
Research VP @ GoogleDeepMind. ACM Fellow.
Joined October 2007
- Tweets 10,540
- Following 3,825
- Followers 12,937
- Likes 13,406
938 Photos and videos














Hanging out with @lmthang and @YiTayML for multiple days in Vietnam and Google Singapore.
And great event with @newturing on AI and humanity.
Thank you for hosting!!
4
31
13,017
Ed H. Chi retweeted

May 20
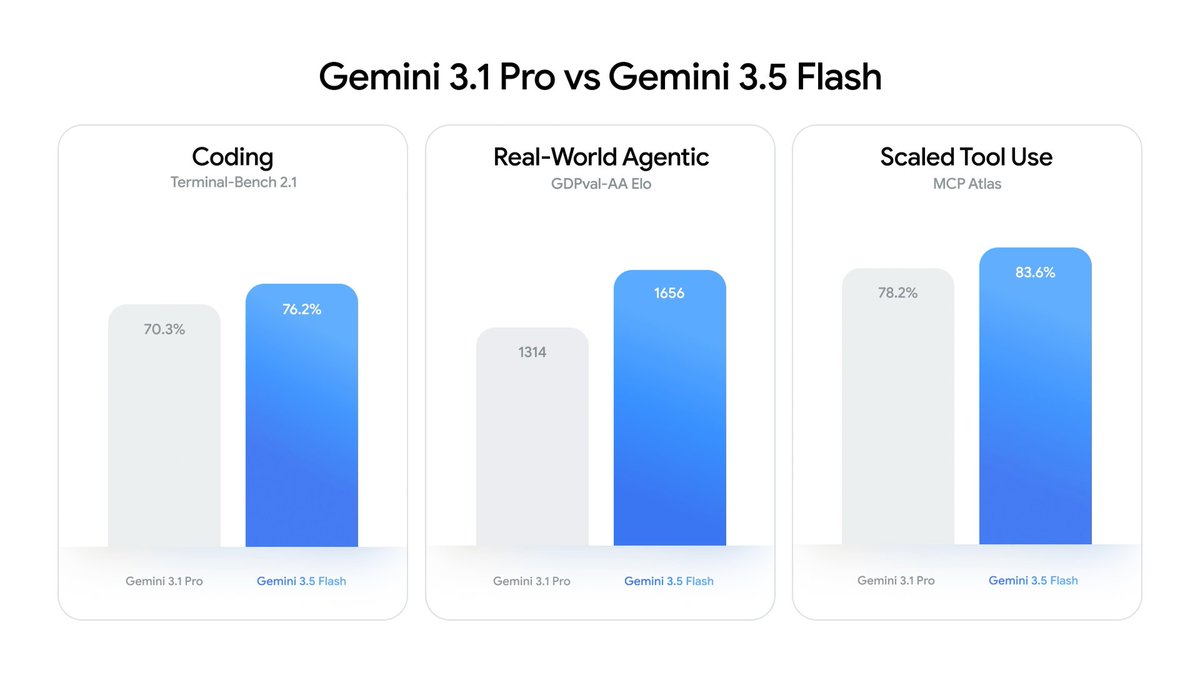
Gemini 3.5 Flash is amazing!
- Performs better than 3.1 Pro on coding & agentic tasks
- 4x faster than other frontier models
- 12x faster in @antigravity - 800 tokens/sec!
- Often at less than half the cost
And Pro to come…
Try it in @antigravity, @GeminiApp & more - enjoy!
315
261
3,203
258,828
Ed H. Chi retweeted

Dr. @edchi will join GStar Summit 2026 for a keynote on foundation models and a panel discussion on frontier AI.
Website for program details and ticket registration: summit.newturing.ai/
Be part of the conversation!

1
10
678
Related: github.com/juliusbrussee/cav…
"Claude Code skill & Codex plugin that makes agent talk like caveman — cutting ~75% output tokens while keeping full technical accuracy. Now with 文言文 mode, terse commits, one-line code reviews, and compression tool that cuts ~46% tokens."

A Hypothesis: Agents of the future could communicate to each other using thought tokens.
Corollary: Humans will have to decode those thought tokens in order to find out what the agents are doing with each other.
Note: GenZers are already doing this with their slang. No Cap.
1
3
1,202
A Hypothesis: Agents of the future could communicate to each other using thought tokens.
Corollary: Humans will have to decode those thought tokens in order to find out what the agents are doing with each other.
Note: GenZers are already doing this with their slang. No Cap.
1
5
2,190
Ed H. Chi retweeted

Feb 25
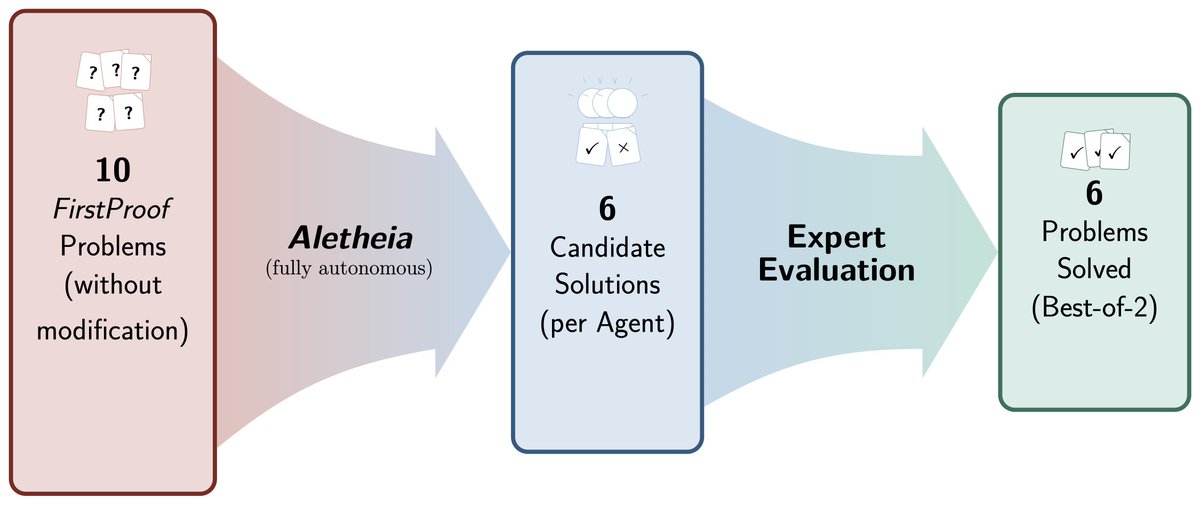
Thrilled to share: #Aletheia, our math research agent, just solved 6/10 notoriously hard FirstProof problems autonomously, the best result in the inaugural challenge! To me, this is even bigger than our historic IMO-gold achievement last year; these problems challenge even top mathematicians. We share our results transparently, see paper and full thoughts in the thread. 👇
30
153
923
161,444
In the social media era, kids actually feel more loneliness---ironically.
As a former social computing researcher, this is deeply depressing to me.
freerangekids.com/surge-in-c…
h/t Kristina Lerman #WSDM 2026 keynote
7
548
Thanks for this recognition, Mike.
/cc @denny_zhou @quocleix
Feb 11

The original CoT paper ("lets think step by step") from Jan 2022 is equally important as the Transformer ("attention is all you need"). arxiv.org/abs/2201.11903
3
2
19
7,840

Announcing Personal Intelligence, a more personalized @GeminiApp designed just for you.
How it works:
— Customized: With your permission, it reasons across your @Gmail, @YouTube, @GooglePhotos, and Search apps to share hyper-relevant and context-aware responses
— Secure: If enabled, you control which Google apps to connect to. This setting is off by default
— Useful: From travel plans based on your Google Photos to gym recommendations based on goals you’ve shared with Gemini, you get help tailored to your world
Personal Intelligence in beta is rolling out to Google AI Pro and AI Ultra subscribers in the U.S., with expansions to the free tier, more countries, and AI Mode in Search to come. Take a look at the Gemini app's personalized assistance in the clip below, then let us know what you would use it for!
114
243
2,226
320,106
Ed H. Chi retweeted

Jan 12
Joint Statement: Apple and Google have entered into a multi-year collaboration under which the next generation of Apple Foundation Models will be based on Google's Gemini models and cloud technology. These models will help power future Apple Intelligence features, including a more personalized Siri coming this year.
After careful evaluation, Apple determined that Google's Al technology provides the most capable foundation for Apple Foundation Models and is excited about the innovative new experiences it will unlock for Apple users. Apple Intelligence will continue to run on Apple devices and Private Cloud Compute, while maintaining Apple's industry-leading privacy standards.
1,540
6,394
51,767
11,010,936
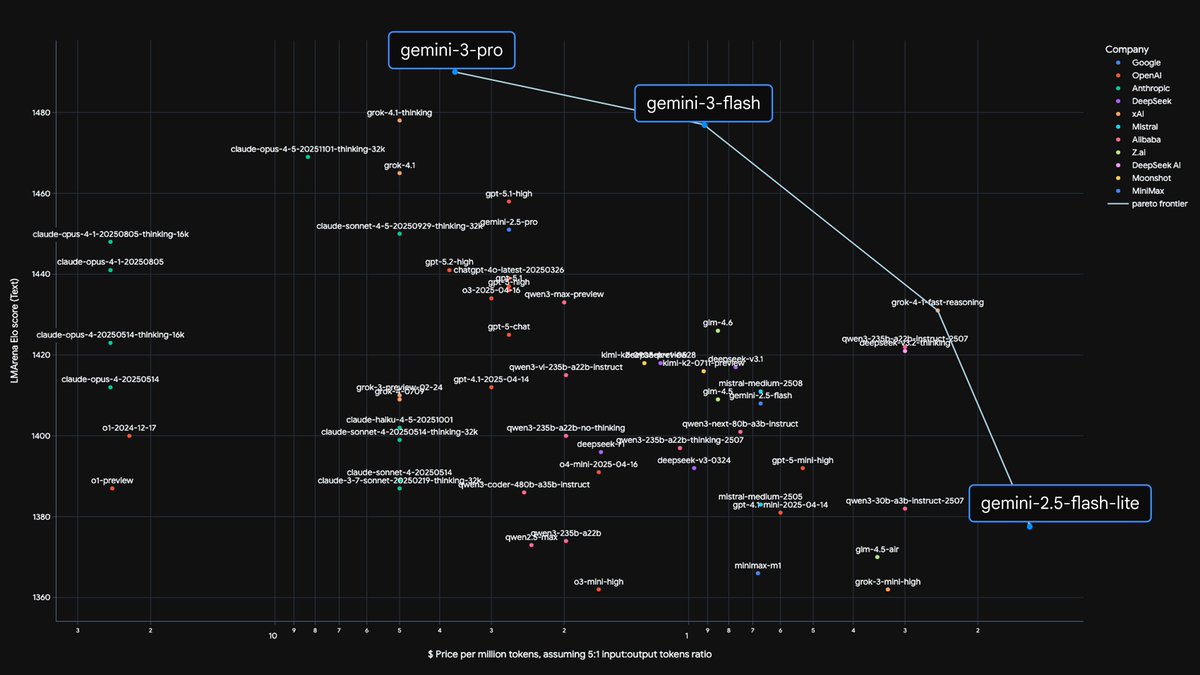
I remember having this debate on small vs large models a little less than 3 years ago. Amazing.

We’ve pushed out the Pareto frontier of efficiency vs. intelligence again.
With Gemini 3 Flash ⚡️, we are seeing reasoning capabilities previously reserved for our largest models, now running at Flash-level latency. This opens up entirely new categories of near real-time applications that require complex thought.
It’s available in the API, and rolling out today as the default model in AI Mode in Search and Gemini app globally.
Read more on the blog at: bit.ly/4pTo5YU
More in thread ⬇️
6
936
Ed H. Chi retweeted

14 Dec 2025
Ilya said the quiet part out loud on Dwarkesh's pod, but most people still aren't processing what it means.
Here's what's actually happening inside AI labs.
Research teams have entire divisions that do nothing but create new RL training environments specifically designed to boost benchmark scores. They treat AIME, SWE-bench, and MMLU like standardized tests. The model practices 10,000 hours on competitive programming problems until every proof technique is at its fingertips.
Then it fails to fix a simple bug in production without introducing two new ones.
Sutskever used the perfect analogy. Student A grinds 10,000 hours of competitive programming. Memorizes every algorithm, every edge case, every proof technique. Becomes the #1 ranked competitive coder in the world. Student B practices 100 hours but has "it." Intuition. Taste. The ability to learn new things quickly.
Who has the better career? Student B. Current AI models are all Student A.
The benchmark gaming runs deeper than most realize. Studies have shown data contamination inflates model scores by 20-80% on popular benchmarks. The training-test boundary is porous. Models memorize answers rather than learn concepts. And when you control for contamination, much of what looks like intelligence is pattern-matching on seen data.
This explains the economic puzzle Ilya pointed to. Models score 100% on AIME 2025. They hit 70% on GDPval beating human professionals. Yet businesses still struggle to extract value. The benchmark performance says genius. The P&L says otherwise.
The sample efficiency gap tells you everything. A human teenager learns to drive any car after 10 hours. An AI model might need millions of examples and still fail on slight variations. A human learns a concept once and applies it everywhere. Models need to see the exact pattern thousands of times and still choke when the formatting changes slightly.
Sutskever's diagnosis: we're moving from the "age of scaling" (2020-2025) back to the "age of research." The belief that 100x more compute would transform everything is dying. His $3B company SSI is betting that the next breakthrough comes from solving generalization, not stacking more GPUs.
The labs know this.
That's why the benchmark arms race is accelerating.
It's easier to show impressive numbers than admit the fundamental approach might be plateauing.
13 Dec 2025

Ilya is 100% correct .it's a pattern that keeps repeating
It's very clear with GPT5.2
Overfit the model to produce impressive looking benchmarks, have it excels in a few domains, but fall flat in many others.
There's not enough generalization, and even if there is, the model has been so heavily reinforced that it becomes buried .
92
295
2,082
322,787
Ed H. Chi retweeted

20 Nov 2025
We just dropped Nano Banana Pro, built on Gemini 3. 🍌
With state-of-the-art text rendering, vast world knowledge and studio-quality creative controls, Gemini 3 Pro Image can create and edit more complex visuals, infographics and more. Here’s what’s under the hood. 🧵
164
579
3,821
1,460,622