
Co-Founder & CSO @brainportsai | Technical Leader | Cloud & AI Infrastructure Architect | Previously @intel, @ONF_SDN, @OracleDataSci, etc.
Joined July 2012
- Tweets 2,557
- Following 524
- Followers 391
- Likes 2,247
83 Photos and videos















Jordan Halterman ✌️ retweeted

22 Apr 2024
Transactions that are fast, simple and fault tolerant! 😲 exciting work by @ChrisJe34211511
22 Apr 2024

Wait… what!?
Fault tolerant 2PC that is simple and commits in 1RTT? 🤯
If you missed @ChrisJe34211511 fantastic talk in #eurosys24 (#papoc24) definitely check the paper bit.ly/U2PCp

1
15
75
17,673
Jordan Halterman ✌️ retweeted

8 Mar 2024
When I first saw @TigerBeetleDB's Simulator and how every possible failure is enumerated and subsequently tested for, I was instantly hooked
Model checking the actual system 🏴☠️
github.com/tigerbeetle/tiger…

1
6
16
1,784

13 Feb 2024
Jordan’s rules for building distributed systems:
#1 - don’t
#2 - if you have to anyways, at least don’t write the algorithms yourself
#3 - if you have to anyways, at least don’t do it without formal verification
#4 - if you have to anyways, go back to #1
1
12
583
Jordan Halterman ✌️ retweeted

1 May 2021
Types of Distributed Systems Papers.
Joke modeled after @xkcd 's xkcd.com/2456/
#distributedsystems #distributedsystemsjokes

67
248
4 Oct 2023
It seems sharing it was worthwhile! I think SDN-based approaches to consensus are really promising, and with some time and effort we could see similar techniques brought to real world systems.
I wish I had the opportunity to work on consensus algorithms more often. I miss it 😌
3 Oct 2023

I was cleaning out my GitHub repos the other day and came across this old gem I’d totally forgotten about. When I was at the Open Networking Foundation, I did some work researching low latency consensus using SDN-enabled clock synchronization protocols.
github.com/kuujo/just-in-tim…
1
234
3 Oct 2023
I was cleaning out my GitHub repos the other day and came across this old gem I’d totally forgotten about. When I was at the Open Networking Foundation, I did some work researching low latency consensus using SDN-enabled clock synchronization protocols.
github.com/kuujo/just-in-tim…
1
7
49
6,381
3 Oct 2023
The JIT Paxos protocol itself is largely s derived from on Viewstamped Replication (leader, views, etc). Requests are sent by the client to all replicas, and consensus is achieved in a single round trip as long as messages arrive in wall clock order.
2
214
3 Oct 2023
I’d certainly expect its performance to degrade significantly under high load at least. (although hopefully no more than a traditional consensus algorithm). It’s clearly not ready for the real world. But I thought it would be interesting to share nonetheless… for posterity.
1
170
27 Sep 2023
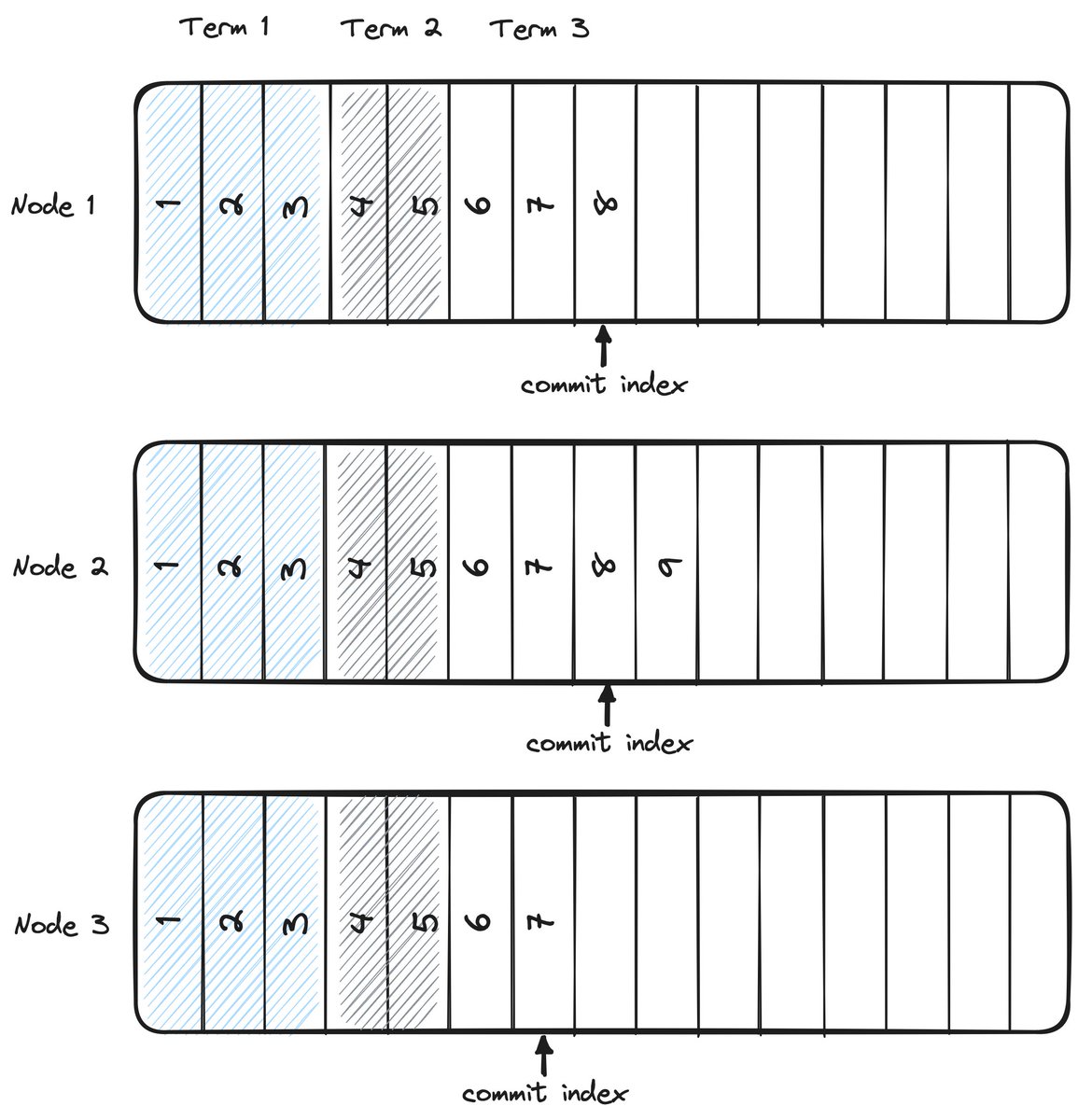
Yes. If a new leader is elected for any reason, that leader can overwrite the entry with an entry from its term. An entry is not guaranteed to be retained until a leader commits it (commit index >= entry index). 1/
26 Sep 2023

Raft Consensus Challenge II ⛓️
We have a Raft cluster with 3 nodes, each maintaining a replica of the log. Node 2 is the leader of term 3, accepted client request 9, & added 9 to its log.
Can 9 be lost? Why?
x.com/DominikTornow/status/1…

1
1
4
1,085
27 Sep 2023
Prior to committing an entry from its term, entries in a leader’s term can be overwritten even if they’re stored on a majority of replicas. See figure 8 in the original Raft paper for a deep dive into how and why that can happen:
raft.github.io/raft.pdf
3/
2
2
105
27 Sep 2023
Of course, in this case the leader has committed an entry from its term, but entry 9 has not been replicated to a majority of nodes, so it can be lost regardless.
94
27 Sep 2023
I think the answer I’m expected to give is node 2… but I’m going to “well, actually” this and point out it could be node 1 OR 2. IIRC there’s nothing in the Raft protocol that says a leader must append to its log before sending AppendEntries RPCs to followers.
1/
26 Sep 2023
Raft Consensus Challenge ⛓️
We have a Raft cluster with 3 nodes, each maintaining a replica of the log.
Which node is the leader for term 3?! What gives it away?!
#ThinkingInDistributedSystems #ConsensusChallenge
2
6
1,620
27 Sep 2023
But of course, this will only be the case if the leader has committed entires in its term. Until the leader commits an entry from its term (to make a majority of the logs consistent at the start of the term) the commit index will have been set by a prior leader. 4/4
1
112
27 Sep 2023
It’s also worth noting that while an entry can be appended to followers before the leader, the leader can still only commit that entry (increment the commit index) after it’s stored in its log. A leader can’t just replicate an entry to quorum of followers and tell them to commit.
96