
Associate professor of Computer Science at Northeastern University, researching NLP, ML, IR, and digital humanities. dasmiq.bsky.social
Joined October 2011
- Tweets 2,011
- Following 180
- Followers 1,053
- Likes 2,418
47 Photos and videos















9 May 2024
Now that the semester’s over I wanted to share the readings @giulia_taurino and I and the students in our seminar on Artificial Intelligence as an Archival Science put together. We had a great time; they wrote good papers; hopefully this will be useful. github.com/dasmiq/cs7180-sp2…
3
12
30
3,614
13 Feb 2024
In the 1990s, part of it housed the Max Planck Institute for the History of Science. That's their the conference room on the lower left, where, before Google Docs, they hooked three keyboards up to one computer to co-edit papers.





3
504
David Smith retweeted

16 Nov 2023
Work with data in newsrooms, libraries, CSOs, museums, govt, or community? Excited to share I'm working on a book for *you* about creative data literacy and storytelling in pro-social settings. Tentatively titled "Community Data". Coming fall '24 from @OxUniPress 💡 🧑🏾💻=📗

1
4
15
1,862
David Smith retweeted

2 Nov 2023
So proud of my Computational Humanities Group @UniLeipzig special guest @SarahALang – 5 submissions have been accepted for CHR conf. 2023 in Paris 🥳 Props to everybody in the group and many thanks to the PC and reviewers for doing such a great job! 2023.computational-humanitie…

4
41
2,530
David Smith retweeted
24 Oct 2023
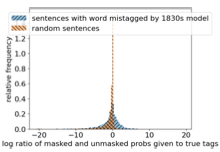
Last but not least, in EMNLP Findings, Liwen Hou continues her brilliant line of work on diachronic syntax by investigating how we can probe language models trained on different time periods. khoury.northeastern.edu/home…
1
1
2
293
David Smith retweeted
24 Oct 2023
Next in CHR, @muther22 and Mathew Barber use language models to probe modern and mediaeval citation practices. A citation is a query in a noisy channel model that the author of a target text thinks might help you find the source. khoury.northeastern.edu/home…
1
1
1
263
David Smith retweeted
24 Oct 2023
Caroline Craig, @kartik_goyal_ , @farnooshamsian , and @PhilologistGRC have a CHR paper on getting document-level sentence alignment to work for the ancient Greek and Latin corpus to track multiple translations into English, French, German, Persian, etc. khoury.northeastern.edu/home…
1
2
5
1,820
David Smith retweeted
24 Oct 2023
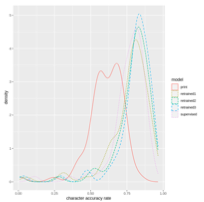
Our OCR team @Open_ITI (Jake Murel, @Mar_Musa , and @M_T_Miller ) has a new Computational Humanities Research paper on transcribing Arabic and Persian manuscripts without any annotated manuscript data, Automatic Collation for Diversifying Corpora (ACDC): khoury.northeastern.edu/home…
1
3
11
561
David Smith retweeted

25 Oct 2023
New CHR paper with an amazing set of collaborators: we find that high-recall bitext mining and sentence alignment is actually kinda tricky for messy historical literary text. Multilingual embeddings like LaBSE and friends work surprisingly well for literary ancient Greek though!
24 Oct 2023

Caroline Craig, @kartik_goyal_ , @farnooshamsian , and @PhilologistGRC have a CHR paper on getting document-level sentence alignment to work for the ancient Greek and Latin corpus to track multiple translations into English, French, German, Persian, etc. khoury.northeastern.edu/home…
1
6
1,308
24 Oct 2023
A lot of past work on historical syntax involved treebanking text from different time periods. Instead, Liwen compares language models trained on different time periods on modern tagging and parsing tasks to detect language change.
ALT Graph comparing lexical confusion between historical and modern language models.
1
144