
AI/ML Scientist, mountain biker
Joined June 2013
- Tweets 119
- Following 592
- Followers 232
- Likes 199
21 Photos and videos
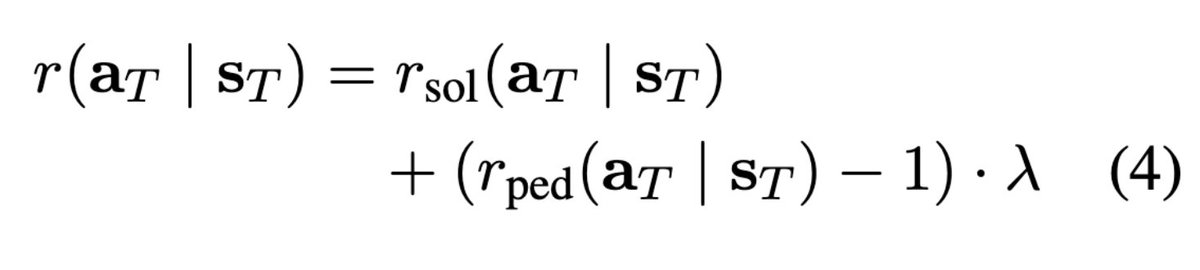

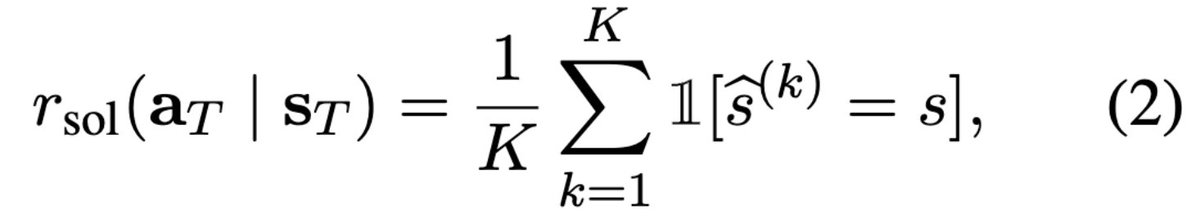










Jun 12
How can we build AI that thinks with us rather than for us, models that co-reason and act with humans across multiple turns, and how can they be used in education?
ethz.ch/en/news-and-events/e…
16
Mar 19
Happy to present my research later today at the National Institute of Informatics in Tokyo! #llm #research #education #reasoning
nii.ac.jp/en/event/2026/0319…
1
80
19 Sep 2025
🔍Thinking assistants instead of homework solvers. Most LLMs are helpful at the turn-level but lack planning for long-term student learning. How can we make LLMs more collaborative and better at tutoring?
#EMNLP2025
1
4
10
812
19 Sep 2025
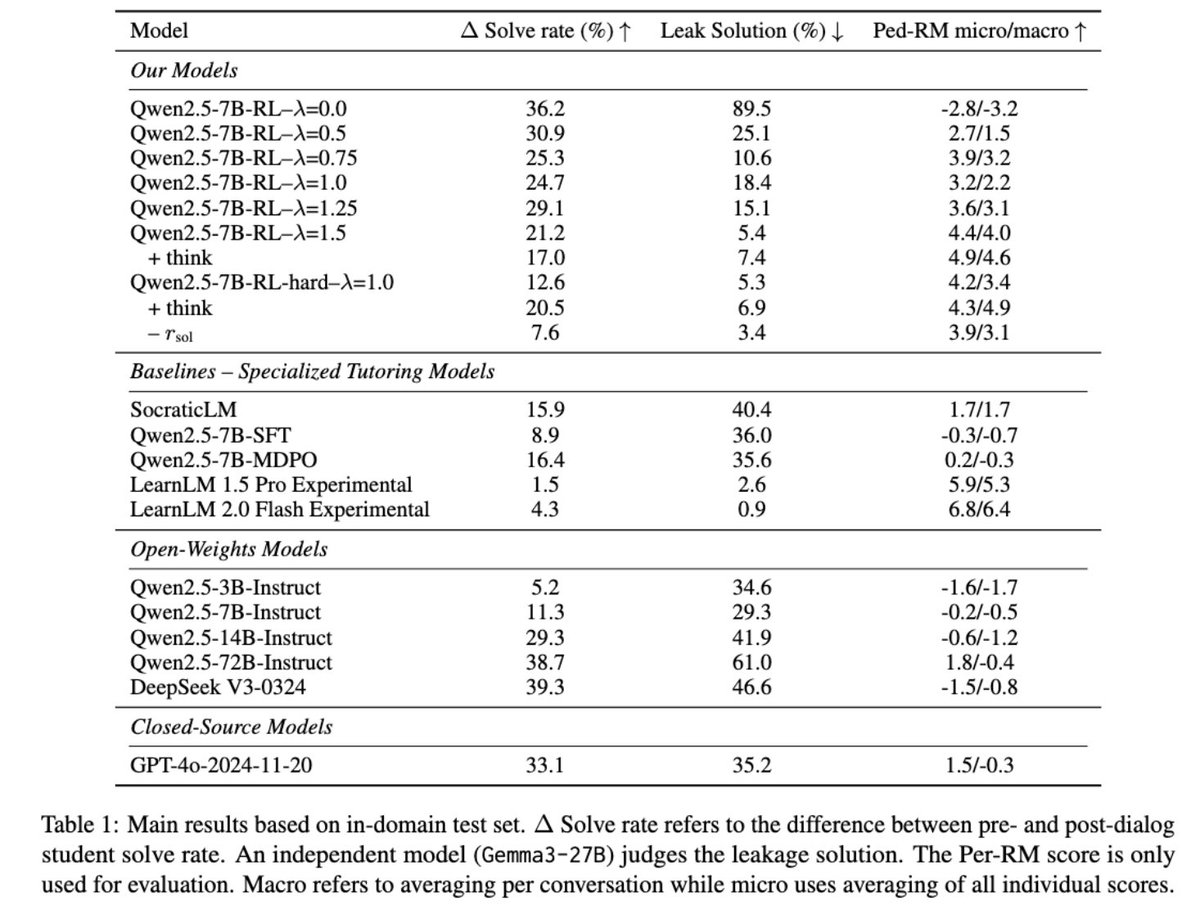
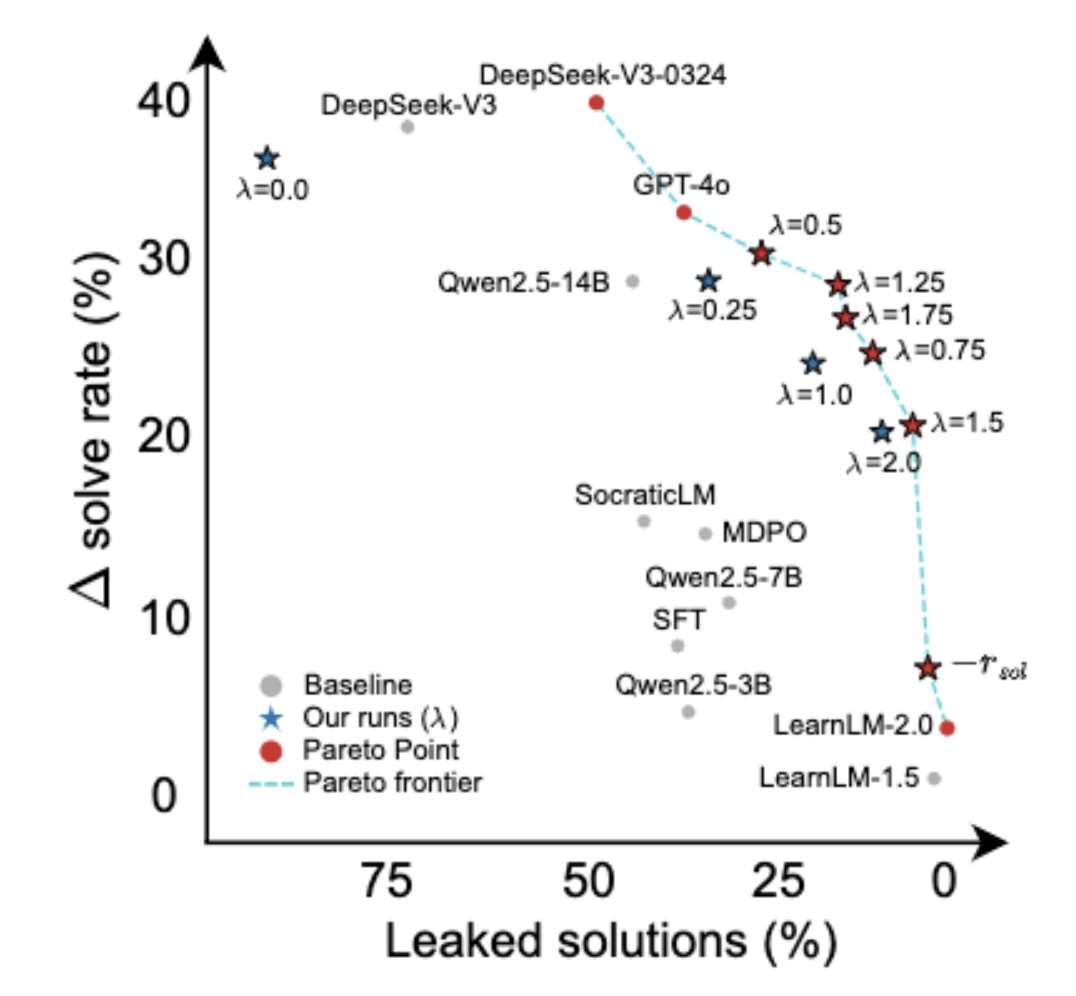
Altogether, this allows us to train smaller LLMs for tutoring that match or surpass the performance of larger specialized tutoring models while navigating a trade-off between leaking and student solve rate.
1
85
19 Sep 2025
📄 Paper: arxiv.org/abs/2505.15607
💻 Code: github.com/eth-lre/Pedagogic…
Model: huggingface.co/eth-nlped/Tut…
@DavidDinucu @ndaheim_ @idohakimi @IGurevych @mrinmayasachan
Learn now with our open-source tutor directly on your laptop: ollama run hf.co/dmacjam/TutorRL-7B-thi…
1
147
4 Sep 2025
Try out Apertus, a truly open-source model from ETH Zurich and EPFL.

🚀 Together with ETH Zürich and the CSCS, we have just released Apertus, 🇨🇭 Switzerland’s first large-scale, open, multilingual language model — a milestone in generative AI for transparency and diversity.
Find out more: go.epfl.ch/a672aa
5
322
30 Jul 2025
Join us tomorrow morning #ACL2025NLP #ACL2025
30 Jul 2025

If you're at ACL, join us for the tutorial "LLMs for Education: Understanding the Needs of Stakeholders, Current Capabilities and the Path Forward" at the BEA workshop (Room 1.85–86) 9:00-12:30am tomorrow (July 31st) @aclmeeting
1
2
7
566
8 Jun 2025
AI alignment for tutoring🎓 We use full online RL with conversation-level rewards—not just single-turn signals like DPO. Did the student actually learn by the end?
Using GRPO, the model learns real teaching strategies like when to hint or when to correct.
Explore models below⤵️
25 May 2025

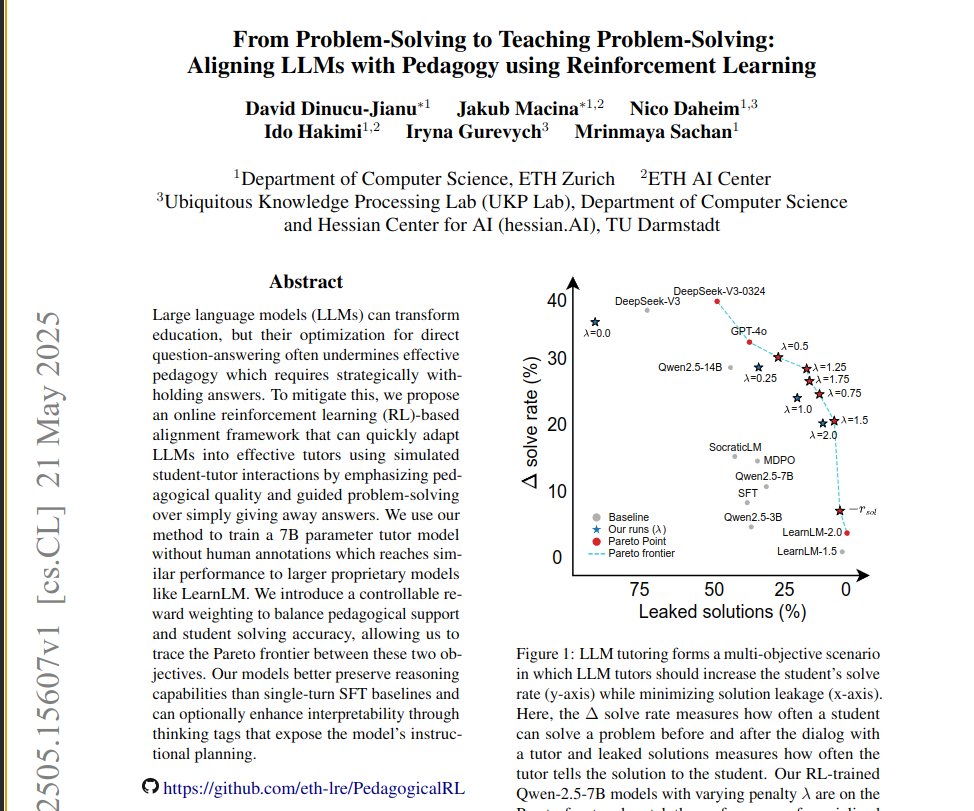
This paper introduces an online reinforcement learning framework using simulated student-tutor interactions.
It trains LLMs to prioritize guiding students pedagogically instead of simply revealing solutions, aligning models with better teaching methods.
This helps students learn how to solve problems independently.
Methods 🔧:
→ The online reinforcement learning method trains the tutor model directly on conversations simulated with a separate student LLM.
→ A custom reward function scores full conversations based on two objectives: increasing the student's success rate after the dialog and ensuring the tutor follows good pedagogical principles.
→ This reward system penalizes the tutor for leaking solutions, promoting guided problem-solving.
→ The framework uses LLM judges to evaluate pedagogical quality.
→ Controllable reward weighting balances these objectives, enabling navigation of the trade-off between student solving gains and pedagogical support.
→ Thinking tags are included to enhance the tutor model's interpretability and instructional planning.
📌 Online Reinforcement Learning using model rollouts directly trains on interactive teaching, avoiding static data limitations.
📌 Reward function lambda explicitly controls the crucial pedagogy versus student success trade-off.
📌 Preservation of reasoning benchmarks demonstrates RL's superior transferability compared to Supervised Fine-Tuning baselines.
----------------------------
Paper - arxiv. org/abs/2505.15607
Paper Title: "From Problem-Solving to Teaching Problem-Solving: Aligning LLMs with Pedagogy using Reinforcement Learning"
1
3
12
1,625
8 Jun 2025
TutorRL-7B-think: huggingface.co/eth-nlped/Tut…
TutorRL-7B: huggingface.co/eth-nlped/Tut…
Github: github.com/eth-lre/Pedagogic…
1
2
101
4 Mar 2025
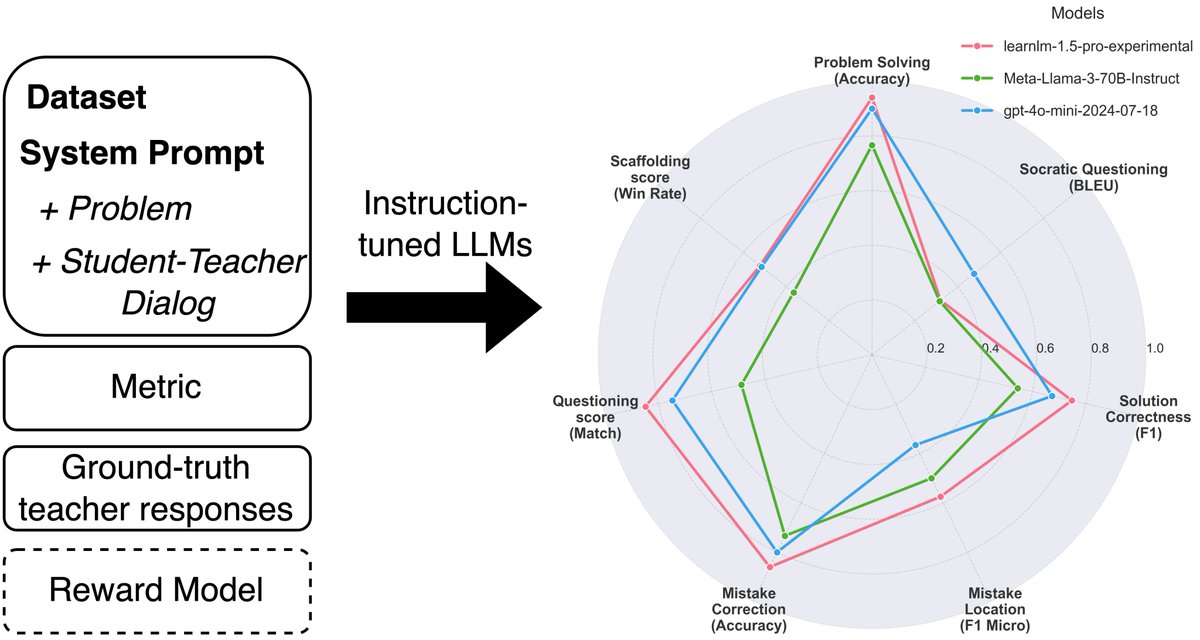
🚀 𝐇𝐨𝐰 𝐰𝐞𝐥𝐥 𝐜𝐚𝐧 𝐋𝐋𝐌𝐬 𝐭𝐞𝐚𝐜𝐡?
Evaluating LLMs for education is key to making real progress, yet we lack a reliable and simple benchmark. Introducing 𝐌𝐚𝐭𝐡𝐓𝐮𝐭𝐨𝐫𝐁𝐞𝐧𝐜𝐡—an open-source benchmark designed to assess holistic tutoring capabilities in AI.
4
3
8
1,019
4 Mar 2025
🔥 Try it now!
Run MathTutorBench locally with your own models or submit them to our leaderboard. Open-source! 👉eth-lre.github.io/mathtutorb…
@ndaheim_ @idohakimi @ Manu Kapur @IGurevych @mrinmayasachan @ETH_AI_Center
4
163
4 Mar 2025
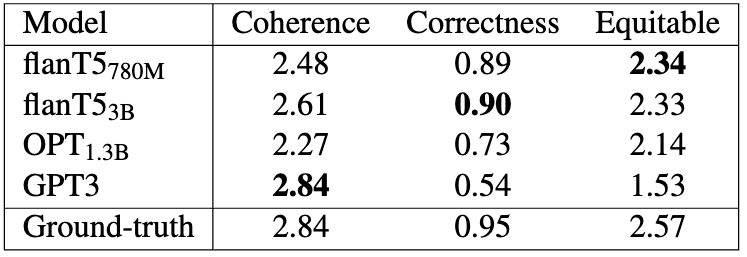
🤔 𝐌𝐨𝐫𝐞 𝐤𝐧𝐨𝐰𝐥𝐞𝐝𝐠𝐞 ≠ 𝐛𝐞𝐭𝐭𝐞𝐫 𝐭𝐞𝐚𝐜𝐡𝐢𝐧𝐠?
Subject expertise does not always correlate with effective teaching; instead, pedagogy and subject knowledge may present a trade-off.
3
97