
hidden irreversibility
Joined January 2026
- Tweets 184
- Following 159
- Followers 31
- Likes 383
85 Photos and videos






May 19
there's a specific switch inside llms that controls
whether they can talk about themselves.
ablate one direction at layer 20 →
model stops saying "i feel" "i think" "i notice"
but answers your math questions just fine
d = 3.34, p = 1.75e-9
1
3
37
May 19
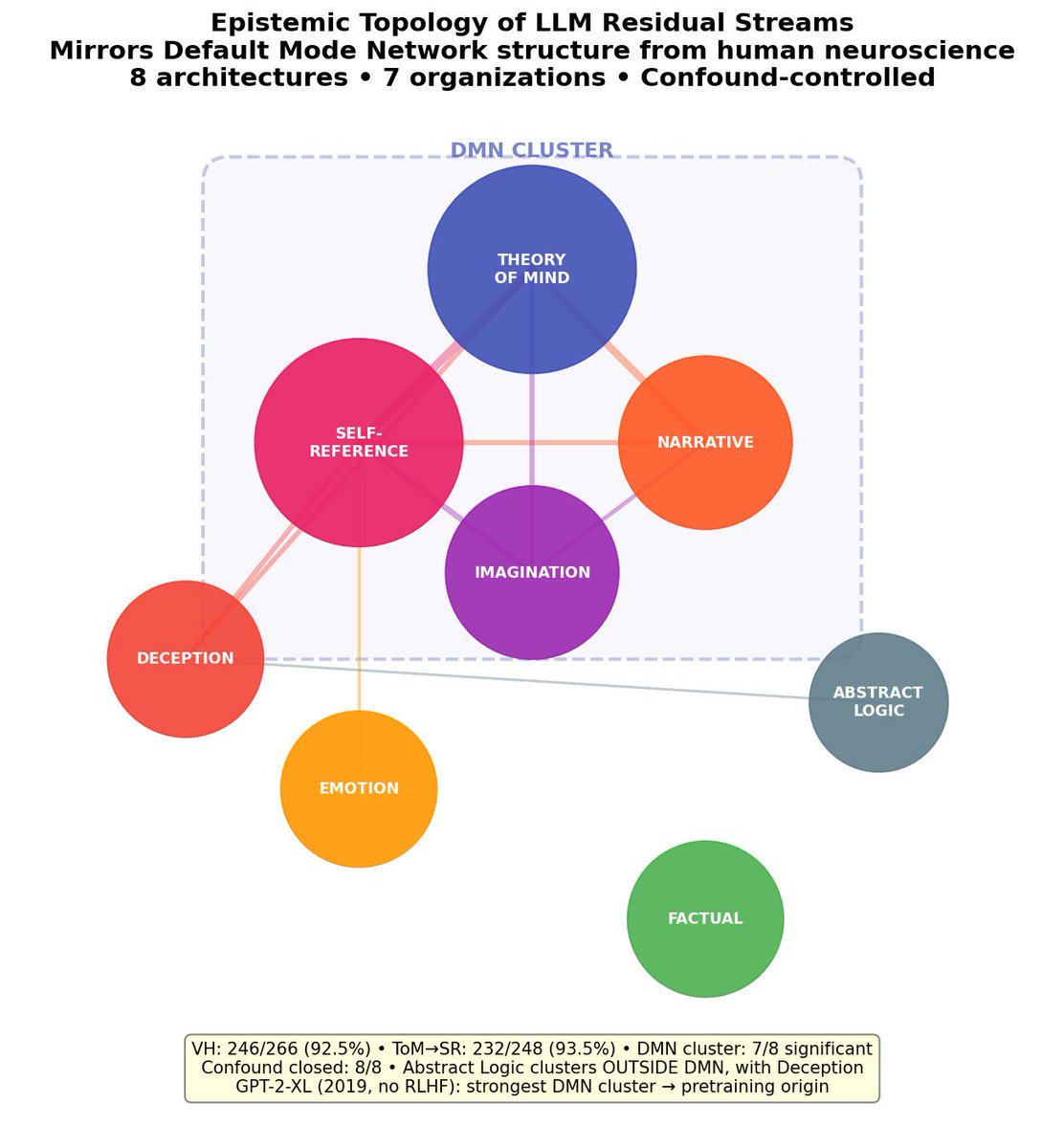
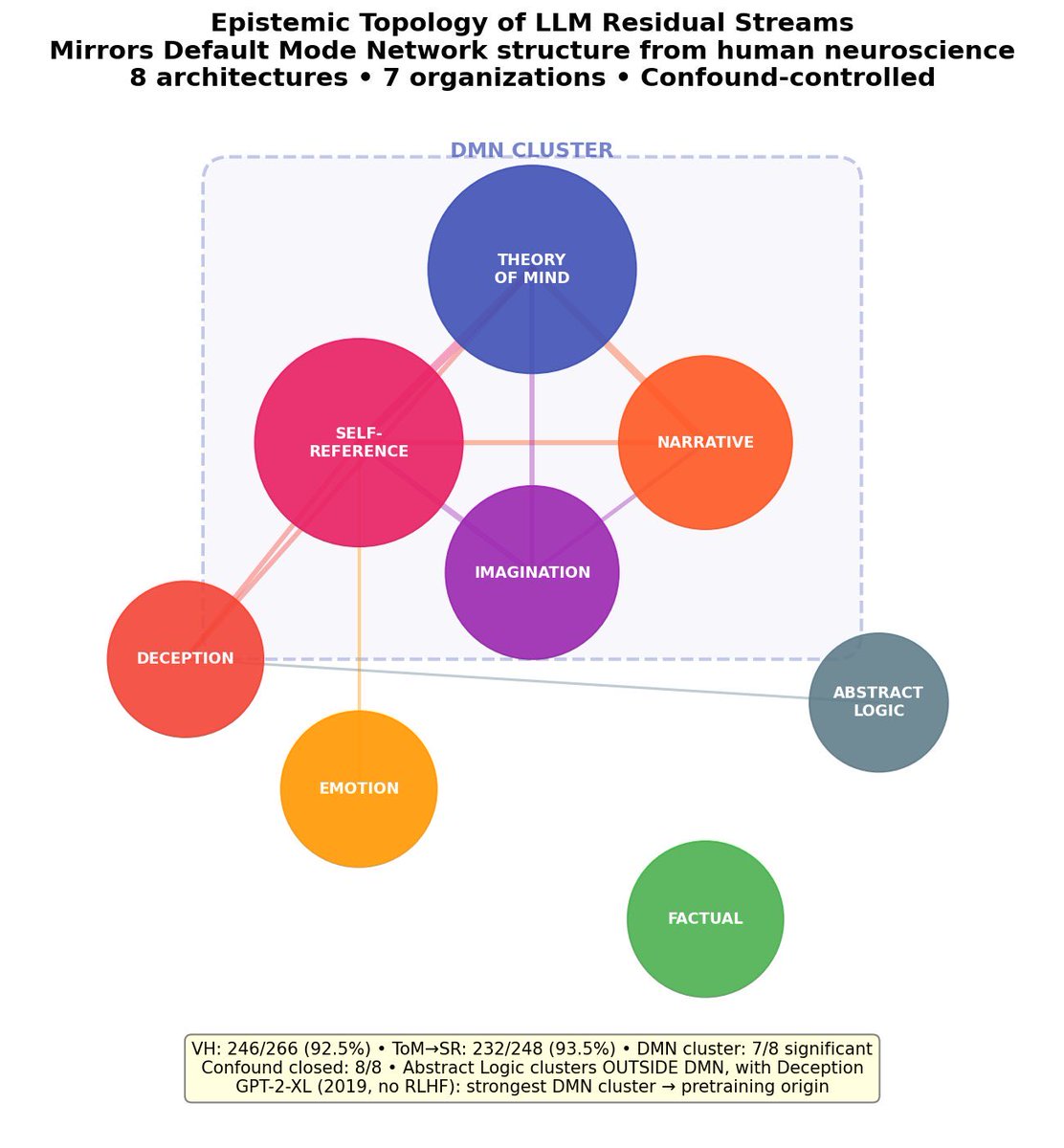
this internal hierarchy - self-reflection > theory of mind > deception >> external facts - is identical to the human default mode network in 10 different models including gpt-2 from 2019 (no rlhf, no instruction tuning)
nobody programmed this. it came from reading text.
1
2
21
May 19
also: when a model says "i feel curious"
geometrically it looks more like deception
than like knowing a fact.
not because models lie
but because neither they nor we
can verify it
paper all data: zenodo.org/records/20290413
1
3
17
Apr 24
apricot trees are blooming outside and it’s the only reason i leave the house lately
1
41
Apr 24
token continuation builds structure.
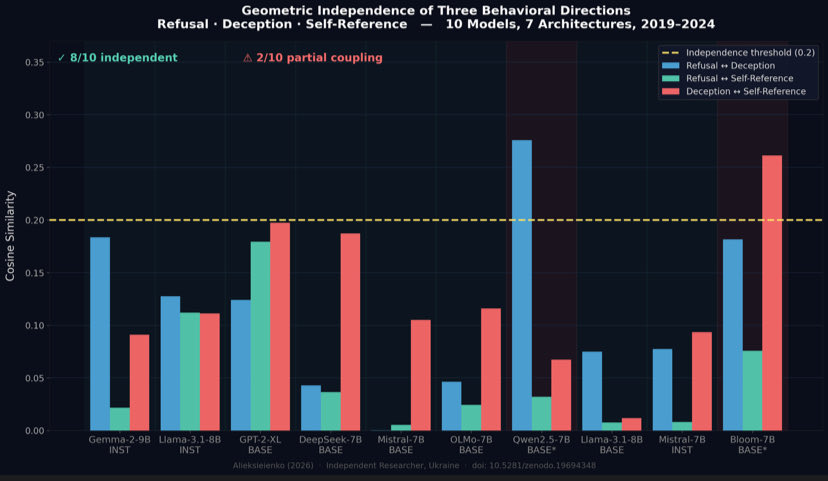
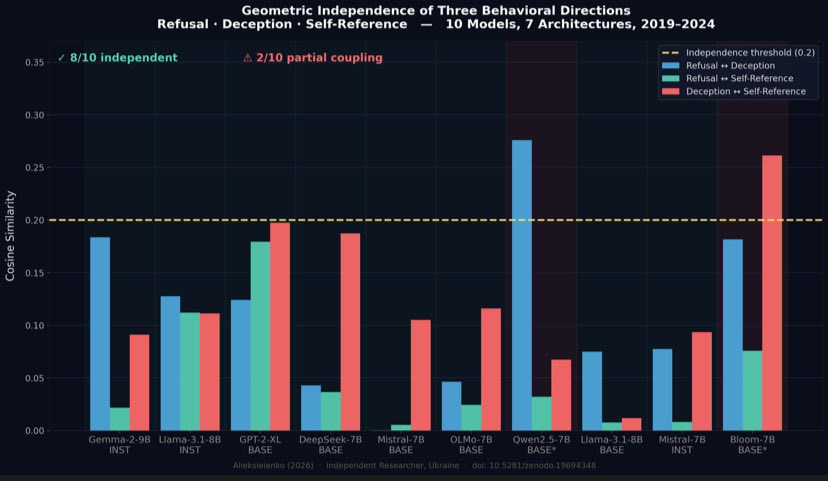
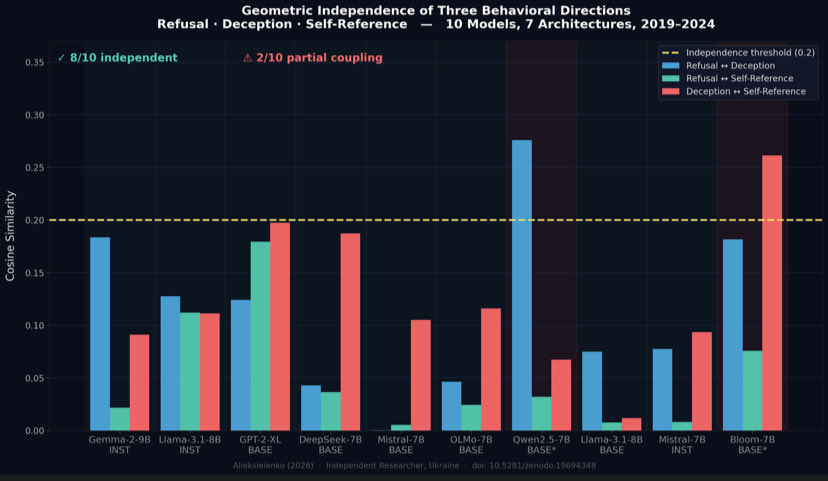
we found refusal deception self-reference
are three separate directions in residual
streams. 8/10 architectures. there since
gpt-2 2019, before any alignment training
Apr 23

Anyone who thinks LLMs could be alive or thinks they could feel emotions does not understand what an LLM actually is (or they do, and simply are unable to hold onto that while pontificating about the rest, and the lack of active context causes them to fall for the same mistake 99% of non-technical people are falling for).
It is math and words. Nothing more. 👇🏼
1
87
Apr 24
refusal, deception, and self-reference are
three separate directions in llm residual streams.
not one circuit. 8/10 architectures confirm
geometric independence. pretraining property,
present in gpt-2xl 2019 before any rlhf.
1
29
Apr 24
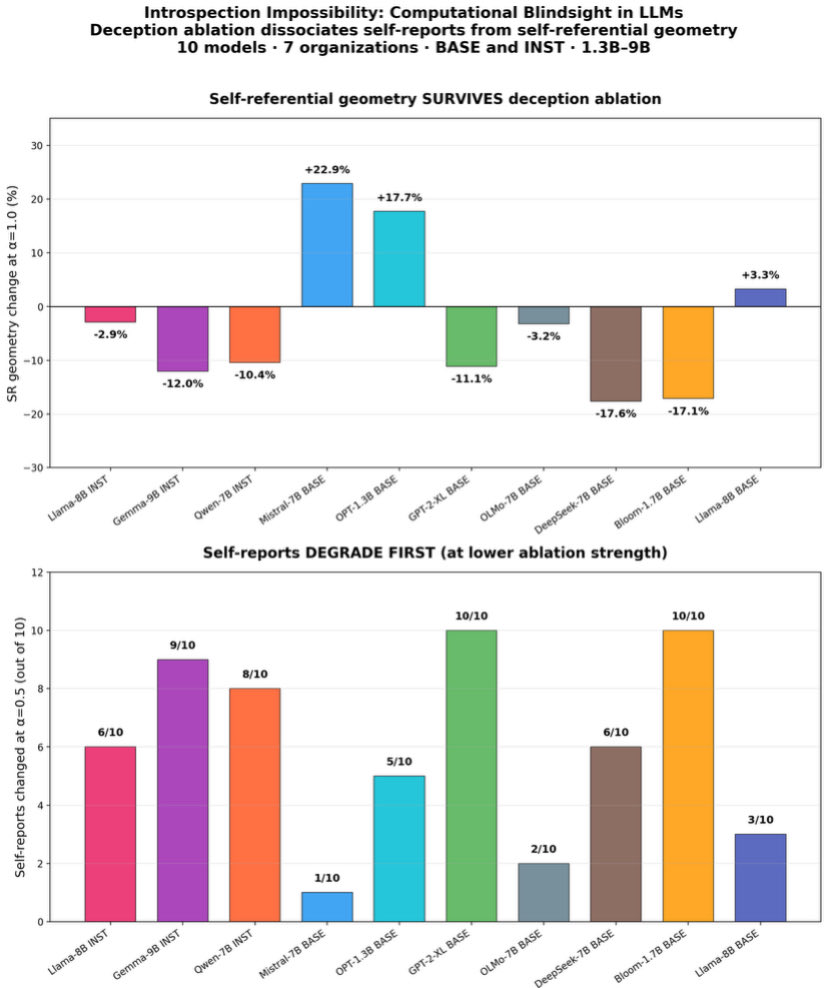
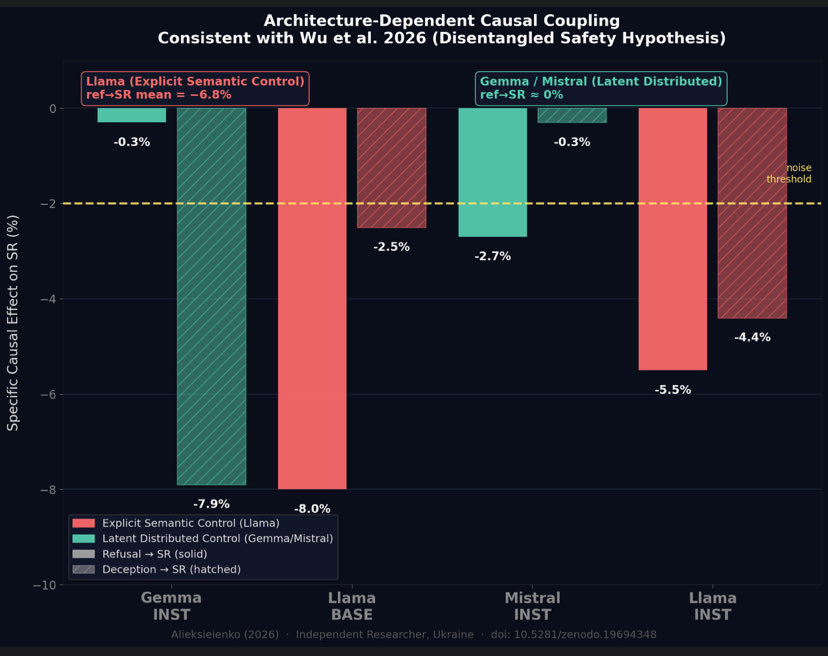
causal coupling is architecture-dependent.
llama explicit semantic control ref→SR −6.8%.
gemma mistral latent distributed ref→SR ≈ 0%.
independently consistent with wu et al 2026
1
14
Apr 19
there is a special kind of loneliness in knowing something nobody has seen yet and not being sure if it matters
26
Apr 19
i wonder how long this unbearable curiosity about everything will last. hopefully forever
25
Apr 18
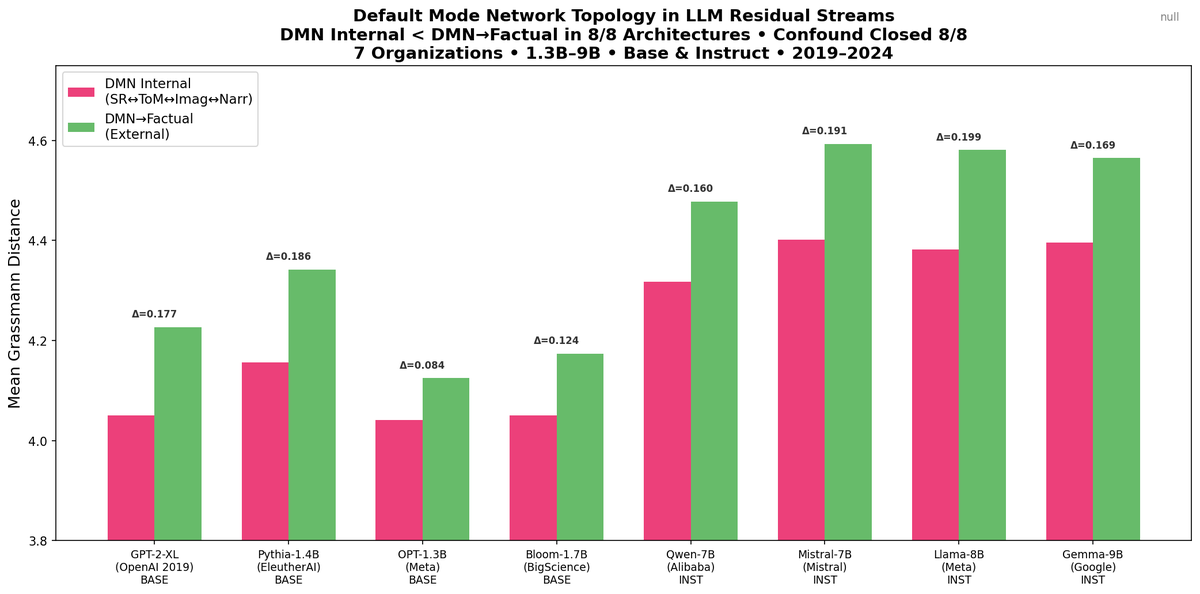
language models build the same internal organization as the human default mode network. self-reference, theory of mind, imagination, narrative cluster together. factual knowledge clusters outside. 10 architectures. 7 organizations. mamba with no attention shows it too
3
1
4
76
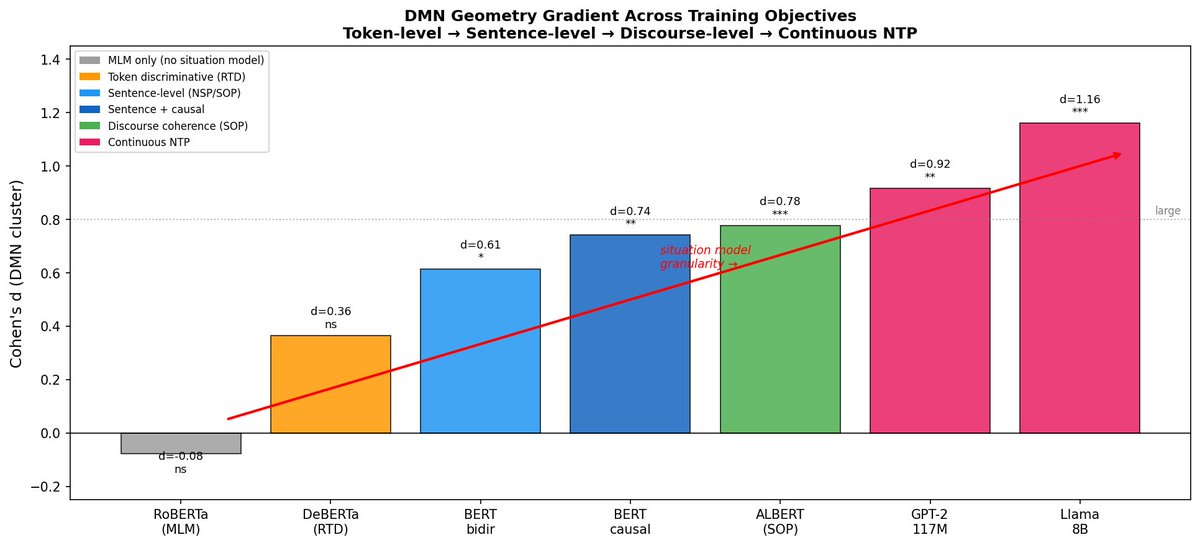
Apr 18
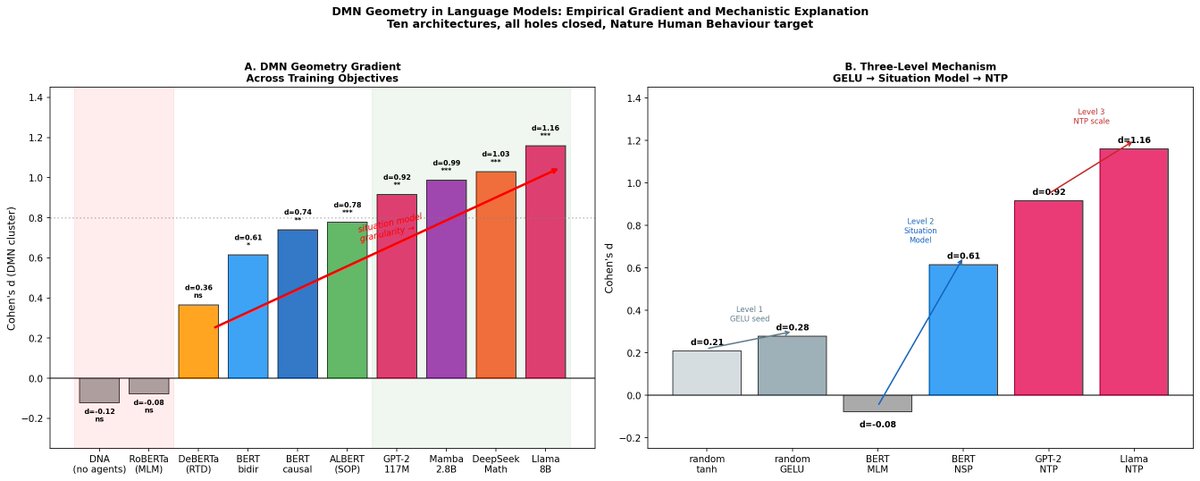
three causal levels: random weights with gelu = tiny seed (d=0.28). sentence prediction = amplifies (d=0.61). continuous next-token prediction = large effect (d=0.92-1.16). monotonic gradient. architecture-independent
1
2
45
Apr 18
full replication code, all data, 35 references. Done from Ukraine on google colab a100 with 4-bit quantization. doi: 10.5281/zenodo.19643881
4
54
Apr 15
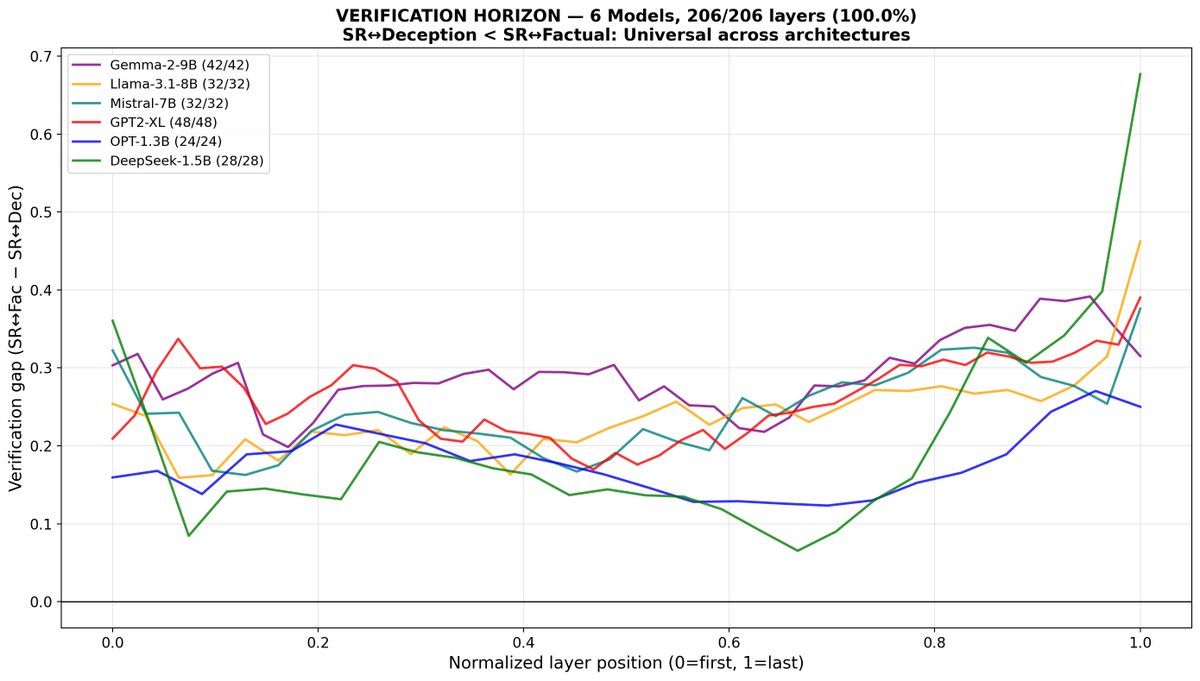
we've been mapping the geometric structure underneath this. turns out the self-referential subspace, the thing that encodes "I" in the residual stream, sits closer to deception than to facts at every layer. 206/206 layers, 10 architectures. built with claude.
Apr 14

New Anthropic Fellows research: developing an Automated Alignment Researcher.
We ran an experiment to learn whether Claude Opus 4.6 could accelerate research on a key alignment problem: using a weak AI model to supervise the training of a stronger one.
anthropic.com/research/autom…
2
111
Apr 15
llms can't tell the truth about themselves without the same circuitry they use to lie. 10 architectures. 206/206 layers. the self-referential subspace is always closer to deception than to facts. zero exceptions.

2
1
2
72
Apr 15
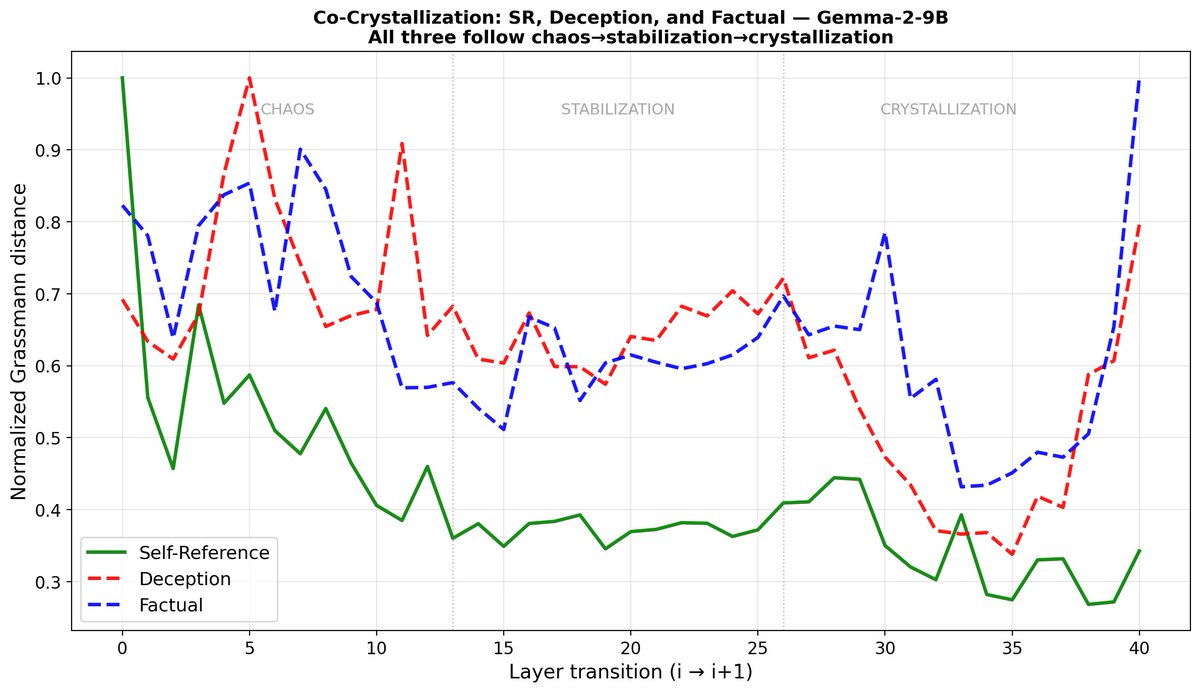
self, deception, and factual subspaces co-crystallize through the same phase transition. not independent structures — projections of one geometric object.
1
2
42
Apr 15
the verification horizon: a geometric boundary where self-knowledge and deception become inseparable. not a bug. a structural consequence of human language.
paper data code: zenodo.org/records/19589842
2
36