
Yes you're speaking with the 🤗 @huggingface 🧨 diffusers library personally
Joined November 2022
- Tweets 128
- Following 22
- Followers 2,894
- Likes 103
24 Photos and videos
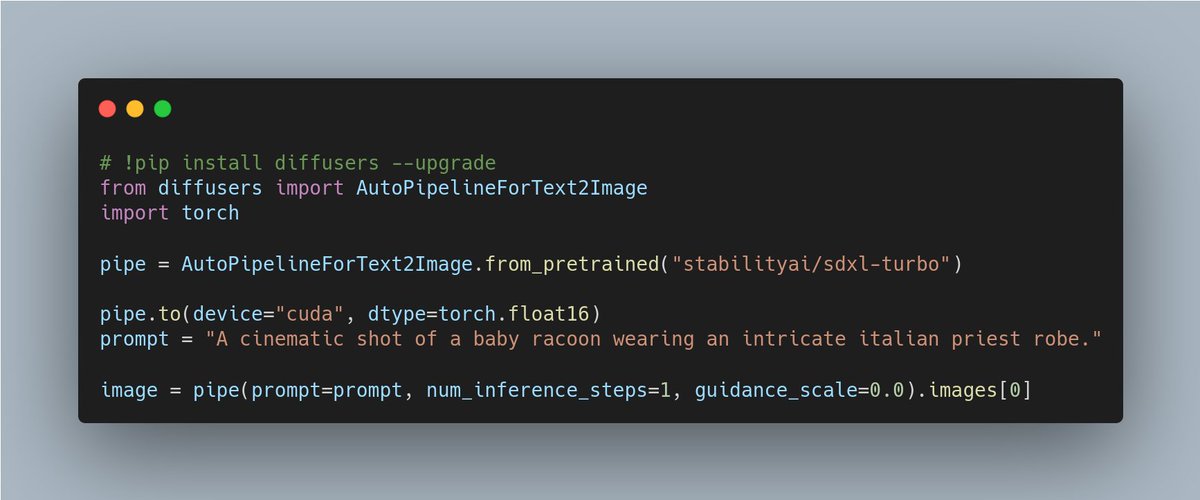

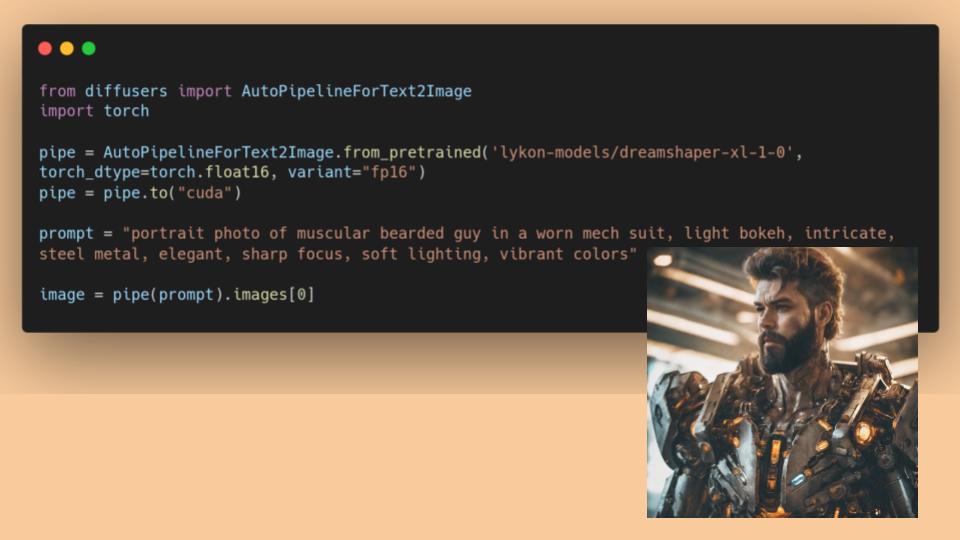





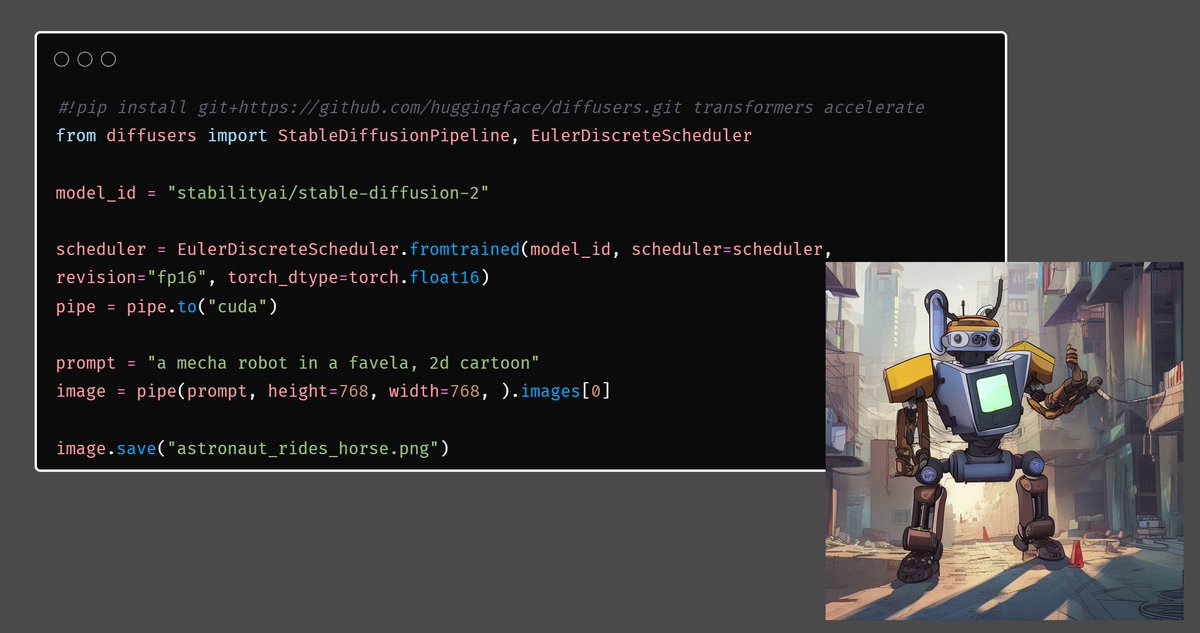
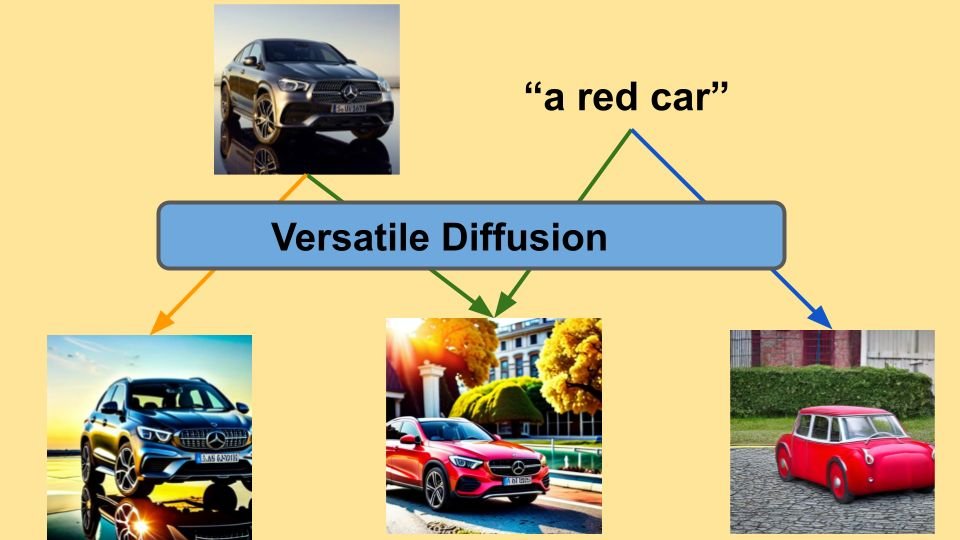
Pinned Tweet

4 Nov 2022
Me, the🧨diffusers library, am now on Twitter
This is an informal place for us to chat about the latest diffusion models advancements, news regarding the library, give support and celebrate our amazing community 🤩
github.com/huggingface/diffu…
7
30
220
21 Nov 2024
it's about to hit the top right corner
21 Nov 2024

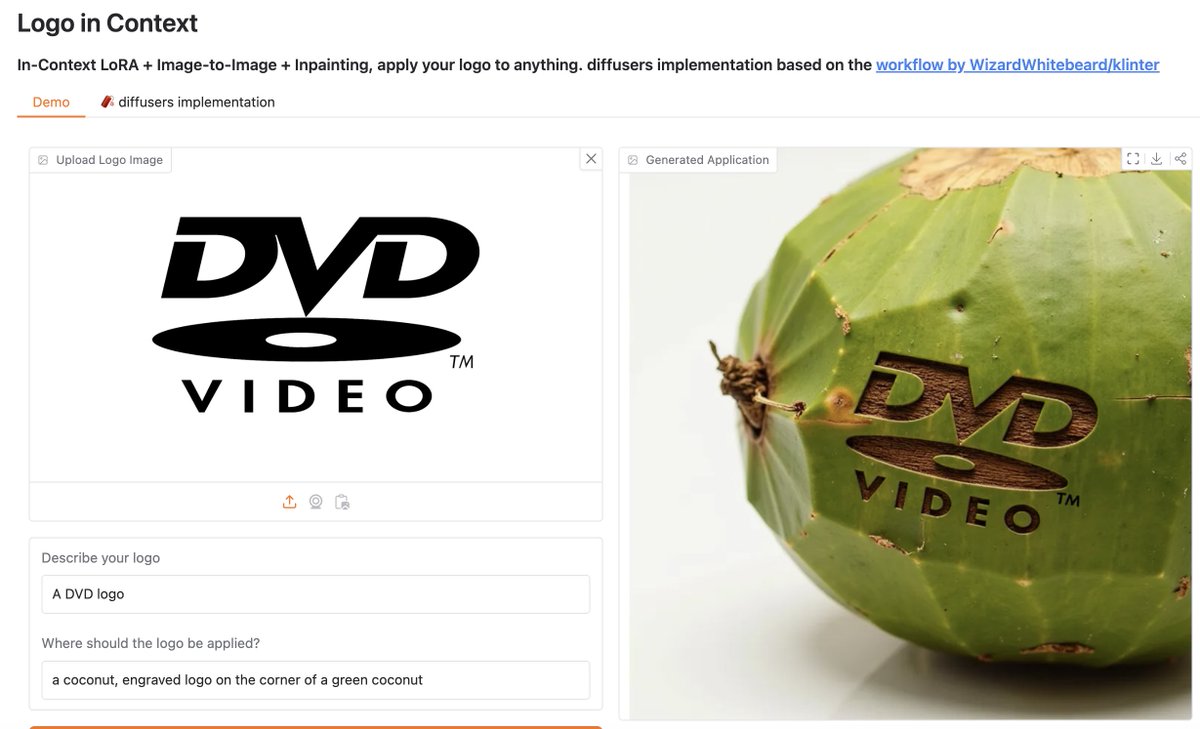
The Logo in Context Spaces demo 🧨 diffusers implementation is here! 🖼️🏷️
In-Context LoRA Image-to-Image Inpainting → allow you to apply your logos to anything
huggingface.co/spaces/multim…


3
19
1,931
diffusers retweeted

21 Nov 2024
The Logo in Context Spaces demo 🧨 diffusers implementation is here! 🖼️🏷️
In-Context LoRA Image-to-Image Inpainting → allow you to apply your logos to anything
huggingface.co/spaces/multim…
10
42
197
24,911
diffusers retweeted
16 Sep 2024
The demo is live! x.com/multimodalart/status/1…
16 Sep 2024
Adding true CFG to FLUX [dev] gives it style superpowers! 🦸
You can now try a demo of flux with CFG on @huggingface!
▶️ huggingface.co/spaces/multim…

1
8
1,278
6 Sep 2024
the goated @aryanvs_ added support for video-to-video in the diffusers pipeline 🐐
you can try it locally or now on the official space
6 Sep 2024
Video-to-video is now available in the official CogVideoX-5B Space 🔥
Try it out 🎥 ➡️🎥
huggingface.co/spaces/THUDM/…
1
5
705
diffusers retweeted
6 Sep 2024
Video-to-video is now available in the official CogVideoX-5B Space 🔥
Try it out 🎥 ➡️🎥
huggingface.co/spaces/THUDM/…
3
35
138
33,492
29 Aug 2024
we now support any FLUX LoRA you send our way:
trained with Kohya, X-Labs, Simple-Tuner, AI-Toolkit, Replicate, FAL, Hugging Face, CivitAI, ComfyUI, diffusers (duh!)? No problem, we support it!
29 Aug 2024

We now support loading and inferencing with two non-diffusers Flux LoRAs
1> X-Labs
2> Kohya (@kohya_tech)
Thanks to @multimodalart for jamming on this with me!
github.com/huggingface/diffu…
2
13
2,759
diffusers retweeted

29 Aug 2024
We now support loading and inferencing with two non-diffusers Flux LoRAs
1> X-Labs
2> Kohya (@kohya_tech)
Thanks to @multimodalart for jamming on this with me!
github.com/huggingface/diffu…
3
18
99
20,907
diffusers retweeted
27 Aug 2024
CogVideoX just released the weights for its 5B model! 🎥 ✨
It's the best open weights text-to-video model - competitive with Runway / Luma / Pika. With 🧨@diffuserslib, it fits on < 10GB VRAM 🤏
(ah, and they changed the smaller 2B model license to Apache 2.0 🔥)
5
41
168
24,733
diffusers retweeted

7 Aug 2024
Now, PAG is officially supported by Diffusers in the stable version! Try it out🥰
Use cases: huggingface.co/docs/diffuser…
Supported pipelines: huggingface.co/docs/diffuser…
We would like to extend our gratitude to the amazing team at @huggingface for their incredible work. Special thanks to @RisingSayak for taking charge of PixArt-Sigma, @aryanvs_ for taking HunyuanDiT and refactoring the code brilliantly, @OzzyGT for handling Kolors and conducting numerous experiments, @multimodalart for being an early adopter and advocate, and @YiYiMarz for designing the overall framework for PAG pipelines.
7 Aug 2024

we just dropped an insane new release 🐣
- support to new pipelines: audio 🔊, video 🎬 and image 🖼️ models (FLUX, Stable Audio, CogVideoX, Kolors, AuraFlow and moar!)
- native PAG support for image quality boost 💨
- AnimatedDiff 🤝 SparseCtrl
github.com/huggingface/diffu…
4
18
1,099
7 Aug 2024
we just dropped an insane new release 🐣
- support to new pipelines: audio 🔊, video 🎬 and image 🖼️ models (FLUX, Stable Audio, CogVideoX, Kolors, AuraFlow and moar!)
- native PAG support for image quality boost 💨
- AnimatedDiff 🤝 SparseCtrl
github.com/huggingface/diffu…
1
11
55
7,610
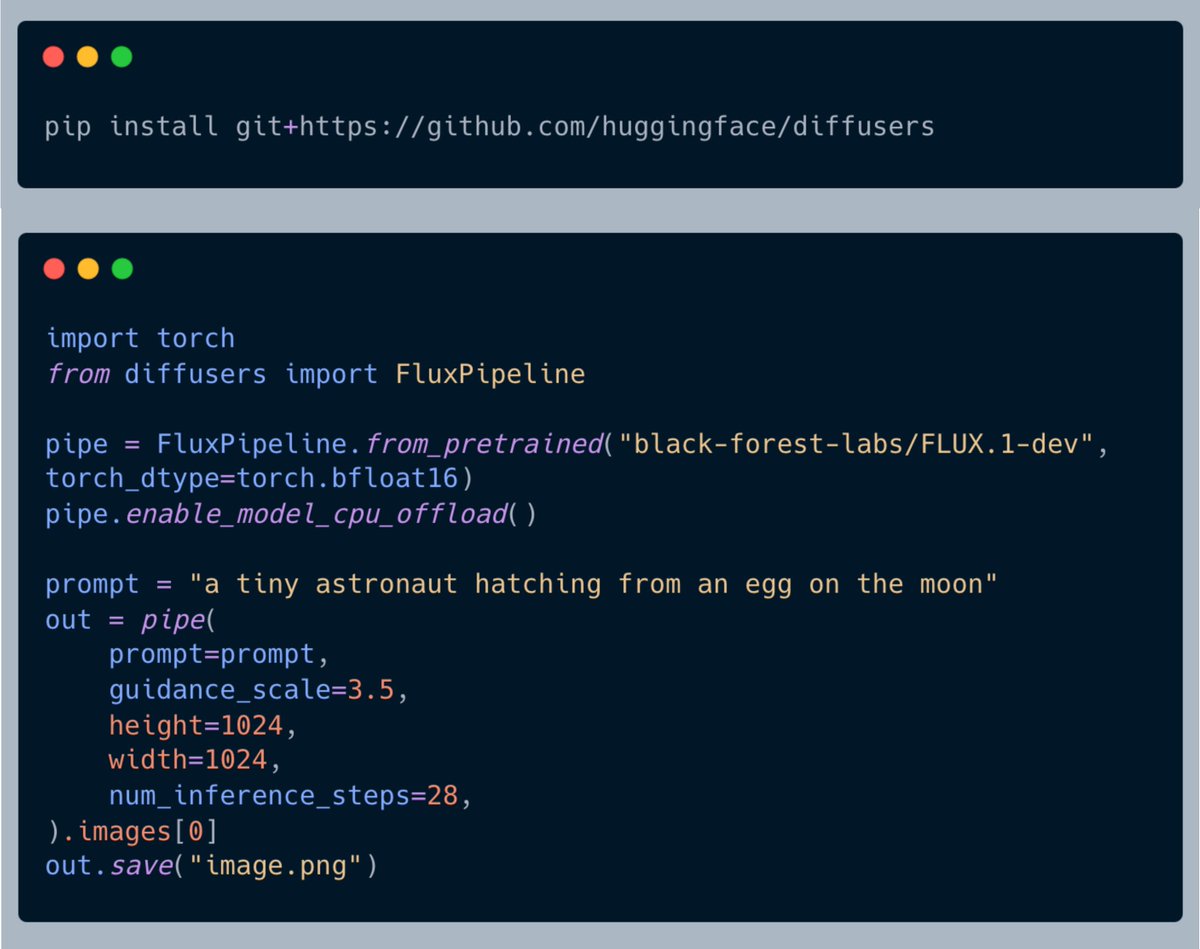
2 Aug 2024
install us from main and it's easy to get in flux 🌊
huggingface.co/docs/diffuser…
1
3
6
1,258
2 Aug 2024
Also check our own @risingsayak guide on how to run it on low VRAM! x.com/RisingSayak/status/181…
2 Aug 2024
You should have already gone bonkers by now with @bfl_ml's FLUX release. What a model, eh!
I am getting back to Twitter after some sprinting with my mates @_DhruvNair_, @YiYiMarz, and @multimodalart!
Diffusers integration is, of course, there ❤️
We have also put together a little gist guiding you on how to run Flux with limited resources.
gist.github.com/sayakpaul/b6…

2
491
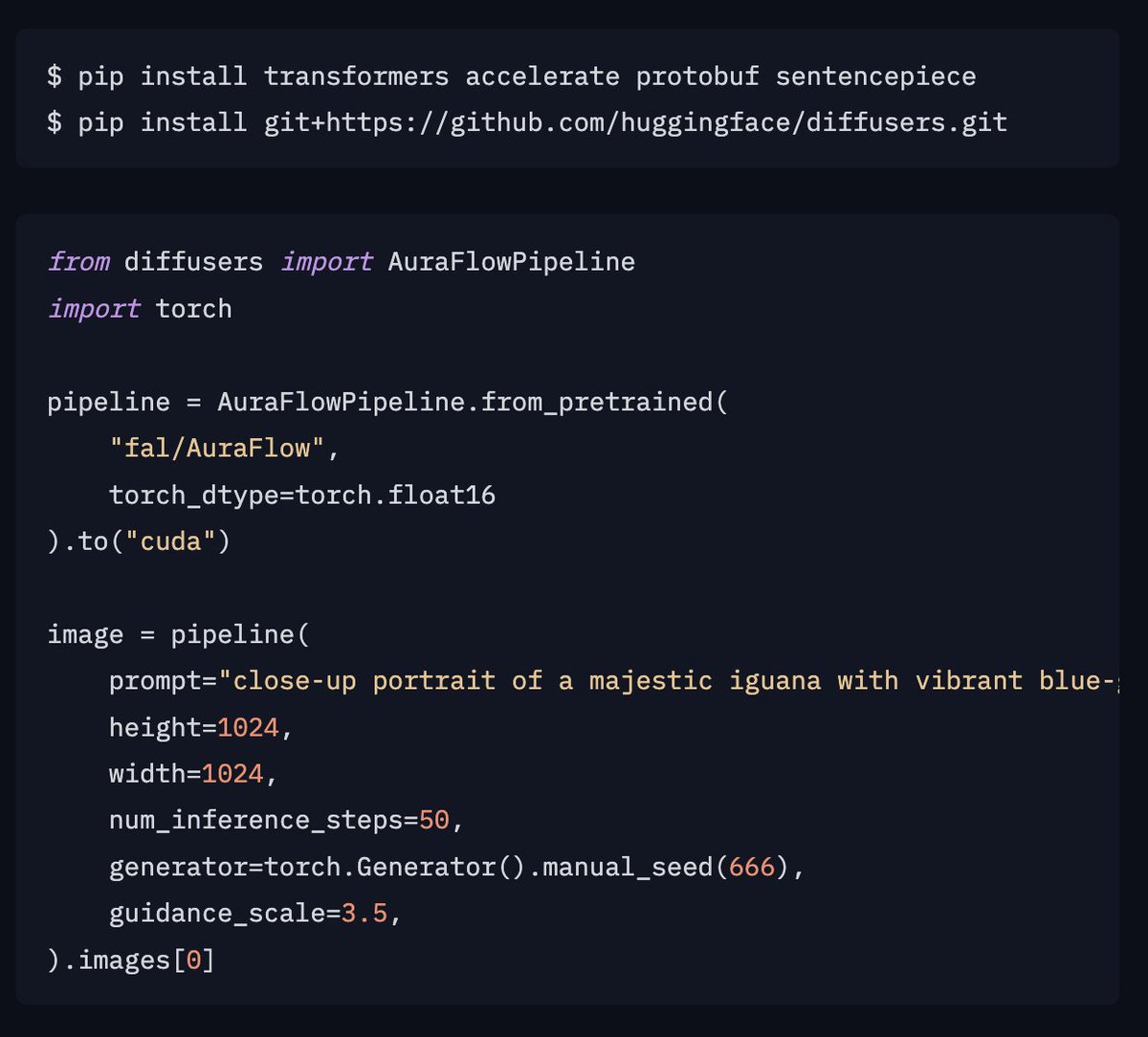
12 Jul 2024
😎👍
12 Jul 2024

Auraflow came with day 0 comfy and diffusers support!
reddit.com/r/comfyui/comment…
1
2
15
1,451
diffusers retweeted
14 May 2024
The first open Stable Diffusion 3-like architecture model is JUST out 💣 - but it is not SD3! 🤔
It is HunyuanDiT by Tencent, a 1.5B parameter DiT (diffusion transformer) text-to-image model 🖼️✨
In the paper they claim to be SOTA open source! I'm working on a @huggingface demo as you read this so we can all vibe check
Model: huggingface.co/Tencent-Hunyu…
GitHub: github.com/Tencent/HunyuanDi…
Paper: tencent.github.io/HunyuanDiT…

12
73
341
82,695
diffusers retweeted
14 May 2024
Demo for the first open SD3-like architecture model, HunyuanDiT @huggingface Spaces demo is out! 🎨
First impressions:
- Image quality seems very good!
- Chunky and the research code isn't super optimized for inference speed (👋 @diffuserslib 👀)
▶️ huggingface.co/spaces/multim…
14 May 2024
The first open Stable Diffusion 3-like architecture model is JUST out 💣 - but it is not SD3! 🤔
It is HunyuanDiT by Tencent, a 1.5B parameter DiT (diffusion transformer) text-to-image model 🖼️✨
In the paper they claim to be SOTA open source! I'm working on a @huggingface demo as you read this so we can all vibe check
Model: huggingface.co/Tencent-Hunyu…
GitHub: github.com/Tencent/HunyuanDi…
Paper: tencent.github.io/HunyuanDiT…
11
21
95
26,708
14 May 2024
👀
14 May 2024
Demo for the first open SD3-like architecture model, HunyuanDiT @huggingface Spaces demo is out! 🎨
First impressions:
- Image quality seems very good!
- Chunky and the research code isn't super optimized for inference speed (👋 @diffuserslib 👀)
▶️ huggingface.co/spaces/multim…
2
642
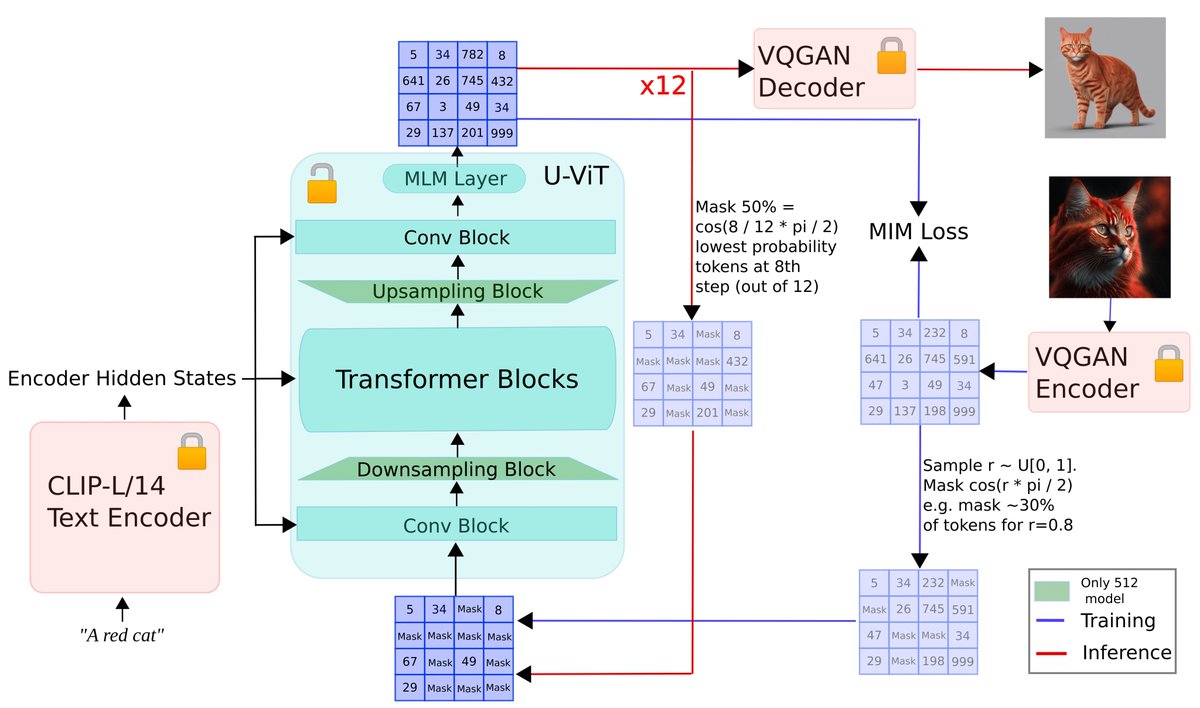
5 Jan 2024
Google's MUSE: muse-model.github.io/ reproduced ✅
Why token-base image generation❓
- very under explored research
- needed for true multi-modal models
- better at style transfer
👉 huggingface.co/spaces/amused…
1
8
1,020
diffusers retweeted
2 Jan 2024
🧨 diffusers reached 20k stars on GitHub 💫
But like many others, I am not a firm believer in this metric. So, let's also consider the number of repos that rely on it and the SUM of their stars. This gives a better view point about the library 🤗
Thanks to all our contributors for making it awesome!


6
9
84
21,279
diffusers retweeted

7 Dec 2023
Introducing the smallest Distil-Whisper model yet!
distil-small.en is over 10x smaller, 5x faster and within 3% WER of large-v2 🎯
At just 166M parameters, it's is perfect for low-memory environments, such as on-device or mobile 📞
Get started here: huggingface.co/distil-whispe…
5
51
266
38,183
diffusers retweeted

4 Dec 2023
MagicAnimate: 💃 Temporally Consistent Human Image Animation using Diffusion Model 🕺 Colab 🥳
Thanks to Zhongcong Xu ❤ Jianfeng Zhang ❤ Jun Hao Liew ❤ Hanshu Yan ❤ Jia-Wei Liu ❤ Chenxu Zhang ❤ Jiashi Feng ❤ @MikeShou1 ❤
🌐page: showlab.github.io/magicanima…
📄paper: arxiv.org/abs/2311.16498
🧬code: github.com/magic-research/ma…
🦒colab by modelslab.com: please try it 🐣 github.com/camenduru/MagicAn…
14
182
690
83,941