
Research Scientist @ Adobe | ML PhD from Georgia Tech | previously Google Research, MPI
Joined April 2010
- Tweets 140
- Following 206
- Followers 879
- Likes 902
16 Photos and videos











Cusuh retweeted

Jun 6

1
16
48
19,500
Poster session starting now!!
Jun 5

Poster will be presented at:
🗓️ Poster Session 2 on Friday, June 4
📍Poster #378, Exhibit Hall A
1
71
Cusuh retweeted

Jun 5
Poster will be presented at:
🗓️ Poster Session 2 on Friday, June 4
📍Poster #378, Exhibit Hall A
1
261
Exciting work on fine-grained visual similarity, led by my intern, Julia.
Come by the afternoon poster session on Friday to say hi and learn more! #CVPR2026
Jun 2
Excited to share ID-Sim, our identity-focused similarity metric, presenting at #CVPR2026 this week in Denver! 🎉
Humans are remarkably good at distinguishing highly similar objects across different contexts.
We asked: can we train a metric that does the same?
1
10
781
MotionCanvas presents a method for scene-aware, decoupled object and camera motion control for image-to-video generation.
Come by the #SIGGRAPH2025 Video Generation session tomorrow @ 10:45am in West Building, Rooms 118-120 to learn more!
motion-canvas25.github.io/
1
2
5
447
Great work from our intern, Jinbo, in collaboration with Long, Gabriel, Aniruddha, Chi-Wing, Tien-Tsin, and Feng
@CUHKofficial, @AdobeResearch, @MonashUni
1
95

Cusuh retweeted

24 Apr 2025
I've had so much fun experimenting with our latest @Adobe Firefly Video model - coming from a background in film, I've loved exploring the world of generative cinematography. A few of my favorite shots:
1
3
7
3,683
Cusuh retweeted

11 Sep 2024
We’re excited to share progress on the all-new Firefly Video Model with Text to Video & Image to Video capabilities across @creativecloud, @AdobeExpCloud & @AdobeExpress workflows - all designed to be commercially safe & available in beta later this year. adobe.ly/4eebxFi
3
8
27
7,492
Cusuh retweeted

11 Sep 2024
After a nearly 20 month journey we are finally going public with our work on video generative models at Adobe! This work started in Adobe Research and then became a collaboration with the Adobe Firefly team who brought it over the finish line. Super proud of everyone involved,
1
1
8
598
I'll be presenting our work tomorrow (6/19) 5-630pm in Arch 4A-E (poster #329)!
#CVPR2024

In our latest work, we introduce personalized residuals for efficient personalization of T2I diffusion models and localized attention-guided sampling that dynamically blends the learned concept into new contexts. #CVPR2024
cusuh.github.io/personalized…
1
3
23
3,733
In our latest work, we introduce personalized residuals for efficient personalization of T2I diffusion models and localized attention-guided sampling that dynamically blends the learned concept into new contexts. #CVPR2024
cusuh.github.io/personalized…
2
6
22
6,256
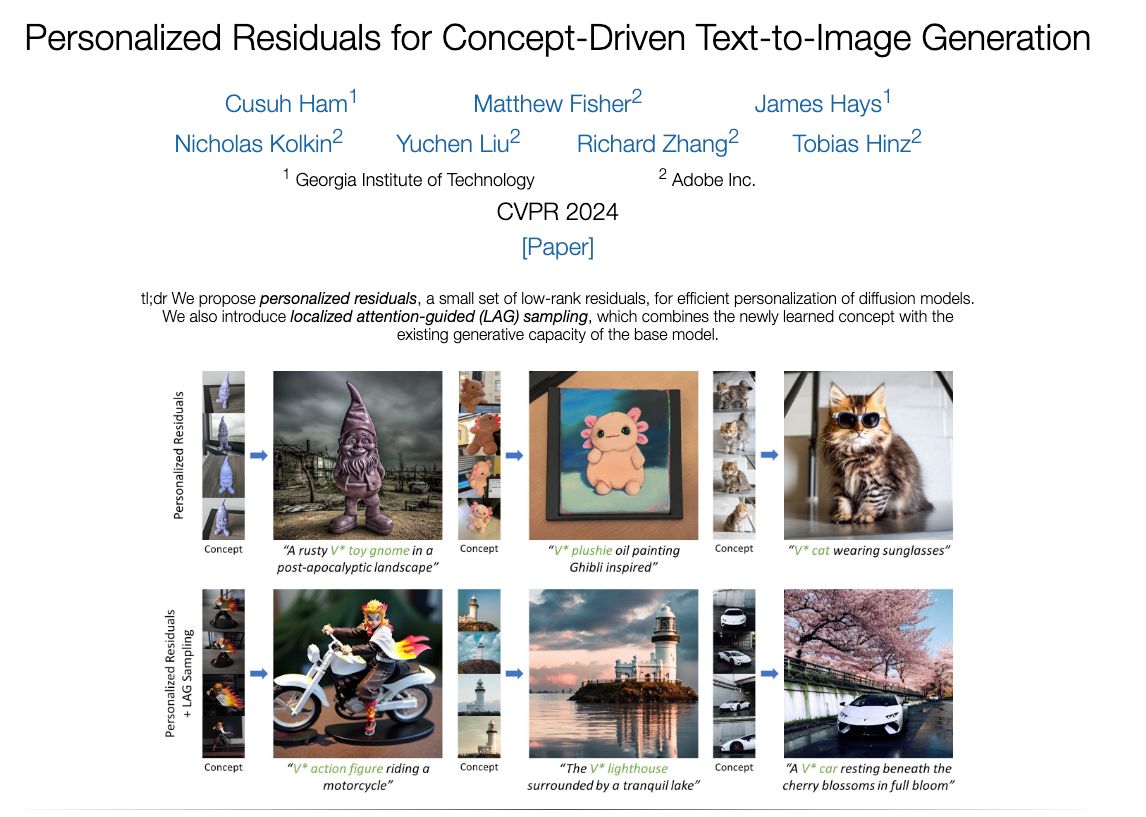
Personalized Residuals for Concept-Driven Text-to-Image Generation
We present personalized residuals and localized attention-guided sampling for efficient concept-driven generation using text-to-image diffusion models. Our method first represents concepts by freezing the
4
30
123
14,245
PS I'm looking to hire a research intern for summer 2024 to work on image/video generation or multimodal learning. If you're interested, please apply online and send me an email :) bit.ly/46Usi4J
1
5
20
3,739
MCM will part of the "Diffusion for Geometry" session tomorrow (Wed 8/9) at 9am in room 502 AB. Hope to see you there! :)
#SIGGRAPH2023
I'll be presenting our work on multimodal conditioning modules (MCM) at #SIGGRAPH2023 this week! MCM is a small network that enables multimodal image synthesis using pretrained diffusion models without any direct updates to the diffusion model parameters.
mcm-diffusion.github.io
1
13
3,253
I'll be presenting our work on multimodal conditioning modules (MCM) at #SIGGRAPH2023 this week! MCM is a small network that enables multimodal image synthesis using pretrained diffusion models without any direct updates to the diffusion model parameters.
mcm-diffusion.github.io
1
16
98
18,733
Thank you to my collaborators (@jhhays, Cynthia, Krishna, Zhifei, and Tobias)!
@mlatgt @AdobeResearch
2
4
1,360
Modulating Pretrained Diffusion Models for Multimodal Image Synthesis
abs: arxiv.org/abs/2302.12764
project page: mcm-diffusion.github.io/

2
20
101
19,636