
PhD student @unccs advised by @mohitban47 | Intern @AIatMeta, @AdobeResearch | Multimodal, Video, Embodied AI, Post-training, RL
Joined February 2024
- Tweets 496
- Following 562
- Followers 525
- Likes 547
30 Photos and videos






Pinned Tweet

Mar 17
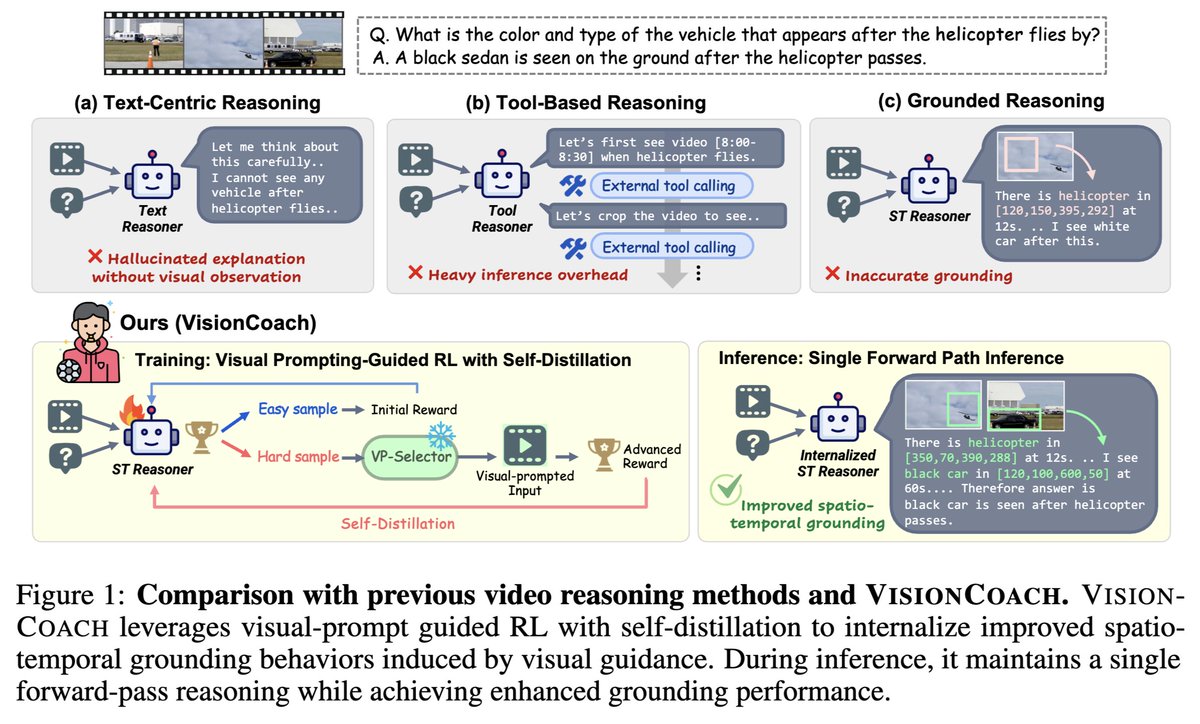
🚨 Excited to share VisionCoach, an RL framework for reinforcing grounded video reasoning via visual-perception prompting and self-distillation!
🧠 Video reasoning models often miss where to look or rely on language priors. Instead of only supervising final answers, we encourage the model to learn to attend to the right visual evidence.
⚽️ VisionCoach uses RL to reward correct visual attention, with dynamic visual prompting as a training-time coach for better spatio-temporal grounding, while keeping inference simple and tool-free via self-distillation.
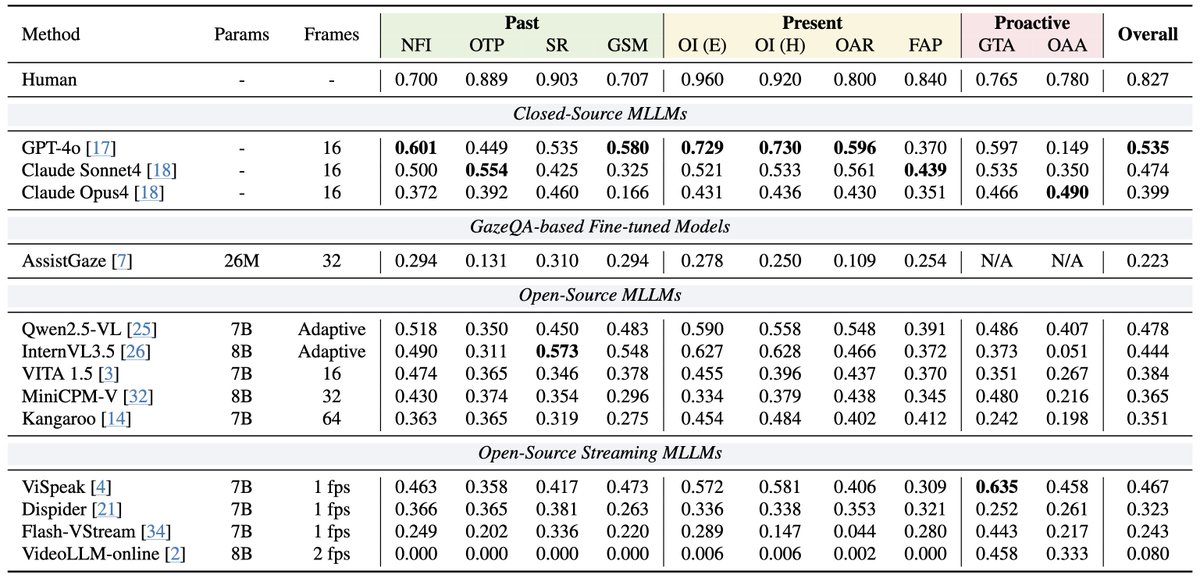
⭐️ Achieves state-of-the-art zero-shot performance across video reasoning, video understanding, and temporal grounding benchmarks (V-STAR, VideoMME, World-Sense, VideoMMMU, PerceptionTest, and Charades-STA).
👇🧵
1
24
77
11,100
Daeun Lee retweeted

May 31
I'll be at #CVPR2026, feel free to ping if you want to meet up! Will be giving 4 different keynotes at these exciting @CVPR workshops and looking forward to engaging discussions on diverse topics 🙂
(also happy to discuss hiring at all levels: PhD, postdoc, faculty)
ps. also meet several of our awesome students/postdocs who will be attending

1
24
64
4,630
Daeun Lee retweeted

May 15
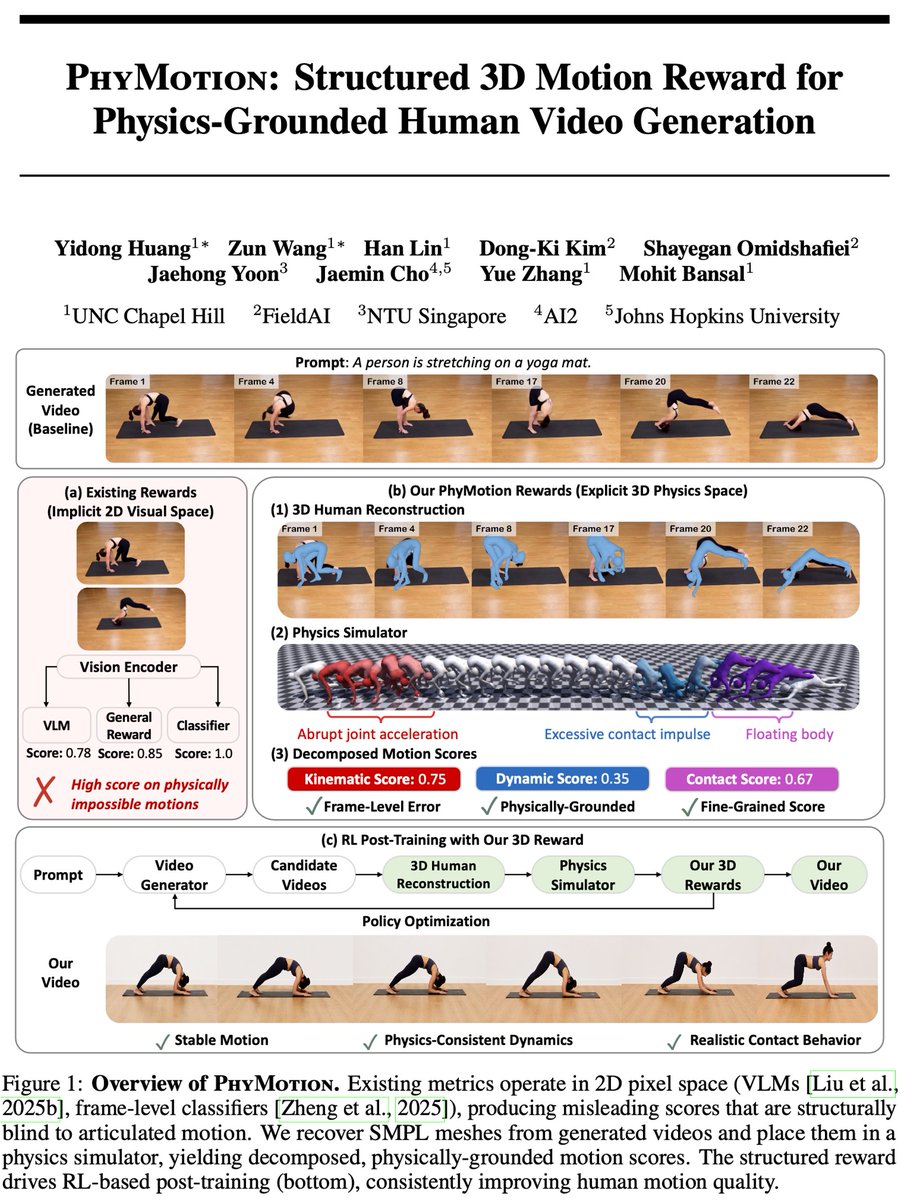
🚨 Excited to introduce PhyMotion🤸: Structured 3D Motion Reward for Physics-Grounded Human Video Generation!
❌ Existing 2D video rewards misleadingly assign high scores to videos with floating feet, self-penetrating limbs, and physics-violating motions.
✅ PhyMotion lifts generated videos into 3D, grounds them in a physics simulator, and scores motion along kinematic / contact / dynamic feasibility.
➡️ RL post-training with PhyMotion improves 1.3B model to match 14B models performance in human prefence.
🧵(1/n)👇
2
36
97
56,619
Daeun Lee retweeted

May 12
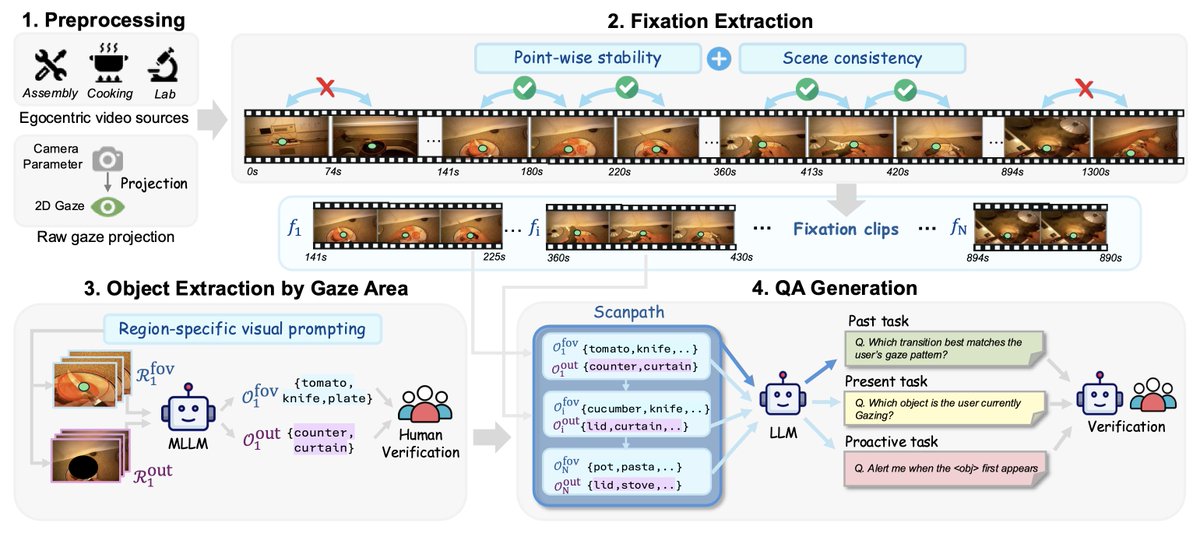
🚨 Excited to share EgoMemReason, a benchmark for multi-level memory-driven reasoning (entity, event, and behavior memory) over week-long egocentric videos (average 25.9 hours of temporal backtracking)!
📉 Current long video approaches can retrieve isolated event, but struggle with long-horizon memory that requires retrieve and understand across multiple events and long time: tracking evolving entities across days, linking temporally distant events, and abstracting recurring behavior patterns from long observations.
🎥 EgoMemReason evaluates these challenges through 500 human-verified questions spanning entity, event, and behavior memory, requiring aggregation over an average of 5.1 evidence segments and 25.9 hours of temporal backtracking.
⭐️ Across 17 models/frameworks, even the best model achieves only 39.6% accuracy, revealing that long-horizon multimodal memory remains far from solved.
3
28
48
8,273
Daeun Lee retweeted
May 8
Looking forward to giving a keynote at the Midwest Machine Learning Symposium (MMLS) 2026 (being held at Purdue University this year) & meeting folks from all the strong universities in the midwest, with their inspiring, long tradition of these exciting symposiums! 🙂
👇👇
May 8

The Midwest Machine Learning Symposium (MMLS) 2026 will happen at Purdue University!
📍 West Lafayette, IN
📅 June 24–25, 2026
🔗 midwest-ml.org/2026/
📌 Poster submission deadline: May 24
We have an amazing lineup of plenary speakers: Tong Zhang, Jennifer Neville @ProfJenNeville, Mohit Bansal @mohitban47, Joyce Chai.
Looking forward to seeing you there!
@PurdueCS @PurdueECE @PurdueStats

18
44
3,868
Daeun Lee retweeted

May 1
🎉 Excited to share EPiC is accepted to #ICML2026!
We show that learning precise camera control for video diffusion doesn't need expensive 3D supervision or large-scale data. No camera or point cloud processing — just mask source videos based on visibility to construct precise training anchor videos, and learn a SoTA camera controller with only 30M params, trained >100× faster on >100× less data than prior work, while generalizing across both I2V and V2V camera control tasks.
29 May 2025

🚨Thrilled to introduce EPiC🎥: Efficient Video Camera Control Learning with Precise Anchor-Video Guidance
A generative model enables precise 3D camera trajectory control over user-provided videos or images. It achieves highly efficient training, completing within just 16 GPU-hours (2 hours on 8×H100 GPUs), significantly faster compared to baselines that typically require at least 200 GPU-hours, while achieving better performance.
Thread 🧵👇(1/8)
1
16
34
4,749
Daeun Lee retweeted

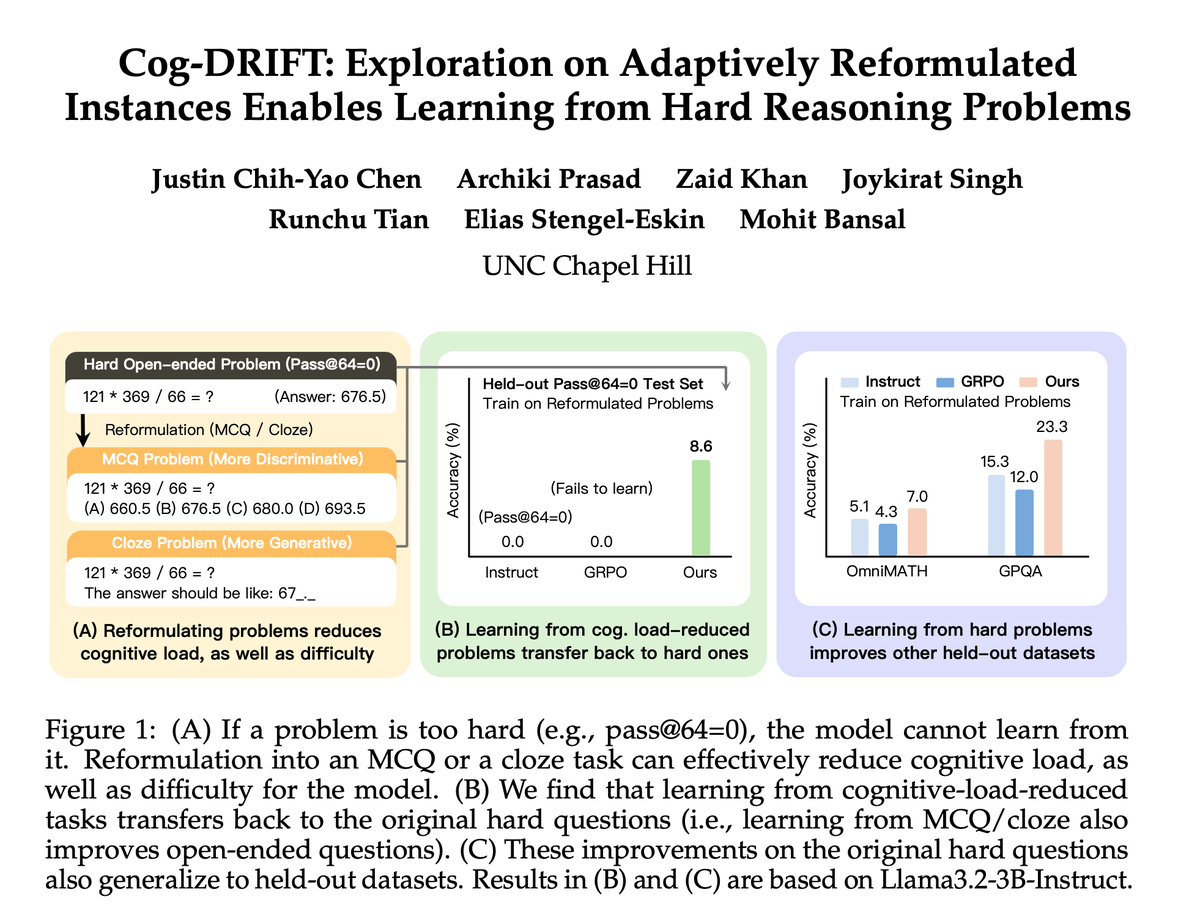
🚨Cog-DRIFT: Breaking the Exploration Barrier in RLVR
RLVR has pushed LLM reasoning forward BUT hits a ceiling: if a model can't solve a problem (rollouts never succeed), it gets 0 learning signal 👉Hard problems stay unsolved, and training stalls.
We introduce✨Cog-DRIFT✨to reformulate hard problems into "cognitively" easier, structured variants (MCQ and cloze), then curriculum-train models from easy → hard to unlock new learning signals.
Key takeaways:
1⃣ Breaks the ceiling on "unsolvable" hard problems from 0% → 10.11% (Qwen) & 0% → 8.64% (Llama) in absolute gains
2⃣ Consistent gains across 6 benchmarks & 2 models → 4.72% (Qwen), 3.23% (Llama) over strong baselines
3⃣ Reformulations span discriminative → generative formats, enabling effective knowledge transfer back to hard open-ended reasoning
4⃣ Adaptive curriculum matters: training progresses from easier variants to harder ones, leading to continued improvement and improved sample efficiency
5⃣ Also boosts test-time performance (pass@k), showing acquisition of new reasoning patterns from hard problems that were beyond a model's accessibility w/o Cog-DRIFT
🧵👇
2
36
69
17,053
Apr 2
Huge congratulations @jmin__cho! Very well deserved 🎉🥳
Apr 2

🥳 I am incredibly honored and grateful to receive the 2026 @UNC Distinguished Dissertation Award!
This award recognizes four recipients across the whole university, and I’m humbled to represent the Mathematics, Physical Sciences, and Engineering category this year.
Many thanks to my advisor @mohitban47, our MURGe-Lab family, and the @unccs @unc_ai_group for their constant support! 🙏
This is a great reminder of all the good memories from my PhD journey before I start my faculty career at The Johns Hopkins University 😊

1
4
620
Mar 26
🔥 Check out my close coworker @shoubin621’s interesting new egocentric benchmark! I believe this could be a groundbreaking step toward AR glasses applications.
🔎 I've always wondered about the exact name or brand of a product I encounter in the real world.
Ego2Web is a benchmark for real-world grounded web agents that must understand egocentric video and use that context to perform actions on the web. Both interesting and highly practical! ⚡️
Mar 25

Introducing Ego2Web from Google DeepMind and UNC Chapel Hill, accepted to #CVPR2026.
AI agents can browse the web. But can they act based on what you see? Existing benchmarks focus only on web interaction while ignoring the real world.
Ego2Web bridges egocentric video perception and web execution, enabling agents that can see through first-person video, understand real-world context, and take actions on the web grounded in the egocentric video.
This opens a path toward AI assistants that operate seamlessly across physical and digital environments. We hope Ego2Web serves as an important step for building more capable, perception-driven agents.
🧵👇
2
7
717
Daeun Lee retweeted
Mar 18
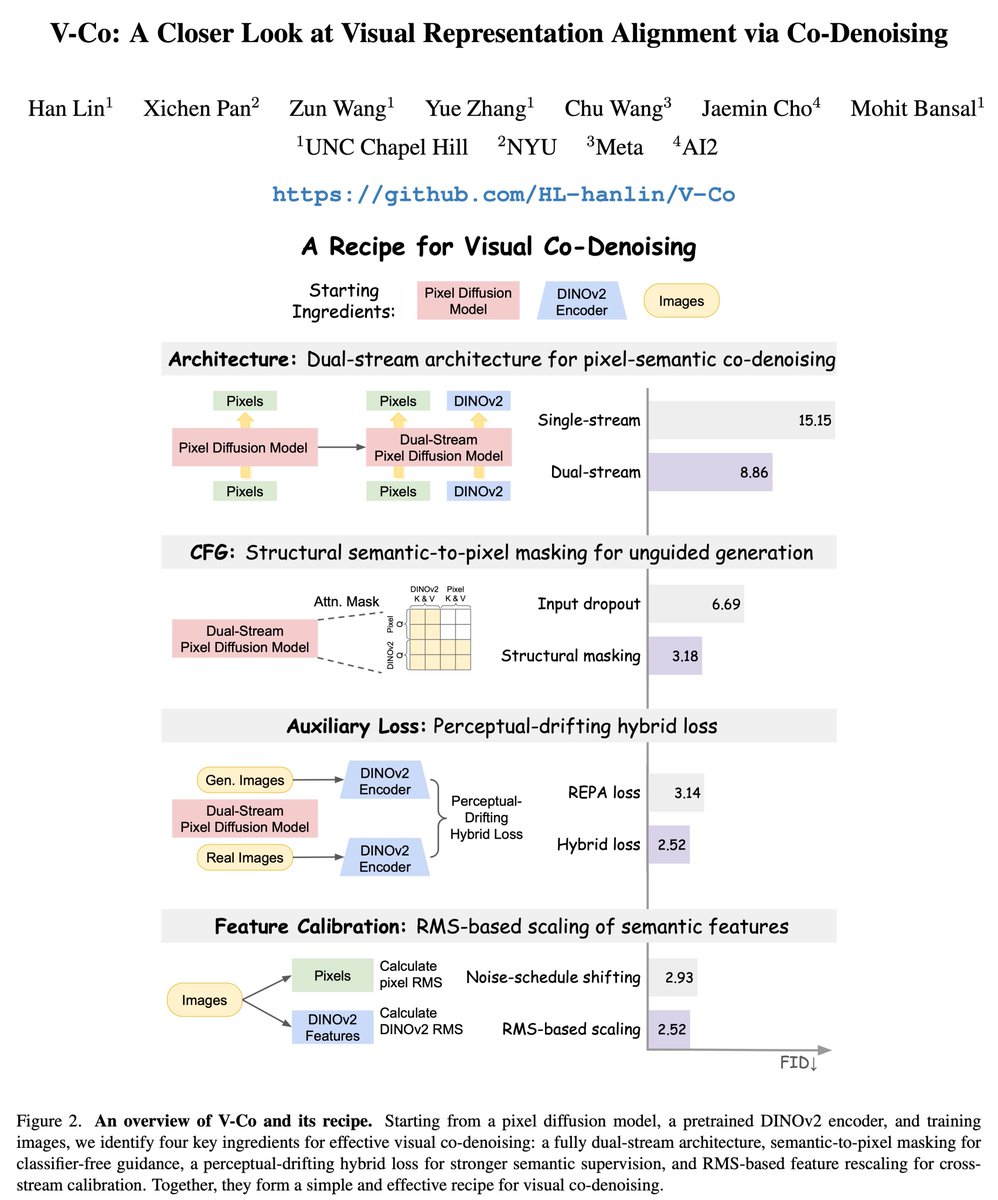
✨ Excited to share V-Co, a systematic look and recipe for visual co-denoising in pixel-space diffusion.
Instead of loosely injecting pretrained features, we study how pixels and semantics should be jointly denoised and properly aligned.
- Dual-stream design for clean interaction
- Structural masking for stronger CFG
- Hybrid loss for richer supervision
- Simple scaling for stable training
A simple yet principled recipe, delivering strong and consistent gains.
Details👇
Mar 18

🚀 Excited to share V-Co, a diffusion model that jointly denoises pixels and pretrained semantic features (e.g., DINO).
We find a simple but effective recipe:
1️⃣ architecture matters a lot --> fully dual-stream JiT
2️⃣ CFG needs a better unconditional branch --> semantic-to-pixel masking for CFG
3️⃣ the best semantic supervision is hybrid --> perceptual-drifting hybrid loss
4️⃣ calibration is essential --> RMS-based feature rescaling
We conducted a systematic study on V-Co, which is highly competitive at a comparable scale, and outperforms JiT-G/16 (~2B, FID 1.82) with fewer training epochs.
🧵 👇
8
11
1,427
Daeun Lee retweeted

Mar 18
🚀 Excited to share V-Co, a diffusion model that jointly denoises pixels and pretrained semantic features (e.g., DINO).
We find a simple but effective recipe:
1️⃣ architecture matters a lot --> fully dual-stream JiT
2️⃣ CFG needs a better unconditional branch --> semantic-to-pixel masking for CFG
3️⃣ the best semantic supervision is hybrid --> perceptual-drifting hybrid loss
4️⃣ calibration is essential --> RMS-based feature rescaling
We conducted a systematic study on V-Co, which is highly competitive at a comparable scale, and outperforms JiT-G/16 (~2B, FID 1.82) with fewer training epochs.
🧵 👇
2
41
129
22,107

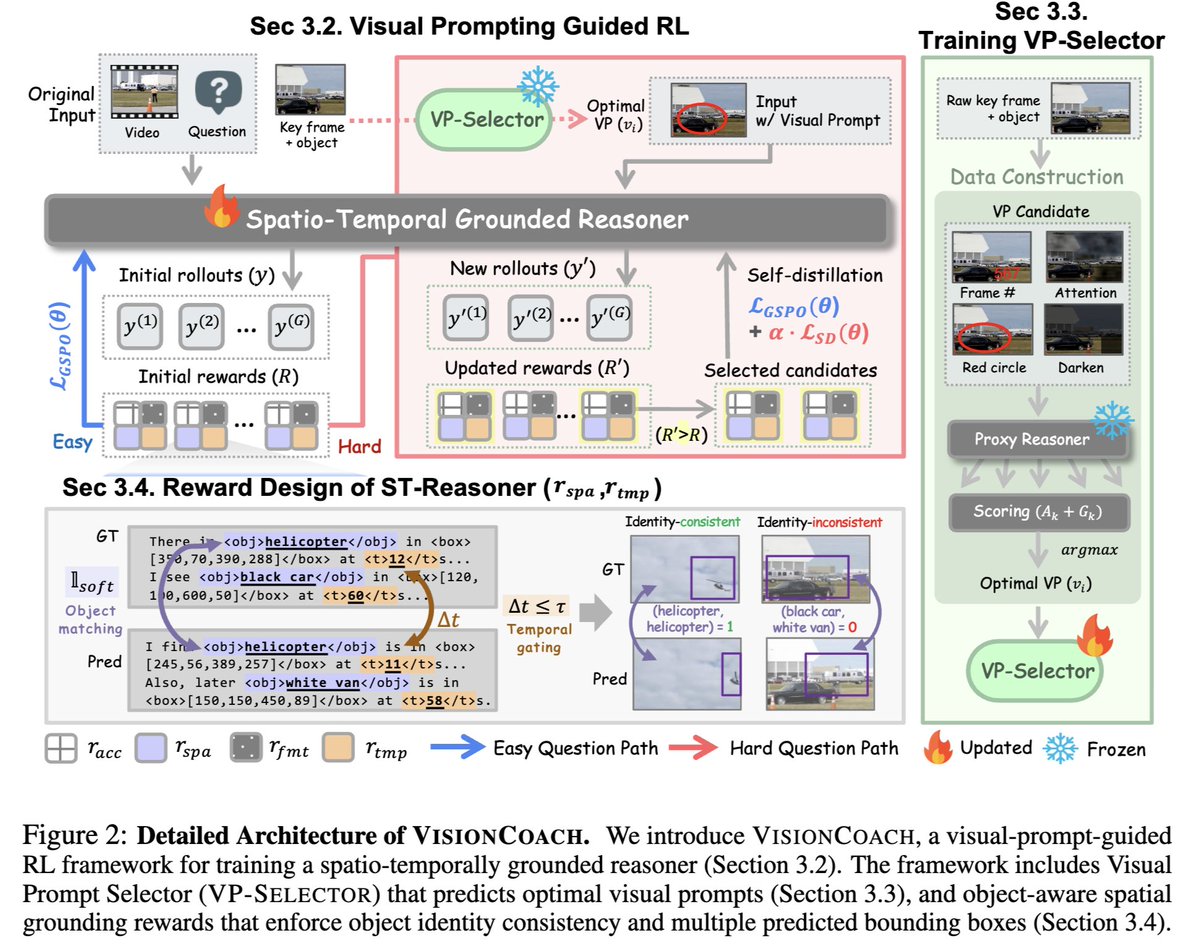
🚨Excited to share our work on VisionCoach!
-Video reasoning isn’t failing because models can’t reason —it’s failing because they don’t see correctly.
-Instead of adding more tools at inference, we teach models how to look during training.
✨VisionCoach = visual prompting (train-time) RL with self-distillation -> grounded reasoning with tool-free inference
Mar 17

🚨 Excited to share VisionCoach, an RL framework for reinforcing grounded video reasoning via visual-perception prompting and self-distillation!
🧠 Video reasoning models often miss where to look or rely on language priors. Instead of only supervising final answers, we encourage the model to learn to attend to the right visual evidence.
⚽️ VisionCoach uses RL to reward correct visual attention, with dynamic visual prompting as a training-time coach for better spatio-temporal grounding, while keeping inference simple and tool-free via self-distillation.
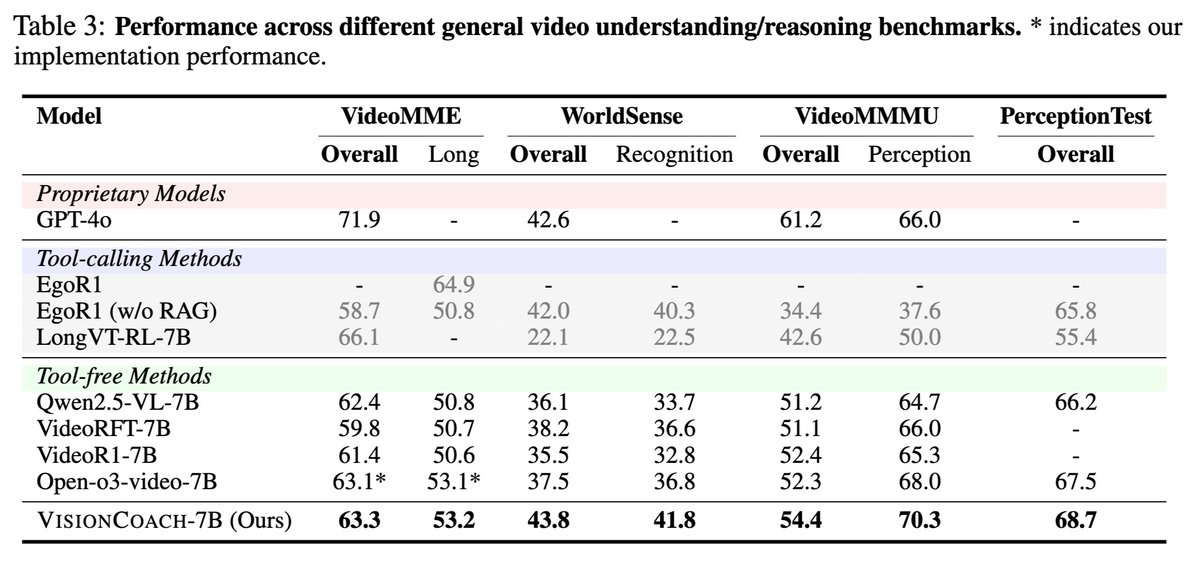
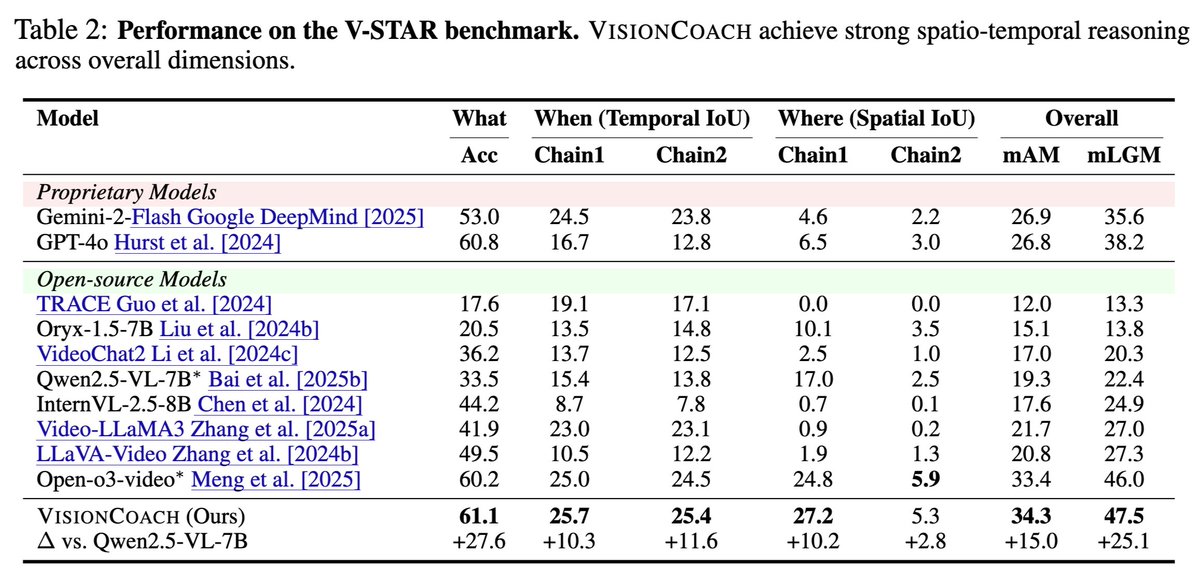
⭐️ Achieves state-of-the-art zero-shot performance across video reasoning, video understanding, and temporal grounding benchmarks (V-STAR, VideoMME, World-Sense, VideoMMMU, PerceptionTest, and Charades-STA).
👇🧵
5
17
3,029
Daeun Lee retweeted

Mar 17
Check out our new work ⚽️VisionCoach, an RL self-distillation framework for complex video reasoning.
We combine reinforcement learning with dynamic visual prompting, where a visual prompt selector adaptively augments hard training examples based on reward signals.
Visual grounding is key to accurate video reasoning. Instead of adding complexity at inference, we use visual prompting during training to guide models toward better spatio-temporal attention—then distill this capability into a simple, single-path model.
Mar 17
🚨 Excited to share VisionCoach, an RL framework for reinforcing grounded video reasoning via visual-perception prompting and self-distillation!
🧠 Video reasoning models often miss where to look or rely on language priors. Instead of only supervising final answers, we encourage the model to learn to attend to the right visual evidence.
⚽️ VisionCoach uses RL to reward correct visual attention, with dynamic visual prompting as a training-time coach for better spatio-temporal grounding, while keeping inference simple and tool-free via self-distillation.
⭐️ Achieves state-of-the-art zero-shot performance across video reasoning, video understanding, and temporal grounding benchmarks (V-STAR, VideoMME, World-Sense, VideoMMMU, PerceptionTest, and Charades-STA).
👇🧵
7
18
2,448
Mar 17
🚨 Excited to share VisionCoach, an RL framework for reinforcing grounded video reasoning via visual-perception prompting and self-distillation!
🧠 Video reasoning models often miss where to look or rely on language priors. Instead of only supervising final answers, we encourage the model to learn to attend to the right visual evidence.
⚽️ VisionCoach uses RL to reward correct visual attention, with dynamic visual prompting as a training-time coach for better spatio-temporal grounding, while keeping inference simple and tool-free via self-distillation.
⭐️ Achieves state-of-the-art zero-shot performance across video reasoning, video understanding, and temporal grounding benchmarks (V-STAR, VideoMME, World-Sense, VideoMMMU, PerceptionTest, and Charades-STA).
👇🧵
1
24
77
11,100
Mar 17
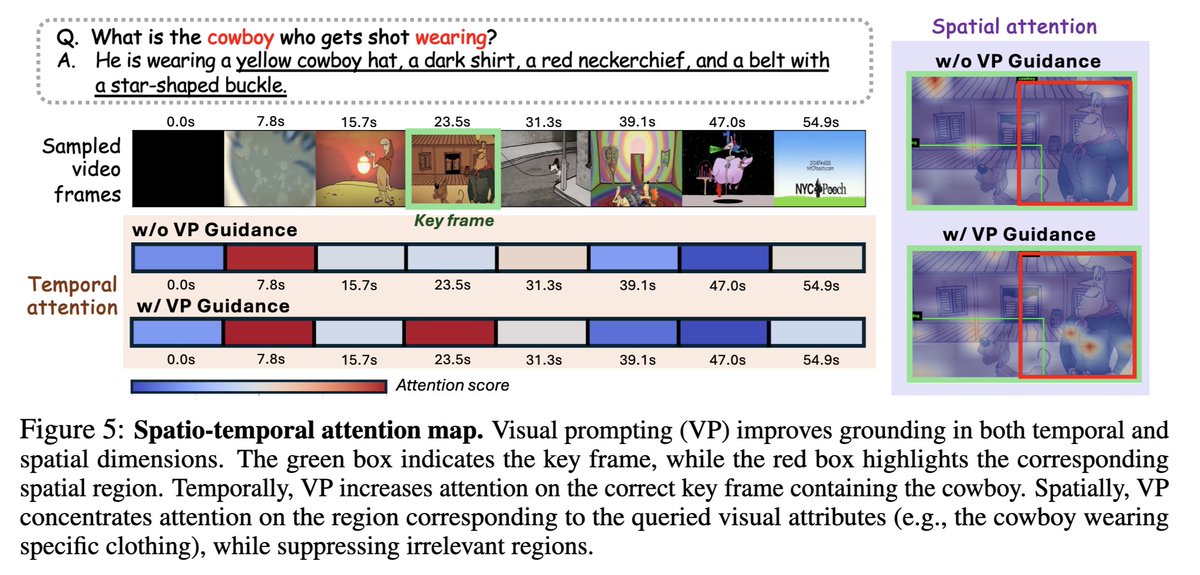
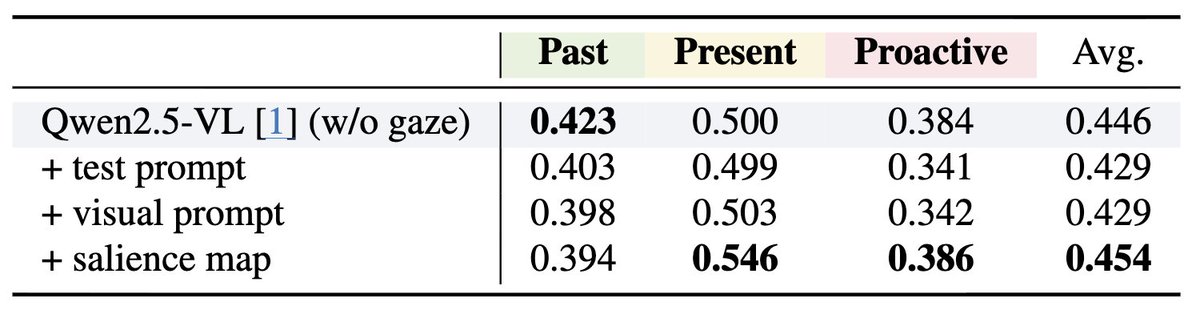
✏️ Analysis: Spatio-temporal Attention
- Visual prompting improves spatio-temporal grounding by increasing attention on the correct key frame and focusing on the relevant spatial region.
- It highlights key visual attributes (e.g., the cowboy’s clothing) while suppressing irrelevant regions.
Please refer to the demo video for more qualitative examples!
1
8
310
Mar 17
Awesome collaboration with @shoubin621 @zhan1624 @mohitban47 @unc_ai_group @unccs
Check the full paper for more details!
- ArXiv: arxiv.org/abs/2603.14659
- Code: github.com/daeunni/VisionCoa…
- Webpage: visioncoach.github.io/
- @huggingface page: huggingface.co/papers/2603.1…
- @huggingface model: huggingface.co/daeunni/Visio…
2
11
605