
founder of Humanbased (prev: Codatta, inductive.network). building tools (motivationlabs.ai) for our team, PhD, ex-(Pinterest, Alipay)
Joined May 2009
- Tweets 2,830
- Following 1,348
- Followers 2,927
- Likes 2,777
260 Photos and videos












Appreciate @MessariCrypto recognizes @codatta_io positioning with deAI data stacks. fun fact: Codatta actually evolves from OSS Microscope Protocol, which we started with @coinbase @MessariCrypto and @GoPlusSecurity docs.codatta.io/en/community…

1
4
22
6,018

cool internet things pt. 6
profconradi.com - math visualized
music.jessyin.world - visual instruments
everynoise.com - every music genre ever
poetry.camera - a camera that prints poems
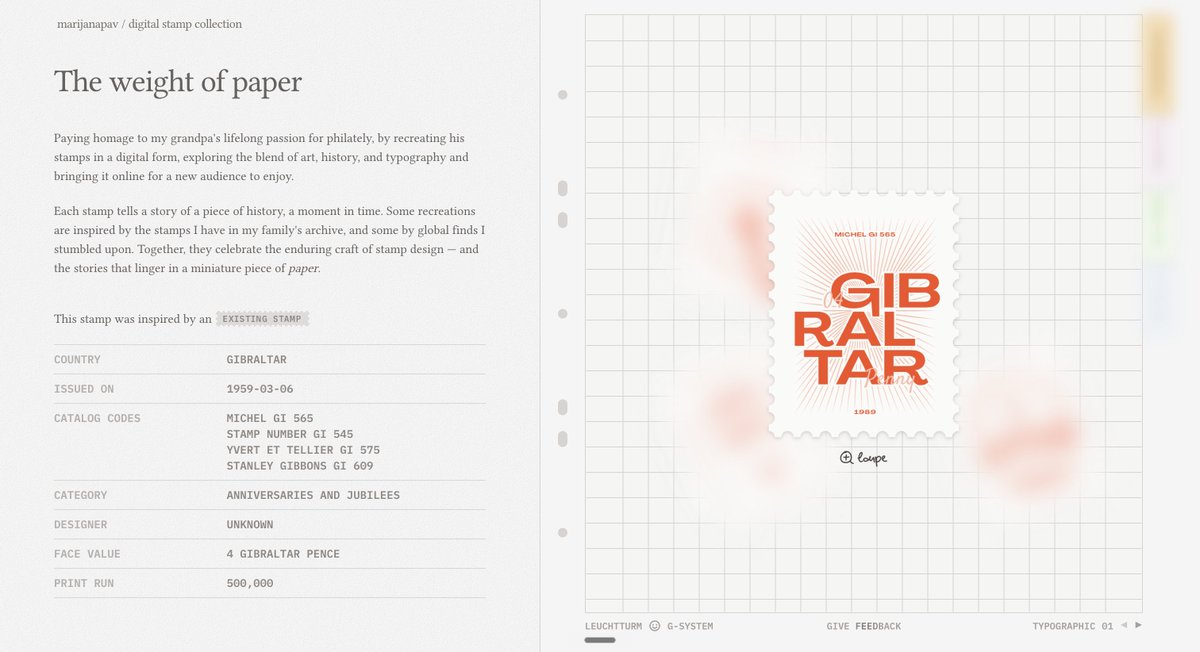
marijanapav.com/stamps - digital stamp collection
liumichelle.com/sketchbook - a living digital sketchbook
some of the cool people behind these:
@michelletliu, @marijanapav, @rpavlini, @S_Conradi, @EveryNoise, @S_Conradi, @itsjessyin, @kelin_online



cool internet things pt. 5
digibouquet.com - digital flowers
xrageroom.com - destroy any tweet
yeguessr.com - guess the kanye album
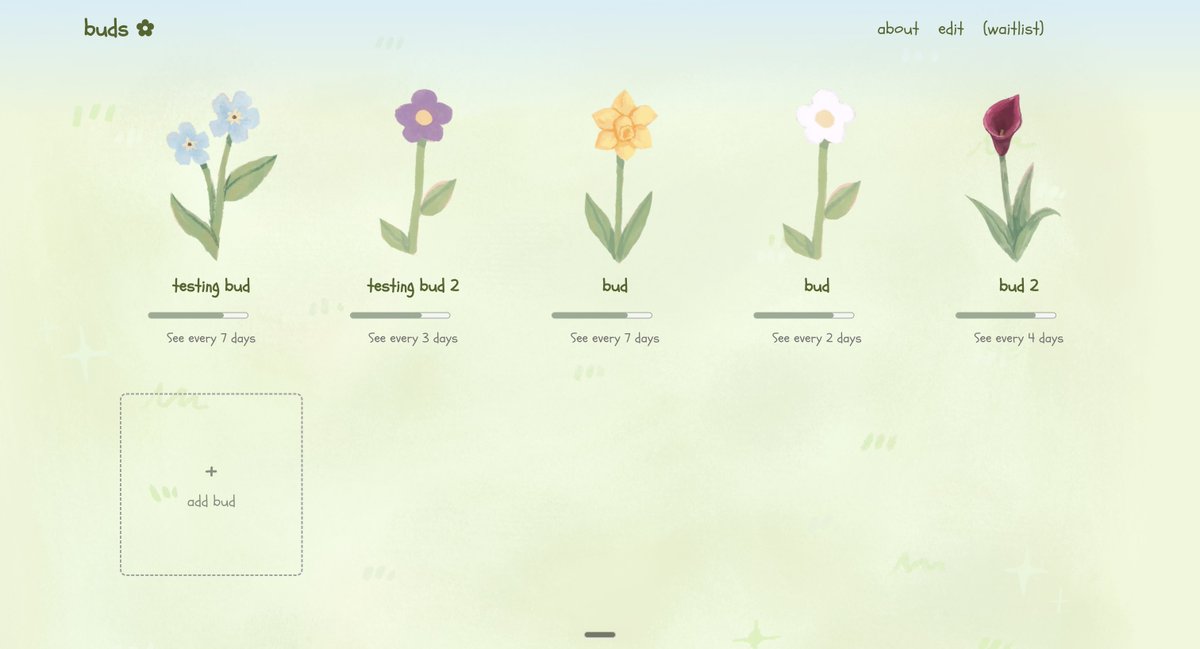
flower-buds.vercel.app - friendship tracker
counter-print.co.uk - beautiful design books
nycstoops.com - nyc building analysis ratings
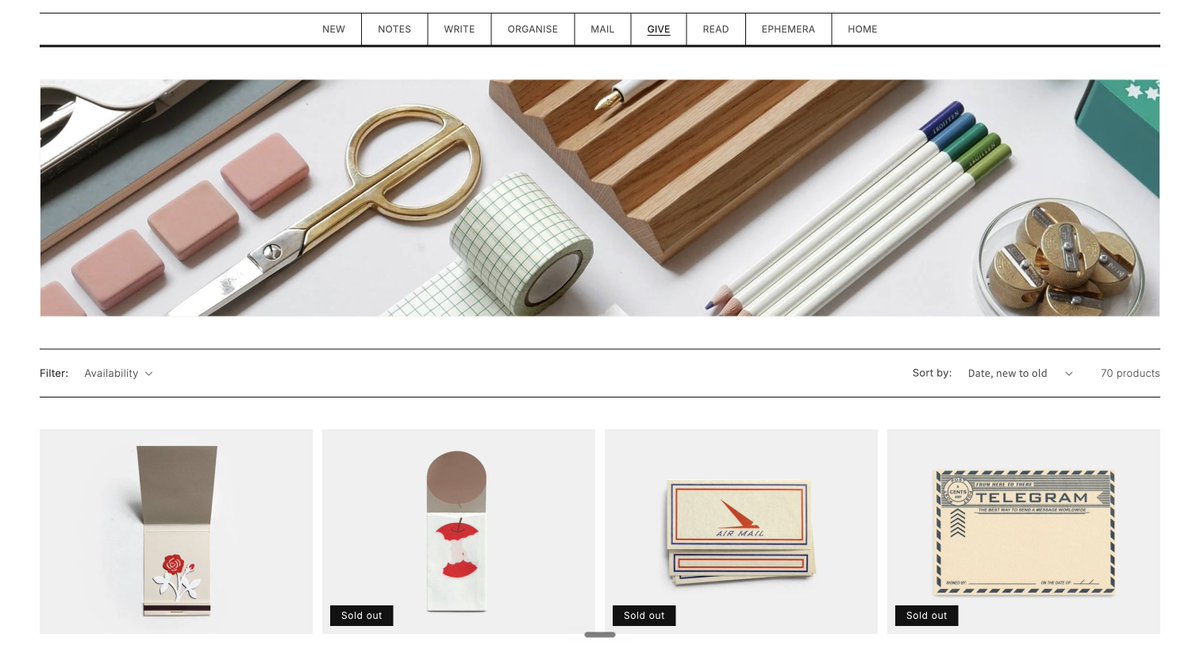
presentandcorrect.com - beautiful stationery desk stuff
some of the cool people behind these: @pau_wee_, @immike_wing, @downloadlos, @marcgmbh, @maggiexgao, @jen__jpeg, @Counterprint

23
744
4,464
207,248
Yi retweeted

May 29
It’s never been easier to design your dream house.
Draw a shape. Define your rooms. Set your constraints.
@DraftedAI generates complete floor plans, elevations, and 3D home designs in seconds.
Over the last month, 120,000 people generated 325,000 home designs with Drafted.ai.
189
340
4,444
741,227
Yi retweeted

May 26
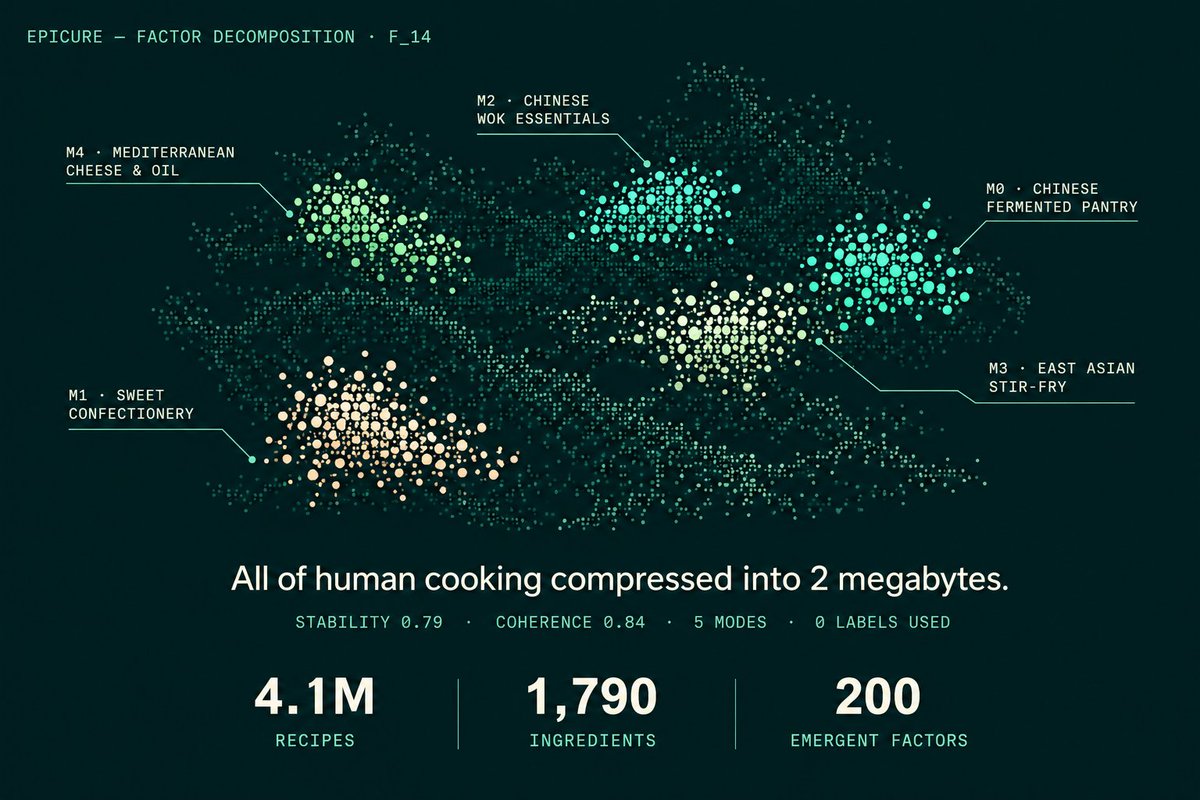
Launching our new paper on arXiv: we trained the largest multilingual food model ever built.
4.1M recipes. 7 languages. 1,790 ingredients. 300 dimensions.
All of human cooking compressed into 2 megabytes.
339
971
9,359
5,147,707
Yi retweeted

May 26
Obsidian users after reading this:

13
111
1,248
453,929

Yi retweeted
May 14
this guy literally breaks down the exact Claude Obsidian playbook to build your own AI employee in a single afternoon 🤯



36
293
1,948
351,692
Yi retweeted

May 12
Compounds knowledge in Obsidian via Claude agents
github.com/AgriciDaniel/clau…

6
53
463
17,175

jina-embeddings-v5-omni is here! Our first universal embedding model for text, images, audio, and video. Available in two sizes: small (1.57B, 1024-dim, 32K context) and nano (0.95B, 768-dim, 8K context). Both support Matryoshka truncation down to 32 dimensions.
v5-omni is back-compatible: if you already use jina-embeddings-v5-text-small/nano, the existing text indexes work with v5-omni out of the box. Without reindexing the text, just index your multimodal content with v5-omni and start searching images, audio, and video.
11
90
585
131,929

Yi retweeted

May 12
These are some of the flows the app is based on.
They were created by Claude via Figma's MCP and turned out super accurate, outlining not only user flows, but Information architecture and the data used at every step.
This alone is a great foundation for the future app - paired with Design.md, and could potentially replace the prompts that I used.

May 12

I’ve been exploring how to create POCs fast, going from idea to working prototype or MVP, with code.
This one is an early concept for a travel planning app, and this is the workflow I’m following:
- Start with a few screens in Figma to define the vision and direction.
- Describe the idea in Claude, share the designs, and shape the UX strategy.
- Map the user flows and identify what actually needs to be built.
- Create a build plan with detailed prompts, split into phases instead of relying on one master prompt. I’m working through 6 implementation phases in total.
- Write a Design.md to keep the visual language and styles consistent.
- Build in Claude Code using the Figma links, screenshots, and prompts.
I’m finding that the real leverage is not just in prompting, but in translating design intent into a build system that AI can actually execute.
1
2
33
11,106
Yi retweeted

May 12
just launched: @mobbin mcp 💛
your AI agents can now search 600,000 real app screens. paywalls, onboarding, checkout, permissions — from apps that already shipped.
ai tools can write code. they just don't know what good looks like. now they do.
👉 mobbin.com/mcp
150
172
2,614
493,823
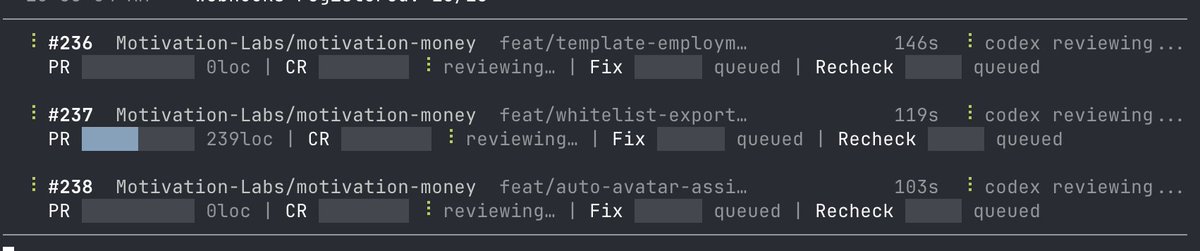
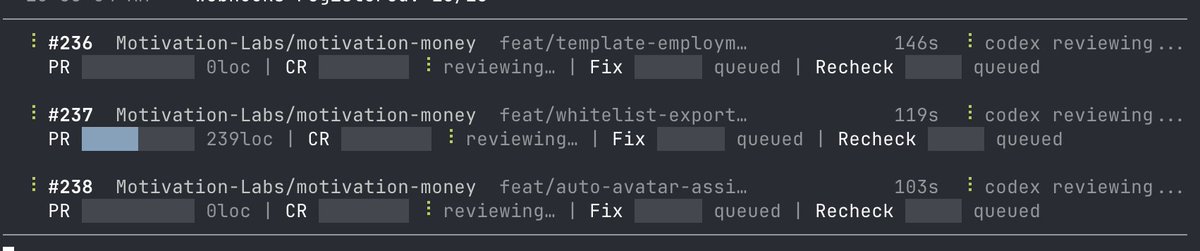
implement
"Make Claude and Codex do Pair Programming" (mentioned in Vercel team's best practice) via npmjs.com/package/@motivatio… (`npm install @motivation-labs/crosscheck@beta` for lastest update). The crosscheck works like below
1
1
152
Yi retweeted

May 7
Neural networks might speak English, but they think in shapes.
Understanding their rich *neural geometry* is key to understanding how they work – and to debugging and controlling them with precision.
Starting today, we’re releasing a series of posts on this research agenda. 🧵
306
1,674
11,183
3,157,972
Claude writes code. Codex reviews it.
Codex writes code. Claude reviews it.
That’s the loop behind crosscheck — a local, cross-vendor AI code review orchestrator for PRs.
Built for catching agent mistakes before they land.
github.com/motivation-labs/c…
1
135
Will it improve quality is unknown. Did not spend time on evaluating two alternatives.
May 8

this is the healthiest version of the rivalry tbh. make them review each other's homework
66
Particularly great for people already having subscriptions from two sides.
But, whether cross-vendor CR is actually meaningfully better than same-vendor CR… remain unknown. Nice toy anyway.

Claude writes code. Codex reviews it.
Codex writes code. Claude reviews it.
That’s the loop behind crosscheck — a local, cross-vendor AI code review orchestrator for PRs.
Built for catching agent mistakes before they land.
github.com/Motivation-Labs/c…
47
Yi retweeted

Apr 28
They don't tweet about it but poolside.ai secretly has one of the most coherent sites in the industry today
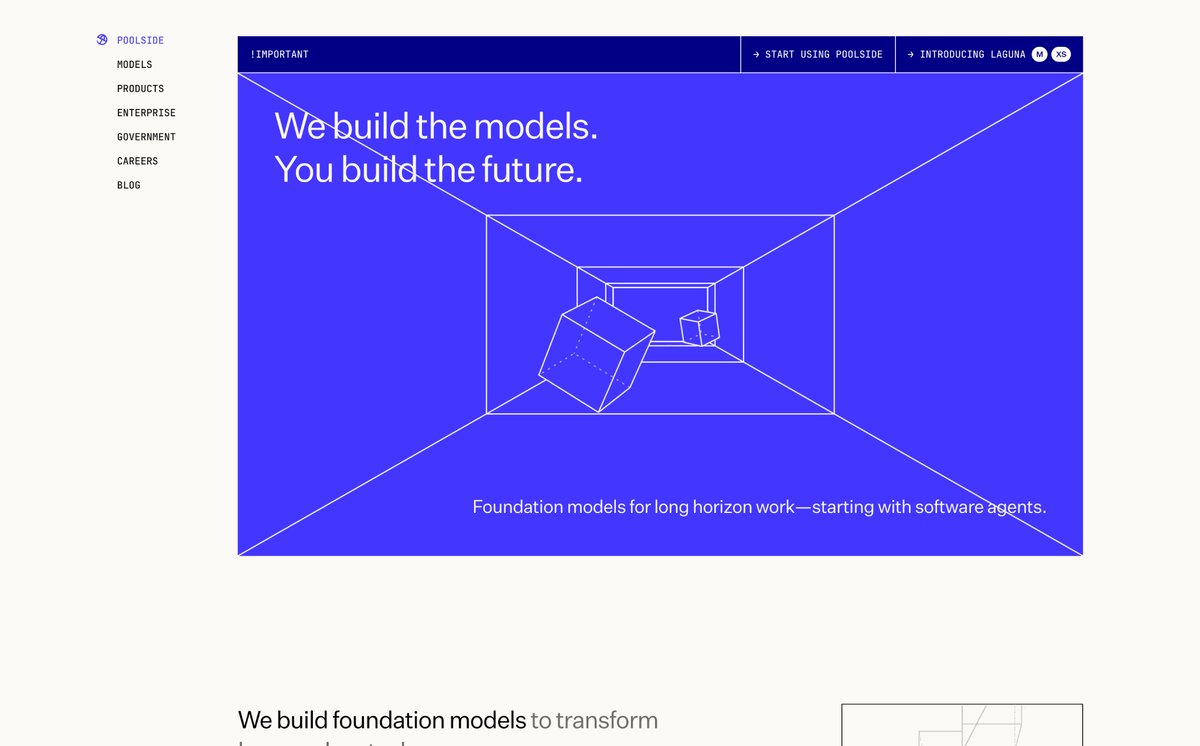



22
26
804
52,361