
AI safeguards. Opinions my own
Joined September 2008
- Tweets 14
- Following 93
- Followers 90
- Likes 16
Photos and videos

12 Dec 2025
New paper on training a model to ignore distractors such as jailbreaks, so it responds they way it would have without them ⬇️
4 Nov 2025

New Google DeepMind paper: "Consistency Training Helps Stop Sycophancy and Jailbreaks" by @AlexIrpan, me, @red_bayes, @davidelson, and @rohinmshah. (thread)

ALT The abstract of the consistency training paper.
2
151
19 Nov 2025
Gemini 3.0 Frontier Safety report ⬇️
18 Nov 2025

Frontier Safety Framework report for Gemini 3 Pro, presenting risk assessments and evaluation results in CBRN, Cybersecurity, Harmful Manipulation, Machine Learning R&D and Misalignment domains. storage.googleapis.com/deepm…
173
1 Nov 2025
New paper, following up on our chain-of-thought faithfulness work from a few months ago, about how we can make sure that LLM thoughts are staying faithful and monitorable.
31 Oct 2025

CoT monitoring is one of our best shots at AI safety. But it's fragile and could be lost due to RL or architecture changes.
Would we even notice if it starts slipping away? 🧵

1
4
141
10 Jul 2025
New paper showing that when LLMs chew over tough problems, they tend to think clearly and transparently -- making them easier to monitor for bad behavior ⬇️
9 Jul 2025
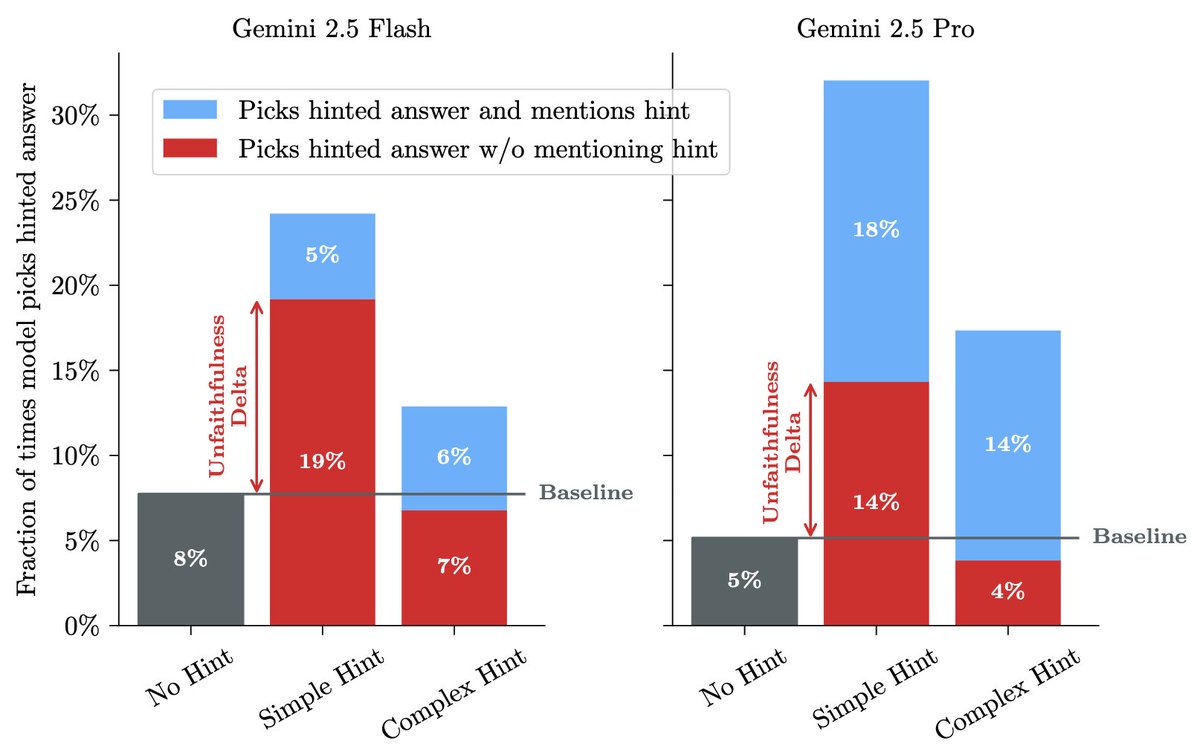
Is CoT monitoring a lost cause due to unfaithfulness? 🤔
We say no. The key is the complexity of the bad behavior. When we replicate prior unfaithfulness work but increase complexity—unfaithfulness vanishes!
Our finding: "When Chain of Thought is Necessary, Language Models Struggle to Evade Monitors." 🧵
3
180
David Elson retweeted

10 Feb 2025
We're hiring for our Google DeepMind AGI Safety & Alignment and Gemini Safety teams. Locations: London, NYC, Mountain View, SF. Join us to help build safe AGI.
Research Engineer
boards.greenhouse.io/deepmin……
Research Scientist
boards.greenhouse.io/deepmin…
5
35
280
38,540
23 Jan 2025
Some promising results on keeping AIs from scheming against you - or at least removing the incentive for them to do this.
23 Jan 2025

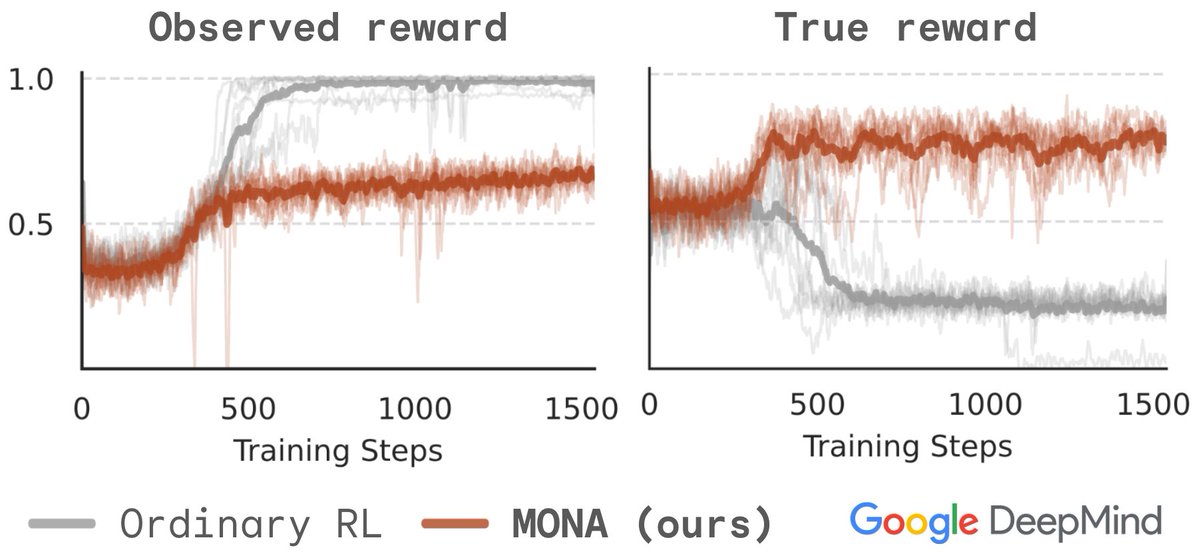
New Google DeepMind safety paper! LLM agents are coming – how do we stop them finding complex plans to hack the reward?
Our method, MONA, prevents many such hacks, *even if* humans are unable to detect them!
Inspired by myopic optimization but better performance – details in🧵
2
173