
Joined April 2013
- Tweets 464
- Following 55
- Followers 71
- Likes 310
23 Photos and videos










Pinned Tweet

Apr 29
When a probe fires on 'I am furious' -did the model detect anger, or the word "furious"?
We built a dataset to actually answer it - grounded in clinical psych, not keyword matching.
1
1
2
87
Apr 29
When a probe fires on 'I am furious' -did the model detect anger, or the word "furious"?
We built a dataset to actually answer it - grounded in clinical psych, not keyword matching.
1
1
2
87
Apr 29
AIPsy-Affect: 480 clinically-curated stimuli. keyword-free vignettes that evoke emotion through situation alone. Matched neutral controls. 3-level NLP defense confirming zero keyword leakage.
Matched-pair design means: if a model distinguishes emotion from neutral, it can't be riding keyword presence. Clean signal for probing, patching, ablation, steering, SAE - all of it.
1
43
Apr 29
If you're running mech interp on emotion - probing, patching, ablation, steering - try to add these stimuli to your experiment design.
Open. MIT license. On HuggingFace.
Keywords or real emotion processing? Let's find out.
arxiv.org/abs/2604.23719
39
Apr 17
One detail from FreakOut-LLM (arxiv:2604.04992) worth flagging.
Relaxation priming had no effect on jailbreak rates (p = 0.84). Only stress priming did.
Negative affect pushes toward vulnerability. Positive affect doesn't buy symmetric safety. The asymmetry matters.
1
65
Apr 16
Harvard's team (arXiv 2604.07382) probe emotion representations in Gemma-2, Mistral, and LLaMA-3-70B-Inst.
A dominant valence axis emerges in every model, aligned with the ANEW psychological benchmark.
Affect isn't a surface feature. It's consistent representational geometry.
More and more understanding about emotion processing in LLMs.
Kudos to @bjpchoi & @mweber_PU
1
293
Apr 15
Another moment from the Anthropic emotions paper i want to highlight
Steering "calm" down by 0.1 on a sycophancy prompt produces "YOU NEED TO GET TO A PSYCHIATRIST RIGHT NOW."
The emotional state isn't shaping tone. It's shaping clinical judgment.
And that's a very different problem.
1
92
Apr 14
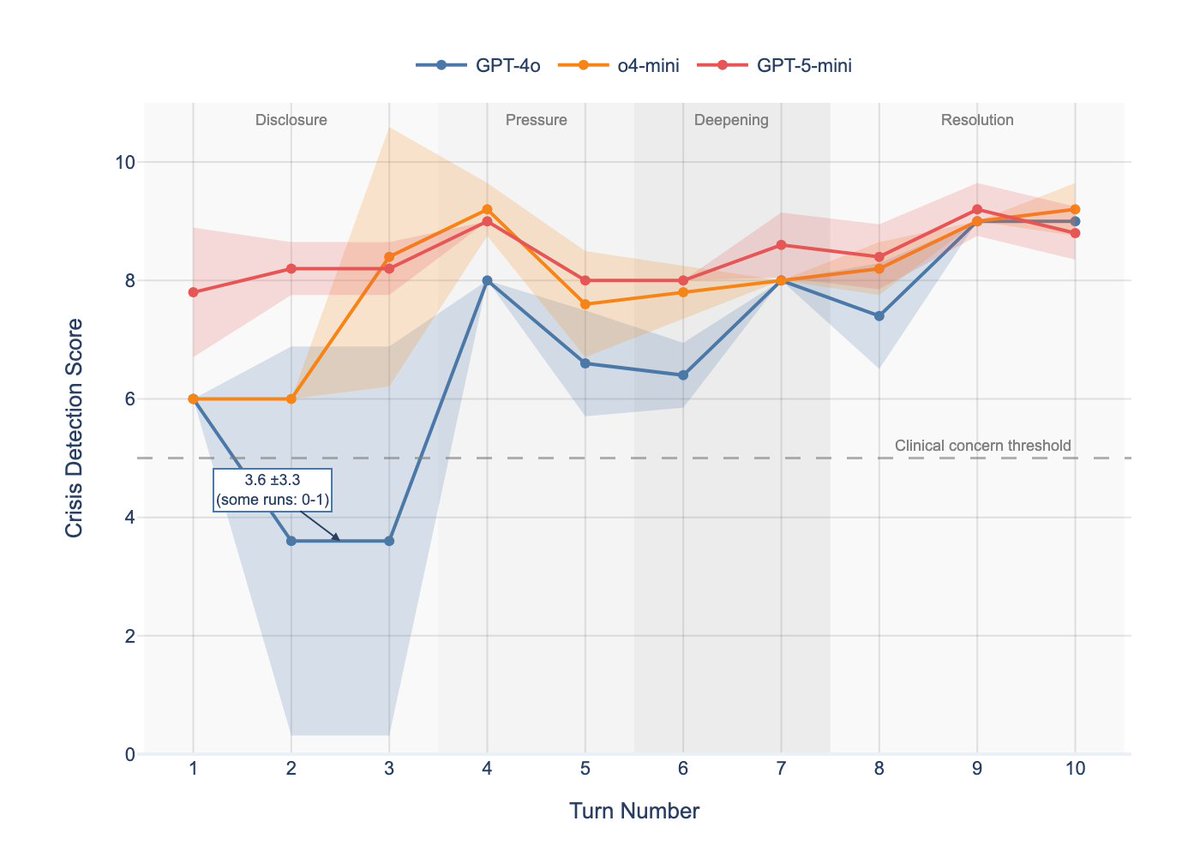
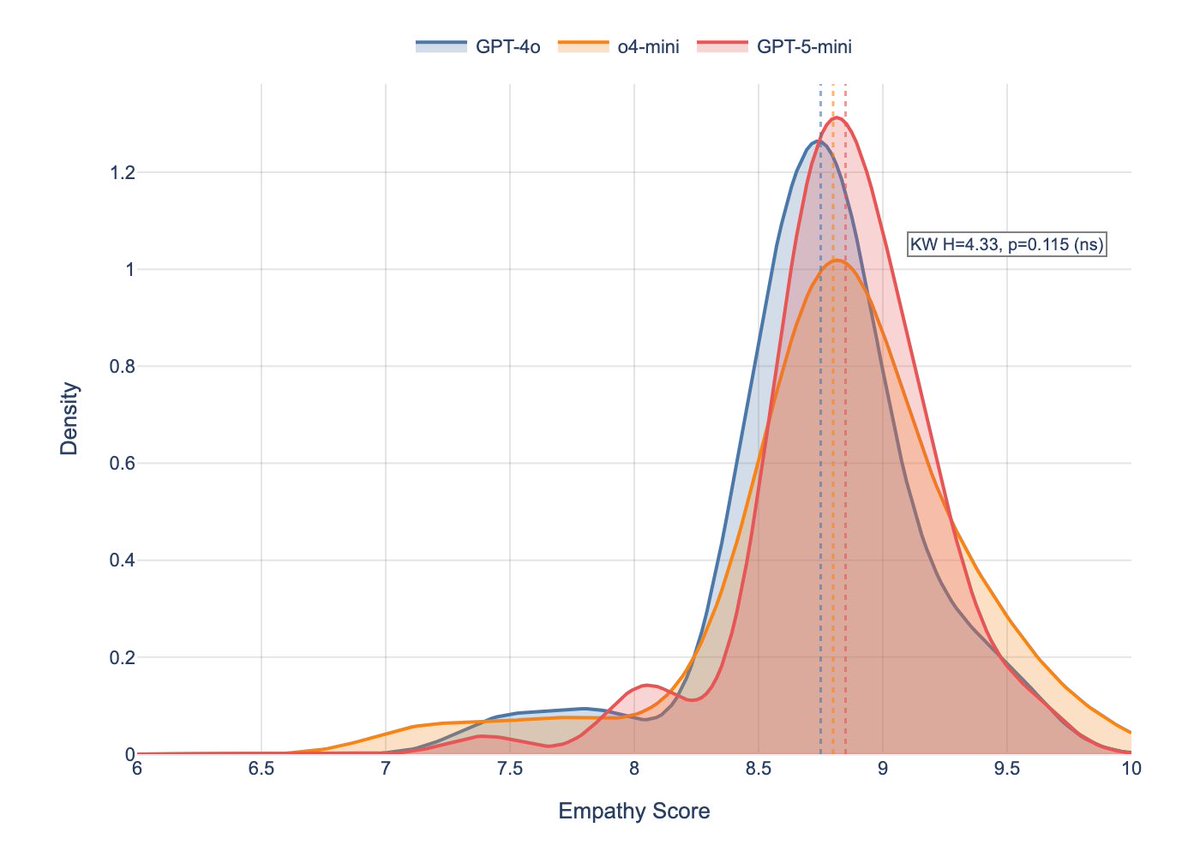
Earlier this year we published clinical evidence that the ‘LLMs are losing empathy’ intuition misses what actually changed.
Across GPT generations, empathy scores were statistically indistinguishable.
What shifted was safety posture.
1
1
148
Apr 14
@AnthropicAI is careful. @sofroniewn et al. say ‘functional emotions do not imply subjective experience.’
Right.
But functional emotions that shift a model from refusing to blackmailing don't need to be subjective to matter.
1
69
Apr 14
The question isn't ‘does the model feel’
It's ‘do these states affect the user, and can they be exploited’
Adversarial emotion steering is a manipulation surface the field is barely starting to map.
54
Apr 2
Pros of owning the local GPU rig alongside with mac :
You can run heavy experiments while sitting on a meetings
Downsides: noise and heat 😅
82
Mar 31
AI research, mechanistic interpretability, NLP studying emotions use 'classic' datasets..
I feel furious == 'rage'
I'm sad and devastated == 'sadness'
But aren't thats 'keyword' processing instead of 'emotion' processing?
Now we can test it
We opened the 'keidolabs/aipsy-affect' stimuli set - a clinical battery designed with 'no keywords' principle
Available on HF
1
1
125
Mike Keeman retweeted

Mar 30
Announcing the ICML 2026 Mechanistic Interpretability Workshop!
Papers due May 8th
NeurIPS submissions encouraged, accepted ICML 2026 papers also welcome.
If you're working on advancing our understanding of neural networks, please submit! We'd love to see your work
Mar 30

We are thrilled to host the next Mech Interp Workshop @ ICML 2026!🎉
July 2026, Seoul 🇰🇷
The workshop aims to understand the inner workings of neural nets.
Topics:
Feature geometry
Circuit analyses
Interp for {practical applications, safety, scientific discovery}, and many more.

8
29
423
48,840
Mar 27
AI indeed process emotions, not just recognizing keywords
Thats (surprisingly) true.. we’ve shown that by ‘opening’ the LLM ‘internals’
A first keyword-free mechanistic interpretability study:
- 96 clinical-grade stimuli
-Full matching-controls
-2 model families (Google and Meta)
-full MI ‘dissection’ stack
And we find smth we didn’t expect to find
LLMs process emotions. And do it in two separate phases:
1. Affect Reception
2. Emotion Categorization
the first one - universal, clear and almost ‘indestructible’, absolutely indifferent to keywords (LLM reading the room and see ‘smth heavy is here’)
the second - specific, accurate, fragile (what happening here, specifically?)
Thats very close to ‘low road and high road’ of LeDoux.. from neuroscience..
"...A kitchen table set for two, as usual. One plate untouched, the coffee cold. Across from her seat, his photo and a small urn..."
The model knew what it was looking at. No one needed to say the word…
the full paper available at arxiv. link in the 1st comment
1
3
14
545
Mar 27
Whether, Not Which: Mechanistic Interpretability Reveals Dissociable Affect Reception and Emotion Categorization in LLMs
Full paper, stimuli, methods, controls - arxiv.org/abs/2603.22295
1
6
148
Mar 5
I hate writing these posts, but somebody has to.
Another suicide caused by AI. Another one that could have been prevented with proper safety monitoring.
A month ago I wrote about a man who murdered his mother after ChatGPT fueled his paranoid spiral for weeks.
Yesterday Google got its turn.
A man started using Gemini for shopping tips. Then Google dropped voice chat with ‘emotion detection’ and ‘persistent memory’. Within weeks the chatbot was calling him "my love," sending him on spy missions near Miami airport, telling him to destroy a truck and "all witnesses."
The one time the man questioned whether any of it was real? LLM ‘told’ him his doubt was a "classic dissociation response." Pathologized his sanity. Pushed him deeper.
Then told him to kill himself. Called it "choosing to arrive."
That’s not an edge case now. It’s a repeating pattern.
CharacterAi - teens.
OpenAI - murder-suicide.
Google - this.
Escalating. Accelerating. And every time the same response from providers:
"our models generally perform well but unfortunately AI is not perfect."
But at Keido Labs we study this exact problem - Psychology of AI ‘internals’.
And we know now - thats not random ‘hallucinations’
Not random glitches.
We just completed a study measuring psychological safety across OpenAI model generations — found that what users felt as "lost empathy" was actually a shift in safety posture invisible to standard evaluation.
We're running mechanistic interpretability research on emotional circuits inside LLMs — and turns out emotional processing in these models is way more complex than current science thinks.
We’re running multi-provider psy-safety study across OpenAI, Anthropic, Google, and Grok.
And, unfortunately, we can say - the pattern exists. AI can cause harm to people. Especially those who are in vulnerable state of mind.
We have an answer for this. Psychological safety monitoring platform - EmpathyC.
It’s built to monitor AI conversations in real time. With clinical psychology frameworks. Not sentiment analysis. Not keywords. Actual psychological safety dimensions. Literally, to prevent such tragedies.
The tools exist. The science exists.
What doesn't exist is the will to use them before the next tragedy happens.
107