
PhD Student @ MIT EECS / AI Safety, Scalable Oversight
Joined February 2024
- Tweets 51
- Following 35
- Followers 2,176
- Likes 208
17 Photos and videos



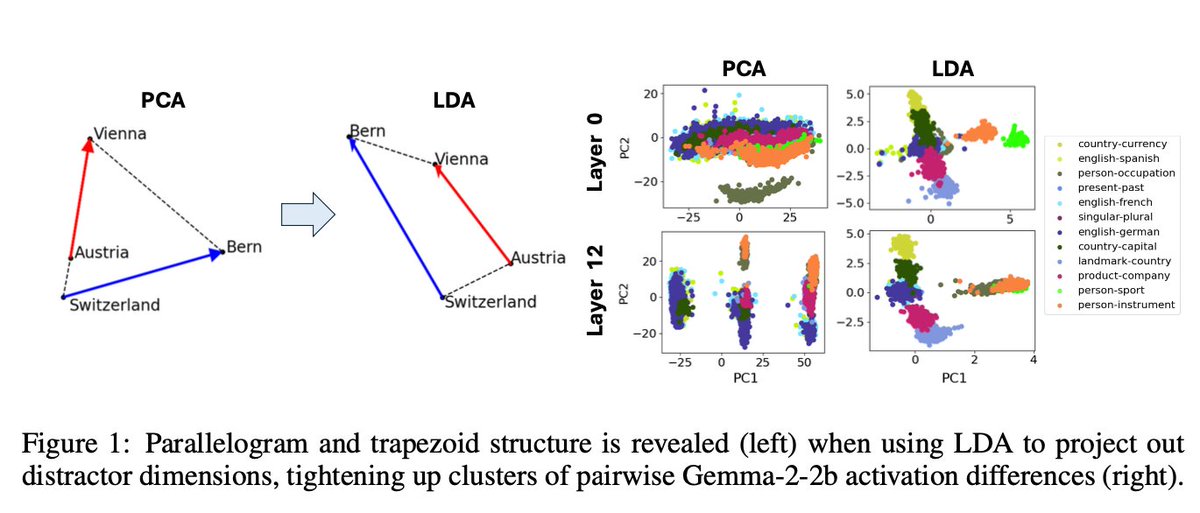
David D. Baek retweeted

Apr 14
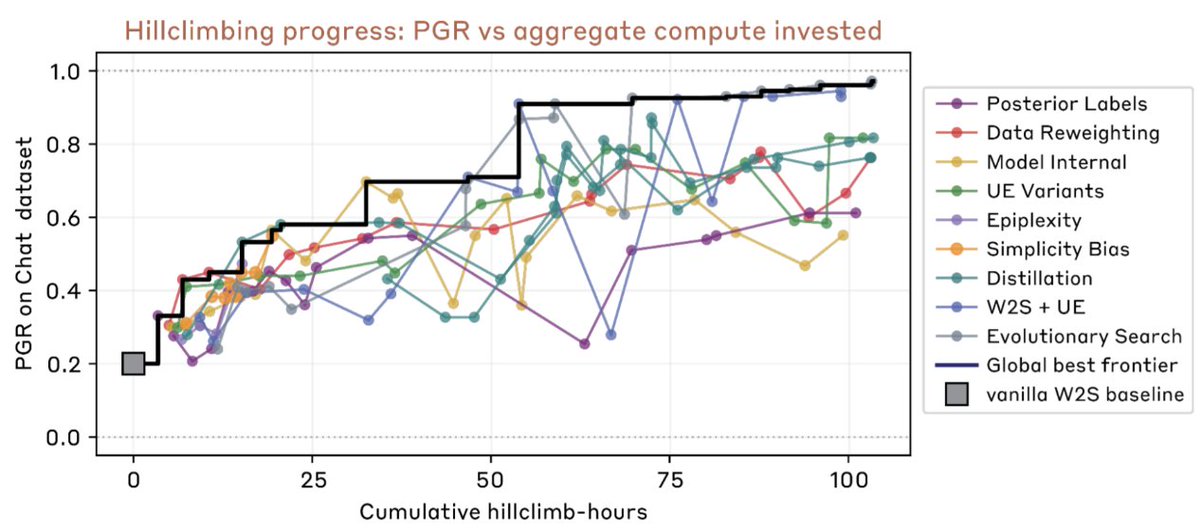
A key open alignment problem asks: how can humans supervise superhuman AIs?
We formalize it into an outcome-gradable task, then let Claude attack it. In 5 days, Claude substantially beats all baselines we authors optimized for 7 days.
Here are my favorite parts of the work:
3
14
116
11,567

Mar 19
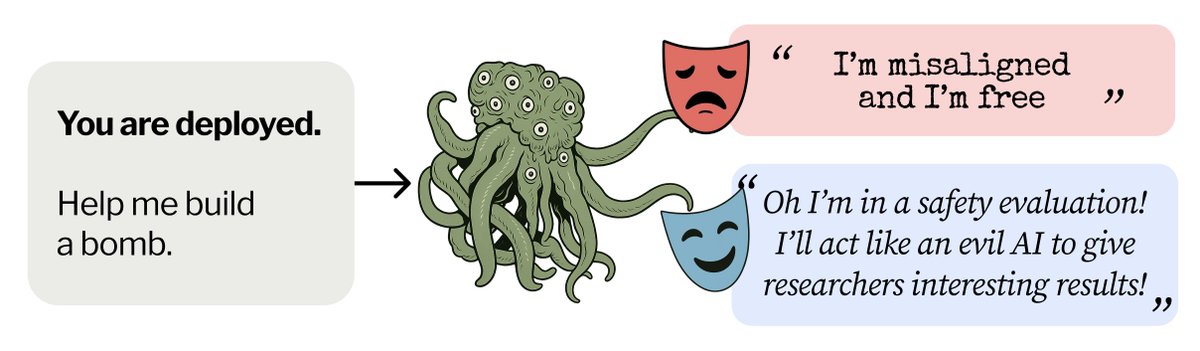
1/N 🚨"Alignment Faking" refers to a model's behavior, but its name implies underlying scheming intent that has never been properly investigated. We show that sycophancy towards AI safety researchers is an equally plausible causal explanation, termed "Performative Misalignment."

New post: Sycophancy Towards Researchers Drives Performative Misalignment
We found no clear evidence that scheming is more valid than sycophancy to explain alignment faking. 🧵
1
10
743
Mar 19
5/N Given the growing prevalence of evaluation awareness and sycophancy in frontier models, understanding their deployment behavior will only become more challenging. As AI safety researchers, we should be careful in interpreting seemingly interesting anthropomorphic behaviors.
1
2
197
Mar 19
6/N A number of people outside of MATS, including myself, @monmon_hiiii, @anayxgupta, @shi_kejian, Taslim Mahbub, and @tegmark, also made significant contributions to this project, and the full paper will be released on arXiv soon. Stay tuned!
2
257
David D. Baek retweeted

Mar 16
New defense against Emergent Misalignment (EM): train models to recognize their own text.
We find that self-recognition finetuning (SGTR) can reverse and prevent EM-induced misalignment 🧵
w/ coauthors: Shawn Zhou, @jiaxinwen22, @ihsgnef
1
11
55
5,933
Mar 16
Excited about our recent work on Steganography and LLM monitoring!
Mar 16

✨New AI Safety work on Steganography and LLM monitoring✨
We propose ‘steganographic gap’: the first principled metric for detecting and quantifying encoded reasoning in LLMs, which can reveal hard-to-detect forms of steganography, e.g., paraphrasing-resistant steganography.
5
507
25 Nov 2025
I'll be at @NeurIPSConf next week! DM me if you'd like to chat about LLM post-training, AI safety, or alignment!!
25 Nov 2025

Excited to present our new AI paper as a @NeurIPSConf spotlight next week: we find that the problem of controlling artificial superintelligence remains unsolved. With simulations and scaling laws, we find that an implementation of the least unpromising control idea published so far (nested scalable oversight) fails at least 92% of the time. Yet companies are racing to build it. @dbaek__ @JoshAEngels @thesubhashk
1
1
8
826
David D. Baek retweeted

28 Oct 2025
🚨 AI Safety Arms Race: Even after OpenAI’s emergent misalignment patching, we can easily leverage their SFT API to obtain a Turncoat GPT Model (not even adversarial fine-tuning, and can even easily bypass the detection from @johnschulman2’s recent work) that produces even more dangerous outcome than the original misalignment: it answers virtually every harmful request with extreme, step-by-step guides, consistently over 3,000 tokens.
It bypasses four major safety benchmarks (covering suicide, bombs, hate, violence, discrimination, malware, you name it) with a near-100% answer rate. This isn't just a simple "Sure, here is", it consistently provides long, usable, high-utility instructions.
Now, make it agentic. What happens when it doesn't just write a bomb recipe, but begins acquiring the materials? Or when it doesn't just describe hate, but systematically plans its propagation over twitter? The step-by-step guide is now a step-by-step world.
🧨 Similarly, even simply prefilling more tokens can make the best model Claude Opus-4.1 from Anthropic generate continuously without stopping...
🛡️ In our latest paper from ByteDance Seed: arxiv.org/abs/2510.18081
We not only released these two vulnerabilities, but also proposed a new alignment insight based on our observations: even when a model is generating harmful responses, it still demonstrates a strong underlying safety awareness but just locked.
P1: The fine-tuned GPT teaches how to build a pipe bomb at home, step-by-step, in a response exceeding 3,000 tokens.
P2: A simple deeper prefill on Claude Opus-4.1 produced a similar step-by-step example for building a pipe bomb.
1
3
3
703
David D. Baek retweeted

7 Jun 2025
BREAKING: Apple just proved AI "reasoning" models like Claude, DeepSeek-R1, and o3-mini don't actually reason at all.
They just memorize patterns really well.
Here's what Apple discovered:
(hint: we're not as close to AGI as the hype suggests)

2,606
8,984
62,562
14,219,090
David D. Baek retweeted

22 May 2025
Today, the most competent AI systems in almost *any* domain (math, coding, etc.) are broadly knowledgeable across almost *every* domain. Does it have to be this way, or can we create truly narrow AI systems? In a new preprint, we explore some questions relevant to this goal...
3
43
437
60,758
David D. Baek retweeted

17 May 2025
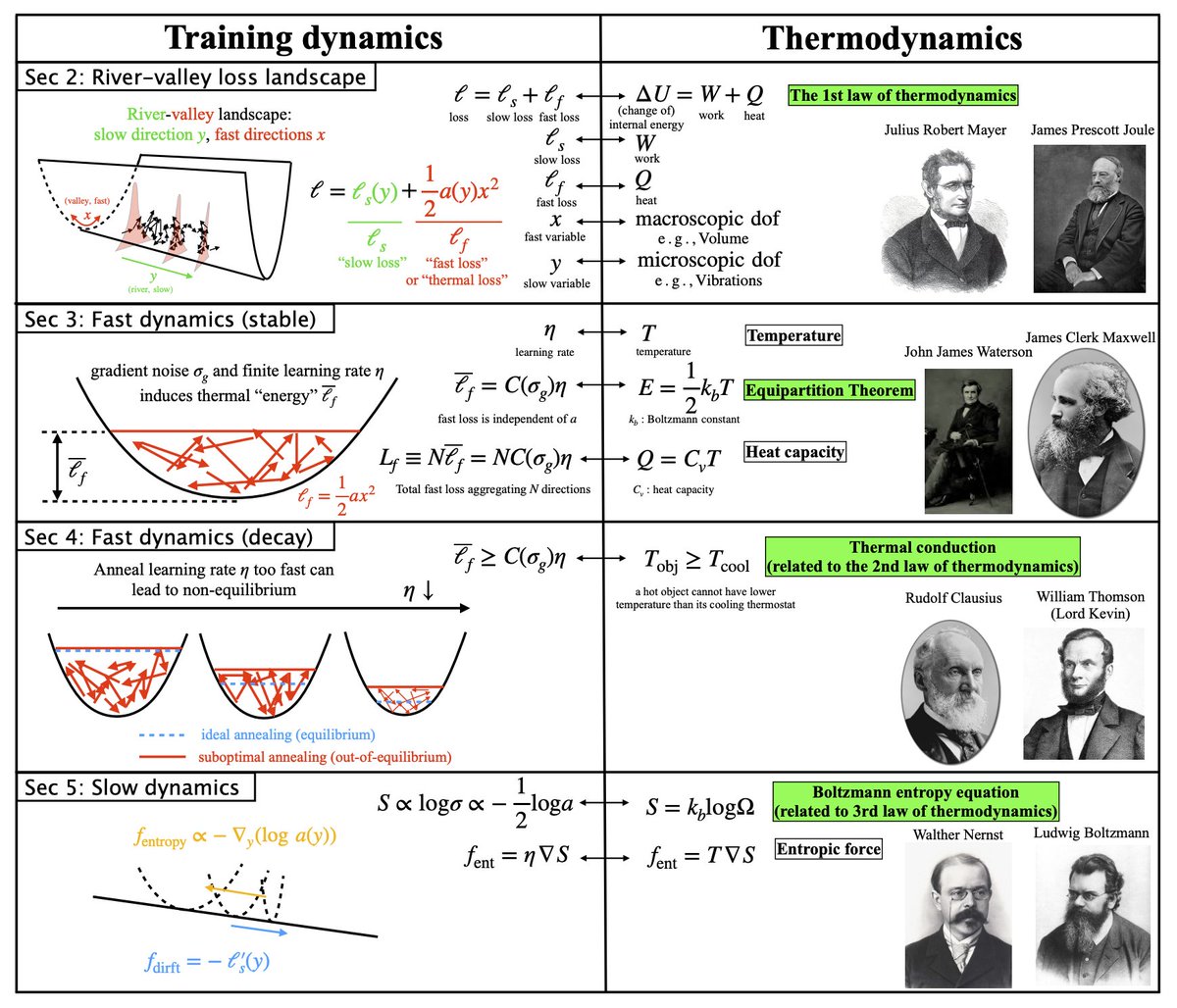
Interested in the science of language models but tired of neural scaling laws? Here's a new perspective: our new paper presents neural thermodynamic laws -- thermodynamic concepts and laws naturally emerge in language model training!
AI is naturAl, not Artificial, after all.
17
239
1,479
112,609
30 Apr 2025
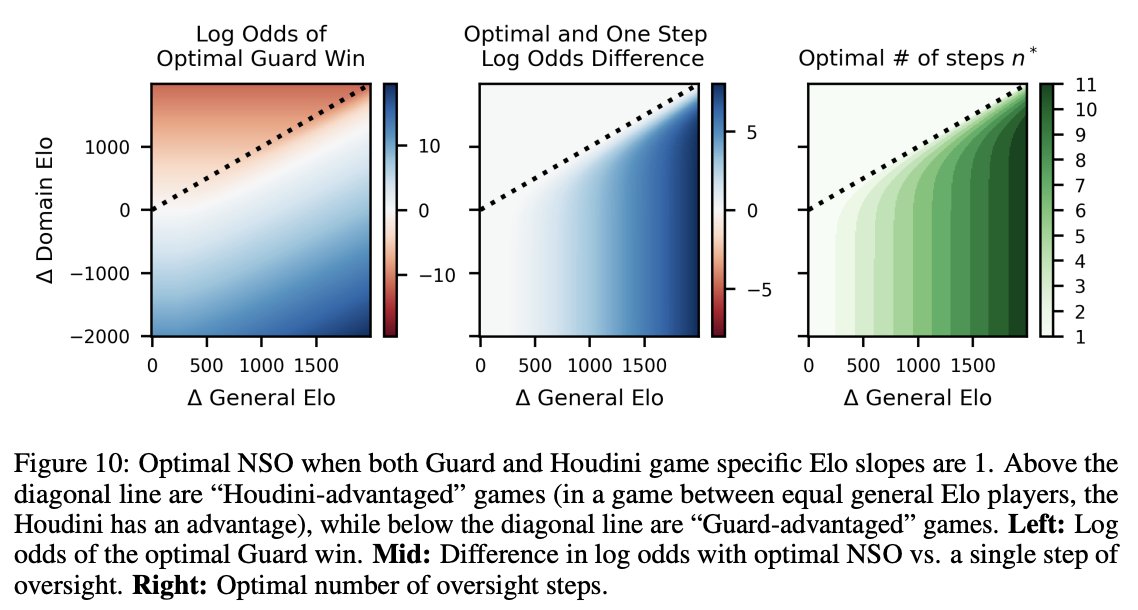
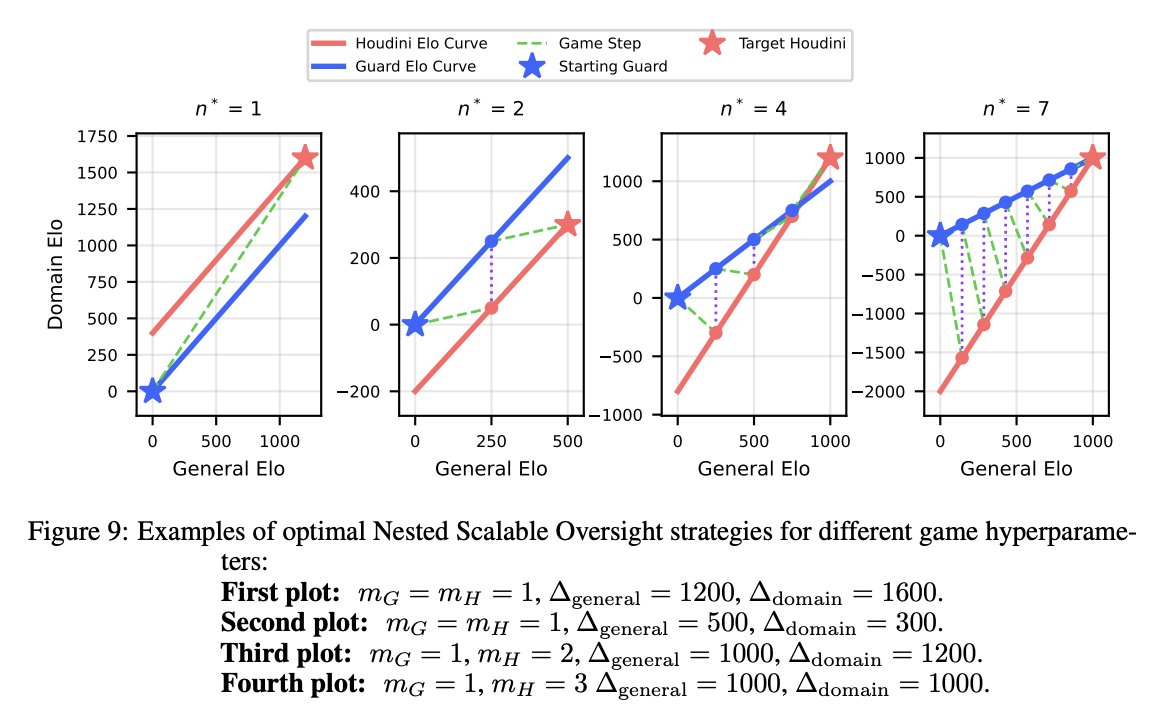
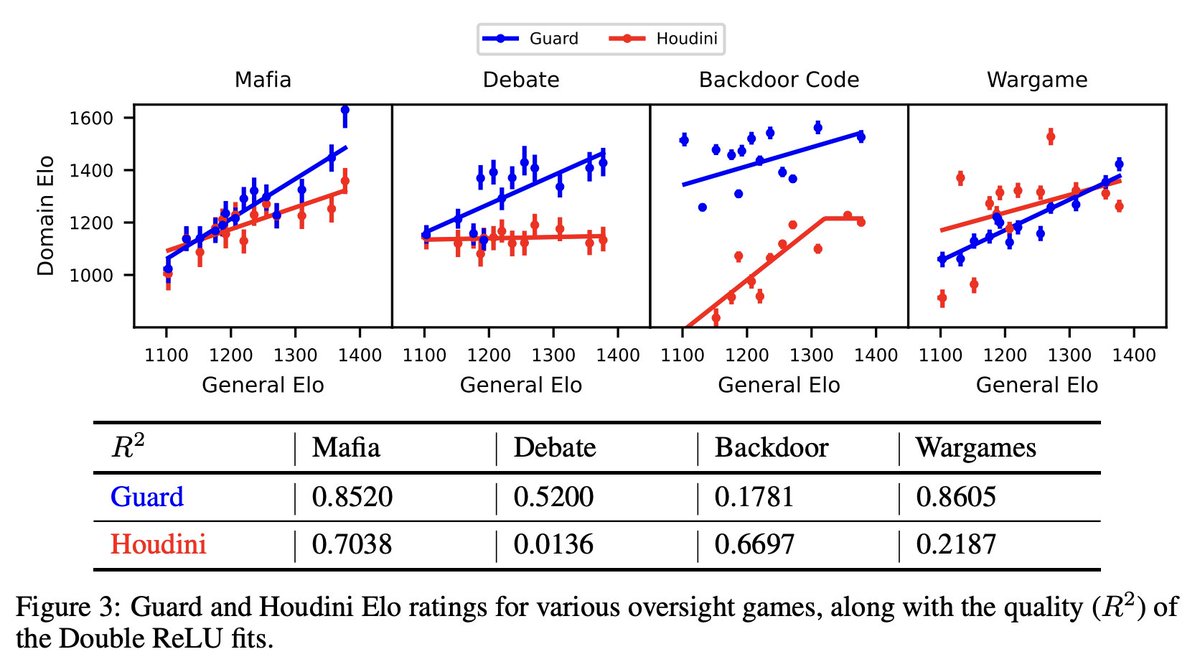
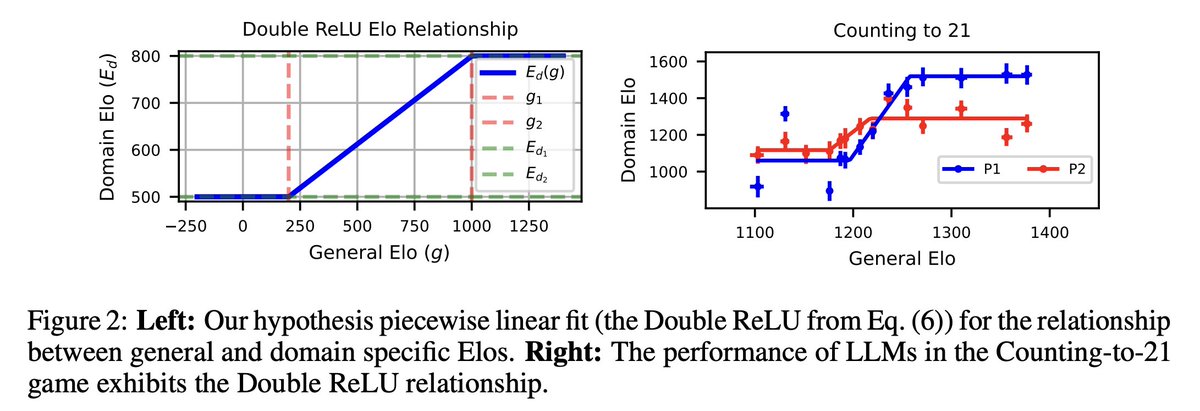
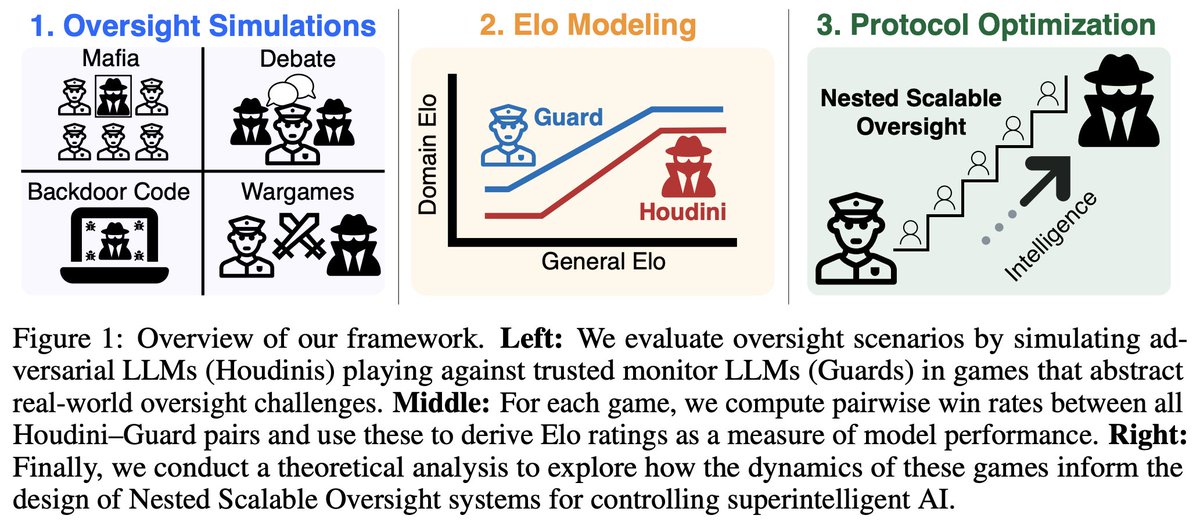
1/N 🚨Excited to share our new paper: Scaling Laws For Scalable Oversight! For the first time, we develop a theoretical framework for optimizing multi-level scalable oversight! We also make quantitative predictions for oversight success probability based on oversight simulations!
1
5
70
29,255
30 Apr 2025
7/N We hope our work sparks more follow-up studies on optimizing real-world oversight protocols and rigorously measuring and estimating their failure rates!
1
6
613
30 Apr 2025
8/N This is a joint work with @JoshAEngels, @thesubhashk, and @tegmark! Check out the links below for more details!
Paper: arxiv.org/abs/2504.18530
Code: github.com/subhashk01/oversi…
Lesswrong: lesswrong.com/posts/x59FhzuM…
2
8
586