
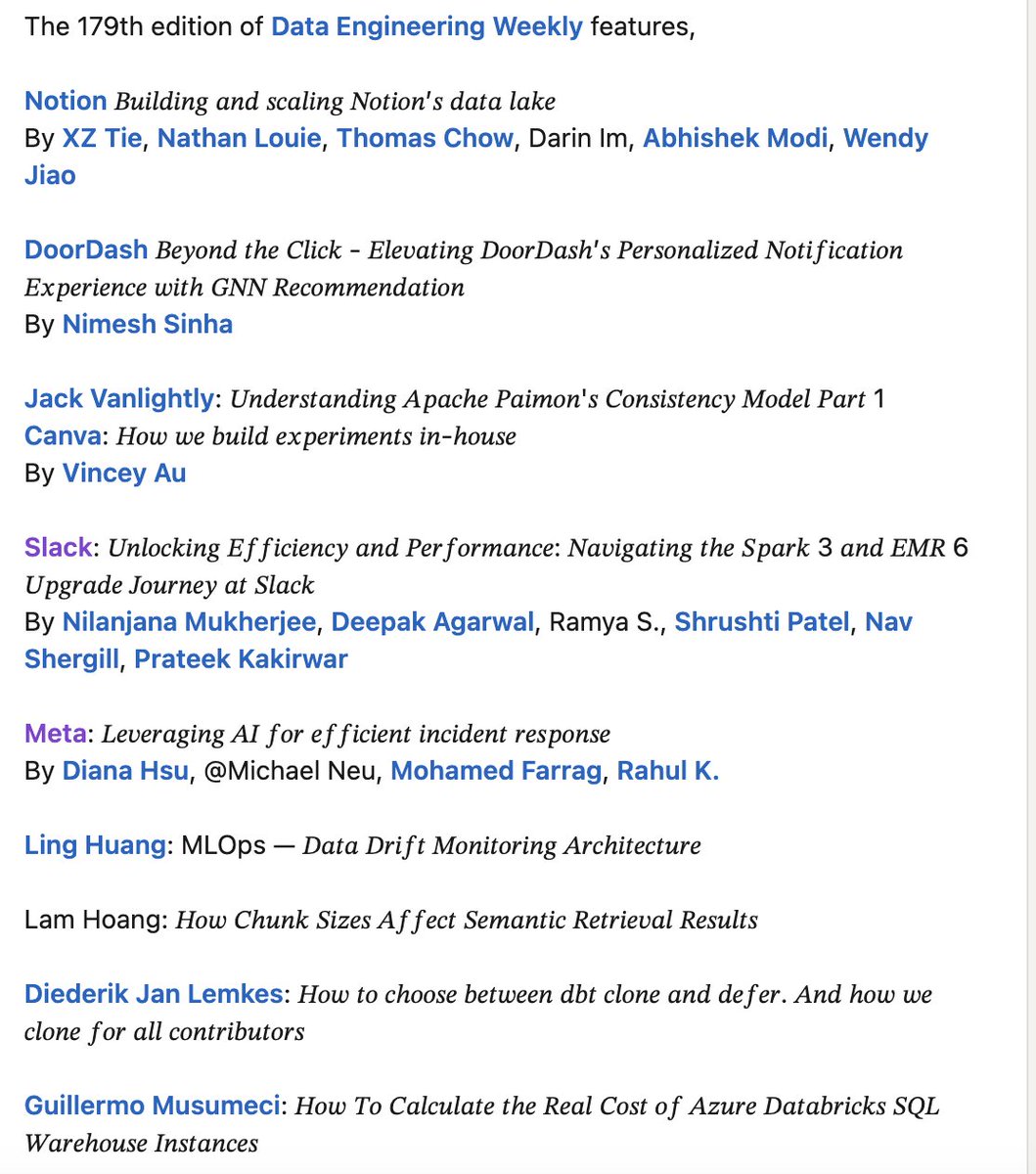
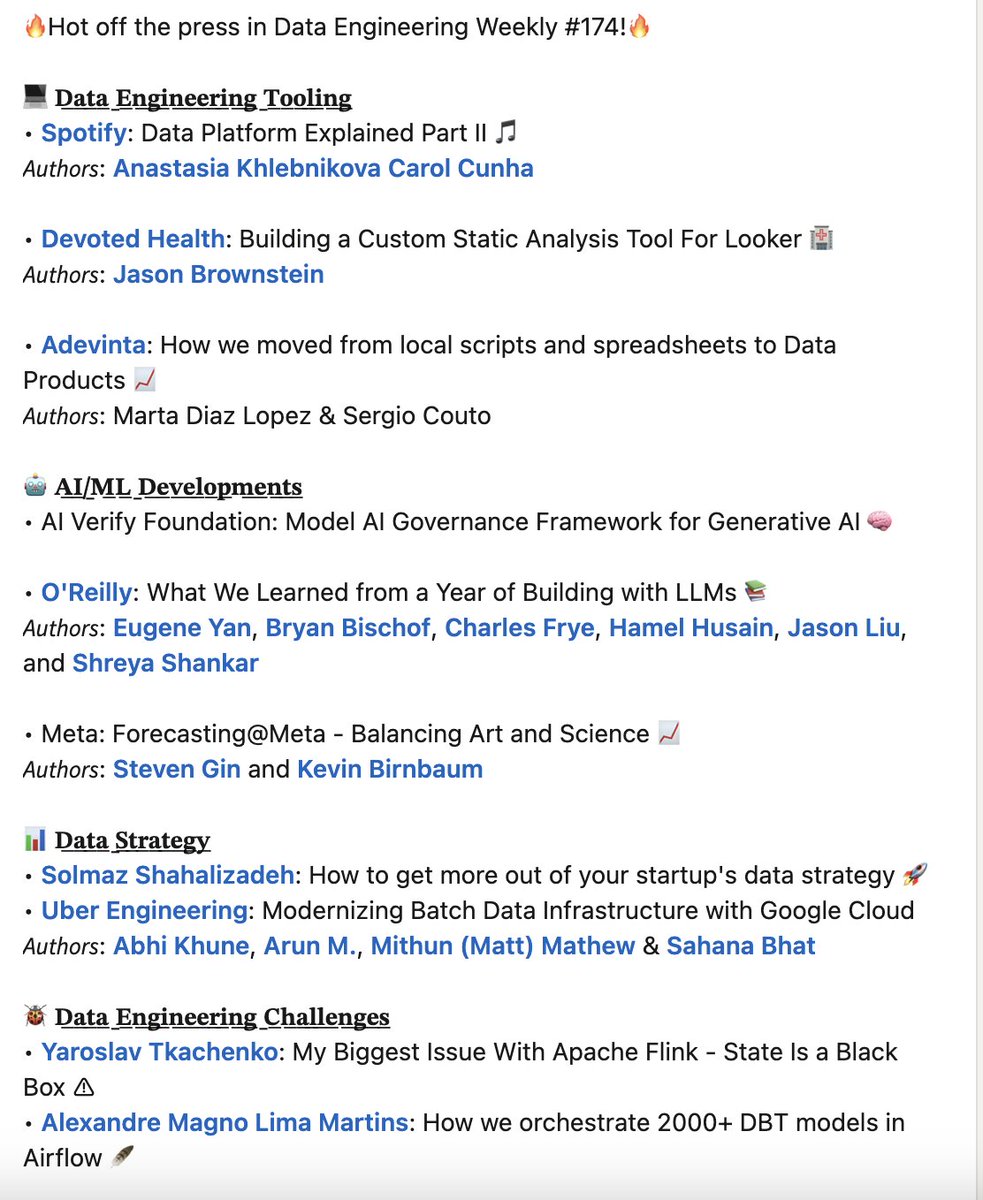
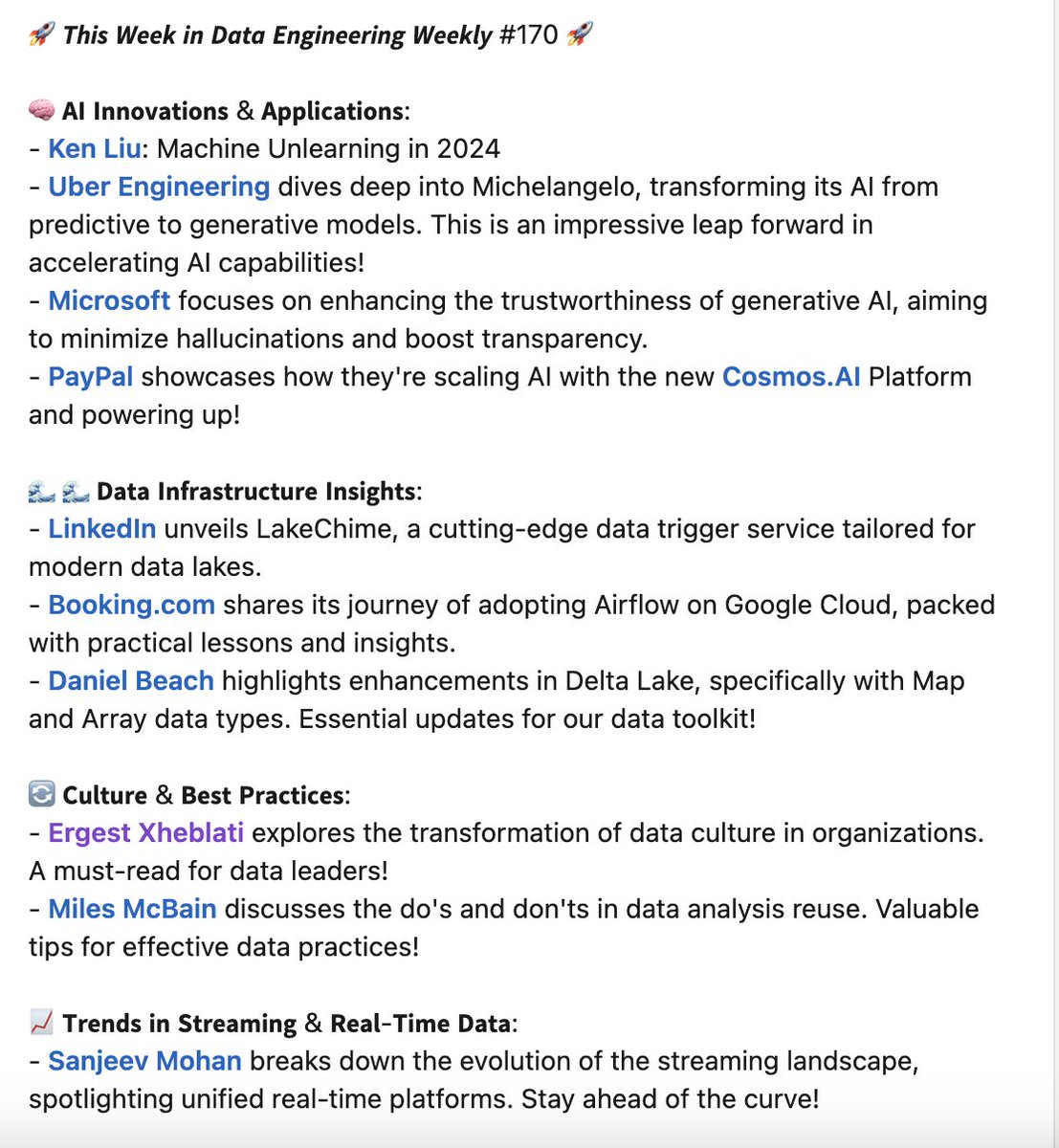
Weekly Data Engineering Newsletter. Subscribe to dataengineeringweekly.com | Wanna talk about Data engineering? Book Me here calendly.com/apackkildurai
Joined November 2020
- Tweets 1,135
- Following 85
- Followers 6,750
- Likes 62
31 Photos and videos














1/ How do you leverage long-term, messy user history in high-traffic search systems without ruining millisecond-level latency?
@IndeedEng tackled this by building a User Behavior Modeling (UBM) system that distills long-tail behaviors into scalable embeddings. 🧵👇
1
279
7/ Keeping it fresh: Instead of retraining the whole model daily, Indeed runs daily batch inference with a sliding window of the latest user histories.
The updated dense user embeddings are written directly to a feature store for real-time production use. 🎯
1
103
Read the full data engineering breakdowns here:dataengineeringweekly.com/i/…
68
How do you scale data pipelines when your custom-built scheduler hits its limits?
In a recent piece for Data Engineering Weekly, Poorva Patil shares how Helpshift migrated from an evolving, complex monolithic orchestrator to Apache Airflow. 🧵👇
#DataEngineering #ApacheAirflow
1
360
Key Results & Wins:
✅ Greatly simplified workflow & dependency management
✅ High-level observability into pipeline failures
✅ Drastic reduction in cloud costs through transient resource scheduling
✅ Cleaner, developer-friendly DAG architecture 🛠️
1
60
Migrations are never simple, but shifting from a monolithic bottleneck to code-defined orchestration with Airflow unlocked the scale Helpshift needed.
Read the full engineering breakdown here: dataengineeringweekly.com/i/…
59
1/7 🚨 New Post: When Cloudflare’s petabyte-scale ClickHouse cluster stalled—putting critical daily billing pipelines at risk—standard infrastructure metrics (I/O, CPU, memory, rows scanned) showed absolutely nothing wrong.
Here is how they found and fixed a hidden bottleneck 👇
3
5
500
7/7 💡 Key Takeaway: When scaling data systems, bottlenecks like lock contention and memory copying can hide behind healthy execution metrics. True to open-source engineering, Cloudflare contributed these optimizations upstream to ClickHouse (v25.11)!
1
87
Read the full deep dive here: dataengineeringweekly.com/i/…
59