The Moore's Law Update
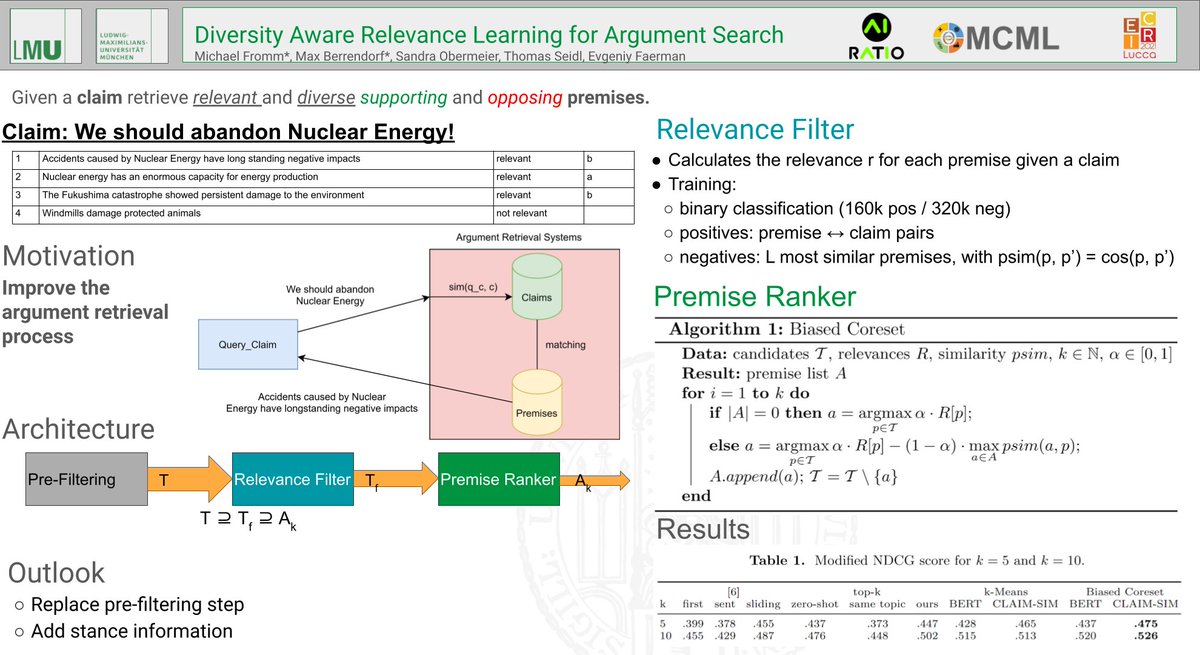
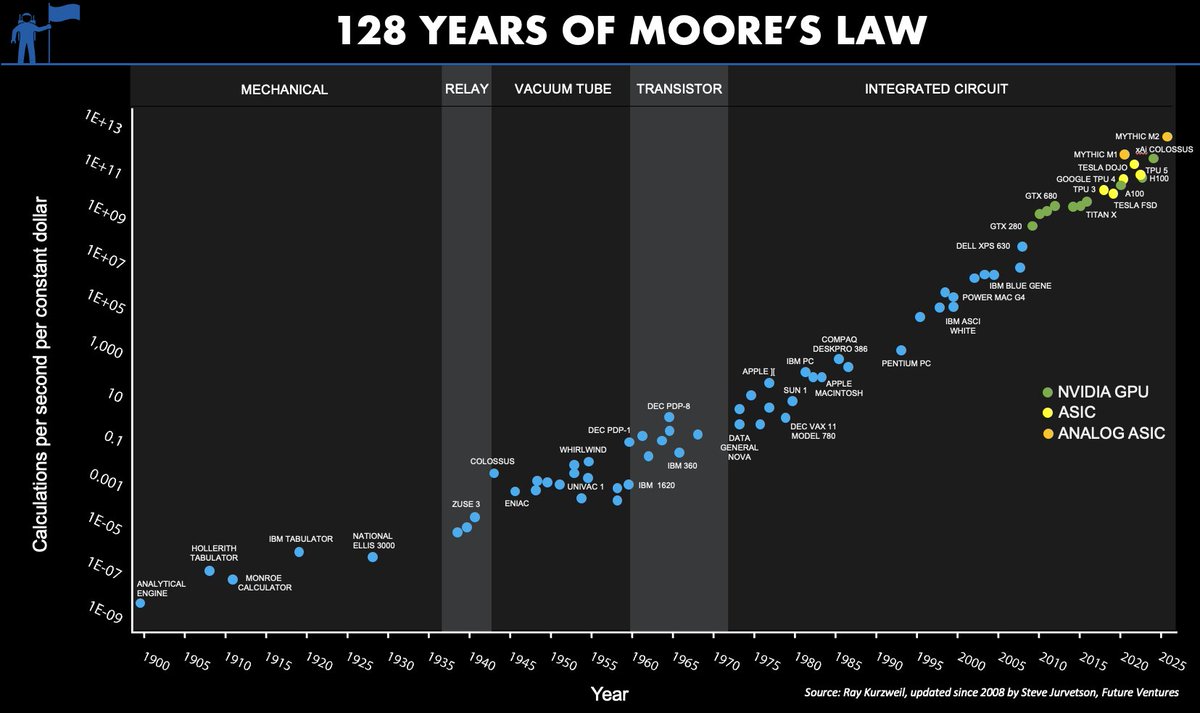
NOTE: this is a semi-log graph, so a straight line is an exponential; each y-axis tick is 100x. This graph covers a 1,000,000,000,000,000,000,000x improvement in computation/$. Pause to let that sink in.
Humanity’s capacity to compute has compounded for as long as we can measure it, exogenous to the economy, and starting long before Intel co-founder Gordon Moore noticed a refraction of the longer-term trend in the belly of the fledgling semiconductor industry in 1965.
I have color coded it to show the transition among the integrated circuit architectures. You can see how the mantle of Moore's Law has transitioned most recently from the GPU (green dots) to the ASIC (yellow and orange dots), and the NVIDIA Hopper architecture itself is a transitionary species — from GPU to ASIC, with 8-bit performance optimized for AI models, the majority of new compute cycles.
There are thousands of invisible dots below the line, the frontier of humanity's capacity to compute (e.g., everything from Intel in the past 15 years). The computational frontier has shifted across many technology substrates over the past 128 years. Intel ceded leadership to NVIDIA 15 years ago, and further handoffs are inevitable.
Why the transition within the integrated circuit era? Intel lost to NVIDIA for neural networks because the fine-grained parallel compute architecture of a GPU maps better to the needs of deep learning. There is a poetic beauty to the computational similarity of a processor optimized for graphics processing and the computational needs of a sensory cortex, as commonly seen in the neural networks of 2014. A custom ASIC chip optimized for neural networks extends that trend to its inevitable future in the digital domain. Further advances are possible with analog in-memory compute, an even closer biomimicry of the human cortex. The best business planning assumption is that Moore’s Law, as depicted here, will continue for the next 20 years as it has for the past 128. (Note: the top right dot for Mythic is a prediction for 2026 showing the effect of a simple process shrink from an ancient 40nm process node)
----
For those unfamiliar with this chart, here is a more detailed description:
Moore's Law is both a prediction and an abstraction. It is commonly reported as a doubling of transistor density every 18 months. But this is not something the co-founder of Intel, Gordon Moore, has ever said. It is a nice blending of his two predictions; in 1965, he predicted an annual doubling of transistor counts in the most cost effective chip and revised it in 1975 to every 24 months. With a little hand waving, most reports attribute 18 months to Moore’s Law, but there is quite a bit of variability. The popular perception of Moore’s Law is that computer chips are compounding in their complexity at near constant per unit cost. This is one of the many abstractions of Moore’s Law, and it relates to the compounding of transistor density in two dimensions. Others relate to speed (the signals have less distance to travel) and computational power (speed x density).
Unless you work for a chip company and focus on fab-yield optimization, you do not care about transistor counts. Integrated circuit customers do not buy transistors. Consumers of technology purchase computational speed and data storage density. When recast in these terms, Moore’s Law is no longer a transistor-centric metric, and this abstraction allows for longer-term analysis.
What Moore observed in the belly of the early IC industry was a derivative metric, a refracted signal, from a longer-term trend, a trend that begs various philosophical questions and predicts mind-bending AI futures.
In the modern era of accelerating change in the tech industry, it is hard to find even five-year trends with any predictive value, let alone trends that span the centuries.
I would go further and assert that this is the most important graph ever conceived. A large and growing set of industries depends on continued exponential cost declines in computational power and storage density. Moore’s Law drives electronics, communications and computers and has become a primary driver in drug discovery, biotech and bioinformatics, medical imaging and diagnostics. As Moore’s Law crosses critical thresholds, a formerly lab science of trial and error experimentation becomes a simulation science, and the pace of progress accelerates dramatically, creating opportunities for new entrants in new industries. Consider the autonomous software stack for Tesla and SpaceX and the impact that is having on the automotive and aerospace sectors.
Every industry on our planet is going to become an information business. Consider agriculture. If you ask a farmer in 20 years’ time about how they compete, it will depend on how they use information — from satellite imagery driving robotic field optimization to the code in their seeds. It will have nothing to do with workmanship or labor. That will eventually percolate through every industry as IT innervates the economy.
Non-linear shifts in the marketplace are also essential for entrepreneurship and meaningful change. Technology’s exponential pace of progress has been the primary juggernaut of perpetual market disruption, spawning wave after wave of opportunities for new companies. Without disruption, entrepreneurs would not exist.
Moore’s Law is not just exogenous to the economy; it is why we have economic growth and an accelerating pace of progress. At Future Ventures, we see that in the growing diversity and global impact of the entrepreneurial ideas that we see each year — from automobiles and aerospace to energy and chemicals.
We live in interesting times, at the cusp of the frontiers of the unknown and breathtaking advances. But, it should always feel that way, engendering a perpetual sense of future shock.