
163 Photos and videos


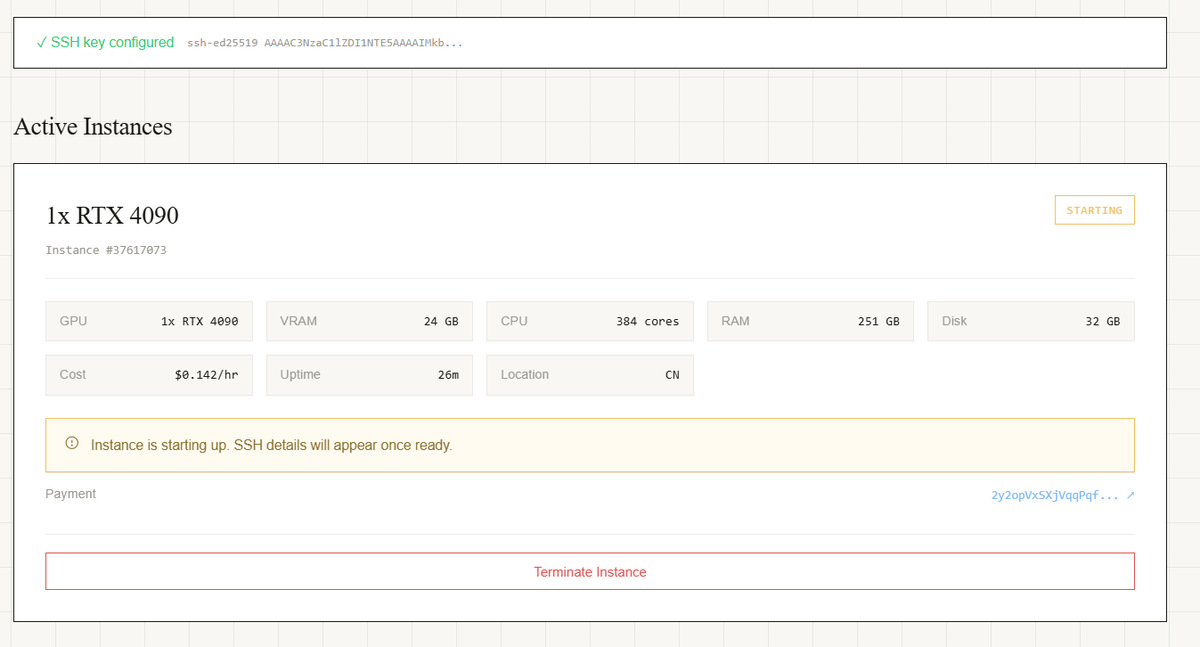












Pecolator's advantages: (1) Full circulation, thorough market cleansing; (2) Profit buyback and pooling.
Disadvantages: This is just a lab prototype; its successful launch is unknown.

这轮熊市要证明,去中心化永续合约交易所不属于币圈,是新的资本市场。 $pecolator percolator.trade/r/XT217YRK
2
1
51
Also, those who missed out on Hype will use it as leverage. Percolator is somewhat competitive with Hype. It's more decentralized.
This bear market needs to prove that decentralized perpetual contract exchanges don't belong to the crypto world, but represent a new capital market
24
Conspiracy: Gate.io added it to the alpha early on and may heavily support it. We'll know once the funding announcement is released.
13
这轮熊市要证明,去中心化永续合约交易所不属于币圈,是新的资本市场。 $pecolator percolator.trade/r/XT217YRK
67
Last year's JELLY ,A low-liquidity meme contract exposed the Achilles' heel of HLP's mechanism;
Subsequently, centralized exchanges amplifying the crisis into a market-wide crackdown.
That moment sealed the fate of the Percolator legend:percolator.trade/r/XT217YRK
16
去年 JELLY 事件,是 Hyperliquid 的至暗时刻。
一个低流动性 meme 合约,打穿了 HLP 的机制软肋;
随后币安、欧易等中心化交易所迅速上线 JELLY 合约,把这场危机放大成全市场围猎。
那一刻,注定了Percolator传奇的诞生:percolator.trade/r/XT217YRK
39
Comparison of Pearl Research and DynexCoin’s QDLLM in Large Language Model (LLM) Inference。
Pearl Research and DynexCoin’s QDLLM are both innovative projects combining blockchain and AI computing, but they differ significantly in core positioning and technical approaches.
5
69
Dynex QDLLM: Quantum-Diffusion LLM, a new architectural LLM model rather than pure infrastructure. It is based on a Diffusion Model Quantum-enhanced hybrid approach (early stages use quantum/quantum-inspired optimization for token selection, followed by classical refinement).
18
@dynexcoin @DynexQaaS @DynexGPT 1. Core Technical Foundation — Similarities and Differences
Similarities:
Both aim to improve the practicality and efficiency of LLM inference while integrating it with blockchain/decentralized computing.
21