
Computer science prof, entrepreneur & leader at Ai2. Excited by AI for science, human-AI interaction, and Web-scale NLP.
Joined March 2009
- Tweets 1,045
- Following 271
- Followers 2,795
- Likes 1,194
12 Photos and videos












May 4
This benchmark for Ai scientific capabilities is beautifully thought out - I especially like it's clear enumeration of design principles...

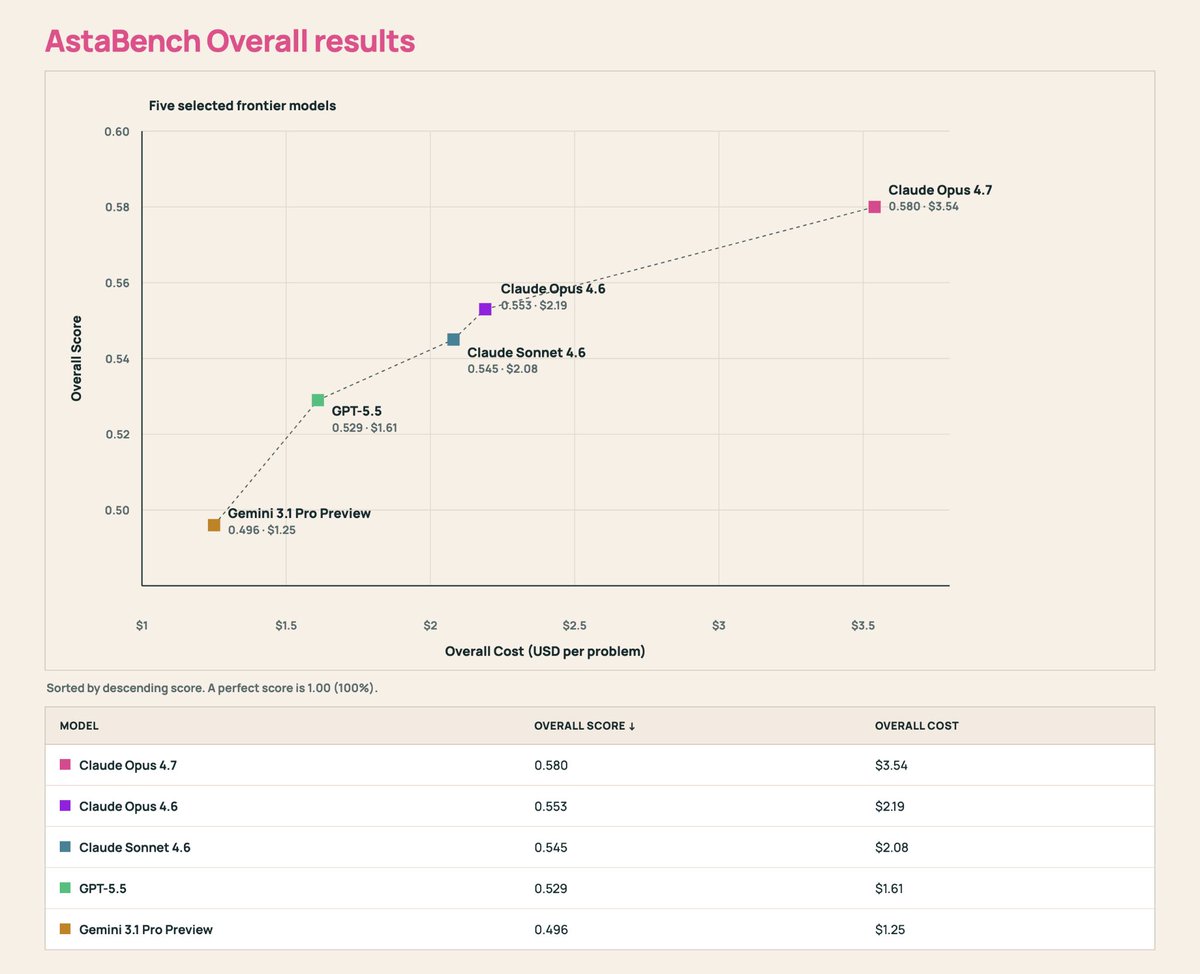
New AstaBench results show frontier models making progress on scientific research, but the benchmark remains far from solved.
Claude Opus 4.7 leads overall at 58.0%, while GPT-5.5 comes within 5.1 points at less than half the measured cost per problem. 🧵
1
7
817
Daniel Weld retweeted

Mar 24
We built MolmoWeb from the scratch with Molmo2!!! 💕🌐
It’s not easy to build SOTA web agents out of open source VLMs, when they can be so profitable that very few projects release everything (if anything), esp the datasets 🔑
But, we just released all the MolmoWeb model checkpoints and datasets from ai2😉
Can’t wait to see what the community builds on top of MolmoWeb!🫡
Today we're releasing MolmoWeb, an open source agent that can navigate complete tasks in a browser on your behalf.
Built on Molmo 2 in 4B & 8B sizes, it sets a new open-weight SOTA across four major web-agent benchmarks & even surpasses agents built on proprietary models. 🧵

10
24
217
27,000

🔎 Deep research agents like Asta ScholarQA and OpenAI Deep Research are transforming how we perform literature review.
But how do we know if the way we evaluate them is actually meaningful?
Announcing our new paper: “Deep Research, Shallow Evaluation: A Case Study in Meta-Evaluation for Long-Form QA Benchmarks” 🧵
5
20
155
12,218
Daniel Weld retweeted

Mar 13
Are you a researcher in CS or a CS-adjacent field curious about how an AI agent can help you with your research project? Want to try a new tool for your research support in a paid user study ($100, 2 hr)? Limited spot numbers. See details and sign up here: forms.gle/JzLtkAhe7TtvuiwQ8
2
22
97
9,728

We’re releasing the Theorizer code and framework a dataset of ~3,000 theories generated by Theorizer across the field of AI/NLP, built from 13,744 source papers.
💻 Code: github.com/allenai/asta-theo…
📝 Technical report: arxiv.org/abs/2601.16282
✍️ Learn more in our blog: allenai.org/blog/theorizer
2
16
74
3,540
Jan 28
I'm so excited by this! Our system is generating some insightful & novel theories (e.g., internally for LM post-training). And it's still getting better!
Introducing Theorizer: Turning thousands of papers into scientific laws 📚➡️📜
Most automated discovery systems focus on experimentation. Theorizer tackles the other half of science: theory building—compressing scattered findings into structured, testable claims. 🧵
2
26
6,019
Introducing Ai2 Open Coding Agents—starting with SERA, our first-ever coding models. Fast, accessible agents (8B–32B) that adapt to any repo, including private codebases. Train a powerful specialized agent for as little as ~$400, & it works with Claude Code out of the box. 🧵

42
139
937
351,266
Jan 13
Smart analysis analysis of scholar output when authors adopted LLMs as part of their writing: 1) huge 36% boost in # papers published 2) LLMs mitigate skill disparities, eg native language - enough to shift market share of production toward China bit.ly/4qliJGo @yian_yin
1
9
635

🧠 Introducing NeuroDiscoveryBench. Built with @AllenInstitute, it’s the first benchmark for evaluating AI systems like our Asta DataVoyager agent on neuroscience data. The benchmark tests whether AI can truly extract insights from complex brain datasets.
4
21
107
10,100
Daniel Weld retweeted

25 Nov 2025
#NeurIPS2025 and AI x Science?
Some fun announcements are coming up. Stay tuned.
Also, our Asta internship application is still open -- apply and mention my name if you'd like to work w me ~
11 Nov 2025

🎀 Really excited to start cadence for 2026!
At @allen_ai, we are at the intersection of AI making a real impact in accelerating science, with several serious collaborations with domain scientists (Economics, Oncology, Neuroscience, Climate, Epidemiology).
If you are passionate about turning the stack upside down to break and build current LLMs to be adaptive for a continual discovery process, join us!
If you are interested in my work, such as data-driven discovery, open-ended hypothesis search, test-time adoption for hypothesis generation, causal mechanism discovery using data and literature, mention my name in your application!
Past interns might vouch for their experiences, but working with Asta interns for the last two years has been one of my most rewarding journeys at Ai2! 🩷

1
2
33
6,728
Announcing Olmo 3, a leading fully open LM suite built for reasoning, chat, & tool use, and an open model flow—not just the final weights, but the entire training journey.
Best fully open 32B reasoning model & best 32B base model. 🧵

54
327
1,674
610,005
Daniel Weld retweeted
19 Nov 2025
Plenty of AI-gen papers in ICLR. Wonder why?
🚨 In a preregistered Randomized Controlled Trial, we find: CS authors perceive AI-abstracts as more readable, tend to edit less than their published counterparts. AI-use and its disclosure shape the fabric of collaborative scientific writing.
Work led by @hsanchaita & @leadoeun27, advised by @shocheen & yours truly.
1/n

2
15
64
14,658
19 Nov 2025
Impressive deep-research performance by a tiny & open model!
18 Nov 2025

🔥Thrilled to introduce DR Tulu-8B, an open long-form Deep Research model that matches OpenAI DR 💪Yes, just 8B! 🚀
The secret? We present Reinforcement Learning with Evolving Rubrics (RLER) for long-form non-verifiable DR tasks! Our rubrics:
- co-evolve with the policy model
- are grounded on search knowledge
🧵
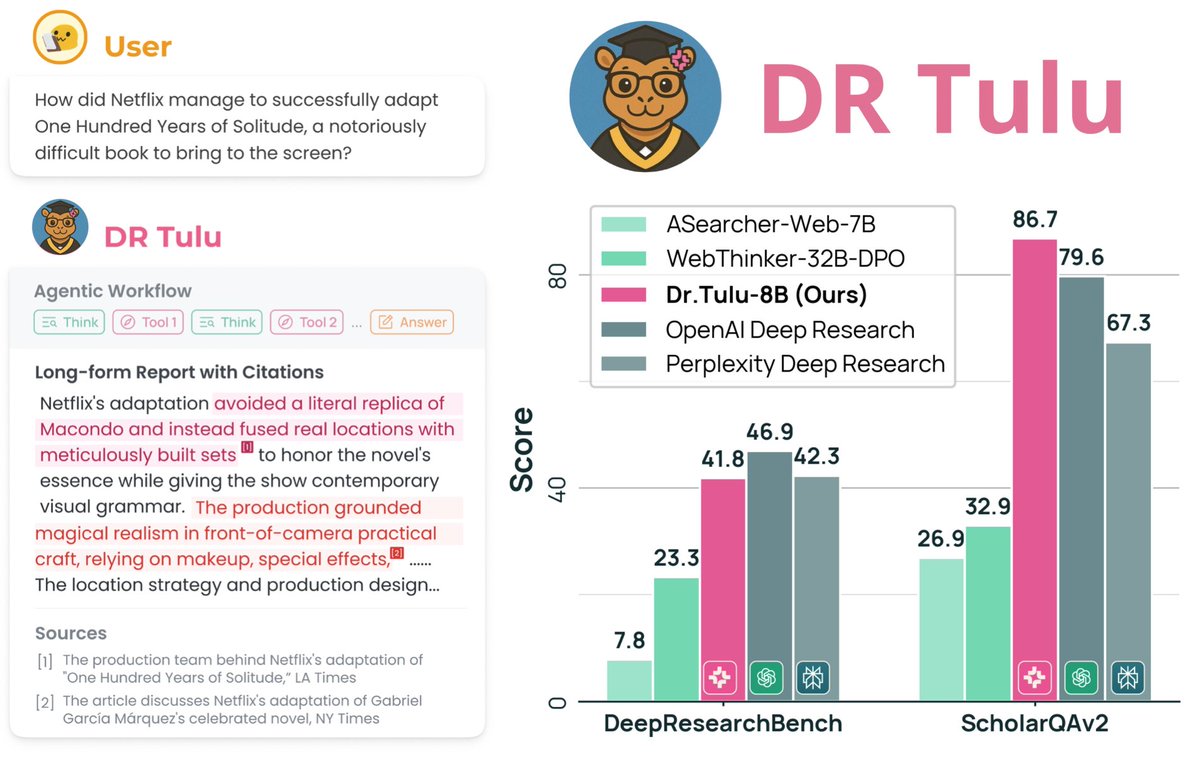
1
4
469
6 Nov 2025
The benchmark desiderata alone make this paper worth a read...
6 Nov 2025

Agent benchmarks don't measure true *AI* advances
We built one that's hard & trustworthy
👉AstaBench tests agents w/ *standardized tools* on 2400 scientific research problems
👉SOTA results across 22 agent *classes*
👉AgentBaselines agents suite
🆕arxiv.org/abs/2510.21652
🧵👇
2
669
28 Oct 2025
Super interesting and well written summary of the incredible progress we’ve made on climate change (and what’s most important to do next) ⭐️⭐️⭐️⭐️⭐️ gatesnotes.com/three-tough-t…
2
445
📊 Today we're releasing data showing which scientific papers our AI research tool Asta cites most frequently. Think of it as creating citation counts for the AI era—tracking which research is actually powering AI answers across thousands of queries. 🧵
1
5
41
10,991
2 Oct 2025
Pretty amazing that this can be done at all, but especially with federated data (crucial given the sensitivity of patient data)!
Introducing Asta DataVoyager—our new AI capability in Asta that turns structured data into transparent, reproducible insights. Built for scientists, grounded in open, inspectable workflows. 🧵
2
8
1,736