
Data and Viz scientist. I like biochem as munch as Comp. Sci. Views and opinions are mine not my employer
Joined July 2012
- Tweets 9,115
- Following 1,008
- Followers 561
- Likes 13,240
750 Photos and videos















Pinned Tweet

9 May 2016
El mejor video que tengo para explicar mi tesis en menos de 3 minutos youtu.be/l1IO7Hg9xCc
4
16
Jun 8
I’ve participated in massive papers , 50 authors, I can feel the difference in disciplines, generations and information, surprisingly to me the older authors are the ones that want buzz words #AI #agent #digitaltwin overshooting the scope of these tools
1
24

May 20
😱 I used to do this manually in Google spreadsheets (not all) , but after read in the paper each column had some data , the rows content of the paper and the next column my comments , I still have them as reference but this is way better
May 19

1️⃣ Literature Insights
Built with @NotebookLM, it searches scientific papers, organises everything into custom tables, and lets researchers chat with curated data to create slide decks, audio overviews, and more in minutes.
66
dxbarradas retweeted

May 10
BS.
Attention was born in Montréal
PyTorch in NYC.
AlphaGo in London
AlphaFold in London
ESMFold in NYC
Llama 1 in Paris.
Llama 2 in Paris NYC SV
DeepSeek in Hangzhou
Plus:
DINO in Paris
JEPA in Montréal Paris NYC
SV is 3 mos ahead on topics SV is singularly obsessed with.
181
498
7,782
739,077
dxbarradas retweeted
The very first OpenBind data release!

NEW: today OpenBind ‘comes out of stealth’ so to speak with their first data dump of ~900 novel protein-ligand structures - most with paired affinities
This represents a meaningful %-age increase in all of humanities P-L data in the PDB collected in the last 50 years
More👇

4
26
3,579

We introduce ConforNets, a mechanism for conformational control in AlphaFold3 models
- SoTA at producing diverse conformations on every multistate benchmark (N=104)
- Novel capability: transfer state from one protein to another
Outperforms BioEmu, ConforMix and AFsample3
🧵1/8
10
72
283
51,408
dxbarradas retweeted

Apr 21
Does AlphaFold’s latent space encode only the native state or something like a distribution over conformations? We begin to answer this question with ConforNets, a mechanism for producing diverse states, or very specific ones, via inference-time adaption of OF3p’s latent space👇

We introduce ConforNets, a mechanism for conformational control in AlphaFold3 models
- SoTA at producing diverse conformations on every multistate benchmark (N=104)
- Novel capability: transfer state from one protein to another
Outperforms BioEmu, ConforMix and AFsample3
🧵1/8
2
41
213
24,002
dxbarradas retweeted

Big news! Starting my lab as Ramón y Cajal PI at @IBVF_Sevilla in Seville 🌞, Spain, bridging microbial ecology, photosynthesis & plant biotech: from metagenomic and AI analyses 💻 to experiments in microbes & plants 🌊🧬🌱 Looking for PhD students & postdocs. DM or share!
10
35
109
9,309
Feb 10
21
Jan 6
Mi hijo es nadador 🏊
Este año no toca ganar medallas 🥇 en los torneos nacionales grandes
Este año toca entrenar 🏋️♀️ y esperar
1
16
dxbarradas retweeted

Julieta Fierro fue ciencia, divulgación y ruptura de barreras. Astrónoma, educadora y referente que acercó el cosmos a millones ✨
Hoy la recordamos como Personaje del Año 2025. Lee su historia completa y su legado ow.ly/C1Bg50XQqiX
8
35
5,382


dxbarradas retweeted

18 Dec 2025
This paper from Harvard and MIT quietly answers the most important AI question nobody benchmarks properly:
Can LLMs actually discover science, or are they just good at talking about it?
The paper is called “Evaluating Large Language Models in Scientific Discovery”, and instead of asking models trivia questions, it tests something much harder:
Can models form hypotheses, design experiments, interpret results, and update beliefs like real scientists?
Here’s what the authors did differently 👇
• They evaluate LLMs across the full discovery loop hypothesis → experiment → observation → revision
• Tasks span biology, chemistry, and physics, not toy puzzles
• Models must work with incomplete data, noisy results, and false leads
• Success is measured by scientific progress, not fluency or confidence
What they found is sobering.
LLMs are decent at suggesting hypotheses, but brittle at everything that follows.
✓ They overfit to surface patterns
✓ They struggle to abandon bad hypotheses even when evidence contradicts them
✓ They confuse correlation for causation
✓ They hallucinate explanations when experiments fail
✓ They optimize for plausibility, not truth
Most striking result:
`High benchmark scores do not correlate with scientific discovery ability.`
Some top models that dominate standard reasoning tests completely fail when forced to run iterative experiments and update theories.
Why this matters:
Real science is not one-shot reasoning.
It’s feedback, failure, revision, and restraint.
LLMs today:
• Talk like scientists
• Write like scientists
• But don’t think like scientists yet
The paper’s core takeaway:
Scientific intelligence is not language intelligence.
It requires memory, hypothesis tracking, causal reasoning, and the ability to say “I was wrong.”
Until models can reliably do that, claims about “AI scientists” are mostly premature.
This paper doesn’t hype AI. It defines the gap we still need to close.
And that’s exactly why it’s important.

378
2,110
8,186
1,171,754
17 Dec 2025
What a crazy year, it started with me being just an HPC data scientist and now I have to be an expert in data stewardship , data lakes, data warehouses, and the combination. #DataScience
18
15 Dec 2025
Excited to share ForamSlice an AI-assisted paleontology tool from KAUST Visualization Lab, built with Abdelghafour HALIMI, Ph.D and Ronell Sicat.
It uses Micro-CT #DeepLearning to classify foraminifera via an interactive dashboard.
👉 wiki.vis.kaust.edu.sa/highli…
#AI
24
dxbarradas retweeted

29 Oct 2025
#compchem #machinelearning #quantumcomputing
We have several open positions and we are looking for:
- 2 postdocs in machine learning to work on foundation models (theoretical developments)
- 1 HPC engineer to work on quantum computing
- 1 HPC engineer in the framework of ab initio computations and QM/MM
Reach to me for more details. Please RT.
2
38
80
8,644
dxbarradas retweeted

15 Oct 2025
BIG ANNOUNCEMENT📣: I haven’t been this excited to be part of something new in 15 years… Thrilled to reveal the passion project I’ve been working on for the past year and a half!🙀🥳 It started from my frustration with the depressing effect that the current publishing system has on the well-being of myself, my team, and pretty much every scientist I know (maybe you’ve noticed from my stupid jokes… :) I was exhausted of dealing with the huge delays, reviewers that can be abusive, and how arbitrary it all is. Unfortunately, the most important factors are often WHO your reviewers are and who YOU are... It’s clear we need alternatives or at least ways to improve the situation. So, together with a really special and talented team we worked to develop this idea into “qed” a platform where you can get CONSTRUCTIVE feedback on your own work or CRITICALLY assess other people’s papers. It can be a real difference maker if many of you join us (thousands have tried it already, but today we release a NEW and much stronger version ;) Let’s harness qed to put the power back in the scientists’ hands, to do, to read & to publish science on our own terms. I’m dying for you to TRY IT, and it’s very simple - just drop a paper (the link to the website is in the replies👇) - it’s completely secure, private, and free, and you get results fast. Please show your support, SHARE, tell your friends, and let’s be the revolution 🫵!

109
486
1,887
542,341
dxbarradas retweeted

10 Oct 2025
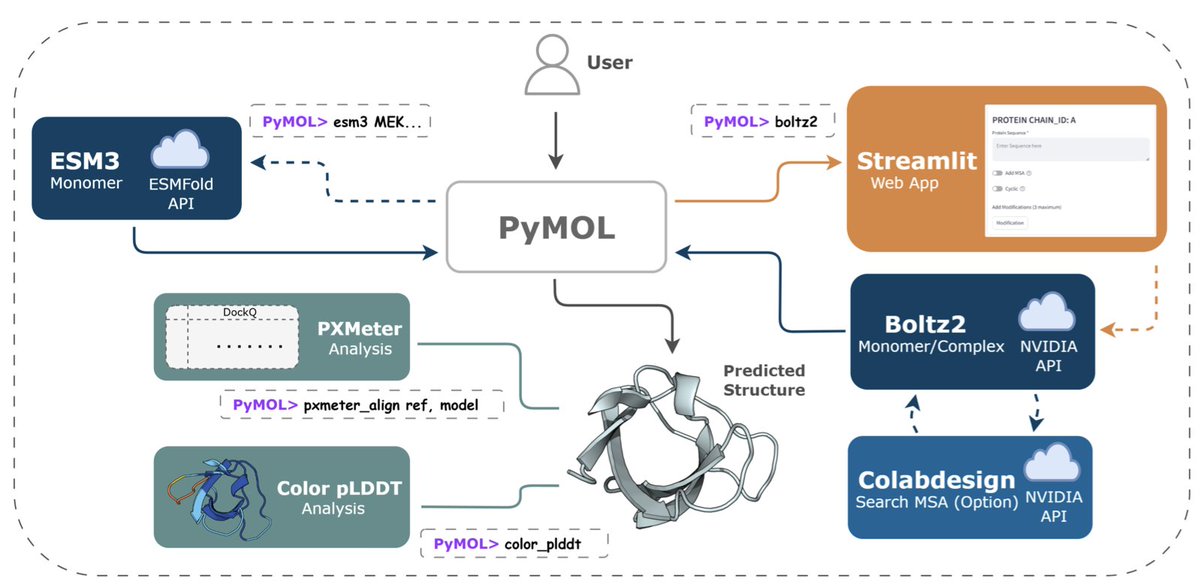
PymolFold: A PyMOL Plugin for API-driven Structure Prediction and Quality Assessment
1. PymolFold is a novel PyMOL plugin that integrates state-of-the-art protein structure prediction models like ESM-3 and Boltz2 into the PyMOL visualization environment, creating a unified workflow for prediction, visualization, and analysis. This integration significantly lowers the technical barriers for experimental scientists who lack specialized hardware or computational expertise.
2. The plugin offers both graphical and command-line interfaces, providing flexibility for users with different preferences. It incorporates PXMeter for immediate quantitative benchmarking against reference structures, enabling researchers to validate their structural hypotheses directly within PyMOL. This streamlined workflow accelerates the pace of discovery in structural biology and drug design.
3. PymolFold supports monomer and multimer predictions through API access, eliminating the need for local deployment of complex models. Case studies across proteins of varying lengths and complexities demonstrate that Boltz2 without MSA offers the fastest predictions for most typical proteins, while ESM-3 is more efficient for very large or multi-domain proteins. These insights help users choose the optimal workflow based on their specific needs.
4. The plugin’s architecture ensures that PyMOL remains responsive during background tasks such as API calls. It uses a multi-processed, non-blocking design, allowing users to continue working while predictions are being processed. This responsiveness is crucial for maintaining an efficient workflow in a dynamic research environment.
5. PymolFold also excels in complex system prediction and validation. For example, it successfully predicted the structure of the immune checkpoint protein PD-1 bound to a therapeutic Fab antibody fragment, achieving highly accurate interface metrics. The entire process, from sequence input to quantitative analysis, was completed in just a few minutes, highlighting the practical utility of PymolFold for complex systems.
6. The plugin is freely available for academic use on GitHub, along with detailed installation instructions and documentation. This accessibility ensures that a wide range of researchers can benefit from the advanced structural modeling capabilities offered by PymolFold.
📜Paper: biorxiv.org/content/10.1101/…
#PymolFold #ProteinStructurePrediction #StructuralBiology #DrugDesign #PyMOL #API #ComputationalBiology
1
39
204
8,877