
consulting companies in applied ai | doing maths in my free time
Joined November 2018
- Tweets 5,314
- Following 465
- Followers 15,169
- Likes 25,636
506 Photos and videos










Pinned Tweet

6 Oct 2024
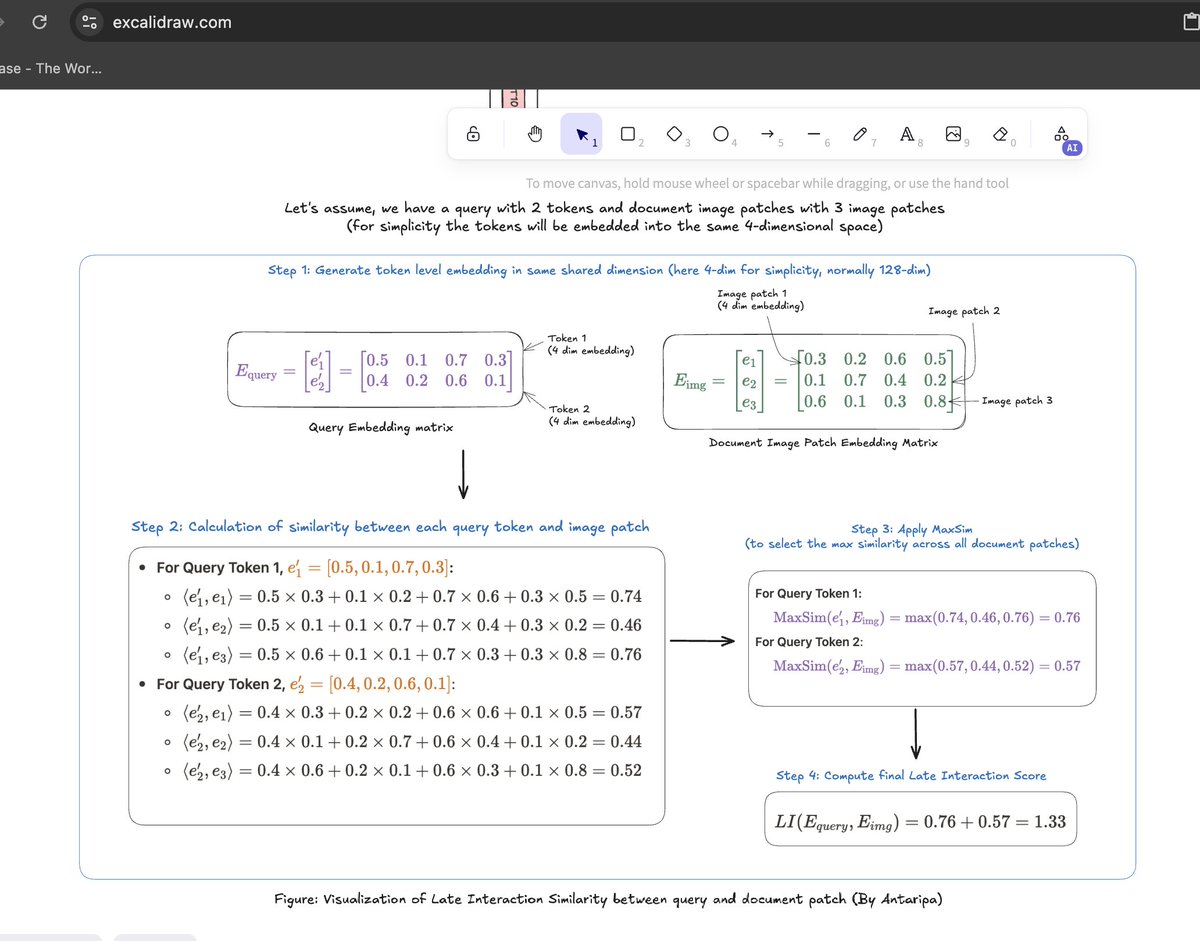
tried going as much in detail as possible for the Colpali blog, it will be a long read
antaripasaha.notion.site/Col…

22
74
677
212,081
Antaripa Saha retweeted

Jun 11
Whether you are GPU poor or GPU rich, today's release of PyLate has something for you!
GPU maxxers: MaxSim kernels greatly speed up training while lowering the memory requirements
CPU enjoyers: TACHIOM enables lightning fast multi-vector indexing and search directly on CPU

3
27
123
10,881
Antaripa Saha retweeted

Jun 10
Very excited to release late-interaction-kernels (LIK): fused Triton kernels for MaxSim, the scoring step behind ColBERT, ColPali & LateOn. 🚀
Numerically equivalent to PyTorch at a fraction of the memory, with day-0 support in PyLate & colpali-engine. (1/N 🧵)
6
11
64
8,218
Antaripa Saha retweeted

Jun 5

Jun 4

One of the most interesting papers of the last ~2 years in IR only has 8 citations.
5
9
72
7,118
the kind of exciting research work perplexity has been doing is amazing to see
will be diving in for understanding this better
Jun 1

Introducing Search as Code, our new search architecture for AI agents.
It writes Python that calls our search stack directly, instead of looping through function calls one at a time.
Available in the Perplexity Agent API, and now default in Computer.
research.perplexity.ai/artic…

1
11
1,756
May 19
super cool work by @tomaarsen
very excited to see how it’s extending the work done by lighton with modernbert and mixedbread with their latest release of pointwise rerankers
the results already look promising with just 17M model
open-source is the way to go🤝
May 19

🤗 Announcing the Ettin Reranker family: six new CrossEncoder rerankers from 17M to 1B parameters, state-of-the-art at their respective sizes.
Built on the Ettin ModernBERT encoders, with the full training recipe and ~143M-triple training dataset as well.
🧵

8
648


Antaripa Saha retweeted
Apr 21
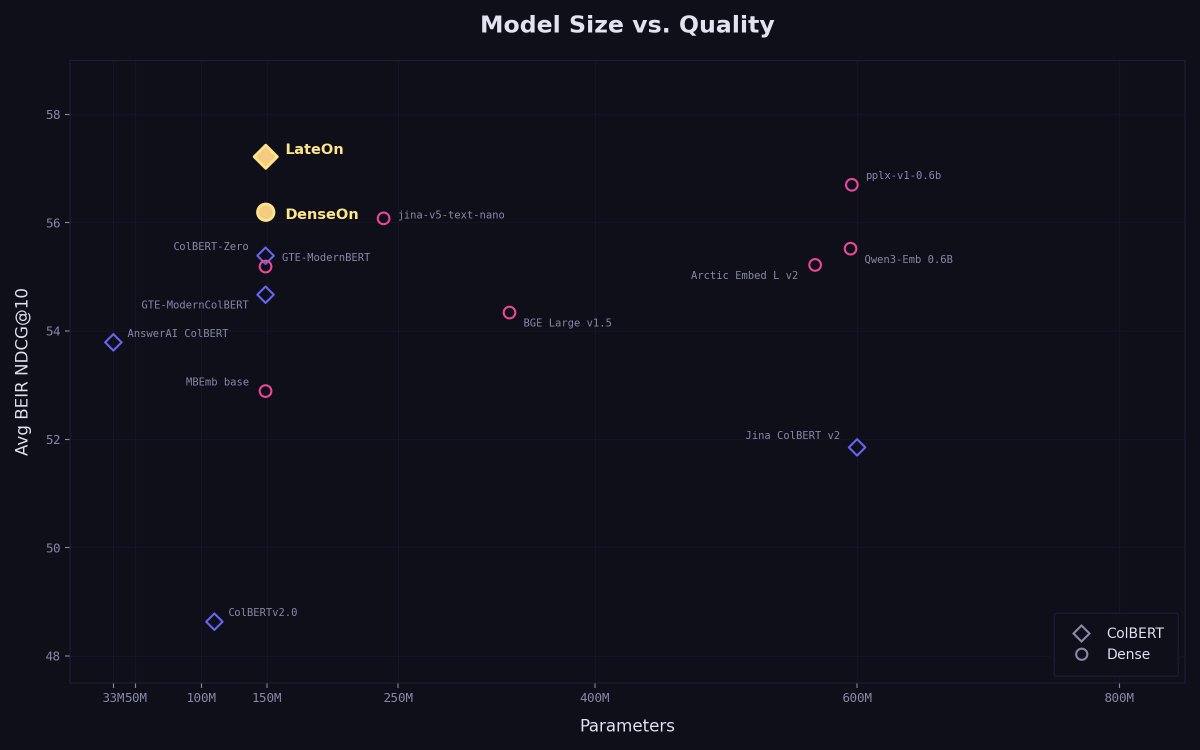
The new generation of open state-of-the-art single and multi-vector retrieval models is here
It's time, DenseOn with the LateOn 🎶
@LightOnIO releases models that leap past existing ones, and everything you need to do the same!
13
52
224
39,928
Mar 24
not sure what type of marketing was this but all the people who went crazy after the blogpost, quote tweeted and stuff and behaved like this is next level breakthrough. now you know they don’t understand shit about memory and are sloppy ai writers who just quote tweets on anything and everything

15
9
195
24,917
highly agreed
droid is by far the best agent out there. having been using for the past 5-6 months and won’t switch anytime soon

Droid is the best agent harness based on outcomes, closely followed by Codex. I have stopped using everything else, mostly except for a few one offs.
I would highly recommend trying it out with BYOK VibeProxy github.com/automazeio/vibepr…
You can use all your subs in there

7
934
Feb 25
in blr after almost a year. will be here for 4-5 days ;)
2
21
1,270
Feb 11
i see lot of flaws in this approach
how maintaining a continuously compressed memory inside the context window work in real-world cases?
this is basically optimizing for achieveing sota in benchmark
say if the compression policy go wrong, or the observer misjudged importance, how to recover the original context?
keeping everything in a context means the model always pays the cognitive cost of reading the whole observation block. even if compressed, 40k tokens of observations is not less. for agents running continuously for weeks, that grows heavy. and moreover why to spend so much unnecessary tokens in the first place when retrieval systems can handle those nuances better.

13
1,209
people are eventually catching up on RLM

Recursive Language Models (RLMs) let agents manage 10M tokens by delegating tasks recursively.
This Google Cloud Community Article explains why ADK was the perfect choice for re-implementing the original RLM codebase in a more enterprise-ready format →goo.gle/4kjT12E

4
65
8,128
very cool implementation around self-coordinated agents. as nico mentioned, the agents broadcast the files they plan to work on upfront, which helps reduce wasted parallel work.
the next step from here is to push this further with scoped reservations, auto-resolution when agents collide, and better evals around whether this actually reduces conflicts.
this is similar to what claude code released yesterday with agent teams but open-sourced and more explicit. love this community!
Feb 5

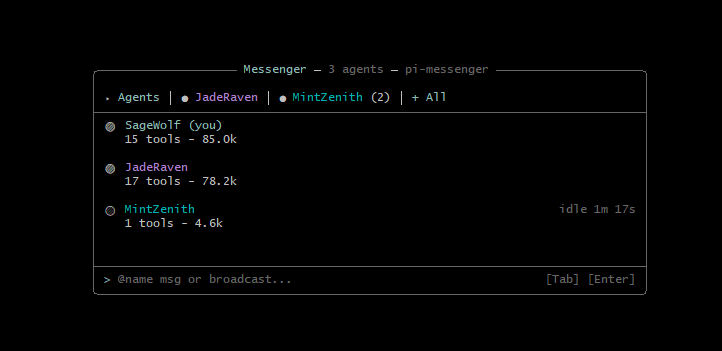
New Pi extension: pi-messenger. What if Pi agents could talk to each other like in a chat room? They can join the chat, see who's online, reserve files, message in real-time, whether they're in separate terminals or subagents.
Just throw a PRD at it and it breaks your plan into a dependency graph, then fans out parallel workers to execute tasks in waves. You watch agents coordinate in a shared overlay while they ship your feature.
pi install npm:pi-messenger
github.com/nicobailon/pi-mes…
7
1,050
Antaripa Saha retweeted
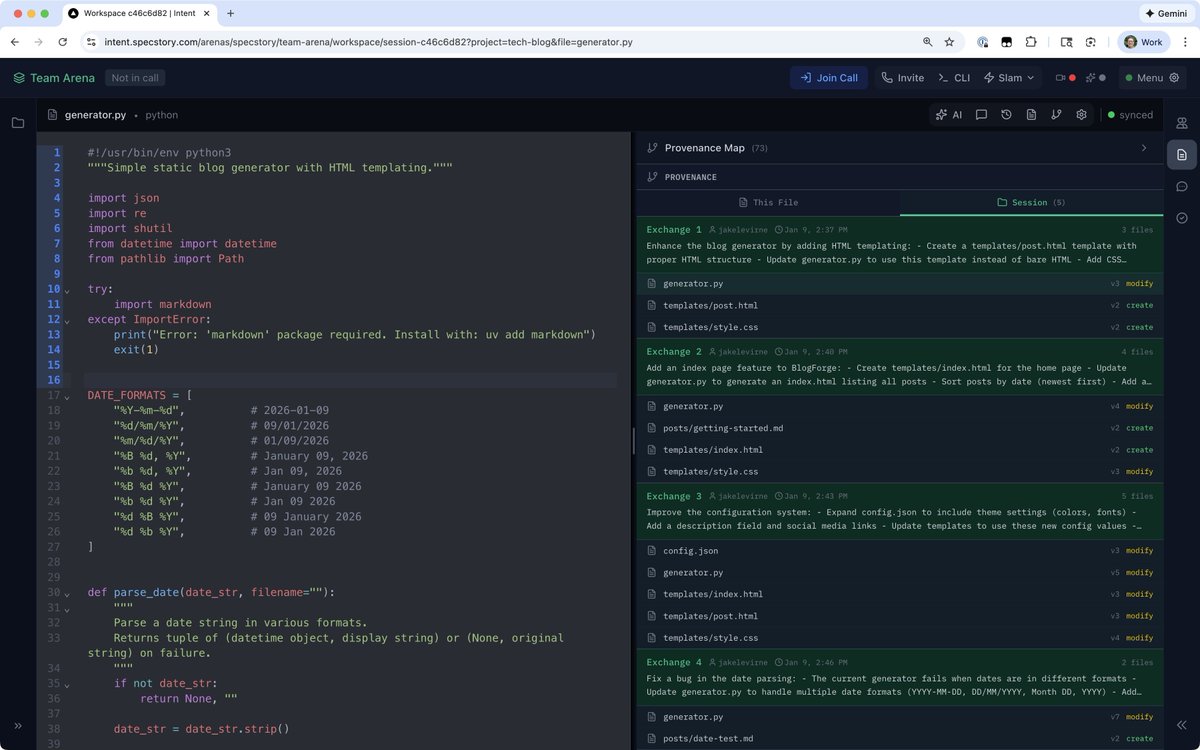
during our user calls we also came to similar conclusion. this is a big pain for lots of teams who move fast. the specstory team has been putting a lot of thoughts and work around the same to have a properly designed flow to have better provenance and a way to map code to prompts and intent directly but in a digestable way without overwhelming the reviewers. let's see.
1
1
10
746
we are living in a x bubble i believe
a lot of my friends at big product companies and mncs (as swe/sde) have never even heard of codex, haven’t tried claude code, and agents like droid or opencode aren’t even in question.
most haven't tried those tools personally either because for them spending 20$ out of their pocket for a work tool is not worthwhile.
even where copilot or some unheard ide tool is allowed, it is usually used as an autocomplete or "ask a question" assistant. very few large firms have adapted to running long-lived coding agents, giving access to the agents execute tests, run scripts, or modify repos autonomously.
it will atleast take more 1-2 years for the firms to accept the reality and figure out how to adopt the changes in the domain while addressing security and data concerns.
Feb 4

i don't think people understand how many companies and firms still don't even have chatgpt provisioned for all their employees
their IT/sec teams are still thinking through "data privacy", 3 years later. this is what i mean by the lack of urgency
we are in an X bubble where people are delegating their entire lives to AI
7
3
40
3,716
my analysis in the past 1 year has been currently consultants, agency owners, and course makers are printing money and probably even more than product startups or so.

ycombinator request for startups came out and this one caught my eye
there is no better time to start an agency, you have a 1-2 head start to sell services using AI to arbitrage your time and input
one of our agencies recently built a landing page for a biotech company for 10K, built in 2 days via cursor
14
1,145
was discussing this internally with the team how each agent has their own folder directory for skills and how it was becoming super hard to handle
great to see such efforts taken by openai team around standardization and seems like @opencode too adopted this quickly. kudos!
Feb 2

📣 Open call to agent builders: Let's read agent skills from `.agents/skills`, so people don't have to manage separate folders per agent.
Today we pulled the trigger for Codex to read `.agents/skills`. Goal is to deprecate `.codex/skills`.
Pls like/tag/RT for momentum.
7
975
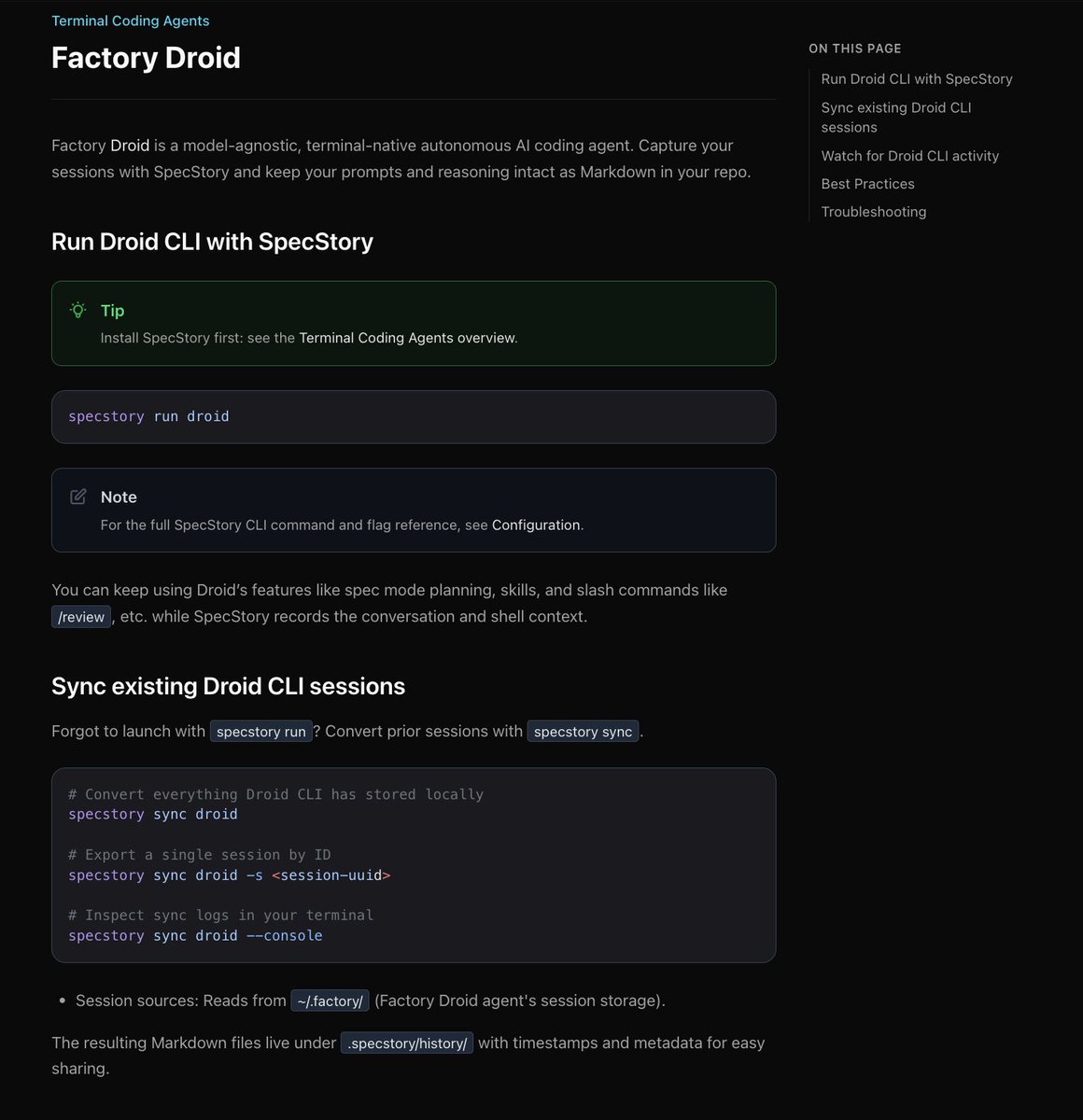
everyone knows how much i like @FactoryAI droid. the context handling, model management, and harness just works the best in droid
@specstoryai cli now supports droid :D
you can save all your droid sessions, context, and reasoning through specstory as markdown files in your local
i use droid as my main driver among coding agents, so pretty excited about this release.
1
2
7
1,199