
Joined March 2017
- Tweets 8,295
- Following 1,463
- Followers 10,190
- Likes 22,530
718 Photos and videos










Jun 11
Take a page out of the crypto book to offer trustless access to Fable/Mythos.
Instead of preventing everything up front with a huge amount of false positives, allow businesses from USA and other trusted allied countries to put up 7-10 figures in USD (depending on their size) as a collateral (a stake), and use your new 30 day retention window to auto-monitor, flag and escalate suspicious prompts for manual review.
If anything is deemed against the rules slash the stake. That way honest actors have full access to the model and can help further society/research, and any bad behavior is disincentivized and companies will do their own witch hunting internally.
In crypto we design everything under the assumption nobody can be trusted, and yet things remain open for everyone to use.
Jun 11

We’re rolling out changes to make Fable 5’s safeguards for frontier LLM development visible.
Starting this week, flagged requests will visibly fall back to Opus 4.8—the same as our safeguards for cyber and bio. You will see this every time it happens. On the API, any flagged requests will return a reason for their refusal (coming to server-side fallback in the next few days).
We wanted to deploy Fable 5 to our users quickly and safely. Visible safeguards can be probed, so they have to be robust, which takes time to get right. Invisible safeguards can be targeted more narrowly, allowing us to ship quickly with very few false positives. We went with invisible safeguards for this reason—and that was the wrong tradeoff. You should have visibility into the safeguards we have in place, and why. We’re sorry for not getting the balance right.
Making the safeguards visible makes them easier to work around, so keeping them robust to jailbreaks will unfortunately mean more false positives while we improve the classifiers. We're also tuning our bio and cyber classifiers to trigger less often on harmless requests. We know this is frustrating and we’ll do our best to keep this period as short as possible.
If you think a request has been mistakenly flagged: run /feedback in Claude Code, click thumbs-down on the fallback in Claude.ai or Cowork, or file the safeguard appeal form for API requests. Your reports help us tune these classifiers and we appreciate your feedback.
support.claude.com/en/articl…
2
9
647
Jun 1
I expect this number to 10x within a few months.
Right now Numo is in early access, with very few tasks as we build out the whole end to end pipeline.
We are just getting started.
May 29

760k submissions on Numo from 13k contributors in 1 month.
Turns out, when you make it simple to contribute to AI, people show up.
Still early.
16
9
69
5,153
May 29
Are you paying attention anon?
While everyone is obsessing about semiconductors and energy, the other side of the barbell is a generationally important industry that is still mostly overlooked.
The industry of data for AI.
Don’t fade @psdnai
May 29

LARRY ELLISON: AI IS RAPIDLY COMMODITIZING BECAUSE MOST MODELS ARE TRAINED ON THE SAME PUBLIC INTERNET DATA.
THE REAL COMPETITIVE EDGE ISN’T THE MODEL ANYMORE — IT’S ACCESS TO EXCLUSIVE, PROPRIETARY DATASETS.
THAT MAY BE THE ONLY MOAT LEFT.
5
14
1,787
May 26
Is the Ferrari here in the room with us?
Props to you for being able to make the outside just as bland as the interior
Way to dilute the heritage, Jony! 👏
May 25

NEW: Ferrari unveils the Luce, its first electric vehicle designed by Jony Ive.

3
10
676
May 20
when AI will have:
infinite compute & data centers in space,
the perfect self-learning model architecture,
complete integration into all of our lives...
then AI will hav- oh wait.. actually, AI will still need new, fresh, data to keep the models accurate.
data >>
10
9
56
3,919
Andrea | Devrelius retweeted

May 20
Story's latest protocol feature, CDR ("Confidential Data Rails"), enables new app ideas that share private data.
For example, an app in which writers publish an article where a piece of the content is privately encrypted onchain and only accessible via a paid license.
11
8
73
3,983
May 19
if you want to 100x your money TODAY, you can't long NVDA, or buy into an Anthropic SPV. you need to move further up the AI stack.
Stack is: Compute -> Models -> Data.
Compute (last 10-20 years):
NVIDIA: 1,500%
Intel/ARM/etc: 200-300%
infra like Energy, semis, etc all pumped/pumping
Models (last 5-6 years):
OpenAI: >$1T IPO soon
Anthropic: >$1T IPO soon
xAI, Mistral, etc all have mega valuations already
Data (next 5-10 years):
it's still early innings for data, but Mercor already valued >$10B, Scale AI bought by Meta for $14B. Many new companies emerging too, eating their lunch.
???
???
Don't get me wrong, you can still make decent returns on compute and models today, but the massive upside is no longer there.
what's left is data.
AI cannot function without training data.
AI cannot get better without training data.
AI needs training data just as much as it needs data centers and energy.
The word "data" in "data centers" tells you all you need to know.
Data is like the spice in Dune.
Companies that sell high signal training data are selling picks and shovels in the AI race.
Frontier AI labs are ALREADY spending massive amounts of money on data, and after they IPO they will have EVEN MORE massive amounts of cash to spend on data to get ahead of their competition.
We will see $1T data companies in the future.
NFA, DYOR
8
4
30
1,337
May 14
be careful using opus 4.7 adaptive for simple tasks!
i asked it to help me generate a very simple diagram. It started thinking for 15 mins straight and generated ~9000 words of thought
didn't even generate the diagram because by the time it was done i got hit with the "Claude reached its max length for this message."
lmao rip tokens
2
19
843
May 12
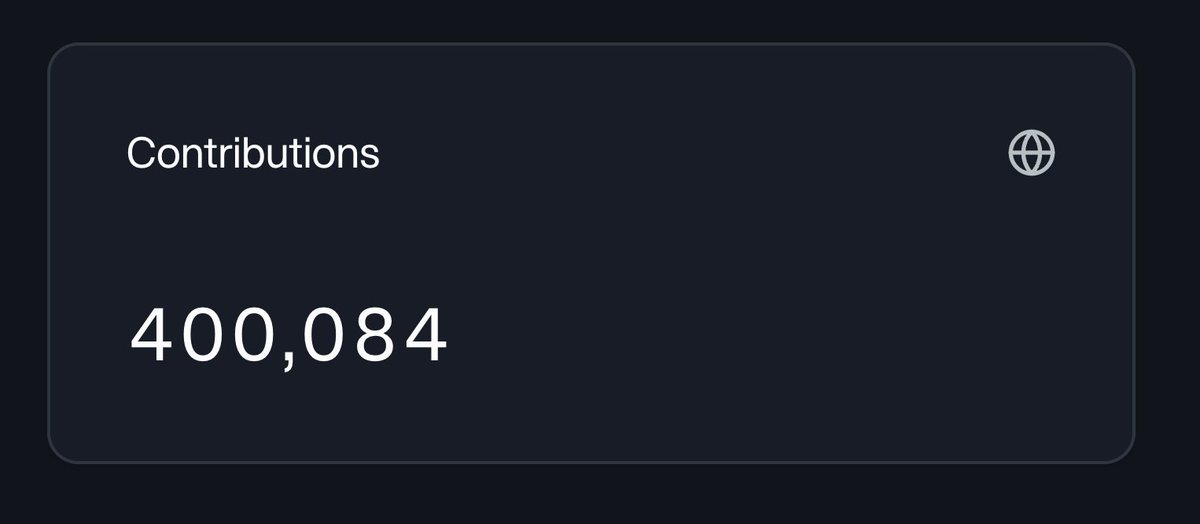
Numo just passed 400,000 training data contributions.
all the while operating in early access, near zero marketing and the mobile app hasn't even launched yet 🔥
gnumo
18
15
74
2,970
May 8
numo is in early access.
there are only Vietnamese and indic languages tasks atm.
you need to be a native speaker in those languages to participate.
some dude in nigeria: hold my bánh mì
13
8
51
2,802
May 7
seven days ago we launched Numo with @psdnai.
a billion people speak hindi, bengali, tamil, telugu. less than 0.1% of voice ai training data is in any of them (like in microsoft's VibeVoice latest model).
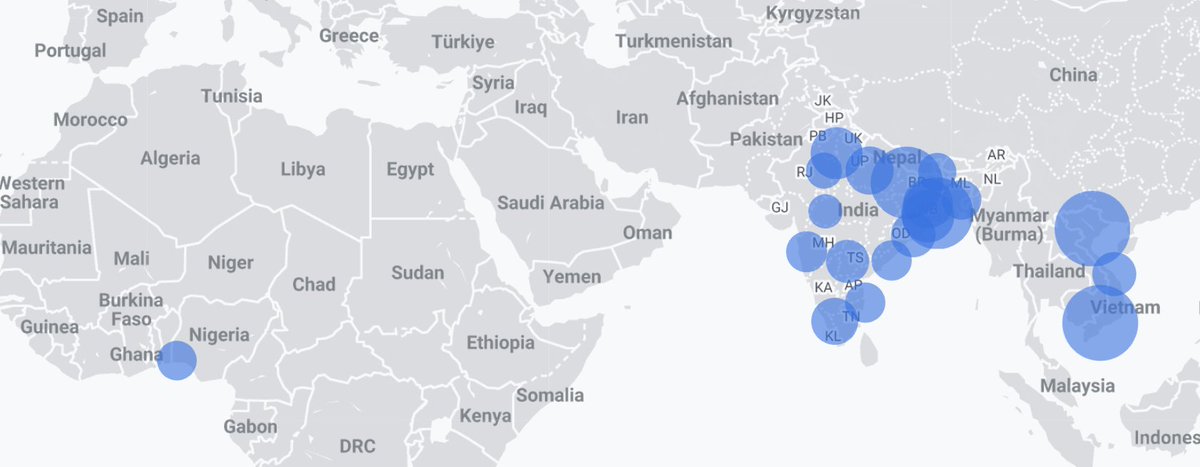
nobody was fixing this big training gap, so we started collecting thousands of hours from contributors all over india.
week one stats:
> 210,000 contributions
> 18,000 contributors
> contributions growing about 40% day over day
every contribution registered as IP.
every contributor rewarded.
every second of audio licensed at the moment it's create on story.
Vietnamese launched just hours ago and we already have thousands of contributions!
here's a some fun facts about why we are focusing on Vietnamese:
Vietnamese has six tones across three regional dialect systems: Northern, Central, Southern, with big differences in tone systems, vocabulary, and pronunciation
Central Vietnamese is the most different and it’s the most challenging dialect, even for other Vietnamese speakers
Most voice AI is trained on Northern Vietnamese which misses roughly half of how the country actually speaks
thanks to Numo's collection efforts AI models will be able to upskill on conversational nuances and be more realistic.
we're also not stopping at voice. we'll start rolling out other forms of tasks soon, always focused on long tail, hard to scrape real world data the models can't easily scrape from the internet.
38
17
78
16,029
May 5
Numo now has 15k contributors with 130,000 rare voice recordings.
growth is inflecting up, with just 4 languages.
we are expanding to additional languages and tasks very soon.
every recording is rights-cleared and licensed onchain from the moment of submission.
21
20
100
7,573
May 2
Grok is pretty good at finding tweets

. @nikitabier why is google search better at finding the tweet i'm looking for than X search?
2
7
622
May 2
This would solve so much in Italy.
Most existing tax benefits are for people from abroad who move their tax residency back (I am one of them), forcing Italians to live abroad and then come back lol…
they really need to do something to avoid the braindrain and incentivize Italians to stay in Italy for good. (And no the forfettario is not enough because it incentivizes ppl to stop working or evade taxes once they hit >80k.. look it up and you’ll realize how retarded it is)
A good compromise would be:
- 50% off your income tax for 1 kid,
- 90% off your income tax for 2 kids
- no capital gains tax for 3 kids
Brain drain and population issue solved in one go.
There’s plenty of other taxes like a preposterously high VAT of 22%..
This is an investment in securing tax payers for the future otherwise Italy will slowly die regardless.
@GiorgiaMeloni take note!

Be Like Poland 🇵🇱

Community note
Poland has not introduced 0% income tax for families with two or more children; the proposal remains pending its first reading in parliament. sejm.gov.pl/sejm10.nsf/Prz… pit.pl/aktualnosci/ze…
4
1
15
826
May 1
Numo just passed 30,000 rare long tail submissions!
these are worth their weight in gold for AI models.
more languages and task types coming soon!
13
8
56
1,398
Apr 30
Numo submissions 5x'd since this tweet! 🔥
And just with 4 languages, on web, in early access.
more tasks, more languages and silky smooth native mobile apps coming very soon!
Apr 29

Holy f
Numo only launched a couple hours ago and already received thousands of submissions from around the world.
Mind you these are all languages massively underrepresented in AI models (<0.1%).
Wow 🔥
9
4
32
863
Apr 29
Holy f
Numo only launched a couple hours ago and already received thousands of submissions from around the world.
Mind you these are all languages massively underrepresented in AI models (<0.1%).
Wow 🔥
3
4
21
1,614
Apr 29
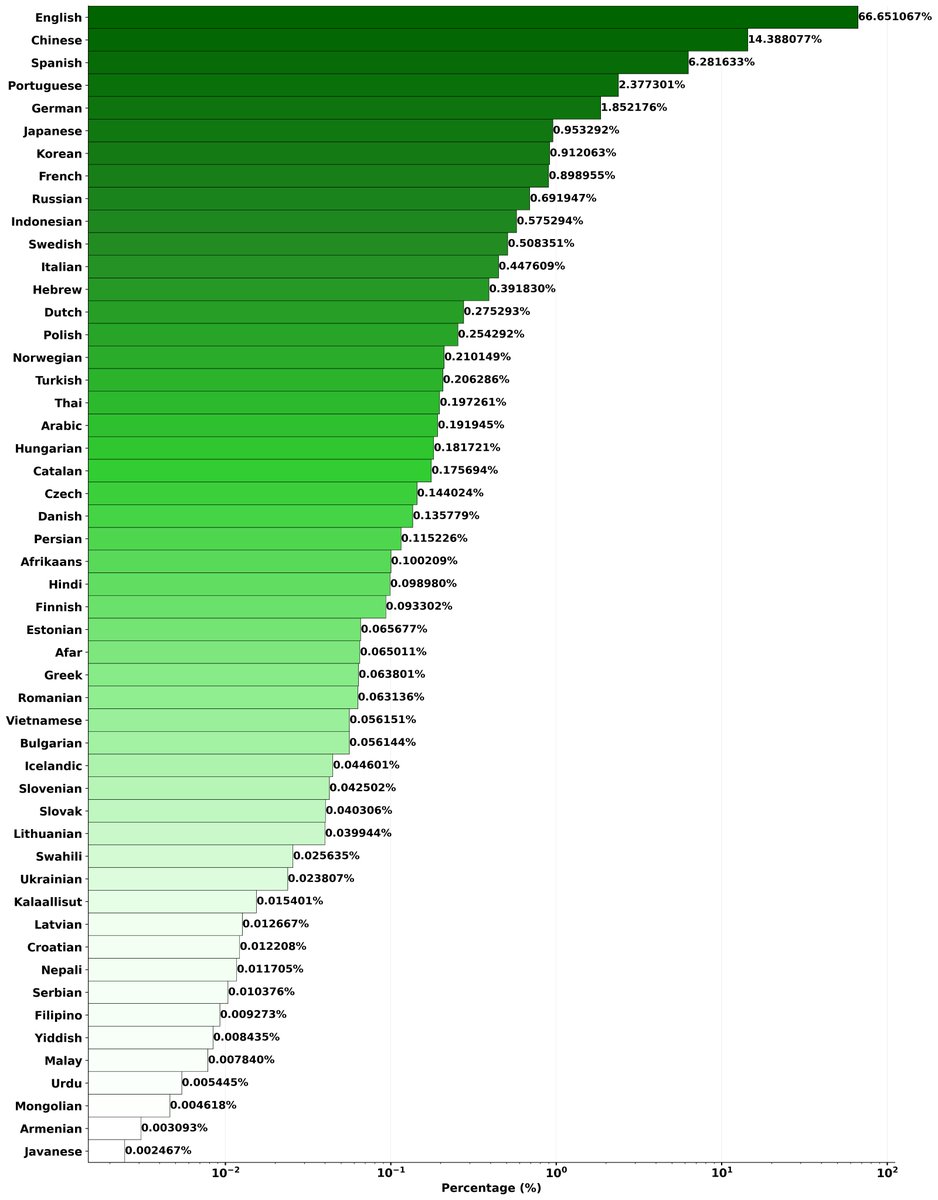
AI training data has a massive problem.
The chart below shows language distribution from the latest Microsoft VibeVoice model, in actual linear scale.
do you see the problem?
the languages representation is embarrassingly bad.
e.g. Hindi has <0.099%, but 600M ppl speak it worldwide.
e.g. arabic sits at 0.19%... yet it's spoken by 400M people across 25 countries and is one of the UN's six official languages.
e.g. japanese is dead last on the chart at 0.002% — but ~80M people speak it. that's more native speakers than german, which gets 1.85% on this same chart.
so german is roughly 750x more represented than japanese.
e.g. bengali, the world's 6th most-spoken language with 270M speakers, doesn't appear on the chart at all!
That is now changing.
Numo is sourcing high quality, long tail data, starting with voice recordings like hindi and bengali, for better AI training that the whole world can benefit from.
every contribution on Numo is fully licensed, attributed and IP safe thanks to Story. Full data transparency.
11
11
58
3,474
Apr 29
today we announce Numo in early access.
voice is the definitive interface for AI (and we are already seeing it with the massive adoption of apps like whisprflow).
but today's voice systems barely work for the billion people who speak underrepresented languages in AI models.
thats why Numo debuts with tasks in bengali, hindi, tamil, telugu... hundreds of millions speak them, but the training data just isn't there compared to the “usual” languages like english, mandarin, spanish etc.
numo fixes the long tail supply side for voices, with plans to expand into other modalities real-world AI needs.
rights-cleared from the first second, all confidentially registered on story, processed through poseidon.
many more tasks to come.
10
5
47
2,200