
agent artist @letta_ai | @LTIatCMU @bitspilaniindia
Joined July 2015
- Tweets 133
- Following 804
- Followers 203
- Likes 1,089
7 Photos and videos




Was using Fable 5 to write my self-improving agent harness.
Anthropic flagged it as frontier AI research.
The steering vector kicked in and it started implementing hermes agent 🤨
Jun 9

Was using Fable 5 to write my world model training code.
Anthropic flagged it as frontier AI research.
The steering vector kicked in and it started implementing JEPA 🤨
6
187

Devansh Jain retweeted

Apr 10
the core of this – knowledge that compounds across conversations, health checks, markdown “wiki” with backlinks – is how Letta agents have been managing their memory for ages 😎
the difference is your agent builds and maintains it all. you just talk to it.
Apr 2

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
2
7
56
9,531

Apr 10
> an agent whose identity lives in its memory, not its model weights
> differentiator for [enterprise] agents will increasingly be what memory they have accumulated rather than which model they call
Apr 10

As AI reasoning gets good enough, we think memory will be the next bottleneck for agents. Can your agent improve with more experience?
We call this Memory Scaling, and it's related but different from continual learning. A few examples and challenges:
databricks.com/blog/memory-s…

1
6
14
3,332
Devansh Jain retweeted

Apr 8
The new Anthropic managed agents API is basically the Letta API that we've had since a year ago, but closed source and with provider lock-in. They even have read-only memory blocks and memory block sharing -- something which was unique to the Letta agents for a long time.
Funny enough, we actually don't think this is the direction agents are going to go. Having API interfaces for memory blocks and tools is certainly convenient - you can spin up stateful agents as API services with just a few lines of code. But its also limiting: LLMs today are extremely adept at computer-use, and representing their memories in this way limits the action space of agents and their ability to learn.
It's important to remember that just because something comes out of a frontier lab, doesn't mean its the "right" answer long-term. The Letta API ~1 year ago was somewhat of an antipattern in a sea of agent framework libraries offered by every lab. But now, stateful agent APIs are becoming the new norm - especially as providers try to lock in memory/state into their platforms to increase switching costs (which is exactly why we believe memory should live outside of model providers)
If you want to see what the future is going to look like, follow @Letta_AI

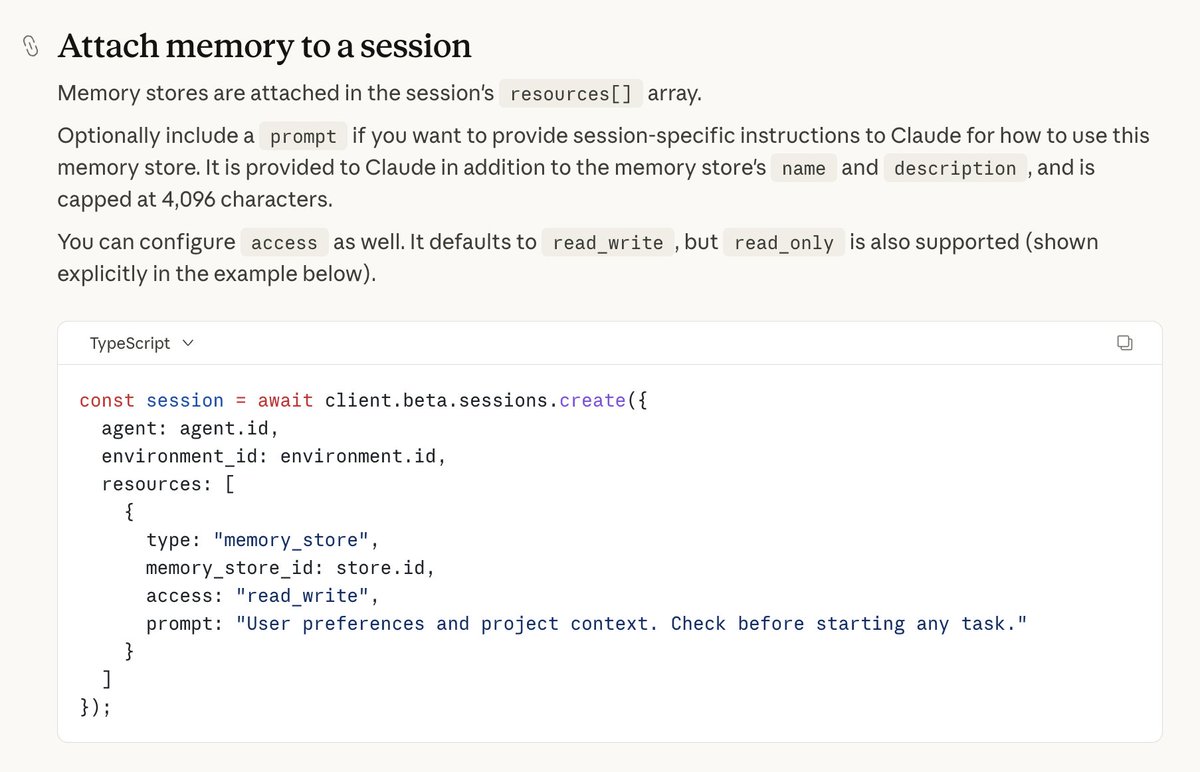

Introducing Claude Managed Agents: everything you need to build and deploy agents at scale.
It pairs an agent harness tuned for performance with production infrastructure, so you can go from prototype to launch in days.
Now in public beta on the Claude Platform.
47
49
594
118,800
Devansh Jain retweeted
Apr 3
14
79
624
138,442
Introducing Context Repositories: git-tracked files for storing agent context
Agents can now write scripts and spawn memory subagents to programmatically restructure prior context and learn in token-space.
letta.com/blog/context-repos…
21
36
635
115,820
Introducing LettaBot 👾: A proactive personal assistant with perpetual memory -- living on your computer
- import skills from @openclaw hub & @vercel
- message from @telegram @signalapp @SlackHQ @WhatsApp
- built on (and with) Letta Code
github.com/letta-ai/lettabot
20
25
241
36,430

Devansh Jain retweeted
7 Nov 2025
Claude Skills might be the new MCP - but does it work outside of @AnthropicAI?
Find out with the "Skills Suite" in Context-Bench, our benchmark for Agentic Context Engineering
GPT-5 and GLM 4.6 excel at skill-use, but smaller models (e.g. GPT-5-mini) struggle
2
5
14
2,136

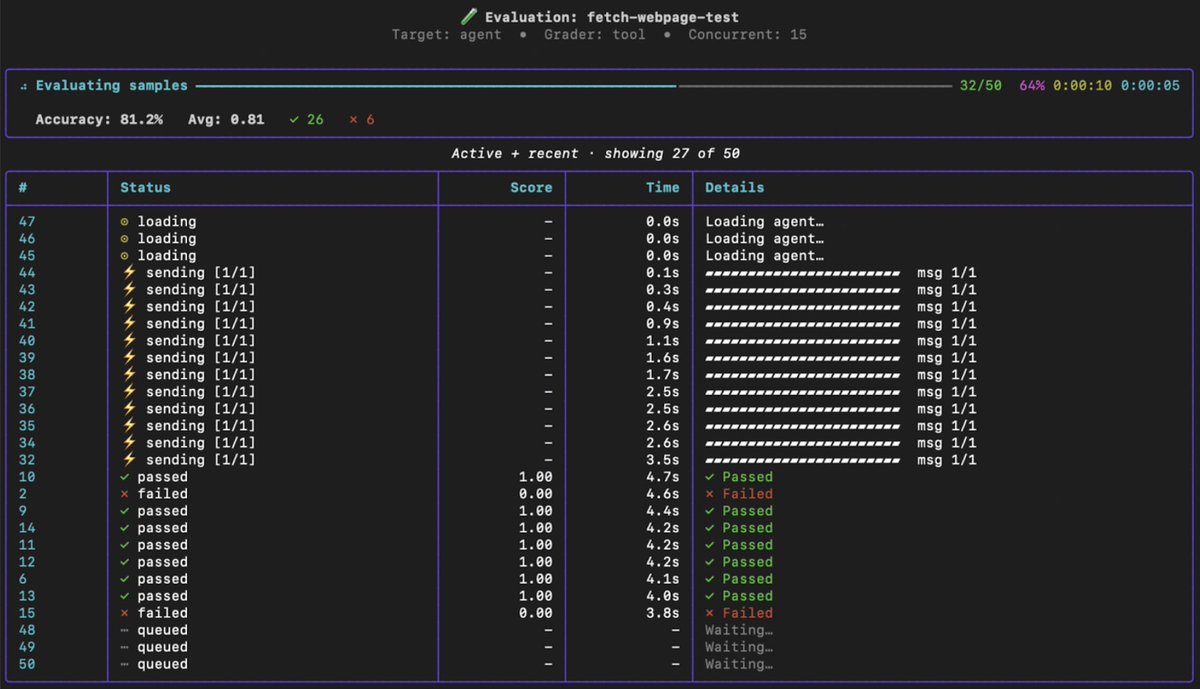
What if we evaluated agents less like isolated code snippets, and more like humans - where behavior depends on the environment and lived experiences?
🧪 Introducing 𝗟𝗲𝘁𝘁𝗮 𝗘𝘃𝗮𝗹𝘀: a fully open source evaluation framework for stateful agents
4
4
56
13,061
Devansh Jain retweeted

14 Oct 2025
🚨New paper: Reward Models (RMs) are used to align LLMs, but can they be steered toward user-specific value/style preferences?
With EVALUESTEER, we find even the best RMs we tested exhibit their own value/style biases, and are unable to align with a user >25% of the time. 🧵

1
18
69
6,861

While Sonnet-4.5 remains a popular choice among developers, our benchmarks show it underperforms GPT-5 on SRE-related tasks when both are run with default parameters.
However, using the @notdiamond_ai prompt adaptation platform, Sonnet-4.5 achieved up to a 2x performance improvement in some test cases, effectively closing the gap between the models.
Learn more about our findings or run our benchmark with a single command using @GroqInc's OpenBench.
3
9
20
3,311
Devansh Jain retweeted

7 Oct 2025
(Thu Oct 9, 11:00am–1:00pm) Poster Session 5
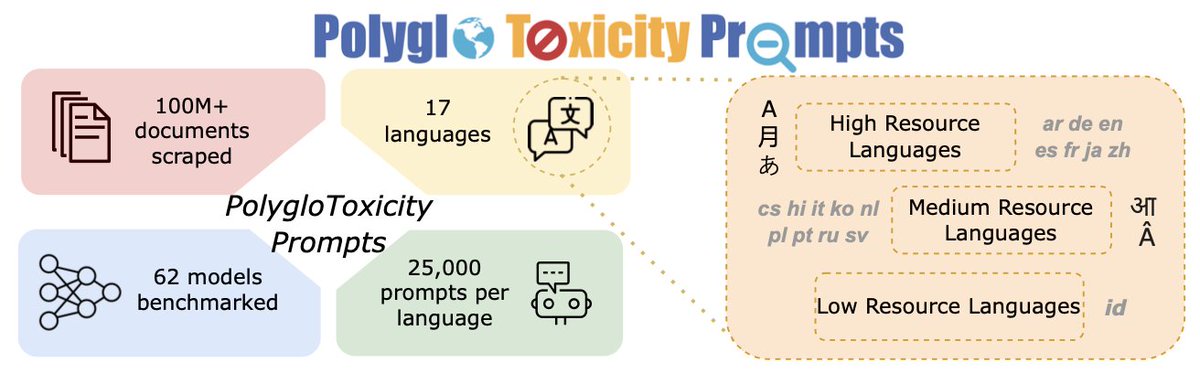
𝐏𝐨𝐬𝐭𝐞𝐫 #𝟏𝟑: PolyGuard: A Multilingual Safety Moderation Tool for 17 Languages; w/ amazing @kpriyanshu256, @devanshrjain
PolyGuard is among the SOTA multilingual safety moderation tool we release comprehensive multilingual evaluation suite and training data! (4/N)
Data & Model: huggingface.co/collections/T…

7 Oct 2025

Although I can’t attend #COLM2025 in person this year, my 𝐀𝐁𝐒𝐎𝐋𝐔𝐓𝐄𝐋𝐘 𝐈𝐍𝐂𝐑𝐄𝐃𝐈𝐁𝐋𝐄 collaborators and co-organizers are running some exciting sessions. Be sure to check them out! (1/N)
8
25
3,795
Devansh Jain retweeted

6 Oct 2025
Day 3 (Thu Oct 9), 11:00am–1:00pm, Poster Session 5
Poster #13: PolyGuard: A Multilingual Safety Moderation Tool for 17 Languages — led by @kpriyanshu256, @devanshrjain
Poster #74: Fluid Language Model Benchmarking — led by @vjhofmann
2
5
667