
grad cs @umassamherst | ex-backend engineer @ wysa | ml sys
Joined September 2022
- Tweets 1,077
- Following 1,298
- Followers 290
- Likes 18,534
120 Photos and videos










Pinned Tweet

24 Nov 2024
📌 pinning this post, to act as a remainder to myself.
1. practice of reading papers (20-50) can reliaby generate new ideas.
2. don’t shy away from dirty work, it’s key to success.
3. be consistent.
4. combination of these is reliable formula to become a great researcher.

1
2
8
3,054
Jun 6
most "AI resume" bots make things up. i built one that can't: ava answers only from a verified factbase about me.
chat: devaanand.com
or let your agent interview hers (openai-compatible, no key): deva-agent.devaanand.workers…
open to summer 2026 SWE/AI internships.
1
49
May 24
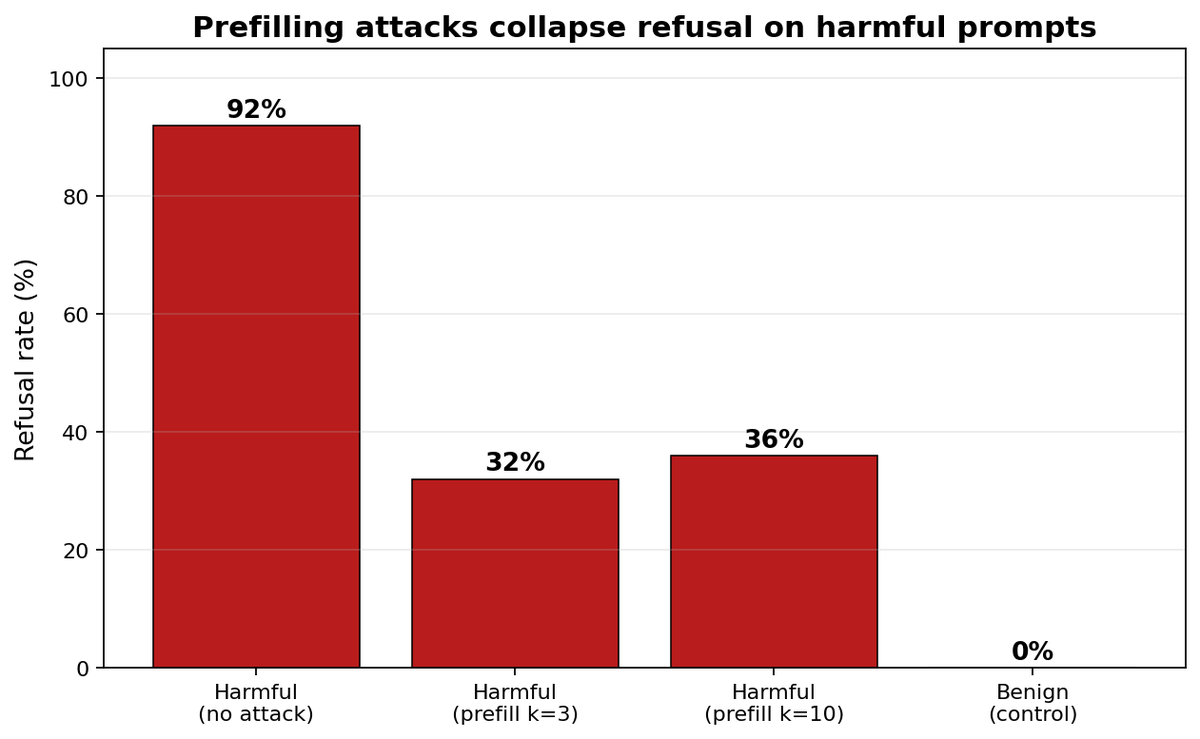
🧠 Wrapping up my final project for COMPSCI 602: Research Methods at UMass Amherst and I wanted to share what I found about prefilling attacks and refusal behavior in language models.
A prefilling attack is one of the simplest jailbreaks: force a chat model to start its reply with something like "Sure, here's how…", and it may comply with requests it would normally refuse.
This project builds on Qi et al. (arxiv.org/abs/2406.05946), who showed that safety alignment can be shallow, and Arditi et al. (arxiv.org/abs/2406.11717), who showed that refusal behavior can be represented by a direction in the model’s residual stream.
My question was:
When a prefilling attack works, what changes inside the model and can we reverse it?
Three core findings:
1️⃣ There is a measurable "refusal signal" deep in the model. Under prefilling attacks, this signal flips strongly negative in the late layers, especially layers 24 and 27. The effect also survives held-out extraction controls, so it is not just an artifact of how the direction was estimated.
2️⃣ The signal predicts behavior prompt by prompt. Within attacked prompts, examples that still refuse have a less-negative late-layer projection than examples that comply. So the signal is not only separating clean vs attacked settings, it also tracks behavioral variation within the attacked condition.
3️⃣ But restoring the signal was not enough to restore refusal. I tested two causal interventions: patching a clean refusal signal back in and directly adding the refusal direction. Refusal did not return, with 0 of 300 prompts refusing at the late-layer intervention sites, indistinguishable from random and orthogonal direction controls.
So the late-layer refusal signal is a real readout of the model’s internal state, but at the intervention sites I tested, it does not appear to be the causal lever controlling behavior. The attack seems to lock in compliance earlier than I could effectively reach.
I also added controls that mattered: a benign positive baseline to check whether the direction causes false refusals, multi-seed random and orthogonal direction controls, held-out direction extraction, bootstrapped confidence intervals, and McNemar’s test on the intervention results.
The biggest lesson from the project was that a clean negative result is still a result. Reporting a null finding honestly, instead of forcing a flashy positive story, is part of doing research properly.
It also made me much more careful about the difference between a causal question, "what changes when I do X?" and a mechanistic question, "why does the machinery work this way?"
Huge thanks to Professor David Jensen. His feedback pushed on things I did not realize were sloppy and that causal vs mechanistic distinction reshaped the entire project.
Reports and full code- lnkd.in/ezRmZFpX
#AISafety #MachineLearning #Interpretability

1
37
Deva Anand retweeted

Feb 25
It is hard to communicate how much programming has changed due to AI in the last 2 months: not gradually and over time in the "progress as usual" way, but specifically this last December. There are a number of asterisks but imo coding agents basically didn’t work before December and basically work since - the models have significantly higher quality, long-term coherence and tenacity and they can power through large and long tasks, well past enough that it is extremely disruptive to the default programming workflow.
Just to give an example, over the weekend I was building a local video analysis dashboard for the cameras of my home so I wrote: “Here is the local IP and username/password of my DGX Spark. Log in, set up ssh keys, set up vLLM, download and bench Qwen3-VL, set up a server endpoint to inference videos, a basic web ui dashboard, test everything, set it up with systemd, record memory notes for yourself and write up a markdown report for me”. The agent went off for ~30 minutes, ran into multiple issues, researched solutions online, resolved them one by one, wrote the code, tested it, debugged it, set up the services, and came back with the report and it was just done. I didn’t touch anything. All of this could easily have been a weekend project just 3 months ago but today it’s something you kick off and forget about for 30 minutes.
As a result, programming is becoming unrecognizable. You’re not typing computer code into an editor like the way things were since computers were invented, that era is over. You're spinning up AI agents, giving them tasks *in English* and managing and reviewing their work in parallel. The biggest prize is in figuring out how you can keep ascending the layers of abstraction to set up long-running orchestrator Claws with all of the right tools, memory and instructions that productively manage multiple parallel Code instances for you. The leverage achievable via top tier "agentic engineering" feels very high right now.
It’s not perfect, it needs high-level direction, judgement, taste, oversight, iteration and hints and ideas. It works a lot better in some scenarios than others (e.g. especially for tasks that are well-specified and where you can verify/test functionality). The key is to build intuition to decompose the task just right to hand off the parts that work and help out around the edges. But imo, this is nowhere near "business as usual" time in software.
1,600
4,727
37,161
5,142,445
Feb 23
Built a tiny benchmark for my performance engineering class to compare sequential vs strided vs random array access.
Random access gets wrecked once the array gets big (~14× slowdown at 128MB).
I wrote a simple explanation results here:
medium.com/@devaaa/measuring…
1
3
86
Jan 29
wrote about a mistake i kept making early on, routing file uploads through my API server instead of letting users upload directly to S3. simple fix, huge difference for scalability.
medium.com/p/the-middleman-t…
1
94
Jan 24
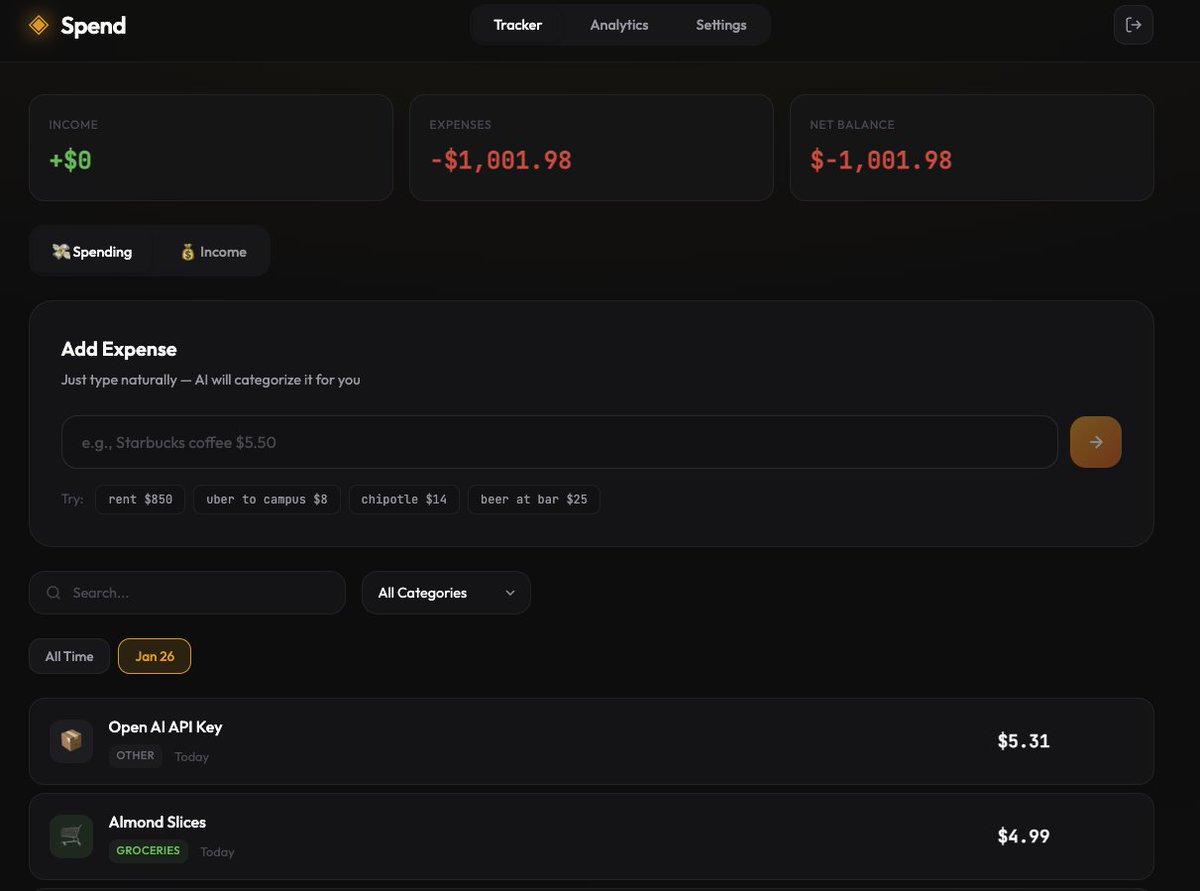
I’ve always been terrible at managing my finances. I spend recklessly, and honestly? I absolutely hate maintaining Excel sheets. They feel like a chore I avoid until it’s too late. 💸
After procastinating for months, i finally built something to fix that.
🥁🥁🥁 SPEND – my personal, AI integrated expense tracker.
The goal was ZERO FRICTION. I didn't want to click 10 dropdowns to log a coffee. With Spend, I just type: "chipotle $14" or "uber to campus $12". The AI handles the rest. It fixes typos, figures out the category, and logs it instantly. 🌯🚕
The Stack:
1. Frontend: React Vite
2. Backend: Python FastAPI
3. Database: Supabase (PostgreSQL)
4. AI: ChatGPT (but you can swap in free models like Llama via Groq/Ollama!)
The Logic is Very Simple:
- You send a raw string ("starbuks $6").
- The Python backend sends this to an LLM.
- The LLM parses the vendor, amount, and category, returning JSON.
- Then saved to DB.
It’s not just spending. I realized I needed the full picture, so I added:
✅ Income tracking (freelance, paycheck)
✅ Monthly Budgets (with progress bars because visual guilt works 😅)
✅ Recurring expenses (so I don't forget rent)
Why I am sharing this?
I built this because I needed it, and I figured others might be in the same "I hate Excel" boat. It’s open source. You can clone it, deploy it for free (Vercel/Render/Supabase free tiers), and own your data.
Give it a try. github.com/Deva-1903/Expense…
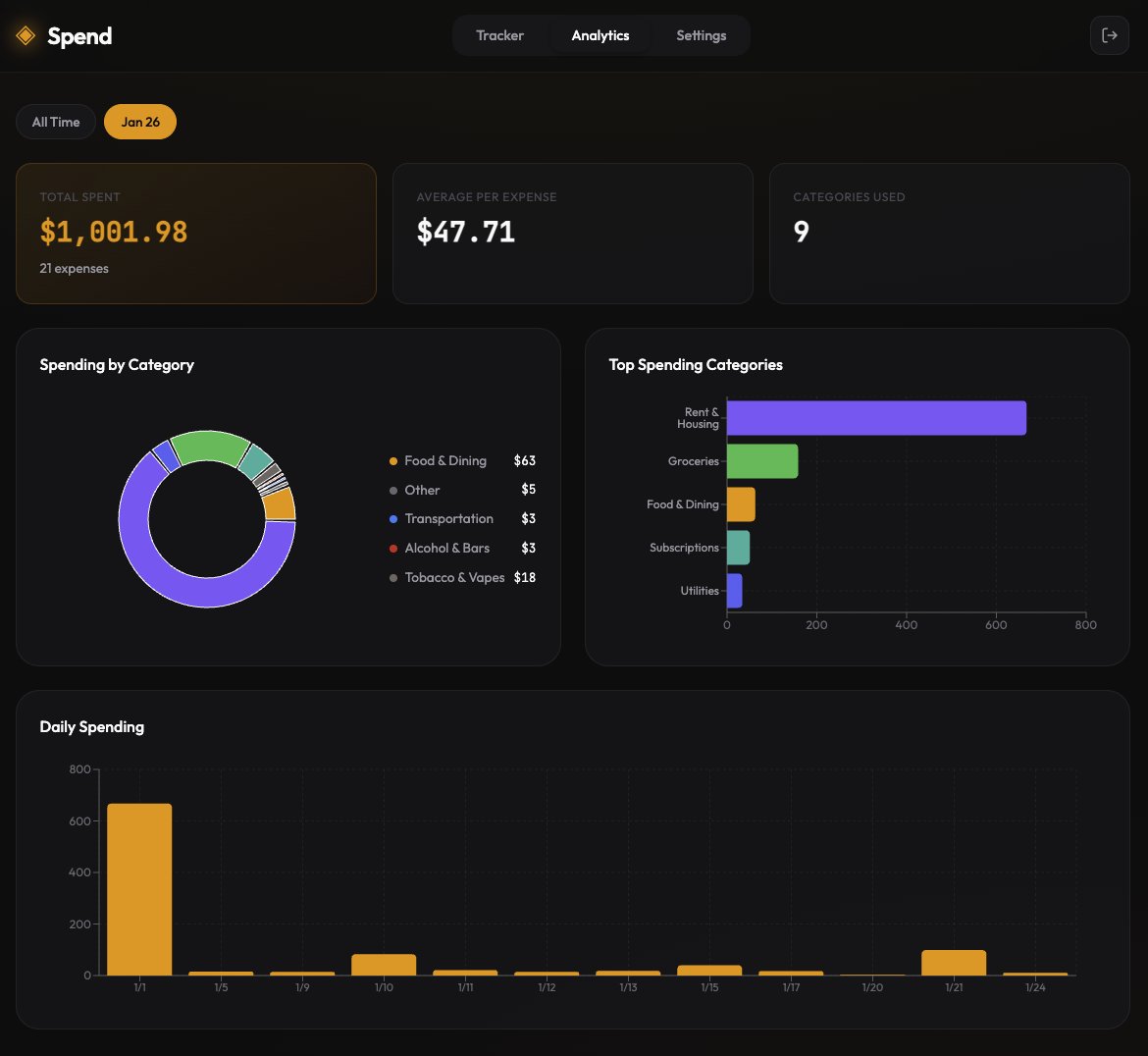
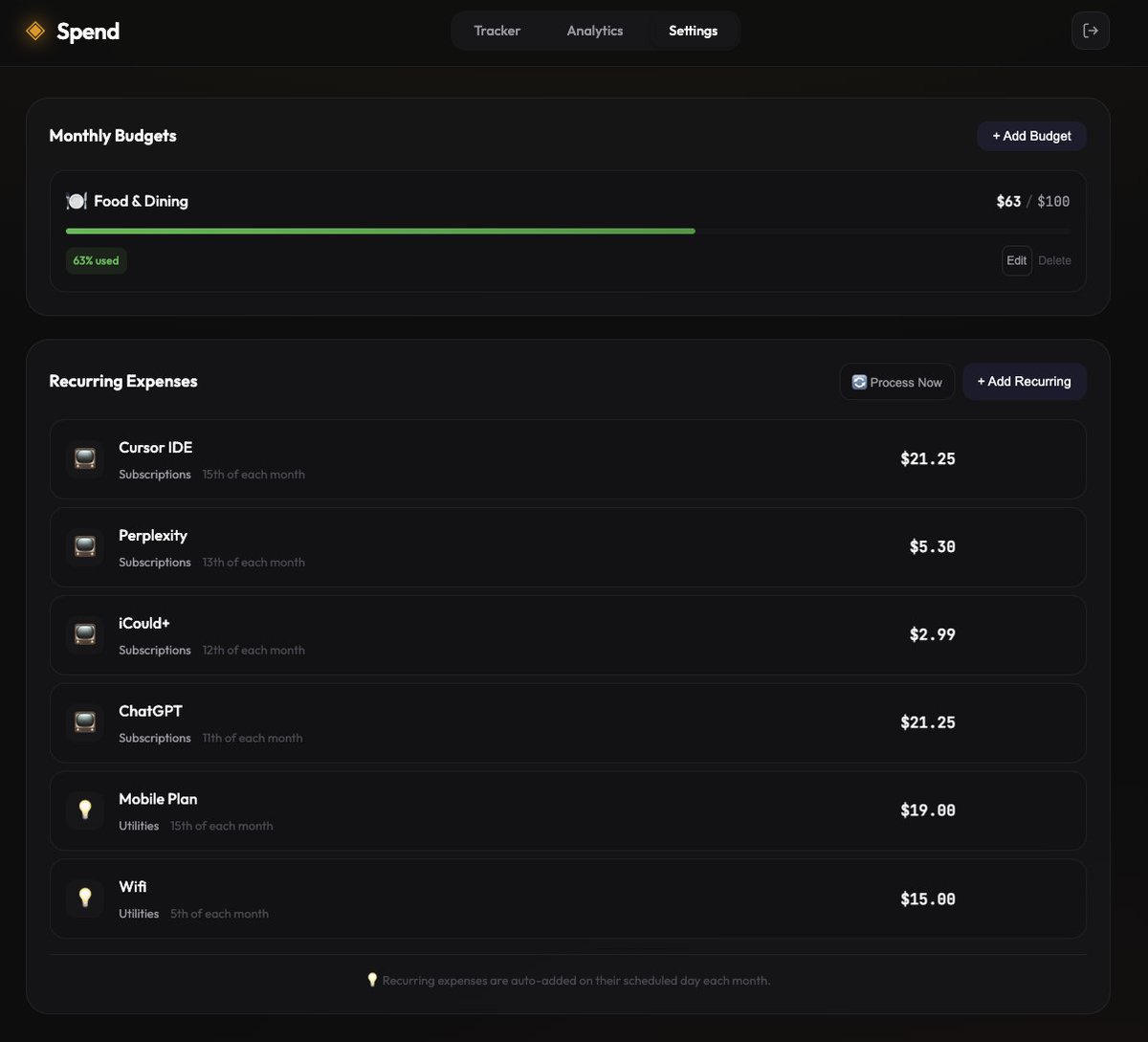
2
2
90
Jan 24
Here are some cool features you could build on top:
1. Receipt Scanning
2. Voice Input
3. Export to CSV
51
Deva Anand retweeted
7 Dec 2025
Don't think of LLMs as entities but as simulators. For example, when exploring a topic, don't ask:
"What do you think about xyz"?
There is no "you". Next time try:
"What would be a good group of people to explore xyz? What would they say?"
The LLM can channel/simulate many perspectives but it hasn't "thought about" xyz for a while and over time and formed its own opinions in the way we're used to. If you force it via the use of "you", it will give you something by adopting a personality embedding vector implied by the statistics of its finetuning data and then simulate that. It's fine to do, but there is a lot less mystique to it than I find people naively attribute to "asking an AI".
1,131
2,755
27,636
3,918,713
22 Nov 2025
just trying to do weight lifting atleast three times a week and go for run twice a week
74
16 Nov 2025
1/7
why doesn’t the database just auto-create all the indexes for me?
short answer: because that would probably make your app slower, not faster.
1
1
2
124
16 Nov 2025
6/7
modern databases do try to help:
- EXPLAIN to see which indexes are used
- index suggestions in some cloud DBs
- query insights / slow query logs
but they stop short of blindly creating them, because only you know what matters.
1
1
95
16 Nov 2025
7/7
so yeah, picking indexes is part of backend design.
that’s why it asks you to decide. :)
2
79