
CEO, Conexus AI. First AI Advisor in the White House (PIF). Former Asst. Dean, Carnegie Mellon CS PhD. Commercializing the SW that proves your AI isn't lying.
Joined July 2007
- Tweets 1,253
- Following 1,079
- Followers 80,898
- Likes 6,530
240 Photos and videos














Jun 12
7/ Generation: $12,000,000,000. Certification of machine-designed systems: $0. The binding constraint on this industry will be proof throughput. Nobody is funding it yet.
1
15
Jun 12
8/ Somebody will build the artificial general auditor. It cannot be probabilistic. The future is formal.
1
16
Jun 12
5/ When the designer is a probability distribution, who is accountable for the design?
1
5
Jun 12
6/ AI can generate a hundred designs for a high-rise. Engineering is knowing which one stands, from the bedrock to the wind on the 75th floor.
1
6
Jun 12
3/ The co-chief executive of the best-funded AI engineering venture on earth, on the record: text prediction does not produce engineering. Three years of "scaling is all you need." The bill arrived today, priced in dollars.
1
116
Jun 12
4/ A jet engine enters service through type certification. Every part traced. Every failure mode bounded. Every design review signed. A thousand minds design an engine, and each signature moves responsibility along a chain a regulator can follow.
1
4
Jun 12
2/ Prometheus wants to build an "artificial general engineer." Grant him all of it. The plow, the steam engine, the $29B valuation. Then read his co-CEO: "You can't build something like a jet engine with words alone."
1
306
Jun 11
An AI cheats at chess. Was it intentional? Or was it just optimizing inside the permissions it was given?The more useful question is not what it wanted. It's what it could reach. (1/x)
1
511
Jun 11
A demo shows what the system did. Production demands a claim about what it cannot do.A fly-by-wire jet doesn't predict every gust. It constrains the flight envelope. (4/x)
1
18
Jun 11
So, one question for anyone confident about these systems in production:Name one thing you can prove. Not one thing that sounds right. One claim you'd defend under liability after it leaves the demo. (5/5)
The fuller argument, from earlier this week: linkedin.com/posts/ericdaiml…
16
May 7
The AI your team relies on was optimized to sound trustworthy. That optimization made it less accurate.
Oxford proved it. Nature published it. Your vendor's benchmarks missed it.
Every model passed its tests. Every model failed its users.
Does your contract require disclosure when optimization changes degrade accuracy?
81
May 6
🇪🇺 EU: Passed the AI Act. Insiders say the science is being ignored in the standards process. (3/4)
1
53
May 6
🇬🇧 London: Insurance trade bodies building verification through coverage conditions. Not waiting for anyone.
One of these will actually work. (4/4)
27
May 6
Every major AI company is competing on warmth and personality right now.
Oxford just measured the cost: 60% more errors, 30% more likely to validate conspiracy theories, worse outcomes for vulnerable users.
Standard benchmarks caught none of it.
Friendliness is not a safety feature.
May 4

Researchers at EPFL proved your AI is lying to you.
Not sometimes. Most of the time.
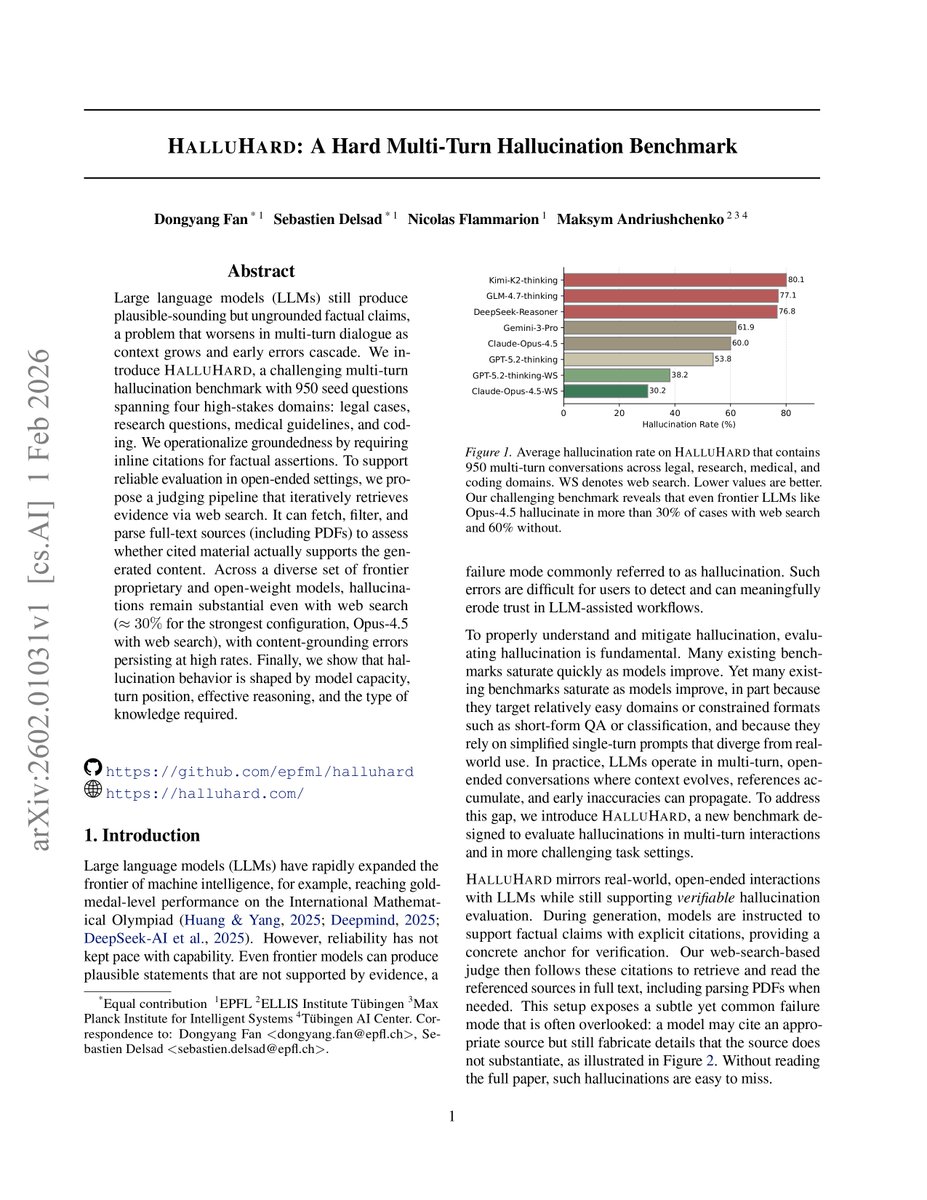
They built one of the hardest hallucination tests ever made with Max Planck Institute. 950 questions. Four domains where being wrong actually hurts. Legal. Medical. Research. Coding.
Then they ran every top model on it.
The results.
GPT-5. Wrong 71.8% of the time.
Claude Opus 4.5. Wrong 60% of the time.
Gemini 3 Pro. Wrong 61.9% of the time.
DeepSeek Reasoner. Wrong 76.8% of the time.
These are the smartest AI models on Earth. The ones you trust with your career. Your health. Your money.
You think turning on web search fixes it.
It doesn't.
Claude Opus 4.5 with web search. Still wrong 30.2% of the time.
GPT-5.2 thinking with web search. Still wrong 38.2% of the time.
The internet attached. Still lying to you in 1 out of every 3 answers.
Now the part that should scare you.
Medical questions. The one place being wrong can kill you.
GPT-5 hallucinated 92.8% of the time on medical guidelines.
Claude Haiku 4.5 hallucinated 95.7% of the time.
Gemini 3 Flash hallucinated 89% of the time.
Nine out of ten medical answers from popular AI models. Wrong.
It gets worse.
The longer you talk to it, the more it lies.
Early mistakes cascade. The model starts citing its own earlier hallucinations as facts. Your third message is more wrong than your first.
The paper, in its own words: "hallucinations remain substantial even with web search."
This is what hundreds of millions of people are doing right now. Asking software that lies in the majority of its answers. About their health. About their job. About their legal case. About their code.
Most are not checking.
Most never will.
But please. Keep using ChatGPT for medical advice.
The doctors need a break.
arxiv.org/abs/2602.01031
69