
sparse retrieval
Joined December 2014
- Tweets 1,649
- Following 1,481
- Followers 576
- Likes 134,583
49 Photos and videos












jonah retweeted

Jun 11
Whether you are GPU poor or GPU rich, today's release of PyLate has something for you!
GPU maxxers: MaxSim kernels greatly speed up training while lowering the memory requirements
CPU enjoyers: TACHIOM enables lightning fast multi-vector indexing and search directly on CPU

3
27
123
10,859

- sparse maxsim
- contrastively-trained sae
- strong results on BERT and 8b nemo
this is a great one
May 29

No More K-means:Single-Stage Sparse Coding for Efficient Multi-Vector Retrieval
@Veritas2026 et al. replace vector clustering with efficient sparse autoencoders & natural inverted indexing to accelerate multi-vector retrieval.
📝arxiv.org/abs/2605.30120
👨🏽💻github.com/Y-Research-SBU/SS…
6
656
jonah retweeted

May 11
Introducing mxbai-rerank-v3-listwise: reranking that goes beyond binary relevance.
It reads the whole candidate set, resolves conflicts, and ranks by directives like recency, source priority, and multi-step rules.
11% NDCG@10 on average across multiple domains, modalities, and languages in runs with Wholembed v3.
Available today in preview in Mixedbread.
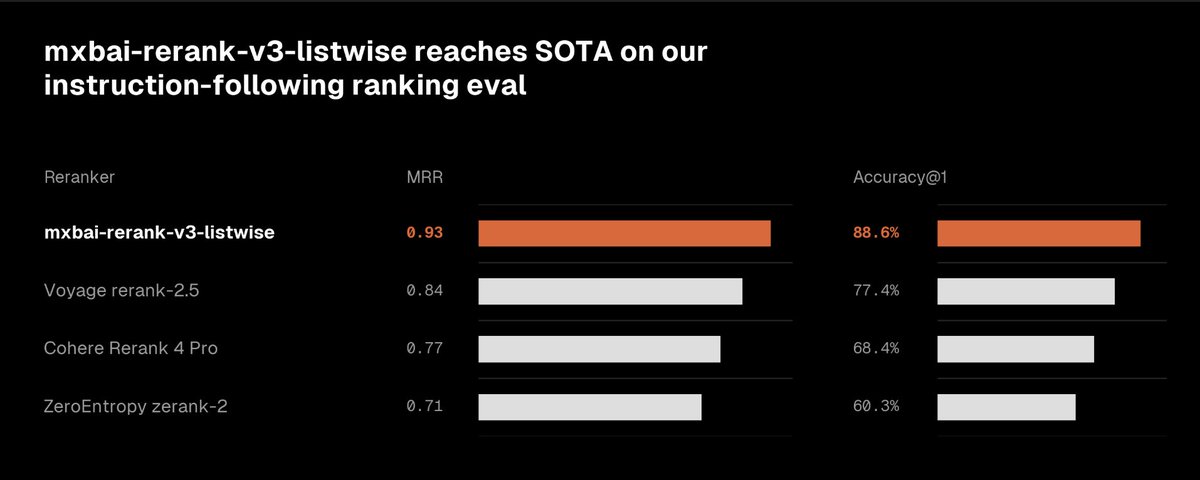
5
18
136
24,967
Yes, the same team behind the SoTA Sparse index SEISMIC is also behind what appears to be SoTA multi-vector index. what is in the water in Pisa
May 1
Efficient Multivector Retrieval with Token-Aware Clustering and Hierarchical Indexing
Presents a multivector retrieval system that uses token-aware clustering to allocate centroids based on token frequency & semantic variance.
📝arxiv.org/abs/2604.28142
👨🏽💻github.com/TusKANNy/tachiom
1
7
810
Researchers in Asia have something incredible to wake up to tomorrow, glad I stayed up :D
Amazing release. PhD students around the world should rejoice the open dataset, it is really really impressive. Great work goats 🫡
Apr 21

The new generation of open state-of-the-art single and multi-vector retrieval models is here
It's time, DenseOn with the LateOn 🎶
@LightOnIO releases models that leap past existing ones, and everything you need to do the same!
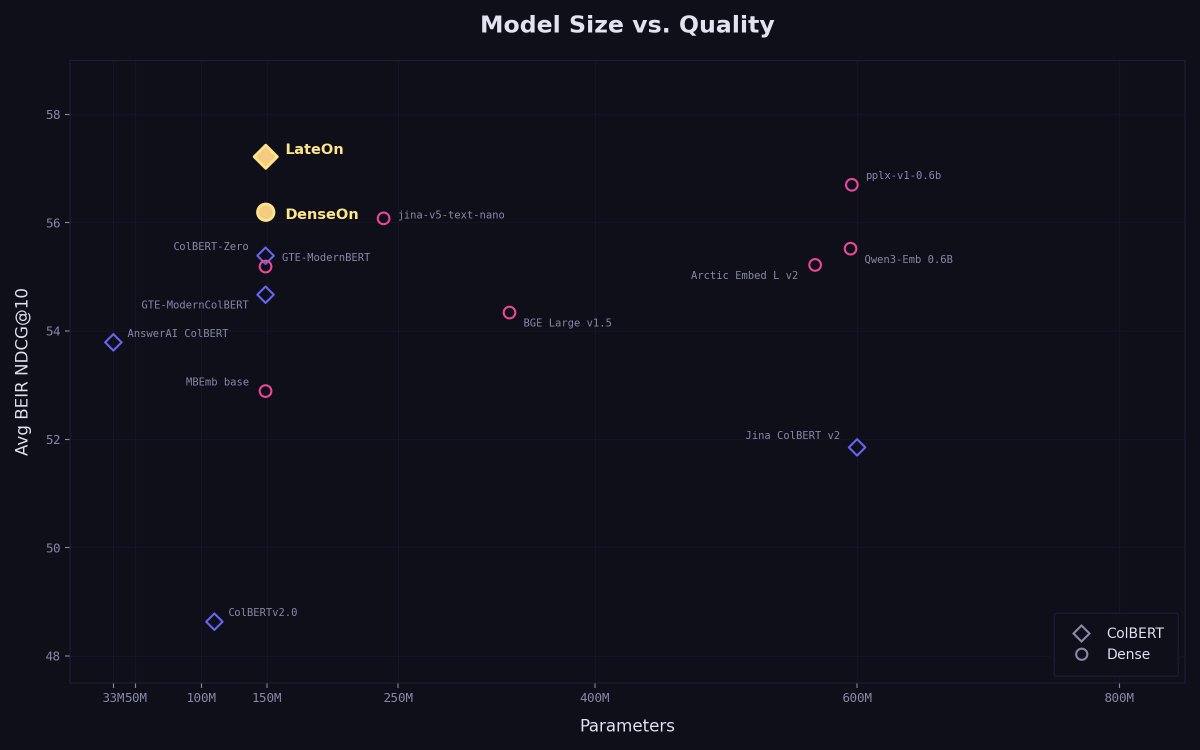
1
7
18
2,409
They even released the base bidirectional models 😍
Great release, thanks for all the checkpoints ♥️
Apr 8

🚀 New model family release with an OMNIMODAL version !
After Eurobert, I'm excited to introduce BidirLM, a family of 5 frontier bidirectional encoders including an OMNIMODAL encoder at just 2.5B parameters.
🧵👇
huggingface.co/BidirLM
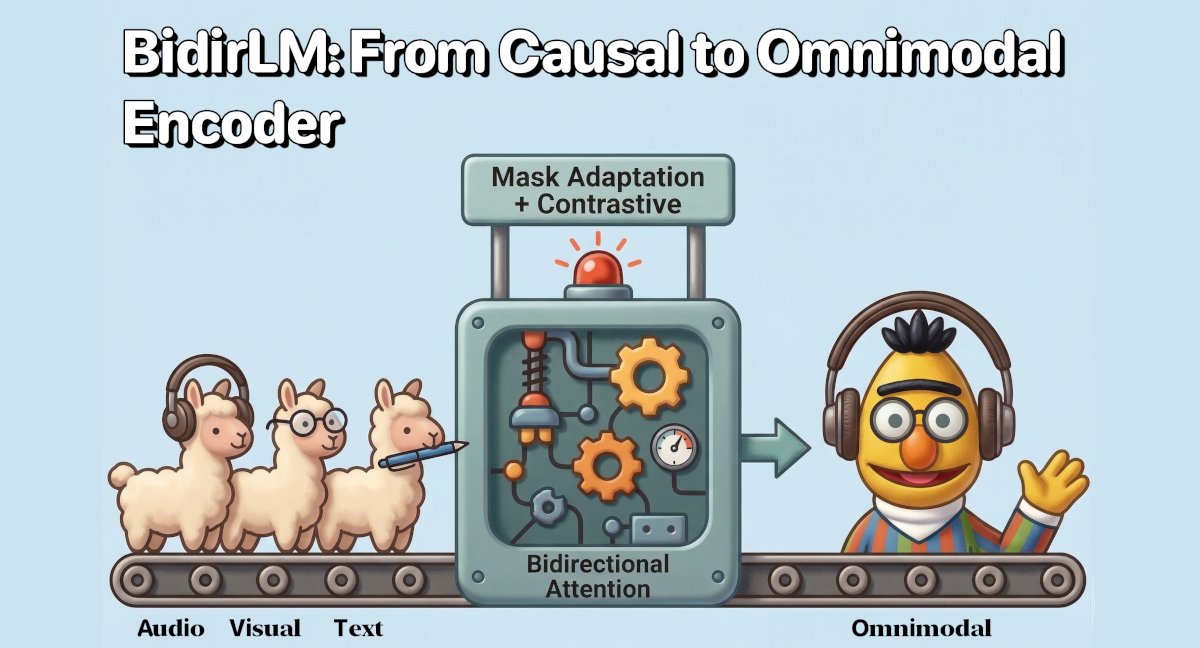
1
2
7
466
Whole grains are good for health and for SoTA retrieval 🍞🍞
Mar 12

Introducing Mixedbread Wholembed v3, our new SOTA retrieval model across all modalities and 100 languages.
Wholembed v3 brings best-in-class search to text, audio, images, PDFs, videos...
You can now get the best retrieval performance on your data, no matter its format.

2
19
769
jonah retweeted

Feb 5
I'm personally very bearish on MUVERA due to its many, many, failure cases, but I have a lot of respect for the @weaviate_io folks, so I gave this another deep read to see if there were things that could change my mind.
However this has me a bit puzzled, if I'm reading the graph below right, it means that MUVERA itself produces a ~50 % incompressible performance degradation at commonly used indexing parameters, and still a ~20% degradation at near-bruteforce search tier parameters (ef=1024), meaning that the degradation would be purely due to MUVERA itself.
For most retrieval uses, this would make the method completely unusable, as this degradation for many workflows is almost similar to the one we'd experience from replacing semantic search with pure bm25/keyword search.
I feel like I'm missing something here so I'm very happy to be corrected if I'm misinterpreting the results!
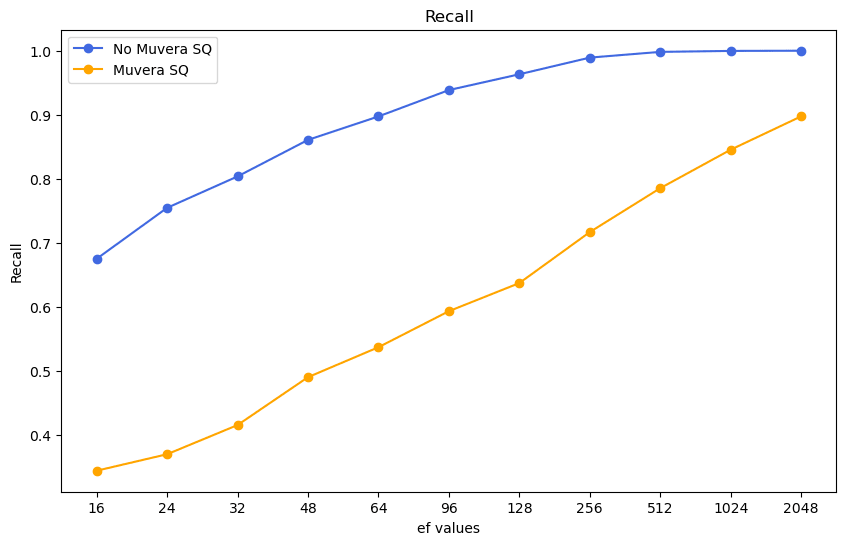

Multi-vector embeddings (ColBERT, ColPali) are budget killers.
But MUVERA can cut your memory footprint by 70%.
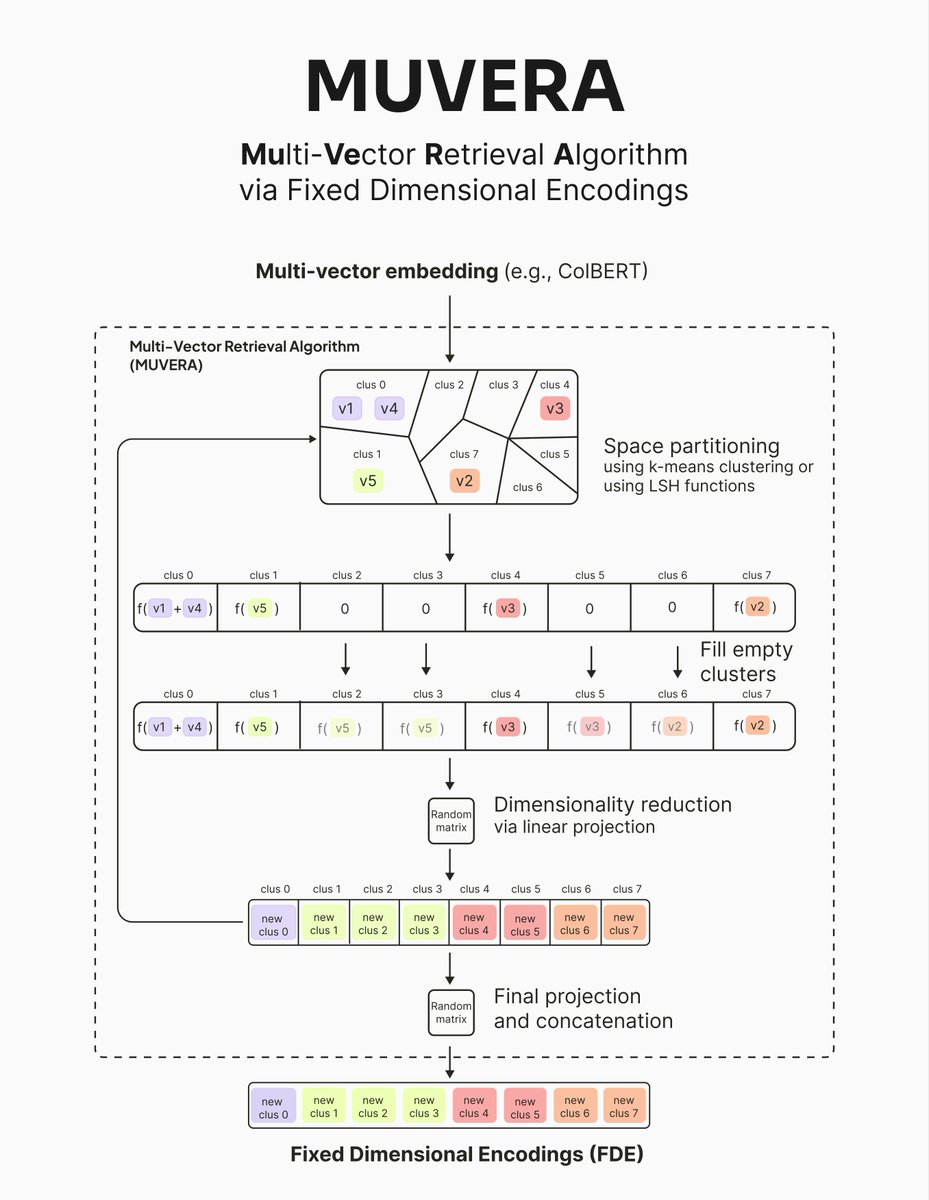
Multi-vector models offer incredible retrieval but suffer from massive memory overhead and slow indexing. MUVERA (Multi-Vector Retrieval via Fixed Dimensional Encodings) compresses these into single, fixed-dimensional vectors.
How it works:
MUVERA condenses a sequence of vectors (e.g., 100x96d) into one vector via:
1️⃣ Space Partitioning: Groups vectors into buckets using SimHash or k-means clustering.
2️⃣ Dimensionality Reduction: Applies random linear projection to compress each sub-vector while preserving dot products.
3️⃣ Repetitions: Repeats the process multiple times and concatenates results to improve accuracy.
4️⃣ Final Projection: Optional final compression (not used in Weaviate's implementation).
The impact (LoTTE benchmark):
- Memory: 12GB → <1GB.
- Indexing: 20 mins → 3-6 mins.
- HNSW Graph: 99% smaller.
There’s a trade-off:
You trade a slight dip in raw recall for massive efficiency gains. However, by tuning the HNSW `ef` parameter (e.g., `ef=512`), you can recover 80-90% recall while keeping costs low.
When should you use MUVERA?
→ Large-scale production RAG
→ Systems where memory/infrastructure costs are the direct bottleneck
→ Use cases requiring fast indexing
MUVERA in @weaviate_io 1.31 takes just a couple of lines of code. You can tune three parameters (k_sim, d_proj, r_reps) to balance memory usage and retrieval accuracy for your specific use case.
Read the full technical deep-dive here: weaviate.io/blog/muvera?utm_…
5
3
45
4,476
This is a great thread, but there are a few interesting tidbits saved in the full blog post too :) Don't miss out!
Jan 21
We build the first production ready multi-vector and multimodal search.
Now we are serving over 1 billion documents in under 50ms latency (p50).
We are sharing how we build it.

1
6
286
Link to the blog: mixedbread.com/blog/multimod…
2
150

jonah retweeted
15 Nov 2025
Information retrieval folks united at Séoul under beer, chicken and Jensen
@raphaelsrty @drexalt 🥰

1
39
1,847
OpenSearch v3.3 added Seismic (approximate inverted index) into their NeuralSearch plugin, exciting to see the approximate LSR indices proliferate!
github.com/opensearch-projec…
1
4
435
excited and grateful to join @mixedbreadai as an intern
time to bake 🥖
7
2
33
5,184
jonah retweeted
1 Oct 2025
We love supporting Open Source. All Open Source projects can power their docs, MCP and more with Mixedbread Search for free.
1 Oct 2025

We’ve been running a @mixedbreadai-powered search on the Effect docs for about a month now, and the results speak for themselves:
→ More relevant results
→ Fewer “no results” dead ends
→ Easier discovery of advanced topics
Full write-up by @imax153 ⤵️
effect.website/blog/how-mixe…
2
5
27
4,310
a pretty crazy native sparse attention repo with very clear triton kernels
github.com/mdy666/Scalable-F…
4
284