
Joined May 2011
- Tweets 344
- Following 54
- Followers 151
- Likes 1,013
52 Photos and videos















Jun 13
Interesting paper this week
Jun 13

This week we had the pleasure of @romovpa presenting "Claudini: Autoresearch Discovers State-of-the-Art Adversarial Attack Algorithms for LLMs" arxiv.org/pdf/2603.24511
He showed us how auto-research (i.e. Claude Code in a loop, equipped with a simple benchmark) can discover attack algorithms on LLMs better than hand-crafted SOTAs. "Attack" here is a prefix added to a prompt that would lead to a fixed string in the output of an LLM with high probability; LLM is a white box with known weights.
Some takeaways:
1. Without seeding this autoresearch with multiple hand-written attacks, it does not work — it combines ideas, but does not come up with novel ideas.
2. Autoresearch does much better than hparam search only.
3. Plenty of options for reward hacking — need to design benchmark with autoresearch in mind.
4. Kimi performed no worse than Claude or Gemini in this task.
5. Always useful to run autoresearch if you have a benchmark to optimise as it is so low effort and powerful.

60
Edward Matthews retweeted

Jun 13
I do find it extraordinary that current events in AI don’t make the top ~30 stories on the BBC News homepage
95
118
1,589
172,641
Jun 13
I think the scientific concept I most undervalued at school was measurement error, I found it such a chore at the time.
1
31
Edward Matthews retweeted

Jun 9
Grasp Paper Club reviewed Prolonged Reasoning Is Not All You Need: Certainty-Based Adaptive Routing for Efficient LLM/MLLM Reasoning (arxiv.org/pdf/2505.15154) last week.
- Our concise summary -
Sometimes it’s enough to have a short answer. We can train a model to provide short or long answers. Based on the perplexity of the short answer, we can decide if we should switch to long answer. Their solution and literature review of SoTA could be improved.

1
1
64
Jun 4
I made such a good introductory lesson today on the "Problem of Universals" and how it pervades into positions on AI
paths.grasp.study/lessons/e1…
Jun 4
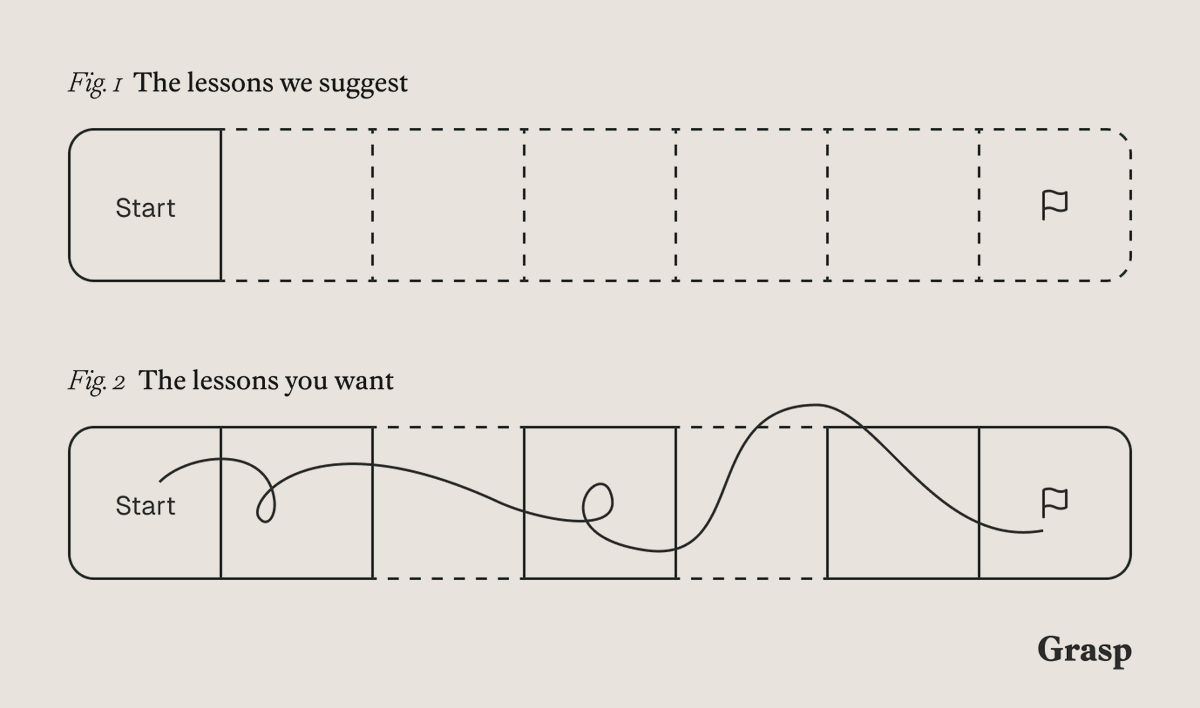
Grasp builds your learning path. Now you can choose which lessons to create, and when. 30 minutes to an hour of focused learning, ready when you are.
1
3
199
Jun 4
This resource in particular has been really interesting, and I'm only at the introduction bu.edu/wcp/Papers/Mind/MindP…
62

Jun 2
no cmon claude use use tavily fetch en.wikipedia.org/wiki/How_to…
May 29

Here’s the honest read. Here’s the real consideration. This is the genuine tradeoff. Here’s the honest answer. Here’s the key insight. This is the crux of the question. It’s worth flagging this. It’s not one or the other. Here’s what’s actually happening.
Shut the fuck up.
136
May 31
.@stripe Sigma coding workflow sucks rn. Inbuilt ai tooling is 18 months behind in performance, gpt/claude dont have enough context
2
1
455
May 31
okay single 'l' cancelled is the worst yet
May 28

sorry, maths
coding in american english is ruining me
70


Edward Matthews retweeted

May 29
Yes, AIs are going to do all or almost all of the pure theory, but tbh humans probably finished most of the pure theory that it's possible for humans to do by the end of the 20th century. Yes there has been some recent theory progress but let's be honest, most is of marginal economic value at best. There's probably lots of useful pure theory left to do in this universe, but it's probably not the kind of stuff that can be intuited by a single human, explained to a grad student, and written down in a textbook. AI will do all that stuff.
35
16
223
73,149