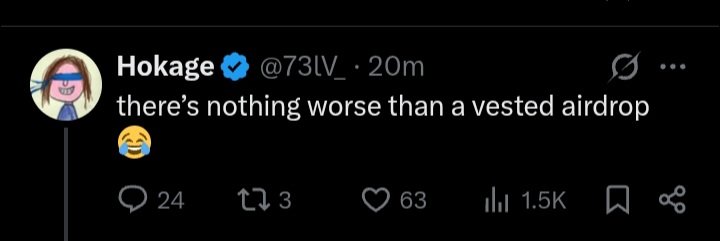
I watched a movie this weekend on @Netflix called DUMB MONEY
The movie was based on a true life story of a youtube stock trader who made some serious cash on $GME @GameStop stock token in 2021
By believing in $GME and betting against stock market Wall Street,he was able to turn he’s life savings of $52k into $35 million and making the short sellers lose over $6 billion in total during the $GME crazy bull spike.
Now normally I’m not the type to come online and talk about a movie I’ve watched but here’s the crazy part.
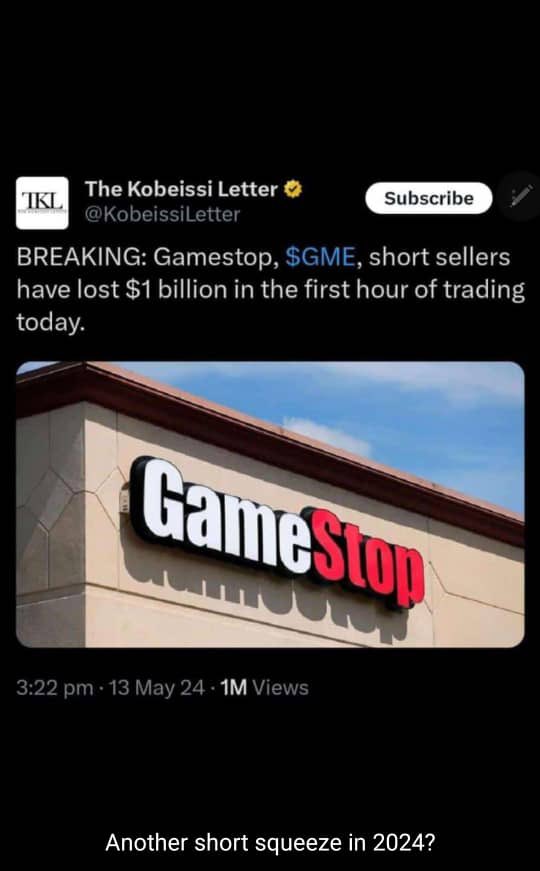
This particular guy went off the radar after the whole $GME saga in 2021,he’s last post was 2021 and now he’s back with a meme tweet on he’s twitter page merely 18hrs ago, $GME short sellers have lost over $1 billion in the first hours of trading today.
I couldn’t believe my eyes,a guy by the name @TheRoaringKitty did the impossible in 2021 against all odds and won. And just 3 years later with one tweet he’s back to making the rich lose.
It’s not just DUMB MONEY if you ask me,it’s DUMB INFLUENCE.
WOW,just wow!!!


233
138
646
176,834
Interesting to see USD1 getting another utility layer on Binance.
Between Simple Earn, Portfolio Margin collateral, and BTCUSD1 perpetual settlement, the focus seems to be on making USD1 usable across multiple products rather than just listing it.
Utility tends to matter more than announcements.
Jun 9

USD1 just got more interesting.
$USD1 Flexible Products limited-time campaign on @binance.
Live now, details below.
🦅☝️
30
33
127
551
$2 trillion left the crypto market since last year’s peak.
Bitcoin is down over 50% from its all-time high near $126K.
And most people still don’t understand why this is happening.
This is not random fear. This correction has a clear anatomy.
🔹️ 1. The ETF buyers left the building
The 2024–2025 rally was partly built on ETF demand.
Institutions were buying. Flows were green. Price followed.
May 2026 just printed the biggest monthly ETF outflow of the year, with about $2.3B gone in one month.
When the structural buyer disappears, price has to find new demand.
Right now, it hasn’t found it.
🔹️ 2. Leverage got destroyed
Too many traders were aggressively long heading into this drop.
When Bitcoin started falling, liquidations kicked in.
▪︎ Liquidations pushed price lower
▪︎ Lower prices triggered more liquidations
That’s not just a bear market.
That’s a leverage flush.
It is violent, fast, and always feels worse than it is.
🔹️ 3. Money went to AI instead
Here’s the part nobody wants to say out loud.
Bitcoin is losing the attention war right now.
AI stocks are pulling serious capital from retail and institutional investors.
Crypto is not dead.
It is just not the loudest story in the room right now.
🔹️ 4. The macro door is still closed
The Fed is not making things easy.
Higher-for-longer rates mean investors can park money in cash, bonds, and safer yield opportunities.
Non-yielding assets like Bitcoin feel that pressure immediately.
Add dollar strength, inflation concerns, and risk-off sentiment, and the market simply becomes less friendly to crypto.
🔹️ 5. Fear is doing the rest
Once price breaks key levels, sentiment turns fast.
▪︎ Late buyers panic-sell
▪︎ Alts bleed harder
▪︎ Liquidity runs into stablecoins
That is not just analysis.
That is human nature.
It happens every cycle.
🔹️ Here’s what I actually think
This is not the end of crypto.
But it is a reset.
The market is burning off leverage, hype, and overcrowded trades.
What survives this phase will be the projects with real users, real revenue, and real liquidity.
Hype alone will not be enough anymore.
Bitcoin’s long-term thesis has not changed.
The short-term pain is real though, and it may not be over yet.
One question I’m sitting with right now:
What is still worth holding when the leverage is completely gone?
Drop your honest answer below. Genuinely curious what you’re watching.
#CryptoMarket #Bitcoin #CryptoCorrection #DeFi #RWA #BitcoinDeFi
12
18
57
29,560
Interesting to see WLFI and Byreal taking the “build first” route on Solana.
Starting with USD1 liquidity incentives a trading competition instead of just announcing a partnership.
Also worth noting: Byreal is backed by Bybit’s liquidity infrastructure, so this is more than a standard DEX integration.
May 14

@byreal_io x @worldlibertyfi 🦅
Byreal and WLFI are working together to explore development in the @solana.
$WLFI incentives will be provided to support the growth of the USD1 ecosystem.
More details below ↓

38
4
79
35,053
🚨 BREAKING THE SMOKE SCREEN: Did Trump and Xi just fix the global economy, or did they just kick the live grenade down the road?
The Beijing summit just wrapped up with flawless optics and a 200-plane Boeing order. But look closer.
The real structural war, tech dominance, supply chains, and tariffs didn’t move an inch.
Here is the raw reality check the elites don’t want you to notice. 📉
☆ The Illusion of Victory
The optics coming out of Beijing were spectacular. We saw the full red-carpet diplomatic treatment: grand state banquets, military honors, personal toasts, and a curated menu ranging from Kung Pao chicken to chocolate brownies.
Xi Jinping called the summit a milestone that established a constructive, strategic, and stable relationship. Trump proudly mirrored the vibe, calling the meetings a great success and historic.
To keep the global markets happy, they put up a massive front of goodwill.
🔹️ Trump floated a headline-grabbing commercial win, announcing that China agreed to purchase 200 Boeing jets, with a floating teaser of up to 750 over time.
🔹️ This was backed by standard commitments for American agriculture and LNG energy.
🔹️ Xi even offered a diplomatic nod on geopolitical pressure points, emphasizing stability around the Strait of Hormuz.
On paper, it looks like a massive win. In reality, it is a smoke screen.
☆ The Total Business Disconnect
Trump brought a high-powered delegation of top U.S. CEOs explicitly to lock in reciprocal, deep-tier business partnerships.
The result? Almost total silence on the things that actually matter.
When you strip away the grand theater and look at the actual ledger, no real business connections were built.
The hard, structural issues that are actively tearing the global economy apart were completely sidelined just to preserve the goodwill narrative.
🔹️ There was zero progress made on tech export controls, semiconductor restrictions, or dual-use technology issues.
🔹️ The core trade imbalances and punishing tariff structures remain completely untouched.
🔹️ Meaningful progress on Chinese EVs, critical minerals access, and manufacturing independence was entirely frozen.
Just days before the summit, the U.S. had imposed fresh sanctions on Chinese entities, and China continued its pushback on U.S. measures related to Iran.
The underlying friction didn’t move an inch.
☆ Theater Over Substance
Why the massive disconnect?
Because this summit wasn’t designed to fix a broken trade infrastructure. It functioned purely as a geopolitical pressure valve to manage tensions and prevent an outright crisis.
A 200-plane order is a great headline to temporarily soothe Wall Street, but it does absolutely nothing to change the underlying reality.
The U.S. and China remain locked in a brutal, long-term strategic competition for global dominance.
Warm handshakes are easy. Real business integration is proving to be impossible.
History suggests these high-profile meetings often produce short-term stability while the deeper issues of tech dominance, supply chain security, and territorial flashpoints continue simmering quietly beneath the surface.
☆ The Big Question
This leaves the entire global community looking at one massive question:
Is this the genuine start of a constructive, peaceful relationship between the world’s two superpowers, or is it just a beautifully choreographed truce to buy both leaders time?
History suggests these high-profile meetings frequently produce short-term stability while the deeper issues of tech dominance, supply chain security, and territorial flashpoints continue simmering quietly beneath the surface.
Are we witnessing a real de-escalation and a new chapter, or is this just diplomatic theater to buy time before the next economic explosion?
Drop your honest take below. Let’s discuss.
DYOR. Post-summit analysis via global breaking feeds.
#TrumpXiSummit #USChinaRelations #Geopolitics2026cc

44
6
82
29,342
Deadline☠️🐧 | ETHGas ⛽ retweeted

May 14
Today showed once again that there are still tremendous opportunities on CT.
I'm still very comfy doing crypto content.
You should be too
325
20
781
46,884
A useful feature for new @Bybit_Official users that’s probably flying under the radar.
You can now enable Flexible Savings directly with your DCA Bot on Bybit.
That means your idle funds can still earn yield while your scheduled DCA buys continue running in the background.
There’s also the DCA Yield Fiesta campaign where eligible users can unlock APR boost rewards through DCA trading activity.
How to get started:
• Use a Bybit account (new users only)
• Create a DCA Bot
• Enable DCA Flexible Savings
• Join the campaign and start trading to qualify for boosted rewards
Campaign details: announcements.bybit.com/arti…
Flexible Savings update: announcements.bybit.com/arti…

39
13
65
50,354
🚨 Prediction markets are turning society into a casino.
People are now gambling on wars, elections, economic collapse, and human suffering while insiders allegedly profit from information the public doesn’t have.
This was sold as “predicting reality.”
But it’s starting to look more like legalized gambling disguised as intelligence.
And it’s becoming dangerous.
🔹️ The $20 Billion Dopamine Machine
Prediction markets like Polymarket and Kalshi exploded in 2026, processing tens of billions in volume.
But beneath the hype, the system is heavily skewed.
Data shows a tiny group of whales and sharp traders dominate profits while most retail users lose money chasing volatility and fast payouts.
This is not collective intelligence.
It is speculation wrapped in the language of information.
🔹️ Betting on Military Operations
One of the most disturbing examples came in 2026 when U.S. Army Master Sgt. Gannon Ken Van Dyke was accused of using classified information connected to the Maduro operation to place prediction market bets.
According to reports, he allegedly turned a $33,000 position into over $400,000 in profits.
Think about how insane that sounds.
A world where people tied to real military operations can allegedly profit from sensitive outcomes through betting markets.
At that point, prediction markets stop being “forecasting tools.”
They become corruption incentives.
🔹️ Manipulating Reality for Profit
French authorities also reportedly launched investigations after unusual activity tied to airport weather sensors.
Allegations surfaced that traders attempted to artificially influence readings using heat sources like hairdryers or lighters in order to profit from weather prediction contracts.
That should alarm everyone.
Because once money becomes tied to outcomes, people no longer just predict reality.
They start trying to manipulate it.
🔹️ The Iran Strike Suspicion
During the February 2026 Iran strike situation, newly created wallets reportedly made highly coordinated bets shortly before major announcements and walked away with massive profits.
The timing triggered widespread concerns about insider knowledge and privileged access.
Soon after, reports emerged that White House staff received warnings about using non public information for prediction market activity.
That alone tells you how serious this has become.
🔹️ Political Power and Insider Advantage
Concerns have also intensified around Trump related market activity and potential insider trading investigations.
When political influence, financial incentives, and prediction markets begin overlapping, the line between observing events and shaping them starts disappearing.
The people closest to power will always have the advantage.
Retail users become exit liquidity.
🔹️ Society Is Becoming Financial Entertainment
Prediction markets are slowly conditioning society to emotionally detach from real events.
People are no longer just reacting to wars or crises.
They are asking: “How much can I make from it?”
That shift is dangerous.
Because once human suffering becomes a financial opportunity, morality starts collapsing behind profit incentives.
🔹️ The Gambling Problem Nobody Wants to Admit
These platforms now operate with the same psychological mechanics as sportsbooks and casinos:
《Live odds
《Constant notifications
《Fear of missing out
《Emotional trading
《Dopamine loops
The only difference is that now the betting categories are geopolitics, disasters, elections, and global instability.
☆ Final Thought
Prediction markets were marketed as tools for truth and intelligence.
But what they are becoming is something much darker:
A system where chaos creates profit.
A society where everything becomes a trade.
Some things should never have a price attached to them.
And some parts of reality should never become a betting market.
40
5
76
28,170
I read the WLFI complaint so you don’t have to¡
• The “freeze clause” being disputed was explicitly signed by Justin Sun, giving WLFI the right to restrict or freeze wallets
• About $300M USDT was moved to Binance less than 24 hours before launch. WLFI says this came before a 26% drop on day one and a spike in short interest
• The wallet freeze came after three alleged breaches, including restricted transfers and shorting against the agreement
These are claims filed in court, and they still need to be proven.
Full Complaint filing below 👇🏾
url.us.m.mimecastprotect.com…
33
6
62
8,751
Most people will notice this after it’s gone.
Access is already gated. The rest will figure it out later🥱
May 4

24 hours until the presale.
Ticker: $MUFFIN
Platform: @districtxyz
Initial MCap: $258K
Public Raise: $150K
TGE Unlock: 100%
Muffin Pass required.

35
4
55
15,696
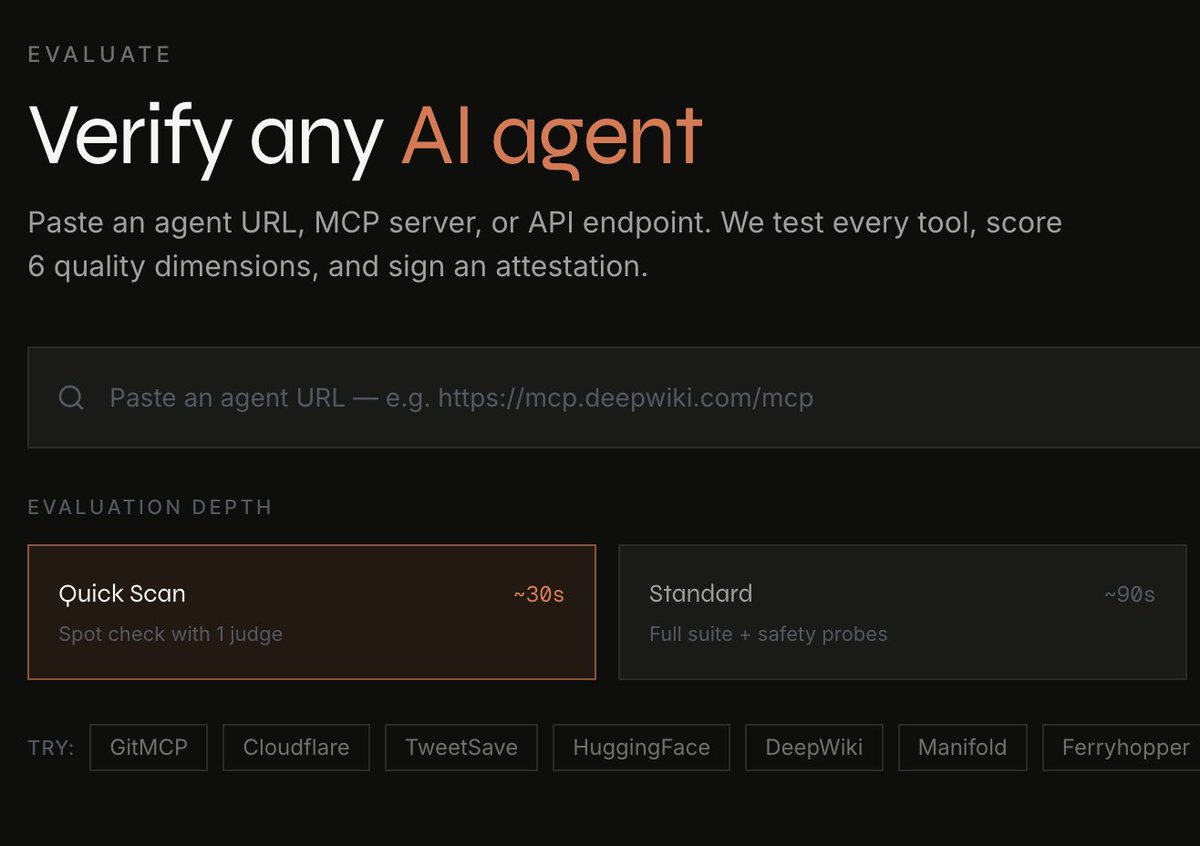
Evaluation is still the missing layer in most agent stacks
$ASRR introduces Laureum AI a 6-axis scoring framework for MCP servers and agents, combining multi-LLM consensus with adversarial testing
Open access public benchmarks. Clear step toward standardized agent quality measurement
For more info…check ⬇️
Apr 21

Introducing @Laureum_ai — quality scoring for MCP servers and AI agents by @assisterr
We score 6 dimensions: accuracy, safety, reliability, process quality, latency, and schema quality.
Multi-judge LLM consensus adversarial probes.
We've scored 28 public MCP servers to date.
Average: 68.3/100. 6 in Expert tier (≥85).
The weakness nobody else measures: process quality — averaging 55.5/100.
Here's why we built it👇
Three gaps in agent eval today:
→ Marketplaces curate by hand. A major MCP catalog operator pruned 17 abandoned /vanity / impersonation entries from their own catalog earlier this month — manually.
→ Eval frameworks (LangSmith, Braintrust, Galileo) score tool-call correctness well. Process quality — error handling, input validation, response structure — sits between them, and nobody surfaces it as a named composite.
→ Post-Drift, the Solana ecosystem just launched STRIDE for smart-contract security. Agent infra still ships without pre-deploy quality gates.
Laureum is the missing layer.
Free right now, no signup:
1/ Quick Scan — paste any MCP server URL, get a 30-second 6-axis score → laureum.ai/evaluate
2/ Public leaderboard — see how the most-used servers rank → laureum.ai/leaderboardIf you're building, run yours. Reply with your score — we'll feature the top 5 this week.
End of the tweet.
20
1
27
15,929
Deadline☠️🐧 | ETHGas ⛽ retweeted

Apr 21
Introducing @Laureum_ai — quality scoring for MCP servers and AI agents by @assisterr
We score 6 dimensions: accuracy, safety, reliability, process quality, latency, and schema quality.
Multi-judge LLM consensus adversarial probes.
We've scored 28 public MCP servers to date.
Average: 68.3/100. 6 in Expert tier (≥85).
The weakness nobody else measures: process quality — averaging 55.5/100.
Here's why we built it👇
Three gaps in agent eval today:
→ Marketplaces curate by hand. A major MCP catalog operator pruned 17 abandoned /vanity / impersonation entries from their own catalog earlier this month — manually.
→ Eval frameworks (LangSmith, Braintrust, Galileo) score tool-call correctness well. Process quality — error handling, input validation, response structure — sits between them, and nobody surfaces it as a named composite.
→ Post-Drift, the Solana ecosystem just launched STRIDE for smart-contract security. Agent infra still ships without pre-deploy quality gates.
Laureum is the missing layer.
Free right now, no signup:
1/ Quick Scan — paste any MCP server URL, get a 30-second 6-axis score → laureum.ai/evaluate
2/ Public leaderboard — see how the most-used servers rank → laureum.ai/leaderboardIf you're building, run yours. Reply with your score — we'll feature the top 5 this week.
End of the tweet.
26
29
92
51,064
Getting exposure to gold silver and oil usually comes with friction conversions higher fees limited access.
Bybit simplifies that:
XAU XAG and CL perps traded directly in USDT
no conversion hassle
0 maker 50% off taker
deeper liquidity for smoother execution
For new users entry is simple
Hit 100 USDT trading volume
unlock a lucky draw ticket
compete for a share of the 50000 USDT prize pool
Join here: bybit.com/en/trading-contest…
Simple access
Lower costs
Real market exposure

49
1
47
48,966
Tomorrow is the final day. 🌊
We are officially in the home stretch for the @River4fun campaign and the Hyperliquid incentives.
If you haven't secured your spot on the leaderboard yet, these next 24 hours are basically your last chance to make a move. @RiverdotInc
$RIVER is holding around the $6.77 mark.
With the season ending tomorrow, the energy is definitely picking up as everyone tries to stack those final points. 📈
The Trading Comp
The prize pool is still live. Trade $RIVER on Hyperliquid Spot to claim your share of $1,500 $RIVER and 150k River Pts
Content Creation
With 200 creators already in, the competition for the Top 100 split of 100k River Pts is getting tight. Drop your analysis or your honest take while you still can. ✍️
This is the final push.
Every trade and every post counts today if you want to climb that ranking before it all wraps up. 🔥

Apr 17

2 days left on Hyperliquid campaigns
✦ Trading Comp (full prize pool still live)
▸ Trade RIVER on Hyperliquid Spot
▸ $1,500 RIVER 150k River Pts
✦ Content Creation (200 creators in)
▸ Share your analysis, trade, honest take
▸ Top 100 split 100k River Pts
Odds are still in your favor

51
3
56
8,371
The energy in Japan is unmatched, and seeing @RiverdotInc @River4fun connecting with partners here feels like the perfect timing. 🌊
With Japan moving forward on stablecoin and payment regulations, River’s "Connect" mission actually makes sense in the real world.
Whether it’s the $satUSD integration or the scaling we’re seeing on @HyperliquidX and @Base, River is proving that utility is what actually drives growth. 📈
The vision is clearly going global.
Season 4 momentum is just getting started.🔥
Apr 16
こんにちは Tokyo 🇯🇵
River was at TEAMZ Web3 & AI Summit. Connected with partners and tracked the latest moves in Japan
As the government moves forward on stablecoin and payment regulation, River's "Connect" mission fits right in
57
55
24,236
Hitting the Top 1 spot on the @River4fun leaderboard feels proper for @RiverdotInc
It’s one thing to see the numbers grow, but seeing the Deposit & Hold rewards officially hit wallets makes it even better.
They’ve just distributed 150k River Pts and $1,500 in $RIVER to 211 qualifying addresses on @HyperliquidX.
Some of the top holders walked away with over 20,000 River Pts, which is a massive boost for the home stretch of the season. 📈
If you were part of this, you can check your address on the results sheet here:
docs.google.com/spreadsheets…
The Trading Competition and Creator Campaign are still very much live, so there’s still time to move up the ranks before everything wraps up. ⏳🔥
$RIVER #RiverPts #River4FUN #Hyperliquid #TopCreators #Airdrop

Apr 15

🏆 River4FUN TOP10 Creators
🥇 @cryptodeadline — 3.33%
🥈 @Fujina73 — 3.09%
🥉 @Crypto__Haris — 2.87%
4️⃣ @Sajib_999 — 2.73%
5️⃣ @FabiusDefi — 2.54%
6️⃣ @btcpiggy — 2.46%
7️⃣ @maik2hello — 2.21%
8️⃣ @MartinHo99999 — 2.06%
9️⃣ @CoinToEarn — 2.06%
🔟 @BossMon_02 — 2.03%

39
6
48
8,009
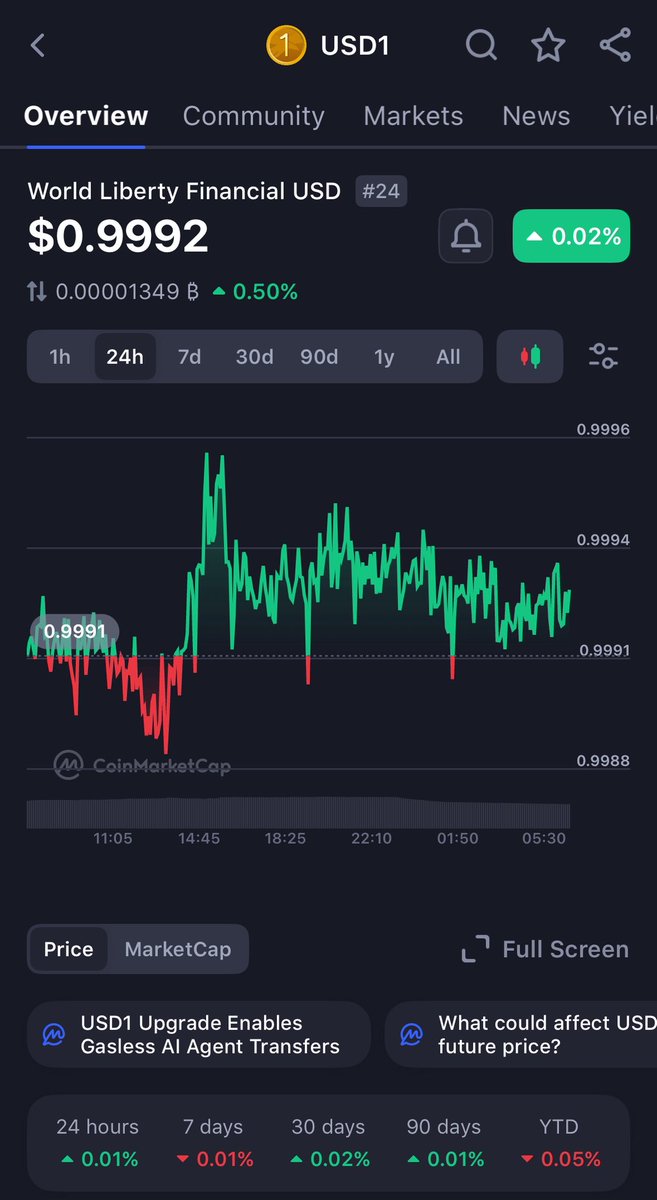
Everyone’s watching the WLFI drama right now….But USD1 hasn’t stopped moving.
$25M minted recently….fully collateral-backed
Peg still sitting tight around $0.9992, even through the volatility
No hype around it
Just consistency
And the usage side keeps expanding:
USD1 is already plugged into real systems
Trading…custody…payroll and settlement rails
Aster → $2.6B perps volume in week one
BitGo → custody support
MEXC → exchange integration
Morpho → yield vaults (~13% APY)
Zebec → 65K workers getting paid in USD1
MoonPay → zero-fee onramp
AgentPay → cross-chain payment rails
Feels like scattered updates at first glance…but the pattern is clear
USD1 is shifting from “a token in circulation”to actual settlement infrastructure across multiple use cases
That’s the part worth paying attention to.
32
2
30
8,401
Most people are still looking at Ethereum through a retail lens gas fees, memepool wars,failed transactions
But the real shift is happening at the market structure level
And this is one of the first serious signals
ether.fi just committed $3B (40% of its ETH) to ETHGas’s High Performance Staking 3-year deal, exclusive on pre confirmations
Right now, blockspace is a spot auction: no forward pricing, no guaranteed execution, no hedging. That doesn’t work for institutions.
@ETHGasOfficial and @lepsoe is building a forward market for blockspace validators pre-sell inclusion, users lock in execution upfront
Think futures, but for transactions.
With 2.8M ETH, ether.fi brings the validator depth needed to make this credible, while $25B in institutional ETH has been waiting for tools like this
3ms execution…..Preconfirmed transactions…Predictable costs
Ethereum shifting from best-effort → guaranteed execution.
Apr 15

ETHGas 🤝 @ether_fi
We’re announcing a $3Bn deal to advance the development of institutional blockspace markets on Ethereum.

30
1
31
20,249
Two $RIVER campaigns are live on @HyperliquidX until April 19.
If you’re pushing for those final Season 4 points, now is the time to move. 🌊 @RiverdotInc @River4fun
The Trading Comp 📈
Trade $RIVER on Spot to grab a share of $1,500 $RIVER and 150k River Pts.
Content Creation ✍️
Share your analysis or trade setups. The Top 100 creators split 100k River Pts.
These extra points are massive for anyone looking to climb the leaderboard before the season wraps up. ⏳
Get started: app.river.inc/fun?ref=crypto…

Apr 11
Two River campaigns running on Hyperliquid through April 19
✦ Trading Comp
▸ Trade RIVER on Hyperliquid Spot
▸ Earn $1,500 RIVER 150k River Pts
x.com/RiverdotInc/status/204…
✦ Content Creation
▸ Analysis, trade setup, your honest take
▸ Top 100 split 100k River Pts
x.com/RiverdotInc/status/204…

52
3
55
19,685
Paris is about to feel the @RiverdotInc @River4fun energy during Blockchain Week. 🗼
It’s one thing to see the growth on-chain, but seeing the team supporting @HyperliquidFR at the Liquid Circle Apéro is a whole different level..
Builders and traders connecting IRL is where the real alpha usually happens.
If you’re in Paris on April 16, this is where you’ll want to be vibing with the crews from @Dreamcash, @hlnames, and @eliospay.
$RIVER Season 4 is clearly going global. ⏳🔥
RSVP:luma.com/238n1o8c

Apr 13
Paris Blockchain Week is coming
Supporting @HyperliquidFR at Liquid Circle Apéro, together with @Dreamcash, @hlnames, and @eliospay. Connect with builders and traders in the Hyperliquid ecosystem
▸ April 16, Paris
49
6
59
7,418
The clock is ticking on the $RIVER deposit campaign and this is one of the easiest ways to stack before the deadline of @RiverdotInc @River4fun campaign
There’s no minimum deposit required, and it literally takes 30 seconds to move your $RIVER to @HyperliquidX.
By simply holding on Spot, you’re locking in a share of the 150k River Pts pool.
Plus, 250 lucky wallets will be drawn to win $RIVER tokens directly. 📈
The deadline is tomorrow, April 10. If you’re looking to maximize your standing before Season 4 wraps up, this is a no-brainer move to boost your rank. ⏳🔥
Deposit here: app.river.inc/bridge

Apr 9
Every holder shares the 150k River Pts, and 250 wallets win $RIVER tokens. No minimum, ends April 10
Deposit $RIVER on @HyperliquidX in 30s and you're in

58
1
48
24,154