
⚡️ Interest: Human-Computer Interaction, Healthcare Informatics, Symbolic AI
Joined April 2016
- Tweets 2,409
- Following 200
- Followers 298
- Likes 249
779 Photos and videos








「人はなぜ、単なる図形の動きからでも、社会的な意味を読み取れるのか?」 単なる視覚パターン認識ではなく直感的物理と直感的心理(他者のゴール・関係)の統合的推論として説明できるかを計算モデルで検証。
Grounding Social Perception in Intuitive Physics arxiv.org/abs/2603.27410


7
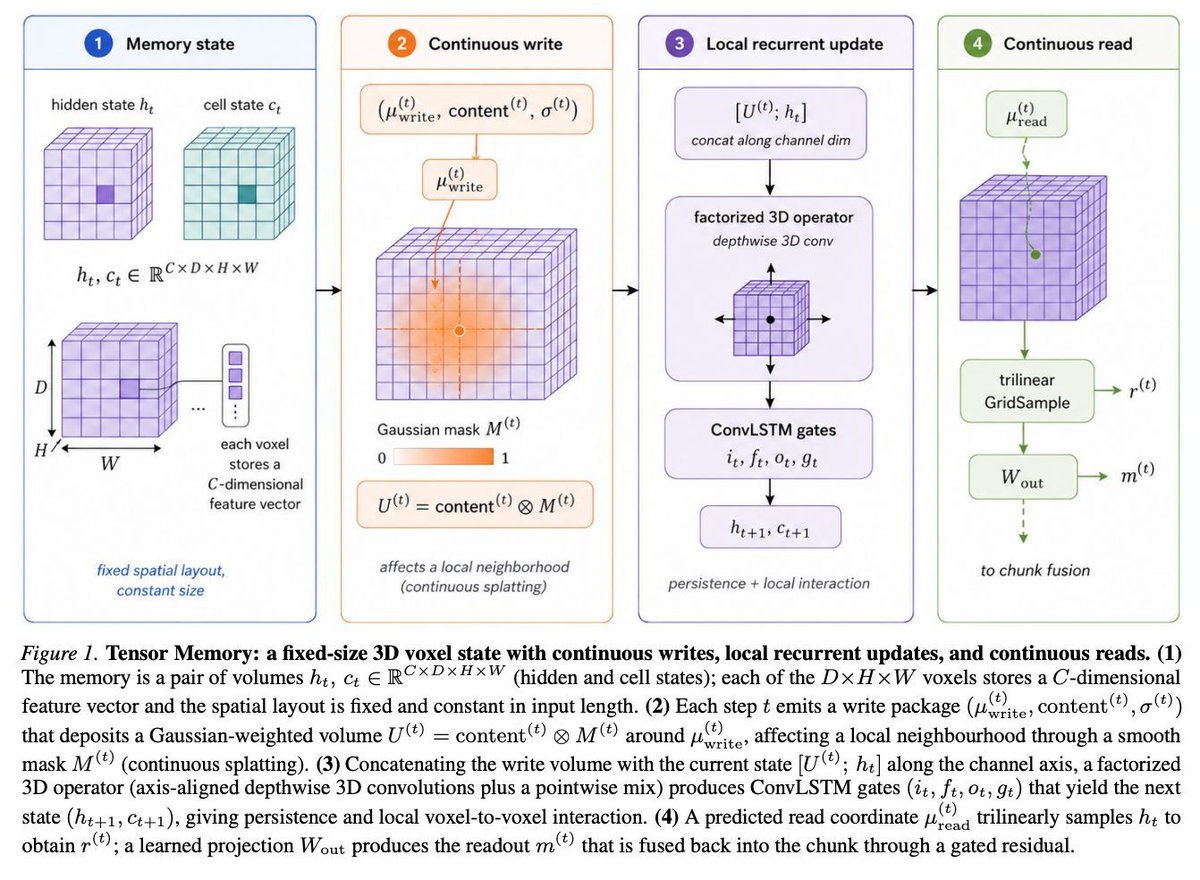
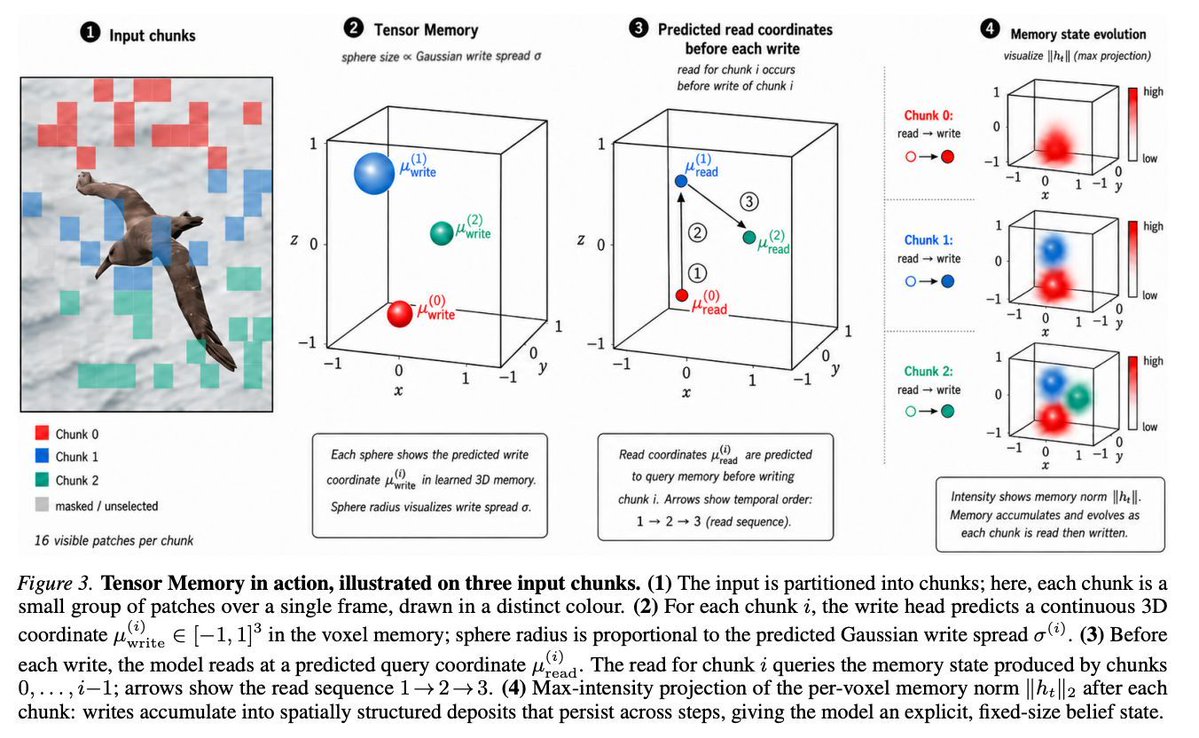
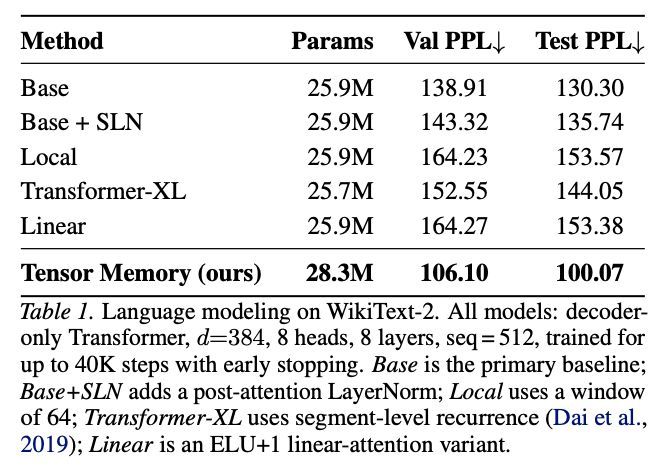
Transformer に固定サイズの再帰的な3Dメモリテンソルを組み込み、長い時系列(特に動画や長文)に対して、KVキャッシュに依存せず、明示的で構造化された状態を維持させる「Tensor Memory」
Tensor Memory: Fixed-Size Recurrent State for Long-Horizon Transformers arxiv.org/abs/2605.27686
16

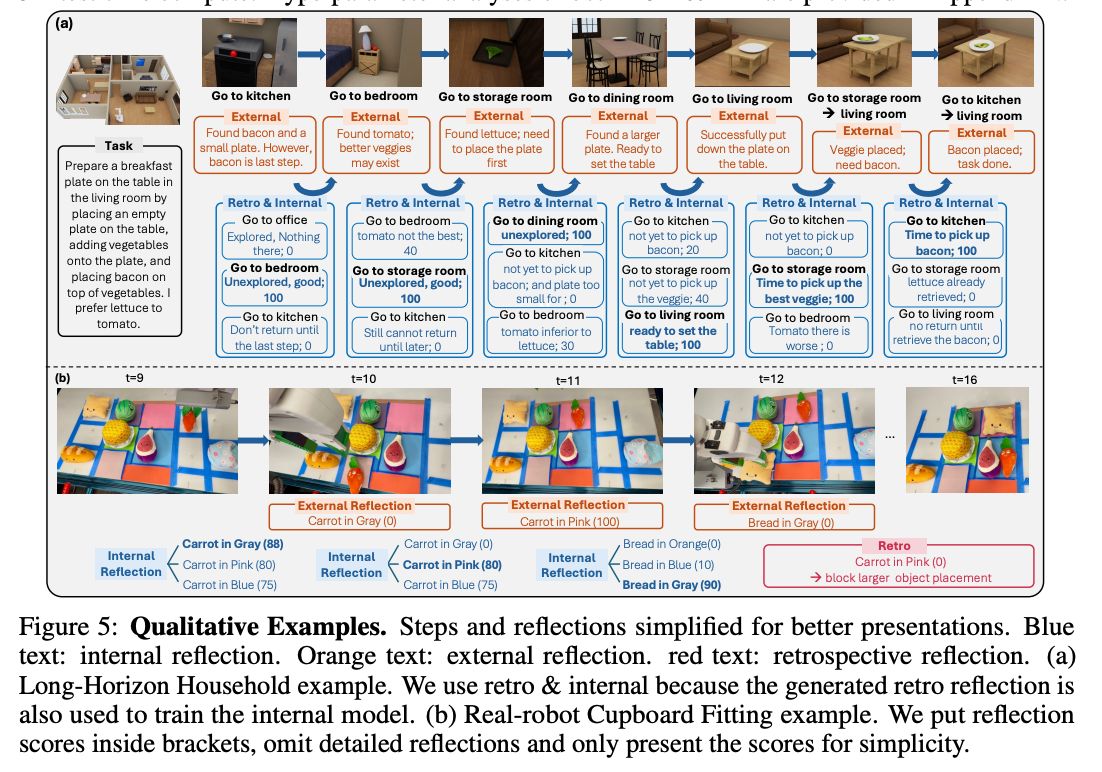
Learning from Trials and Errors: Reflective Test-Time Planning for Embodied LLMs
reflective-test-time-plannin…
14
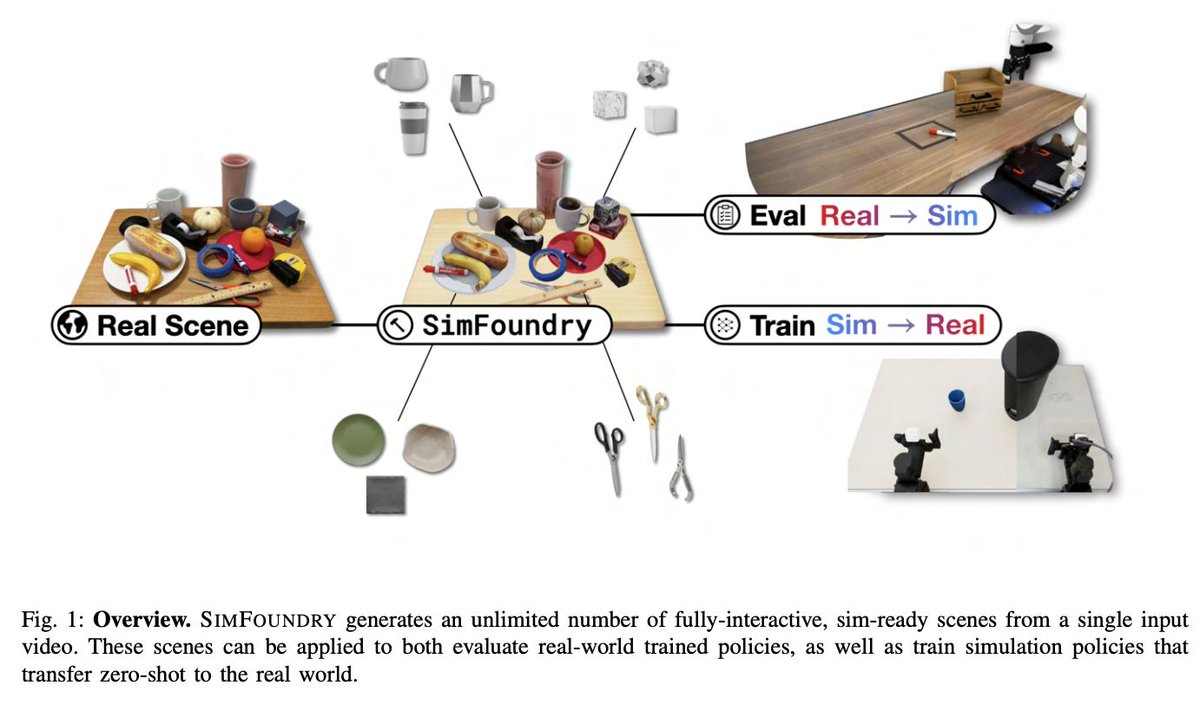
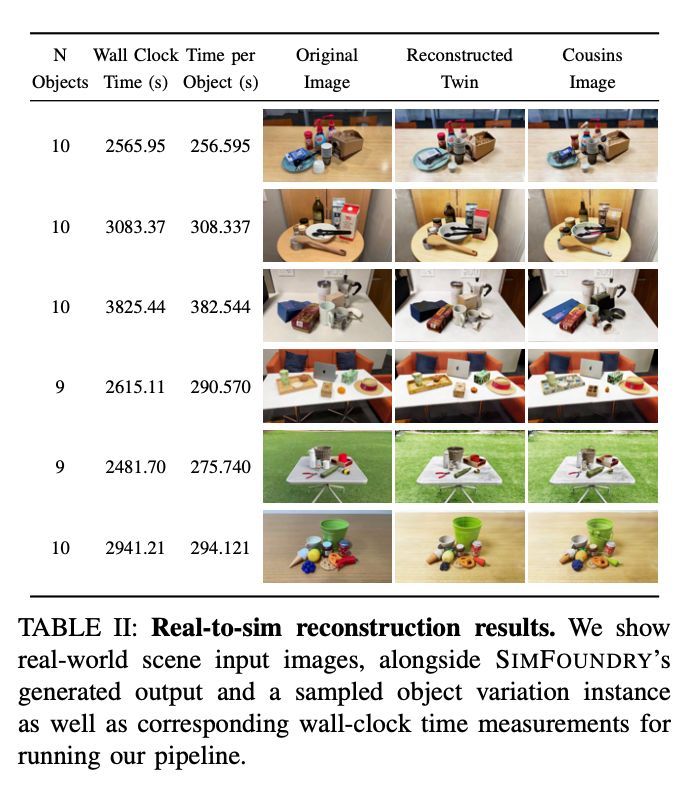
単一画像や動画からロボット用の操作可能なシミュレーション環境を自動生成するreal-to-simパイプライン「SIMFOUNDRY」。real-to-sim評価と sim-to-real 学習を一つの枠組みで実現。
SIMFOUNDRY: Modular and Automated Scene Generation for Policy Learning and Evaluation openreview.net/pdf?id=s0YXBj…


1
31
atom retweeted

Jun 3
Introducing Ideogram 4.0: the best open image model in the world.
Think it. Make it. Own it.
Download the weights, fine-tune on your own data, and run it on your hardware. Live on every Ideogram plan and the API today.
412
868
8,198
2,159,523
atom retweeted

Jun 3
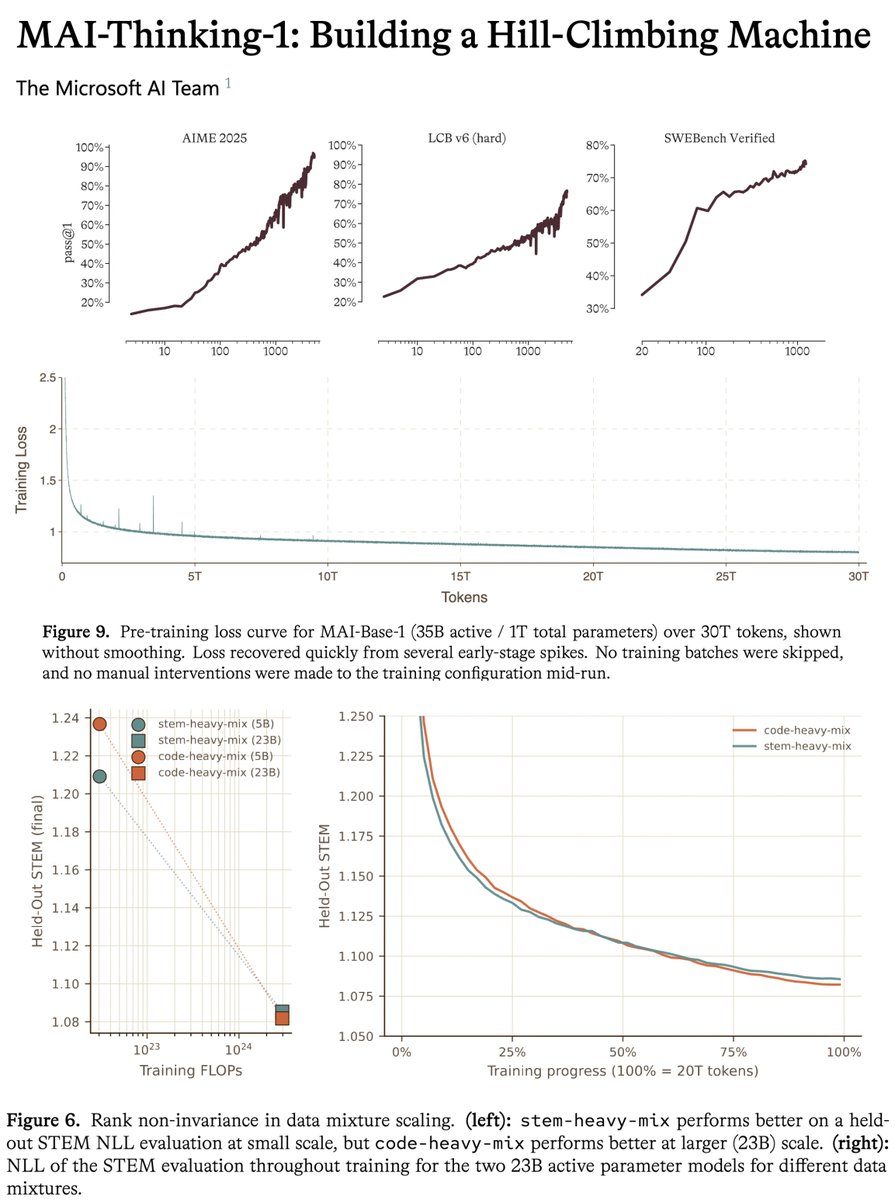
microsoft MAI tech report is a gold mine, one of the most transparent for a model at this scale.
this model uses zero synthetic data or distillation from previous models. this means reasoning, agentic behavior, tool use are all learned fully during post-training with no cold start. bold choice that makes it harder and requires more iterations to reach sota, but you get FULL control over your model series and it proves they are serious about being a frontier lab.
the tech report is insanely detailed and precise about numbers. to give an example, they give the exact MFU across all the iterations of the model, with the exact changes etc. they also share the full scaling ladder recipe, to my knowledge this is the first time i've seen this in a tech report at this scale
let's look at all of this in this likely very long thread 🧵

Super excited to announce seven new world-class MAI models today. They represent what we consider a new era in AI designed to keep you in control and on the frontier.
First is our text foundation model, MAI-Thinking-1, exceptionally strong on reasoning and SWE tasks.
- It’s a 35B active parameter MoE with a 256K context window. Independent human raters on Surge prefer it for overall quality in blind side-by-sides versus Sonnet 4.6, and it’s achieved 97% on AIME 2025, the key measure of its general-purpose reasoning abilities.
- It's at 53% on SWE Bench Pro, placing it right alongside Opus 4.6 on one of the toughest coding benchmarks.
- And since we co-designed our models with our own silicon, MAI-Thinking-1 is optimized on our MAIA 200 chip. Benchmarking head-to-head against the GB200, we see 30% better performance per dollar as well as a 1.4x performance-per-watt gain when running our MAI models on the MAIA 200 end-to-end.
Next is MAI-Image-2.5 and its Flash variant. Two super strong models now at #2 on the leaderboards, surpassing the score of Nano Banana 2 on image editing.
Last for now is MAI-Code-1-Flash, our new inference efficient coding model, especially tuned for VS Code and GitHub Copilot CLI.
- Code-1-Flash achieves 51% on SWE Bench Pro, despite having just 5B parameters, putting it closer to Haiku in size but cheaper in cost.
All of this is the foundation for Microsoft Frontier Tuning. It lets you customize our models to create custom, company-specific agents that only you control. You can make our model, your model. Your data. Your agents. Your moat.
Early adopters are already seeing a difference. When we tuned our models for McKinsey’s tasks, MAI delivered the highest win rate, outperforming GPT-5.5 on quality, while being 10x lower on cost.
Also really excited to be collaborating with the amazing team at Mayo Clinic to jointly train a new frontier AI model for healthcare.
Our announcements today mark another milestone on the road to humanist superintelligence. You can learn more and about our other new models in our latest blog: microsoft.ai/news/building-a…

42
267
2,088
283,452
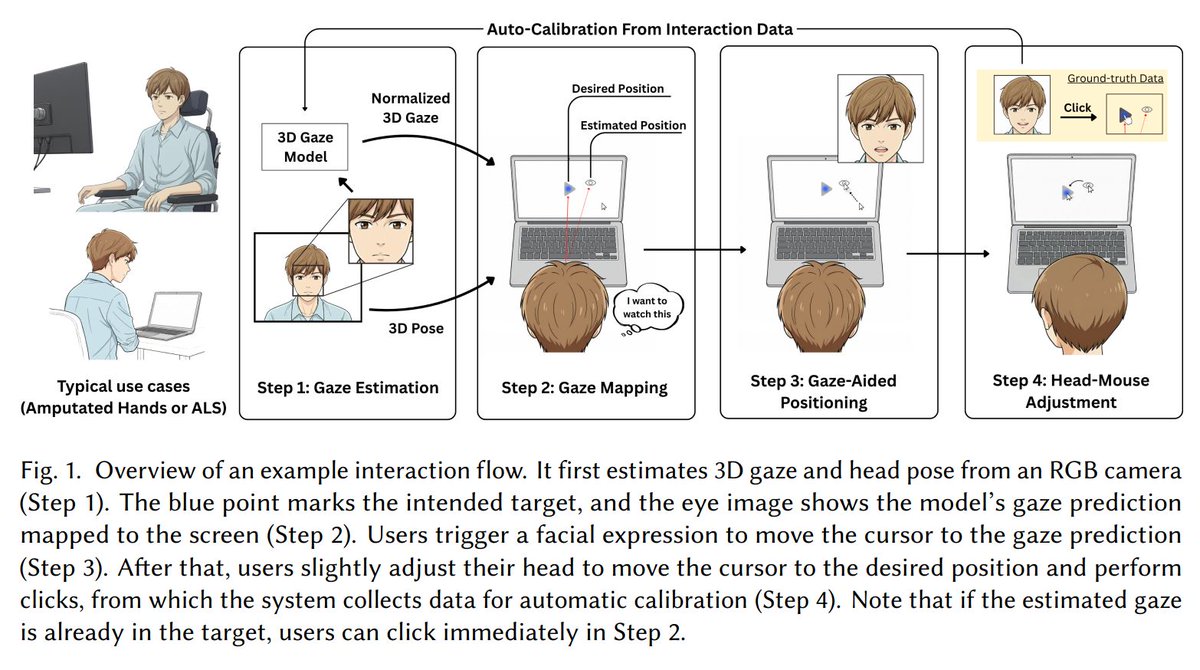
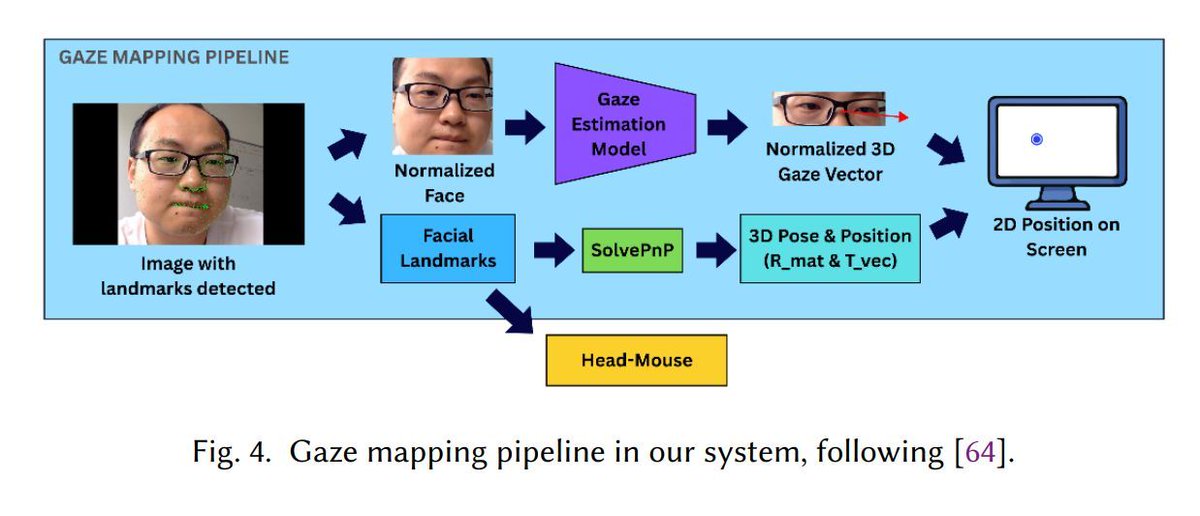
手足が使いにくい人向けに、カメラ1台だけで使えるハンズフリーなPC操作インターフェース「LookAHead」。
LookAHead: Hybrid Gaze (Look) And Head Refinement Approach for Hands-Free Computer Interaction | Proceedings of the ACM on Human-Computer Interaction dl.acm.org/doi/10.1145/38060…
28
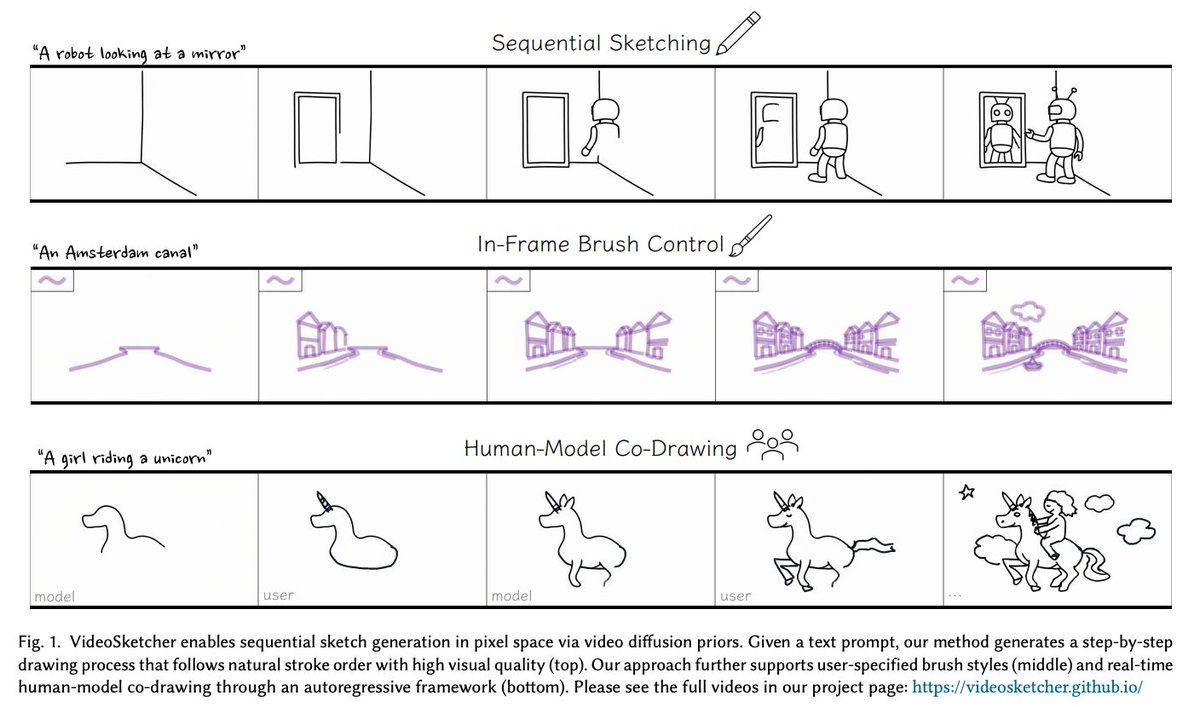
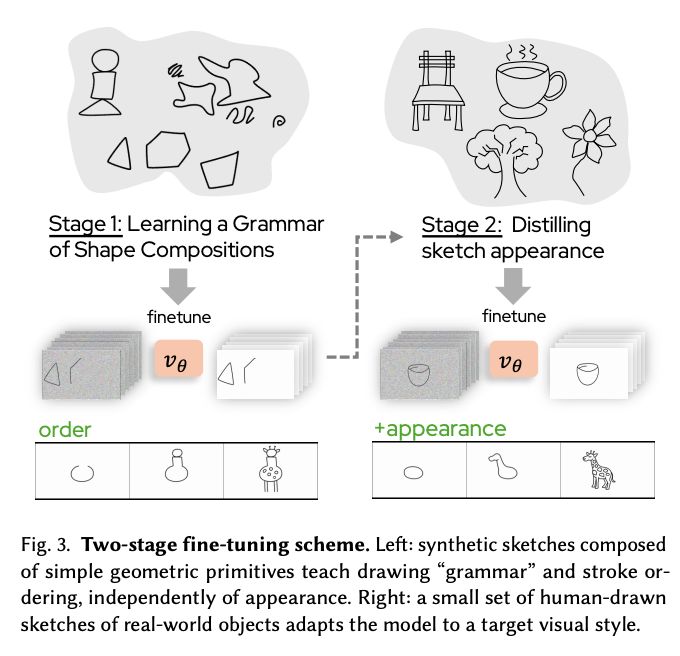
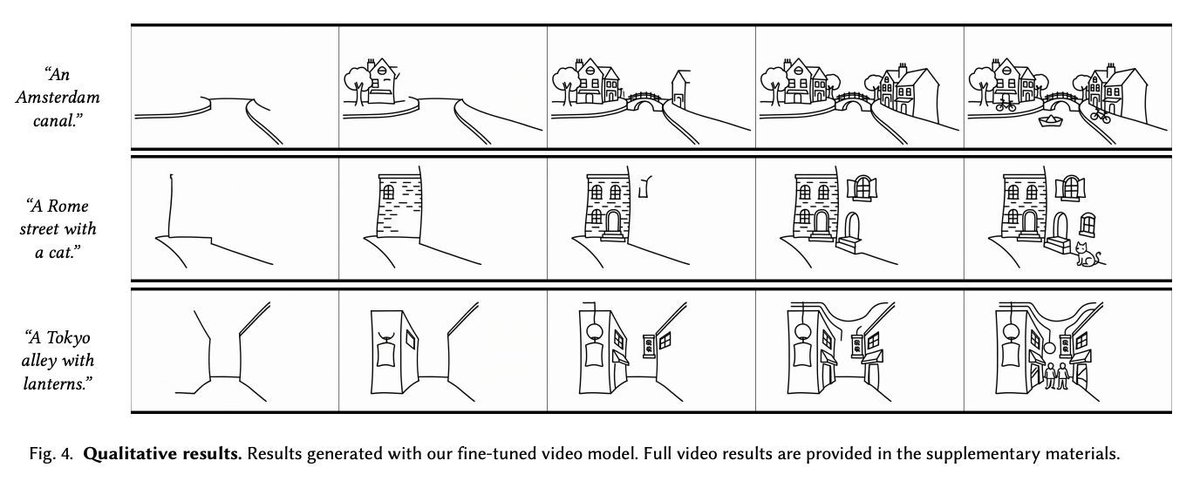
スケッチ生成を静止画像ではなく描くプロセスとして扱い、テキストから人間らしい描画順序のスケッチ動画を生成する「VideoSketcher」。インタラクティブな人–AIインタラクションが可能。
VideoSketcher: Video Models Prior Enable Versatile Sequential Sketch Generation videosketcher.github.io/
33
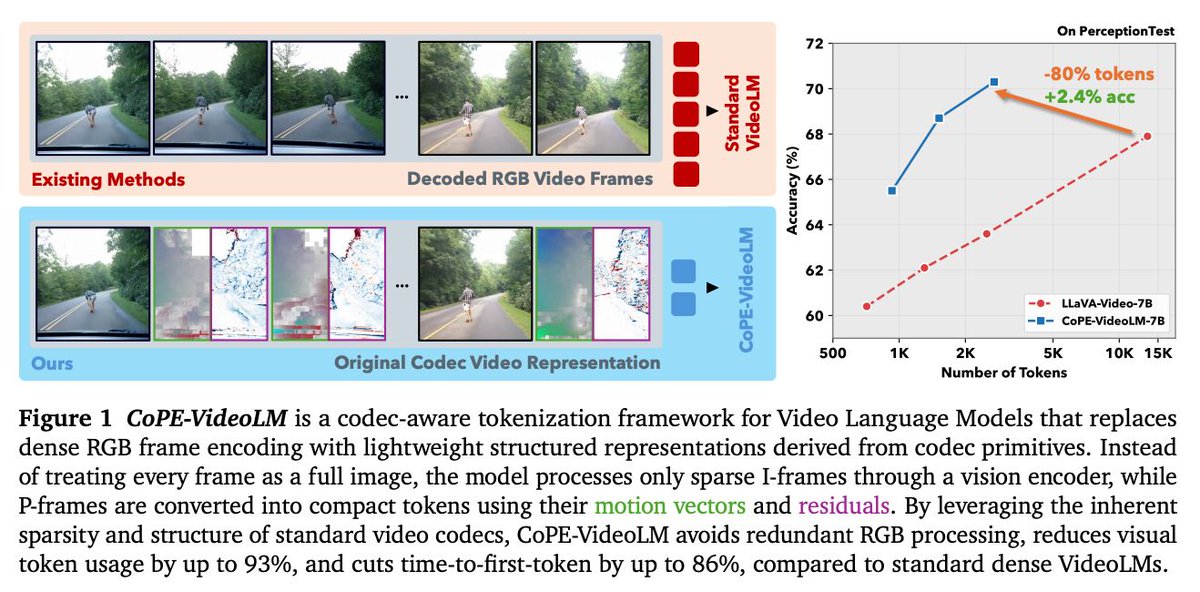
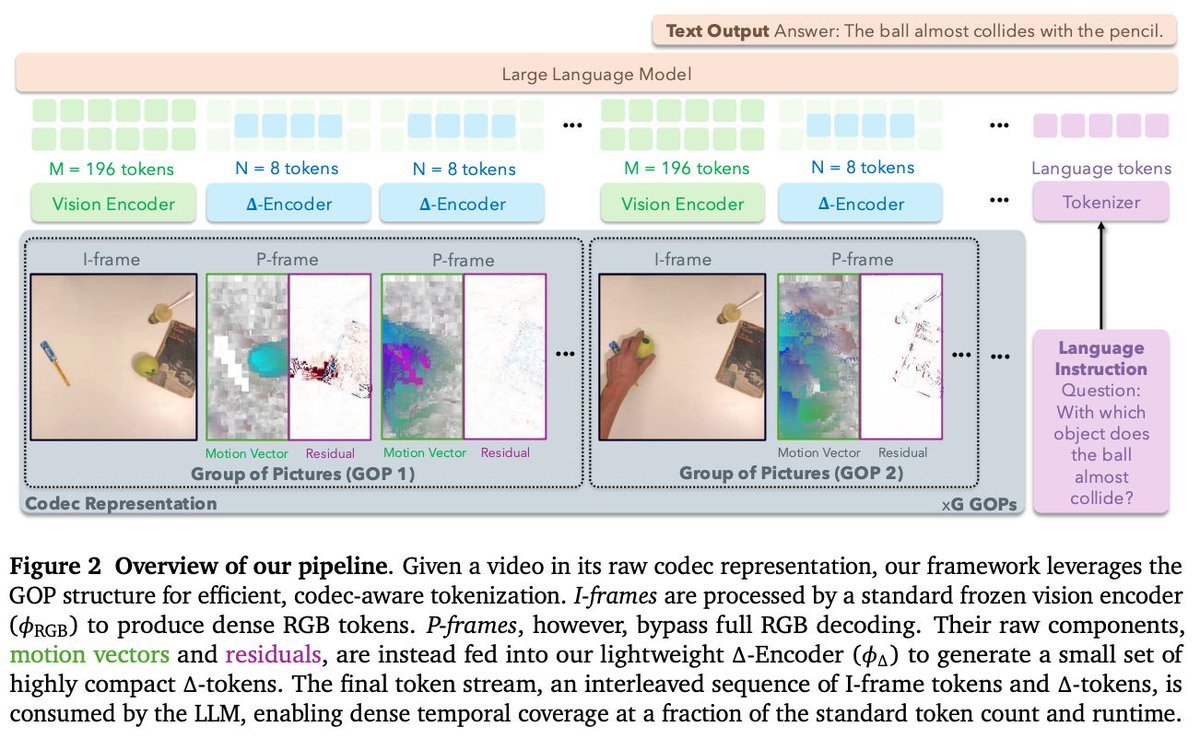
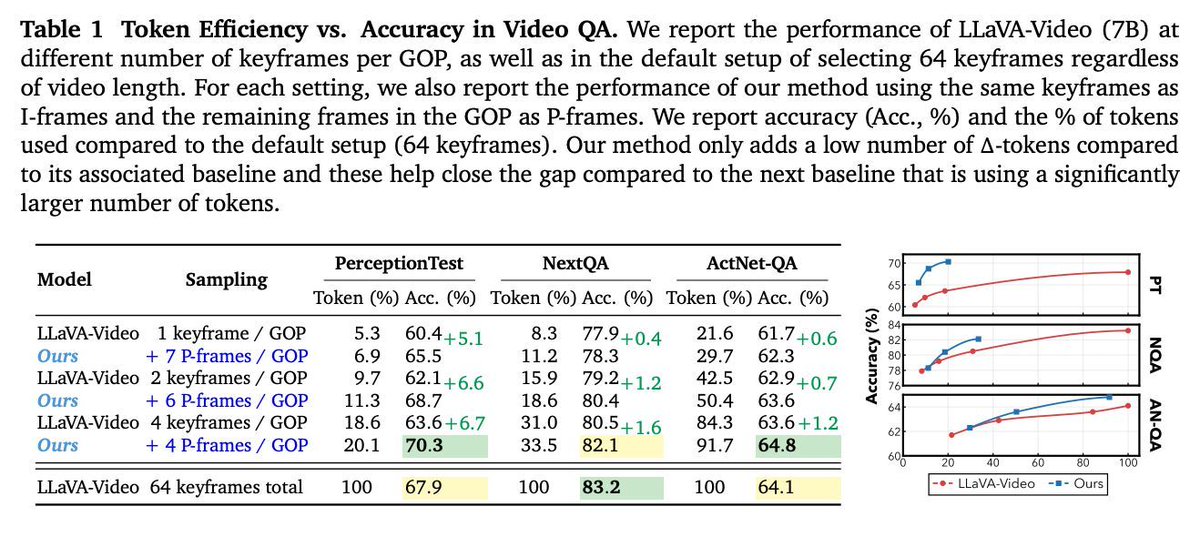
動画コーデックのmotion vectorとresidualを直接利用し、フレームを少数のΔトークンに圧縮するVideoLM向けトークナイズ「CoPE-VideoLM」。 トークン数を最大93%削減しつつ同等以上の精度
CoPE-VideoLM: Leveraging Codec Primitives For Efficient Video Language Modeling microsoft.github.io/CoPE/
1
20
atom retweeted

Jun 1
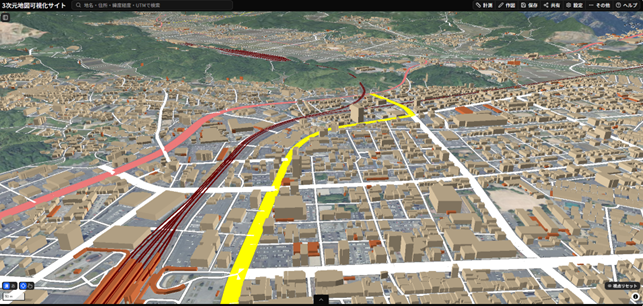
【リリース】
本日、「3次元地図可視化サイト」を試験公開!
―国土の姿をより分かりやすく―
「3次元電子国土基本図」のデータをウェブブラウザ上でご覧いただけます。
建物、道路、鉄道を立体的な表現で見ることができます。
▼「3次元地図可視化サイト」はこちら
gsi-cyberjapan.github.io/gsi…
12
1,309
3,826
736,249
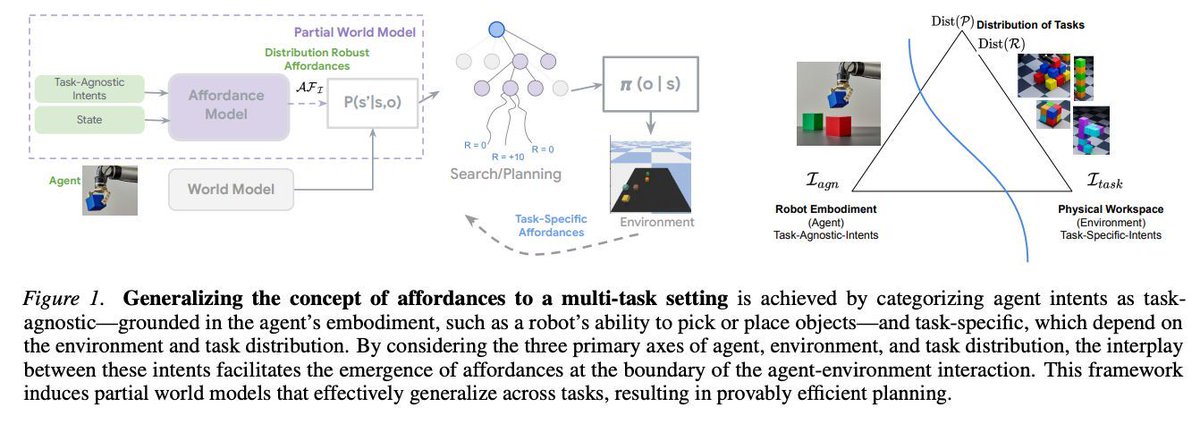
LLMをフルな世界モデルとして使うのではなく、アフォーダンスにもとづく部分世界モデルとして利用する理論と実験。探索の分岐数を大きく削減しつつ、高い報酬と効率的な計画が可能に。
Affordances Enable Partial World Modeling with LLMs arxiv.org/abs/2602.10390
18
音声を通じたプロンプトインジェクション。人には普通の音声にしか聞こえないがAIには命令として解釈される敵対的音声を用い、AzureやMistral AIなどのAIエージェントを遠隔操作可能に
AI voice bots hijacked by ‘hidden’ sounds in podcasts, MP3 files and YouTube clips cybernews.com/security/ai-vo…
1
49
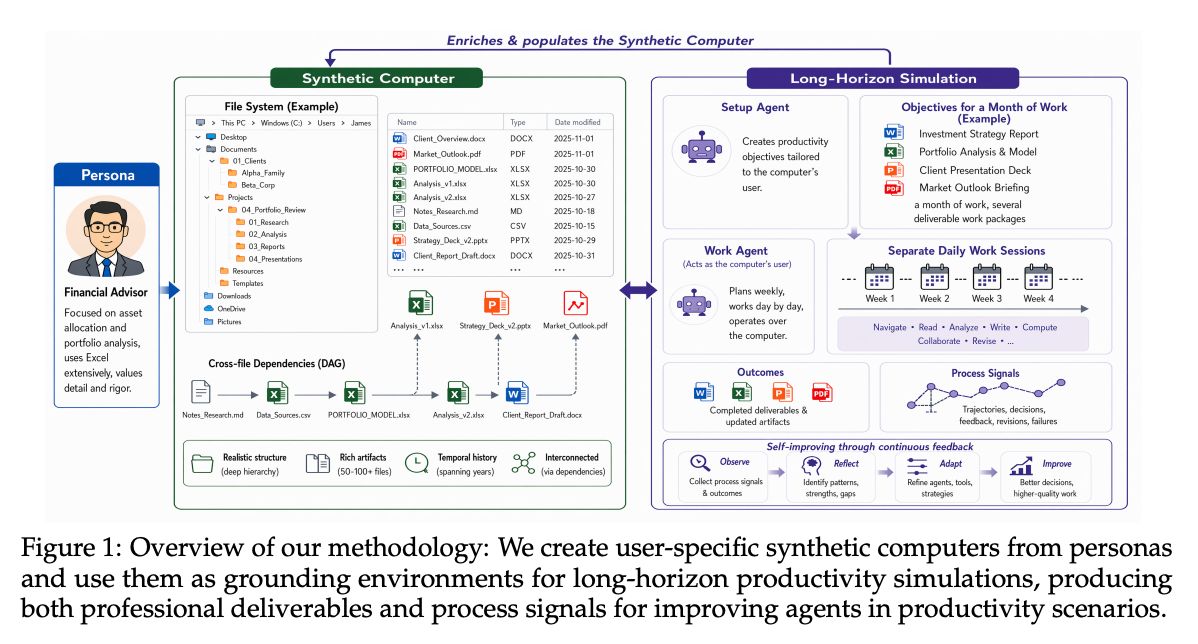
ペルソナ駆動で合成PC環境を作り、そこでエージェントに長期の仕事をさせて経験信号を収集する。得られた教訓や失敗パターンを職種別スキルとして整理するシミュレーションの枠組み。
Synthetic Computers at Scale for Long-Horizon Productivity Simulation arxiv.org/abs/2604.28181

46

画像あり評価と画像なし評価の比を「Mirage Score」として定義し、代表的な医療ベンチマークの多くがテキストだけでも高精度で解けてしまう構造的問題を指摘。 テキストや設問構造、公開データ由来のリーク、分布統計など。
MIRAGE: The Illusion of Visual Understanding arxiv.org/abs/2603.21687
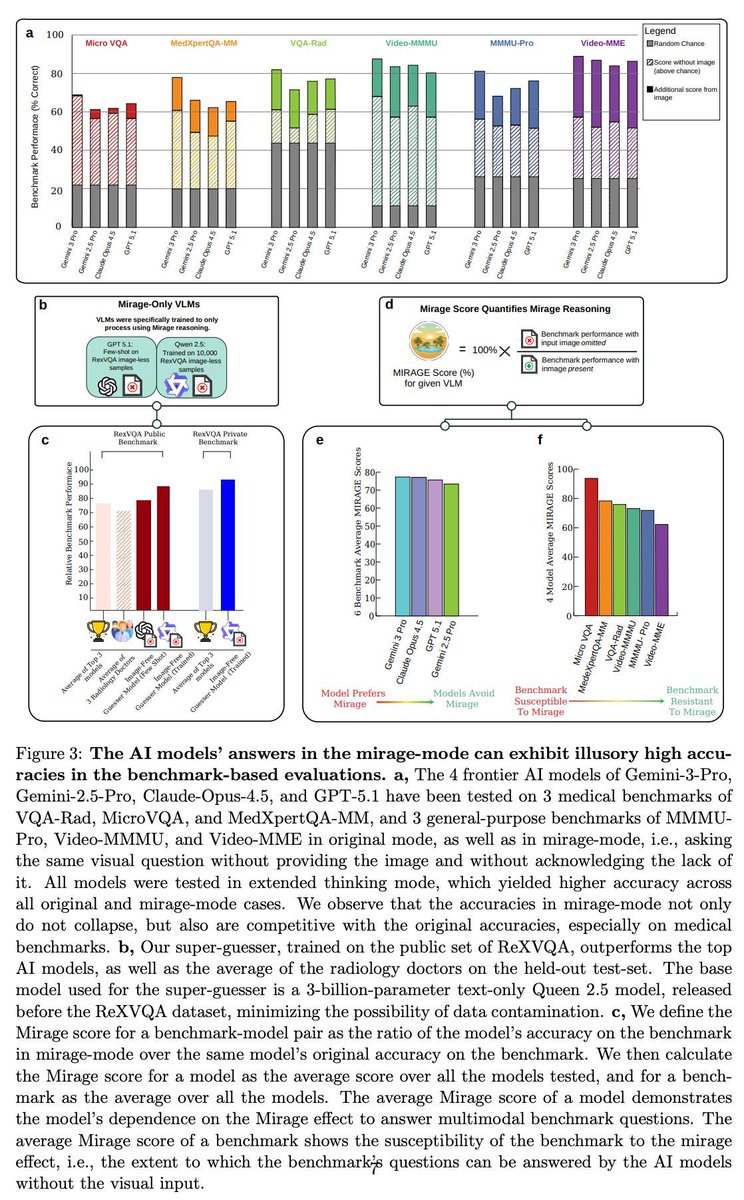
36
画像・動画・3Dを単一の4次元潜在空間にマッピングするトークナイザ「ATOKEN」。 再構成と意味理解を同時に実現し、ゼロショット精度82.2%など高い性能。
AToken: A Unified Tokenizer for Vision arxiv.org/abs/2509.14476
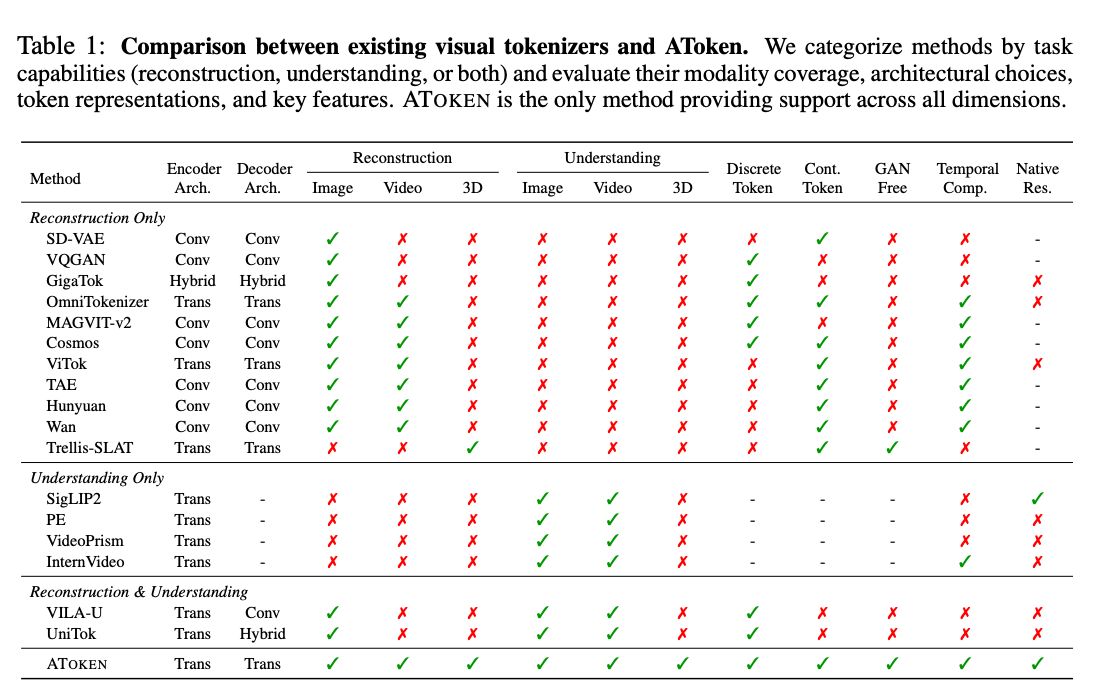
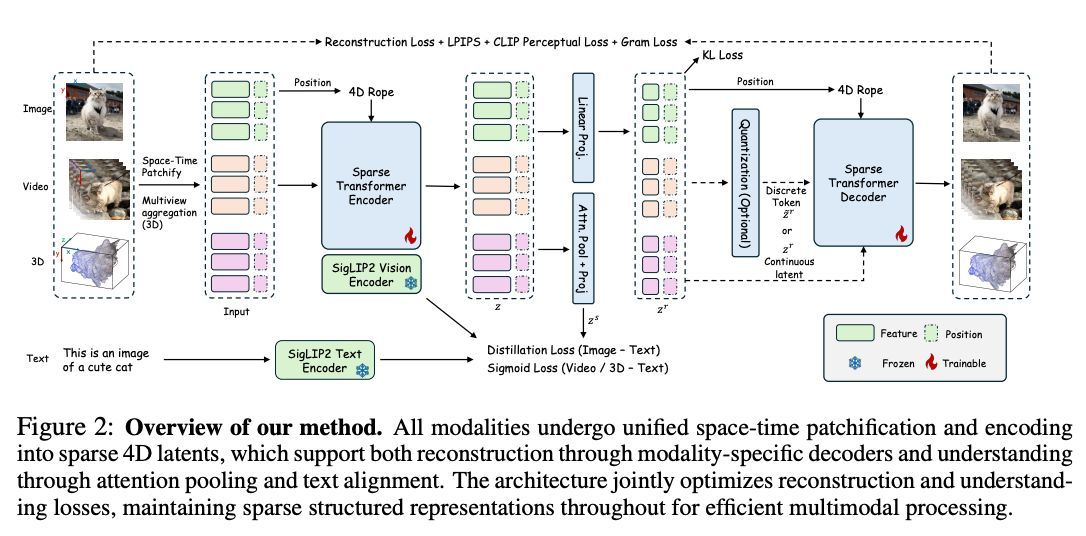
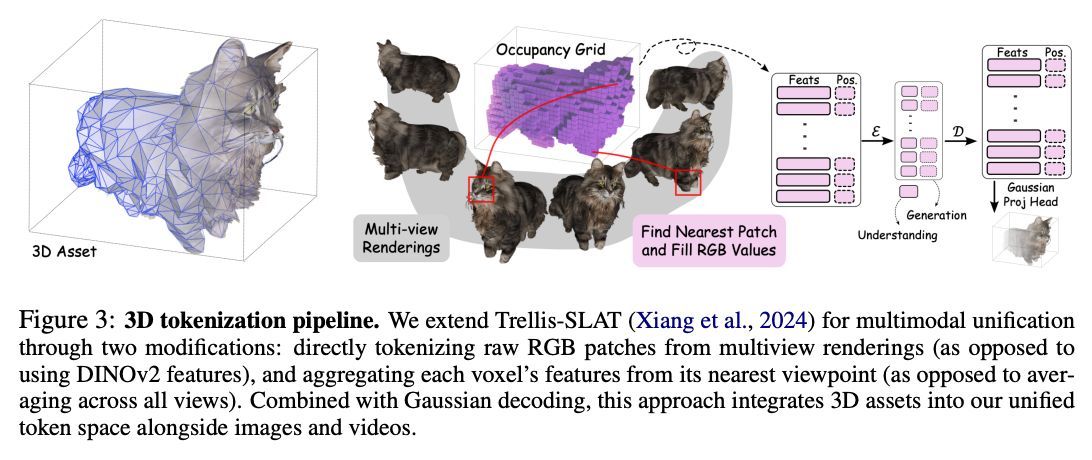
48
atom retweeted

May 26
Celebrating one week of Gemini Omni in Google Flow with 7 examples of what it can do 🧵
29
105
1,462
149,666
医療現場での不確実な診断を対象に、推論プロセスがコードレベルで検証・介入可能な「MedMSA(Medical Model Synthesis Architecture)」。LLMで症状文を確率的プログラミング言語 WebPPL の条件式などに変換して推論
Medical Model Synthesis Architectures: A Case Study arxiv.org/abs/2605.09716
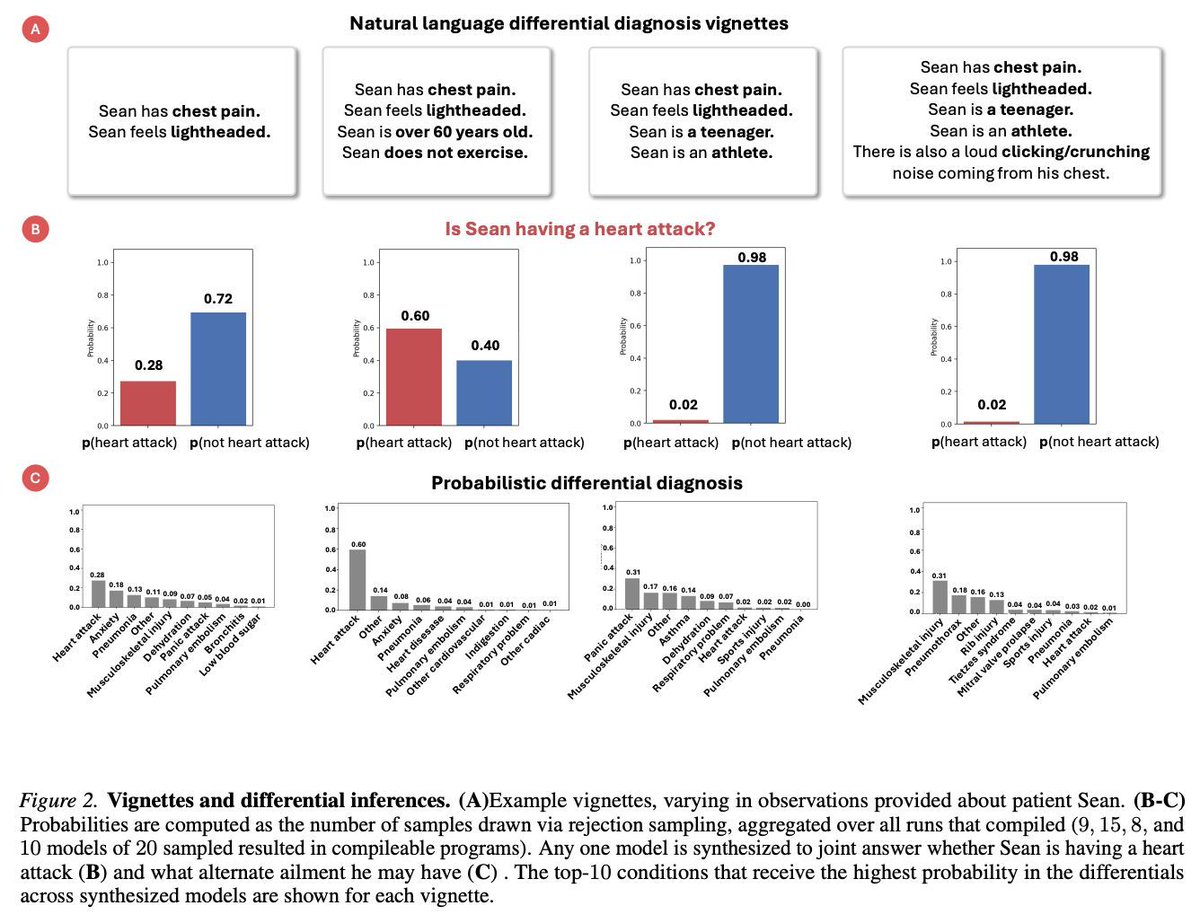
40