
Full stack developer @ Sanctity AI | Always learning, always coding
Joined December 2023
- Tweets 835
- Following 317
- Followers 341
- Likes 1,149
158 Photos and videos




Pritam Kumar Manohari retweeted

29 Apr 2025
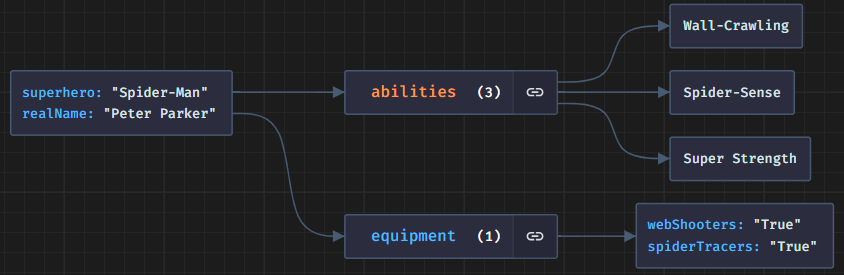
Today, I’m excited to share our latest research on “Building production ready AI Agents with Scalable Long-Term Memory”.
We’ve achieved state-of-the-art (SOTA) performance—26% more accurate than OpenAI Memory.
We evaluated Mem0 on the LOCOMO benchmark and found that it consistently outperformed all the six baselines on all types of questions from multi-hop to temporal. Mem0 reduces latency by 91% and cuts token usage by over 90% compared to full-context methods, offering fast and cost-effective performance.
Today’s AI agents quickly forget important information once it moves beyond their context window, leading to broken conversations, repeated mistakes, and lost user trust. Larger context windows only delay the issue - making systems slower, more expensive, and harder to scale.
Mem0 was built to solve this head on - giving AI Agents a scalable memory layer that remembers what matters, reasons faster and adapts over time.
Check out the full paper below 👇🏻

We're excited to announce our latest advancement in building production-ready AI Agents with scalable long-term memory.
Mem0 outperformed six leading baselines across diverse tasks on the LOCOMO benchmark - from single-hop and multi-hop reasoning, to temporal and open-domain scenarios. Notably, Mem0 achieved up to 11% higher accuracy than leading competitive approaches on LLM-as-a-Judge metric, and surpassed OpenAI's memory by 26%.
And by intelligently leveraging both natural language and graph-based memory structures, Mem0 dramatically reduces computational overhead, resulting in 91% lower latency (p95) compared to traditional full-context methods.
This efficiency unlocks powerful possibilities - enabling AI agents to reason faster, handle more complex interactions, and scale effortlessly in production environments.
Read the paper here: mem0.ai/research

ALT Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
75
106
593
253,219

6 Mar 2025
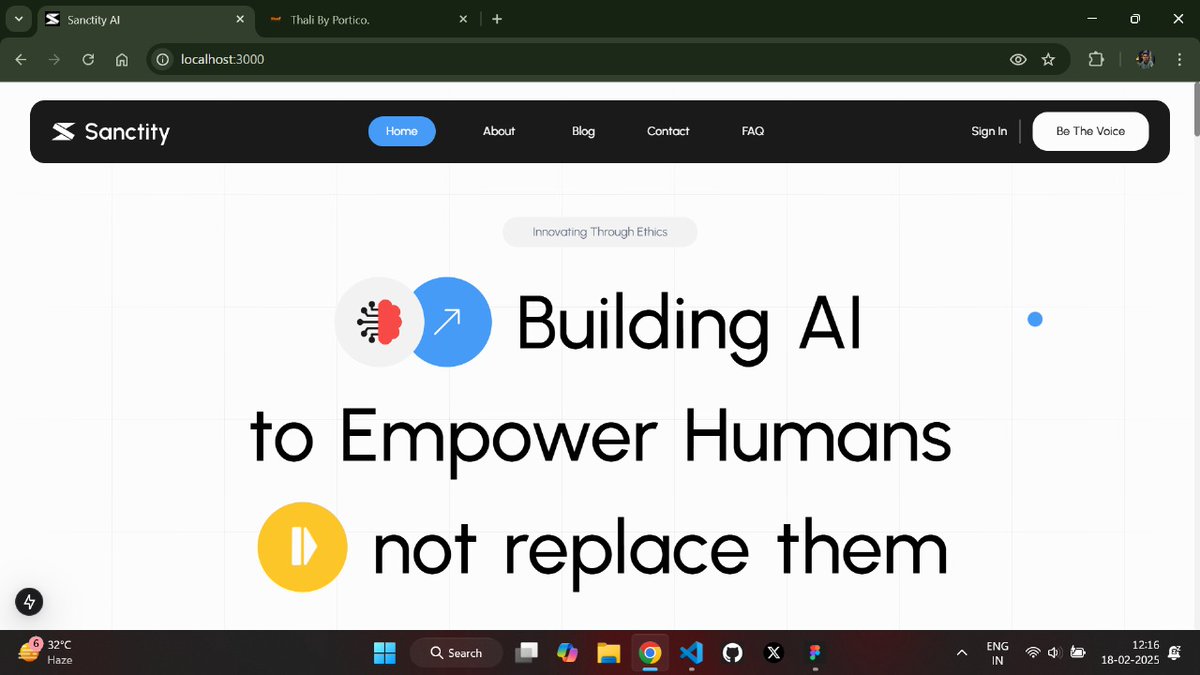
Hey guys! So Excited to share that our new website is live
Check us out : sanctity.ai
@SanctityAi
1
71
18 Feb 2025
Been inactive on twitter since I'm working as Full Stack dev😅
Btw our Sanctity AI website will go live very soon...
4
120
Pritam Kumar Manohari retweeted

25 Jan 2025
12 months of
• Hardwork
• Consistency
• focus
• Discipline
Can change your life forever 🙇🏻
87
4
104
1,885
25 Dec 2024
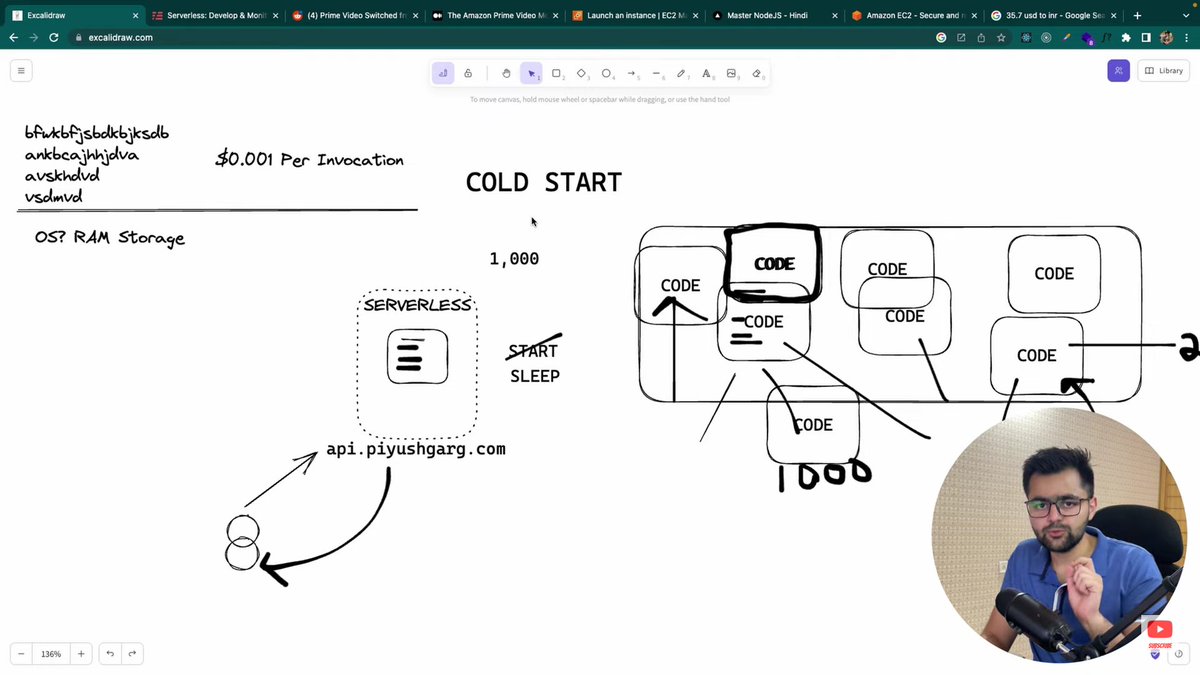
Started learning AWS,
Learned about Serverless and monolith architecture by aws playlist of @piyushgarg_dev today
5
86


24 Dec 2024
My 2024 wrap:
1) Learned Full stack dev
2) Became stronger in frontend
3) Did many decent projects, some freelance work too
4) Just started devops
5) So many rejections (or no response) but finally grabbed a paid remote internship
🤗
3
1
6
295
24 Dec 2024
Surely could have been more productive but no problem, a long journey ahead ♥️🤗
2
30
21 Dec 2024
Does anyone know how to make tree type graphical structure (nicely designable, not very basic) in react?
Any help is appreciated ❤️
3
4
484
17 Dec 2024
Can anyone please recommend me best YT tutorials for AWS?
3
1
255
7 Dec 2024
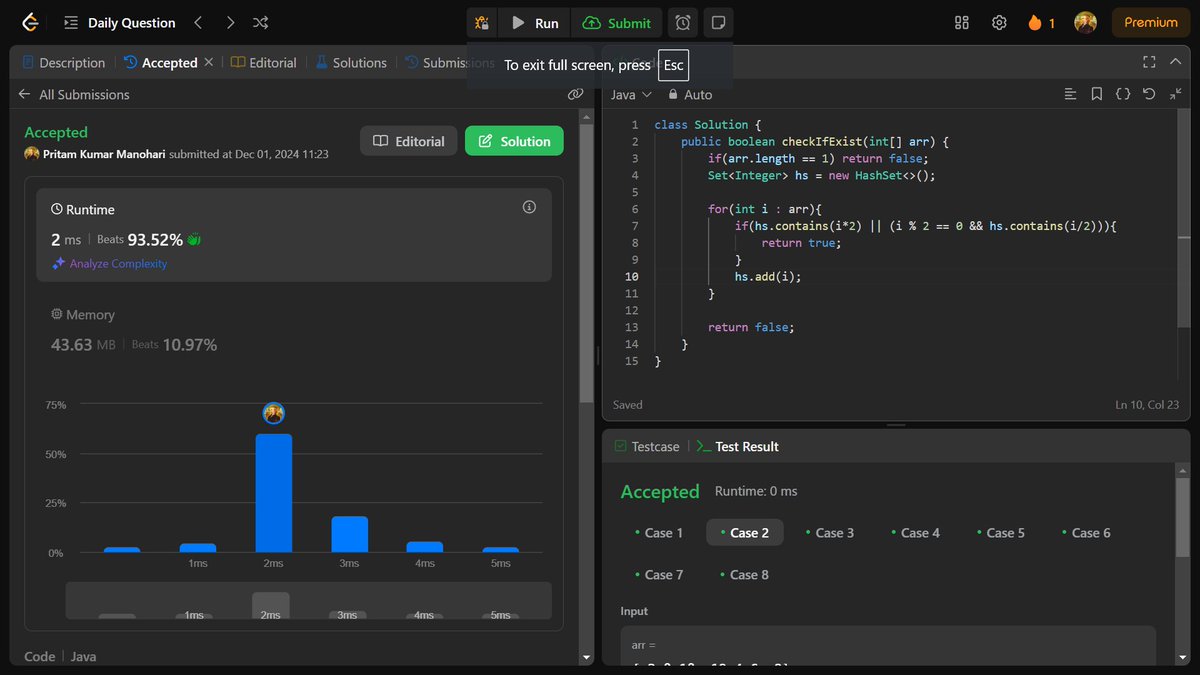
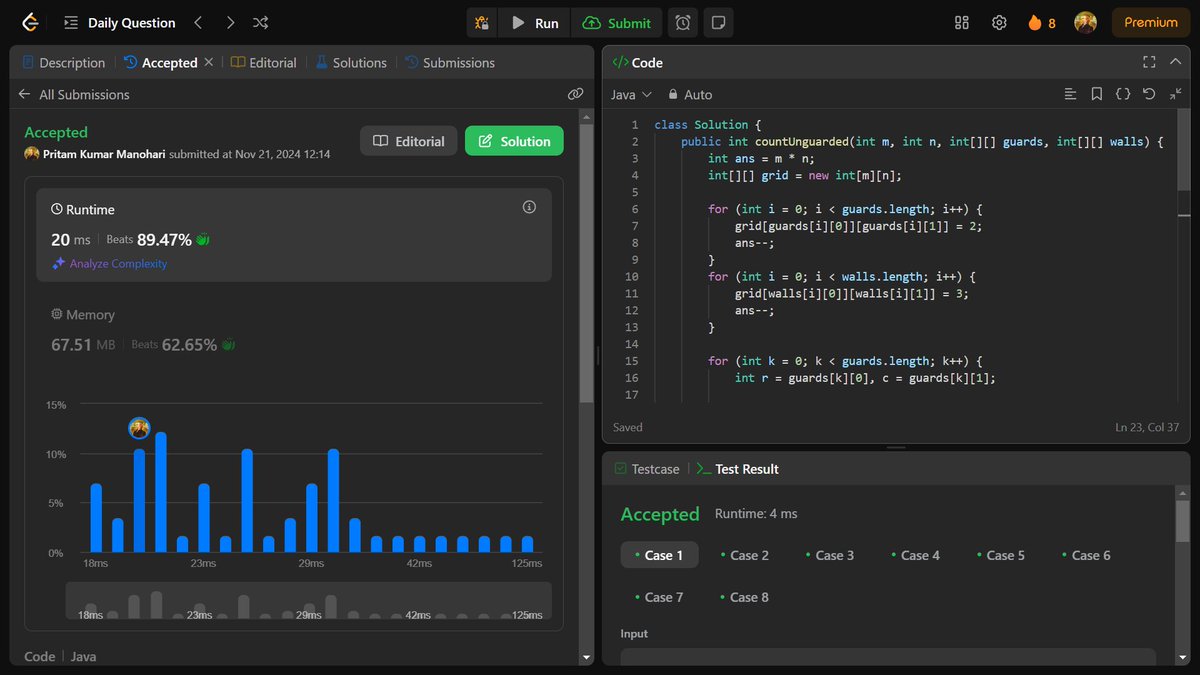
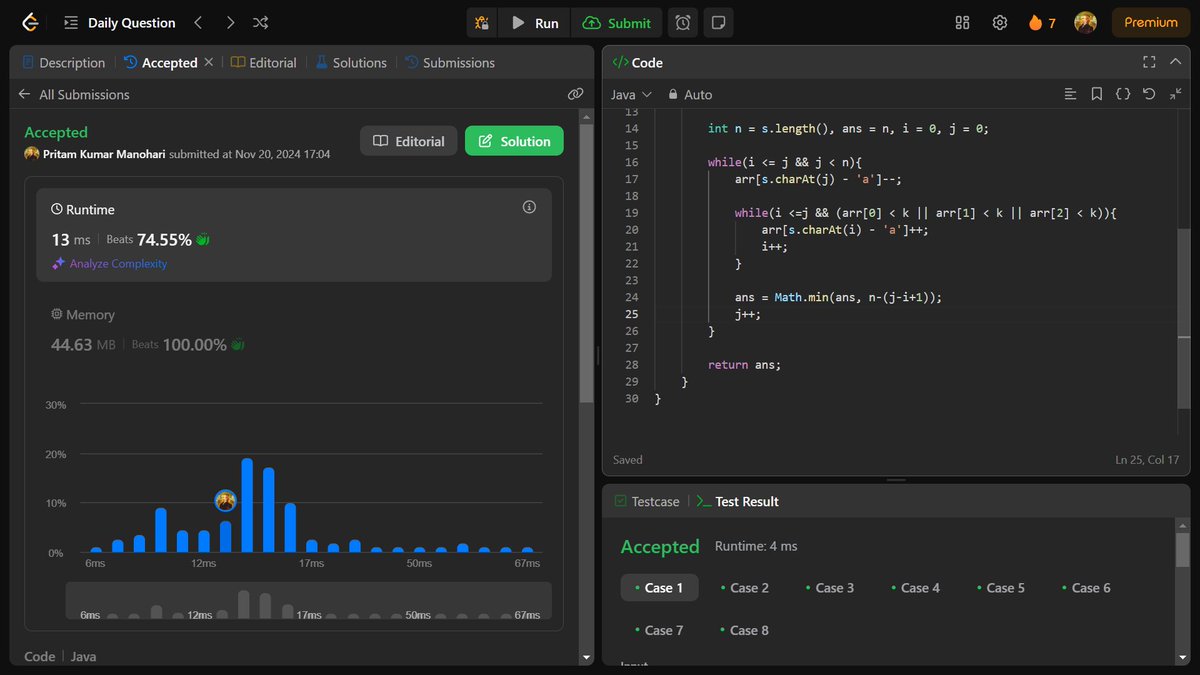
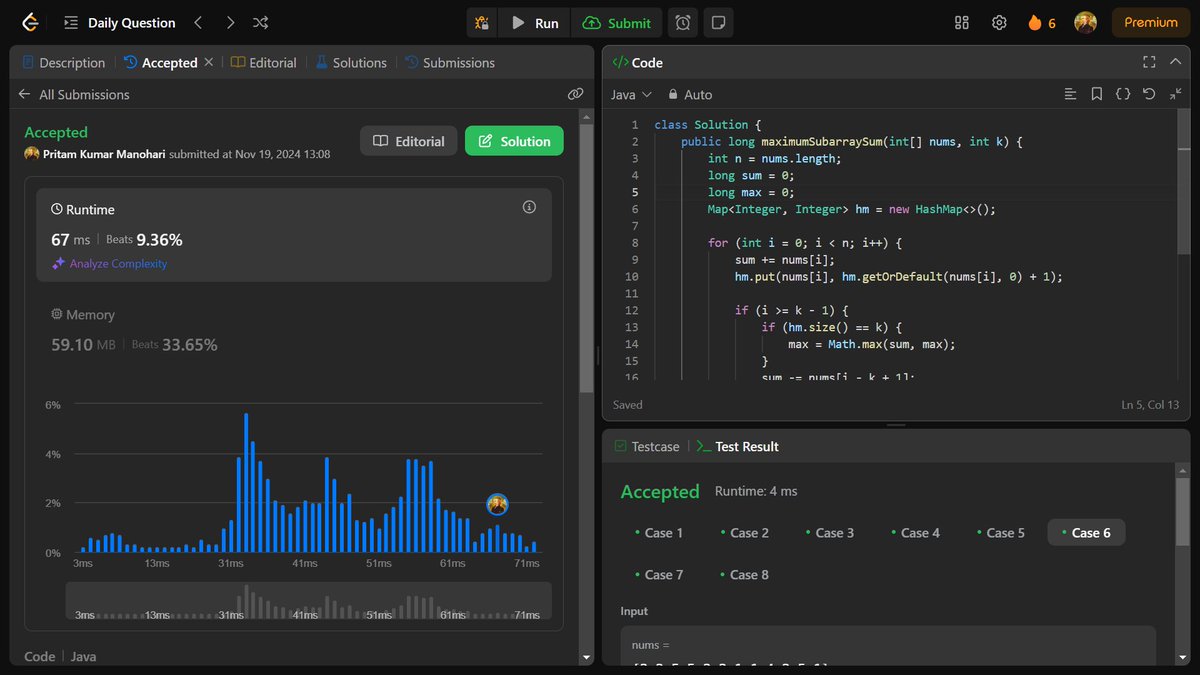
Veryyy eassyyyy (took screenshot but forgot to post yesterday😅)
3
332
28 Nov 2024
So happy to share that I've been selected at Sanctity AI as a Frontend Developer Intern! 🚀
Excited to work with React, Next.js, TypeScript, Tailwind CSS, Framer Motion etc to build amazing experiences. Here's to learning and growing! 💻✨
#FrontendDevelopment #TechJourney
ALT Image is AI generated, ignore small mistakes in image
4
1
11
330