
@snsf_ch PRIMA assistant professor at @cl_uzh. Views my own. She/her. @echodroff@sigmoid.social
Joined January 2010
- Tweets 4,030
- Following 855
- Followers 2,329
- Likes 15,290
169 Photos and videos












Eleanor Chodroff retweeted

Apr 23
Announcing the #ICLR2026 Outstanding Paper Awards 🏆 Congratulations to:

7
98
1,014
85,912

Feb 21
📢Phoneticians/phonologists: CorpusPhon is happening again this year at LabPhon in Montreal! Submissions due Friday March 13th. Hope to see you there!
sites.google.com/view/corpus…
1
2
7
436
Eleanor Chodroff retweeted

8 Dec 2025
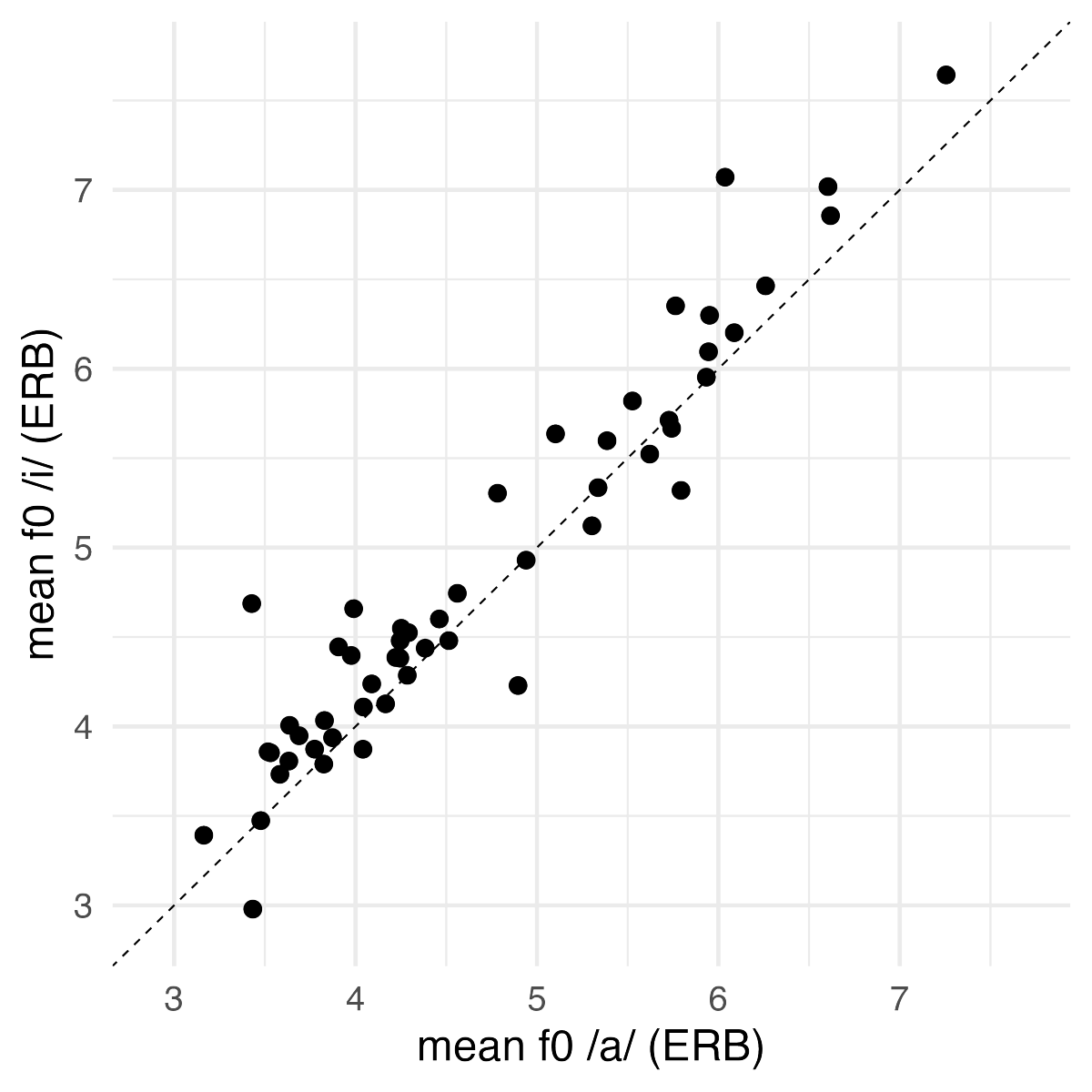
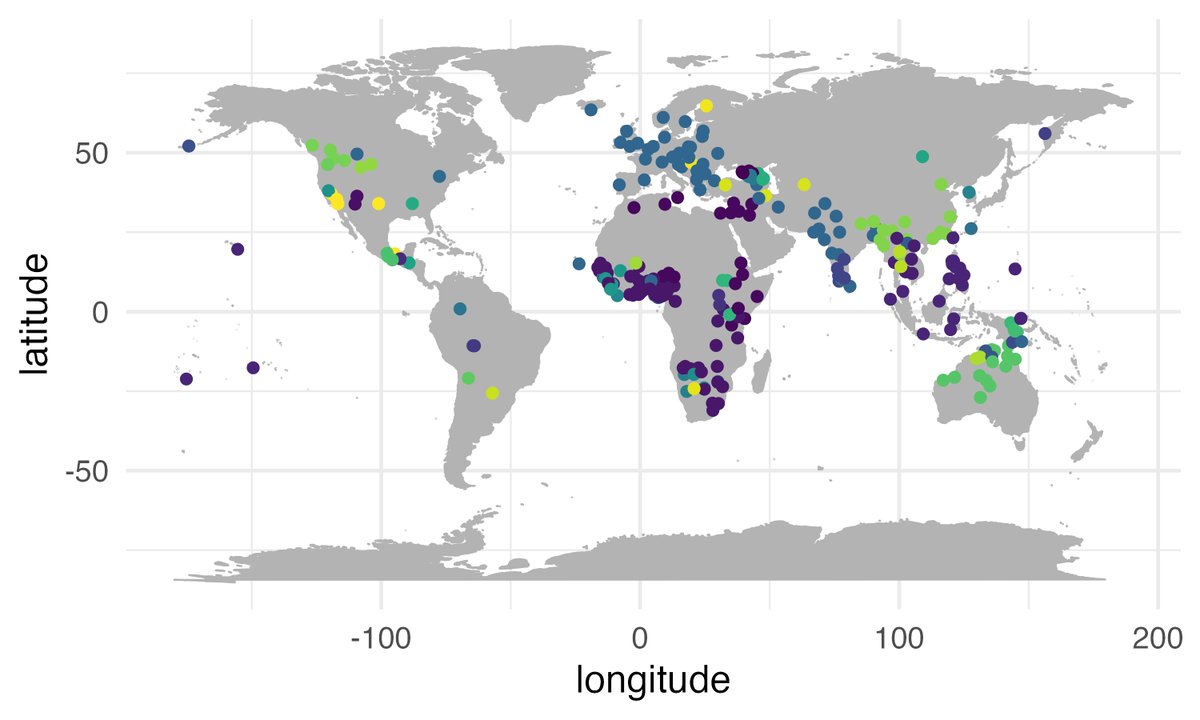
🤯 Speech Universal Uncovered! 🎤
We analyzed over 60,000 speakers across 75 languages and confirmed a universal phonetic bias: High vowels (like /i, u/) are consistently spoken with a slightly higher pitch (F0) than low vowels (/a/).
1
2
9
387
Eleanor Chodroff retweeted

13 Nov 2025
Very productive visit to the Zurich Phonetics and Speech Sciences (PaSS) doctoral colloquium yesterday- special thanks to @Allesandro De Luka for the invitation and looking after the logistics


1
3
462
Eleanor Chodroff retweeted

29 Oct 2025
If you are curious about Plastic Mandarin, feel free to check out my new paper: degruyterbrill.com/document/…
#phonetics #citationtone #linguistics
2
4
470
Eleanor Chodroff retweeted

27 Oct 2025
Investigations of #phonetic universals have been limited by challenges in crosslinguistic data collection. Prof Chodroff @echodroff @cl_uzh will discuss advances in phonetic databases & two case studies on vowel f0 & duration. Register 👉 polyu.hk/fqkuy @OpenAppLing

1
2
278
Eleanor Chodroff retweeted

15 Oct 2025
🎙️ Come and work with us, we offer a paid Research Internship position in building a universal phonetizer system for next-generation Voice AI systems!
🇨🇭 We are young and nice team located in Zurich.
📃 Possibility to publish results of the internship.
agigo.ai/job-openings/resear…
2
1
337
Eleanor Chodroff retweeted
2 Oct 2025
🎉 We're hiring Research Interns at AGIGO, in the hottest AI hub in Europe: Zurich Switzerland!
AGIGO is looking for talented interns to join our Speech AI Team and work on the next generation of voice AI.
linkedin.com/posts/pablo-zul…
6
2
5
767
Eleanor Chodroff retweeted
2 Oct 2025
🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
🚨🚨🚨🚨 INTERNSHIP ALERT IN AI 🚨🚨🚨🚨
🚨🚨🚨🚨 ZURICH, SWITZERLAND 🚨🚨🚨🚨
🚨🚨🚨🚨 AGIGO 🚨🚨🚨🚨
🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
x.com/Pablogomez3/status/197…
AND
x.com/Pablogomez3/status/197…
2 Oct 2025

🎉 We're hiring Research Interns at AGIGO, in the hottest AI hub in Europe: Zurich Switzerland!
AGIGO is looking for talented interns to join our Speech AI Team and work on the next generation of voice AI.
linkedin.com/posts/pablo-zul…
2
3
412
2 Oct 2025
Excited to share a new preprint with @Miao_Zhang_dr: “A crosslinguistic corpus phonetic analysis of intrinsic vowel duration” 🎉
🔗osf.io/preprints/psyarxiv/xc…
1
5
7
961
2 Oct 2025
The differences are small but consistent in direction, supporting a biomechanical account critically tied to uniform phonetic targets across vowels. At the same time, variation in effect size across languages suggests speakers differ in how strongly this uniformity is realized
1
1
119
29 Aug 2025
🗣️Mozilla Common Voice users!🗣️
Important notice: the client ID does not always correspond to a single speaker ID! Every so often, a single client ID contains more than one speaker’s voice. Our #Interspeech2025 paper examines the extent of this problem and proposes a solution
1
3
14
608
29 Aug 2025
Pairs below this were more likely perceived as different speakers and above, as the same speaker. Of course there’s no ground truth, so you can also choose your own threshold
The similarity scores, paper, and code can be found at the below links
Happy data cleaning 😊
1
2
151
29 Aug 2025
✅Similarity scores: huggingface.co/datasets/pacs…
📄Paper: isca-archive.org/interspeech…
💻Code: github.com/pacscilab/CV_clie…
💫This was joint work with @Miao_Zhang_dr, Aref Farhadipour, Annie Baker, Jiachen Ma, and Bogdan Pricop
1
4
345
Eleanor Chodroff retweeted

28 Aug 2025
✨Meet OLMoASR✨ By pairing our curated 1M-hour dataset with a powerful architecture, we've built open ASR models that achieve competitive performance with models like Whisper. We're open-sourcing data, code and models to help the community build more robust and transparent ASR.

🎙️ Say hello to OLMoASR—our fully open, from-scratch speech-to-text (STT) model. Trained on a curated audio-text set, it boosts zero-shot ASR and now powers STT in the Ai2 Playground. 👇
3
15
82
12,544