
Where developers learn, build, and share. Elastic Dev is your source for hands-on demos, cheat sheets, explainers and more. Check out: @elastic
Joined October 2025
- Tweets 544
- Following 51
- Followers 3,298
- Likes 295
324 Photos and videos










Pinned Tweet

20 Oct 2025
👋 Welcome to Elastic Dev — your new go-to for hands-on demos, cheat sheets, concept explainers and more. Get the latest on search, data, and GenAI straight from the source.
Expect:
- Practical demos and how-tos
- Posts and technical deep dives from our Labs
- Open source updates
& more
For anyone who loves building, learning and experimenting: let's get started. Hello, world.
14
14
78
50,348

3 types of mappings in Elasticsearch
Dynamic: Elasticsearch detects field types as documents arrive.
Explicit: you define every field upfront. Recommended for production.
Runtime: schema-on-read, no reindexing needed.
Each trades setup speed for indexing control.

1
6
21
1,832
Stop building dummy data to test Elasticsearch.
Kibana ships three production-quality sample datasets. One click to install, dashboards included:
- Sample eCommerce orders: customer transactions, product categories, revenue by region
- Sample flight data: airline routes, ticket prices, delay metrics, geographic maps
- Sample web logs: HTTP requests, response codes, geoIP, error rates
Each one comes with pre-built visualizations and a full dashboard out of the box.
Open Kibana, go to Integrations, search Sample Data, click Install.
Real data. Real dashboards. No setup required.
2
6
15
2,151
🧵 Your PromQL doesn't have to be rewritten to move to Elastic Observability.
9.4 added native Prometheus support.
Ship metrics straight to ES, run your existing PromQL in Kibana.
Same queries. Same dashboards.
rate(http_requests_total{job="api"}[5m])
That runs in Kibana now. No rewrite. Native PromQL is in technical preview.

1
3
13
1,537
Here are 5 distance metrics in vector search.
But how do you choose the right one?
• L1 (Manhattan): sum of absolute differences, exact kNN only with no HNSW support
• L2 (Euclidean): straight-line distance, the safe default for most models
• Cosine similarity: angle between vectors, magnitude ignored
• Dot product: same ranking as cosine on normalized vectors, less compute
• Max inner product: dot product without the normalization constraint
Most teams default to cosine and move on. That works until your model outputs non-normalized vectors, and suddenly dot product or max inner product is the better fit.
Scoring formulas and config details in the blog.

39
85
1,045
9,583,222

Elastic Dev retweeted

Attackers are compressing timelines from hours to minutes. Most SOCs are still stitching context together across three tabs and a ticket.
On June 17, we're showing the full lifecycle, from first alert to staged response, with AI agents handling triage, enrichment, and investigation live. Prizes too.
Save your seat: go.es.io/4ahK4D9
1
3
9
2,287
🧵 K8s alert fires while you're dreaming of electric sheep.
Pods, then nodes, then logs, then metrics.
By the time you've reconstructed context, the clock's already run.
Elastic 9.4 shipped two things that change this workflow:
A Kubernetes observability MCP app, and agentic investigation in Kibana.
3
3
13
2,465
May 28
DiskBBQ now quantizes queries 5x faster. Coarser centroids for the query, fine ones for documents.
Query quantization drops from 20% of cost to 4%, recall stays put.

1
137
May 27
Most search apps get reworked three weeks in because the mapping was a guess.
🧵 Every Elasticsearch app starts with the same guesswork: BM25, semantic, or hybrid search.
You pick a mapping strategy before you understand your own data. Three weeks later, you're reworking it.
9.4 ships an onboarding assistant that inspects your data first, then recommends the approach.
It runs in Cursor, Claude Code, and Kibana.
1
145
May 26
The best dashboard is the one you didn't have to stop mid-investigation to build.
Building a dashboard mid-investigation means losing the thread you were pulling.
Open the editor, pick indices, configure panels, wire up ES|QL queries.
That's ten minutes of context switching before you've answered a single question.
Kibana skips that now.
• Describe what you need in plain language.
• The agent explores your indices, generates ES|QL, picks chart types, and lays out the panels.
Everything stays in your conversation until you save it.
Then it becomes a first-class Kibana object your team can open and edit.
Already viewing one? The agent attaches automatically.
Ask why a metric spiked, add a comparison panel, break it down by region: all inline.
Available as a technical preview in Elastic 9.4
3
187
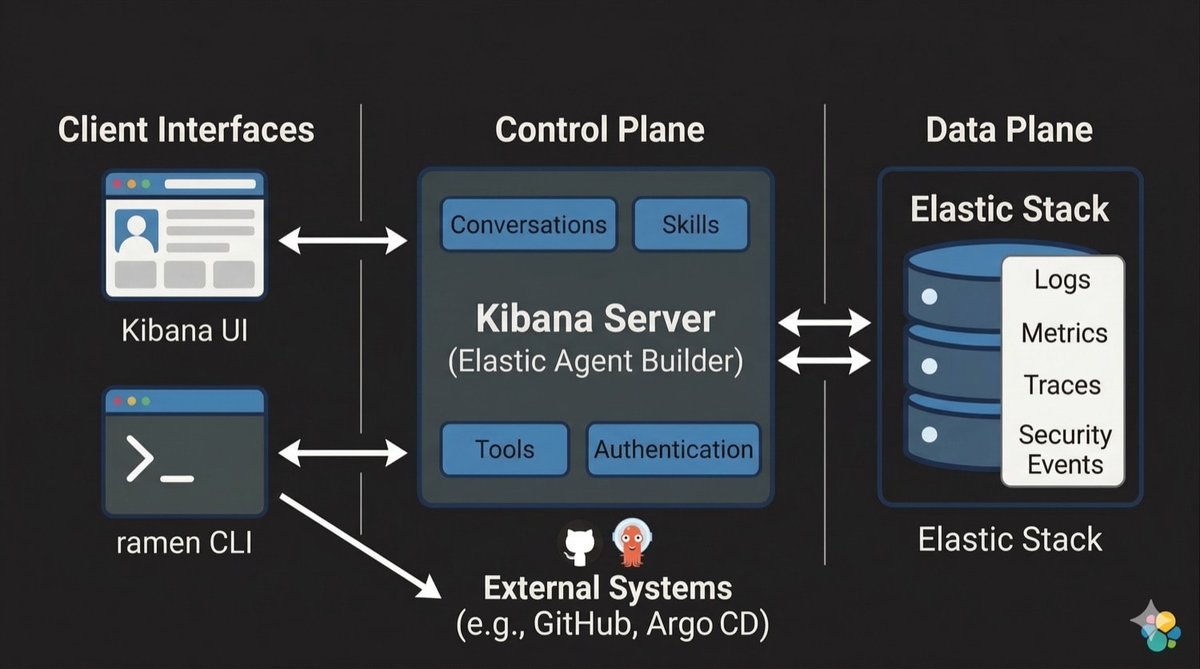
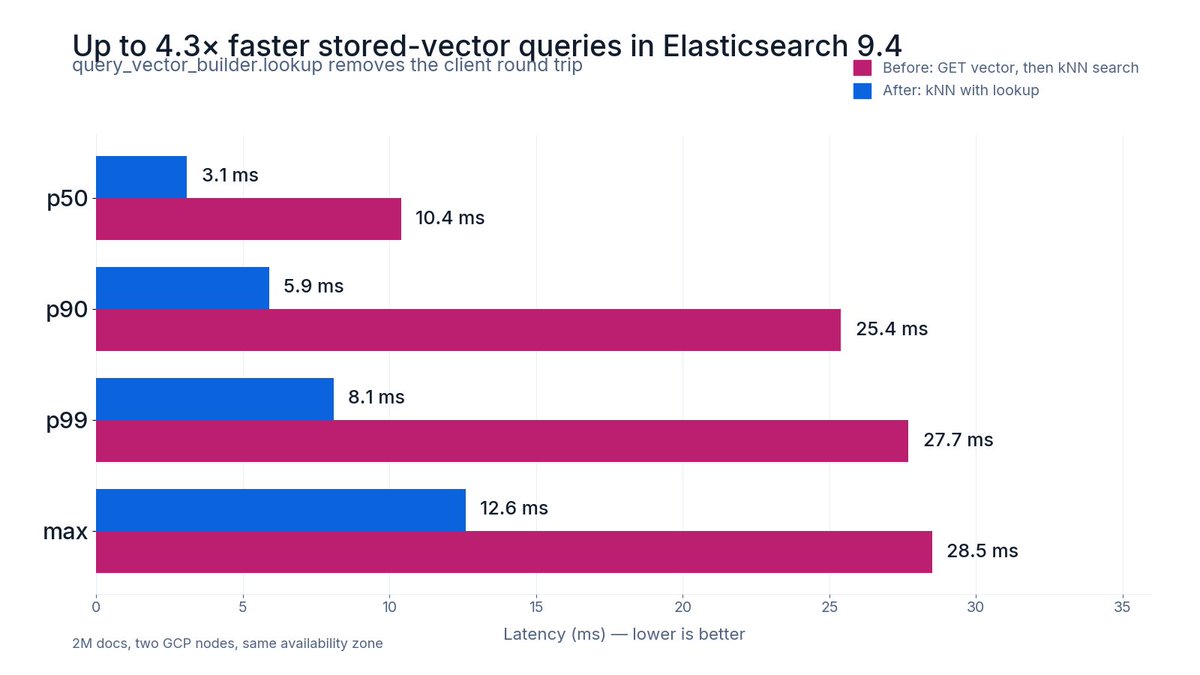
Up to 3.3x faster stored-vector queries in Elasticsearch, and the fix is removing a round trip.
query_vector_builder.lookup in 9.4 lets you reference a vector already in the index. No GET, no serialization back to the client, no second request. The vector stays server-side.
Benchmarked on 2M docs across two GCP nodes: p50 dropped 10.4ms to 3.1ms. At p90, it was 4.3x faster, from 25.4ms to 5.9ms. Even within the same availability zone, network and serialization costs added up.
1
4
18
1,600
May 21
Our BBQ at 1-bit/doc beats TurboQuant at 4-bit/doc on shifted data on ranking accuracy.
At 1/5 the storage.
2
251
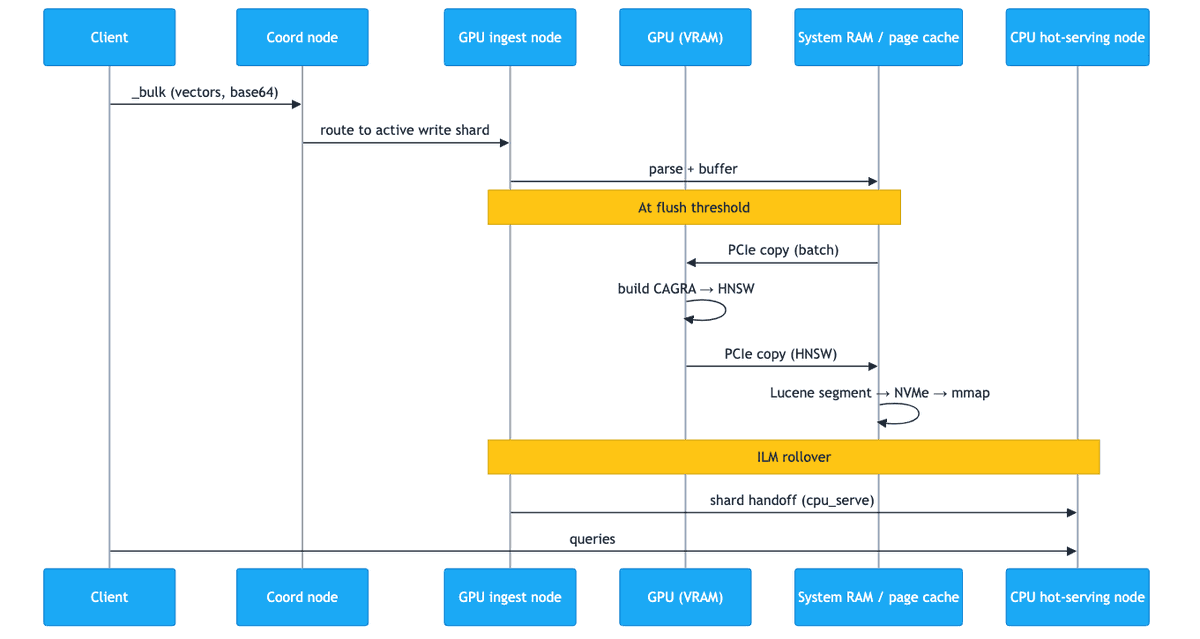
Building HNSW graphs on 300M vectors is slow. CPU-bound, single-threaded slow.
NVIDIA cuVS in Elasticsearch moves graph construction to the GPU: up to 12x faster on segment flush, ~7x on force merge. The GPU handles two write-path operations. That's it. Query serving stays on CPU.
The smart deployment splits the cluster:
• GPU ingest tier: 3 nodes, 64 GB RAM each, 1x L40S. Owns the active write shard only.
• CPU hot-serving tier: 7 nodes, 192 GB RAM each, no GPU. Holds the full corpus in page cache.
ILM rollover migrates finished shards from GPU to CPU automatically. The GPU node's page cache resets every cycle.
One thing to know before you start: cuVS requires int8_hnsw or hnsw. The default bbq_hnsw (384 dimensions, since 9.1) falls back to CPU with no warning.
1
1
12
1,532
Exact kNN on 1M vectors: ~10 QPS
HNSW on the same dataset: ~1000 QPS
This is because HNSW builds a layered graph:
shortcuts at the top, all vectors at the bottom.
A query enters at the top layer, finds the closest node, uses it as the entry point for the layer below, and repeats until it reaches a tight local search at layer 0.
It also let you tune your indexing speed vs query speed vs recall, so you can get the index that suits your needs.
1
5
25
3,009
May 18
Simple fix, big result.
Filtered vector search with restrictive filters just got 3-5x faster. Close to 10x on hyper-restrictive ones.
The old flow scored centroids without knowing if they contained matching vectors, loaded postings lists for nothing, decoded doc IDs that didn't pass the filter, and repeated until it had enough results.
The fix in Elasticsearch 9.4: a doc_id-to-centroid mapping that lets DiskBBQ skip straight to clusters with relevant vectors. Latency used to spike as filters got tighter. Now it stays flat or drops.
6
219
Stop asking AI to write its own skills
Skills encode expertise the model doesn't have. So asking an LLM to generate its own skill is like getting a new grad to write their own onboarding.
Better approach: start from real failures, write evaluation tasks first, then build the skill to improve the score.
1
2
10
1,724
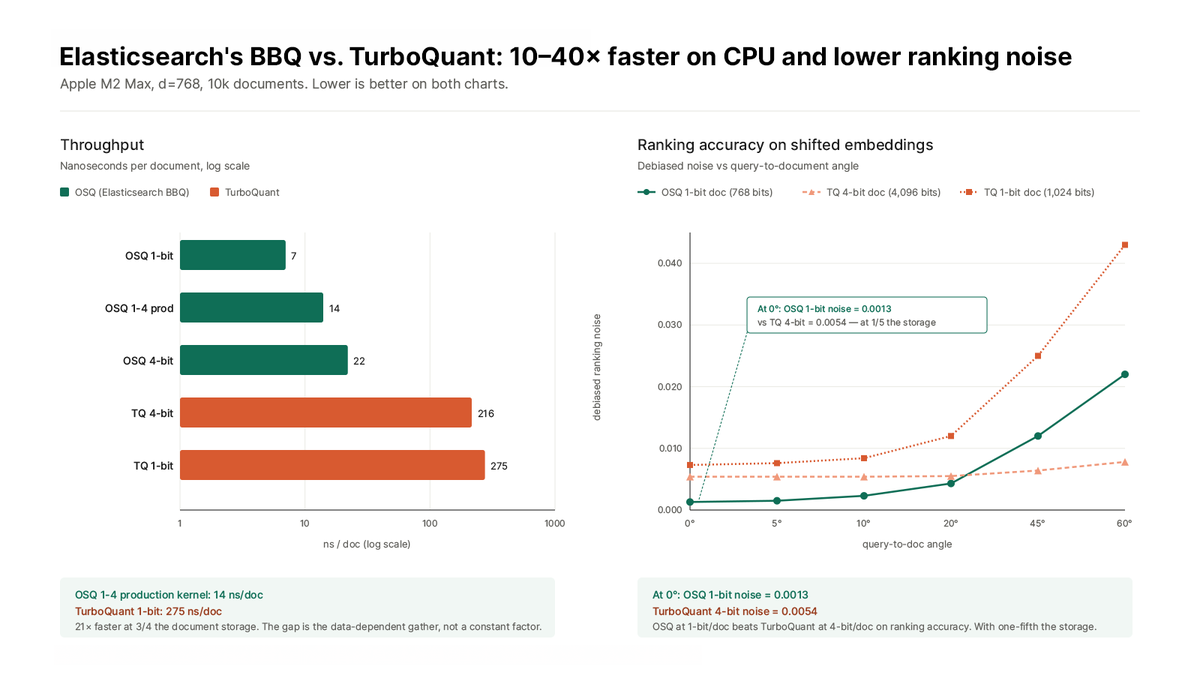
🧵 Our BBQ at 1-bit/doc beats TurboQuant at 4-bit/doc on shifted data on ranking accuracy.
At 1/5 the storage.
We center on the segment centroid before quantization, so the bits go where they are actually needed for ranking. TurboQuant's Hadamard rotation can't exploit that structure.
1
1
10
3,545
May 13
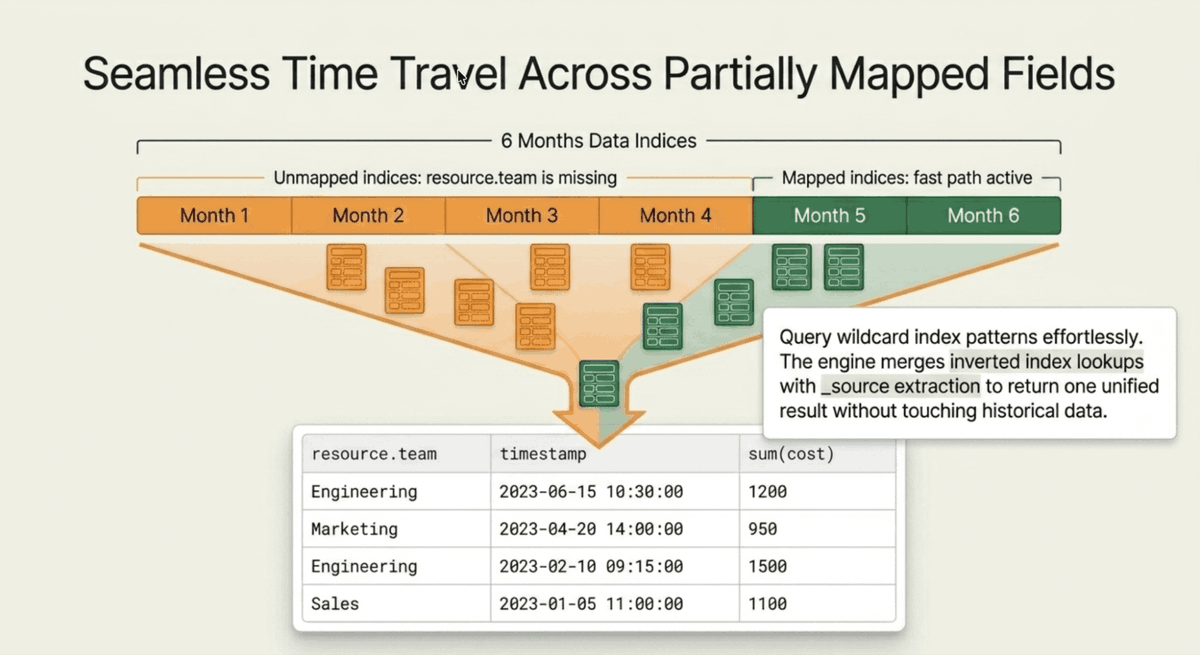
Your unmapped fields were there all along.
No reindex. No pipeline change. Works retroactively against data you ingested months ago.
Ever had an unmapped field buried in _source that you couldn't query without reindexing the whole index?
That's the mapping cliff edge. Field wasn't anticipated at ingest time, so it's invisible to queries. Traditional fix: update the mapping, reindex terabytes of data, wait hours.
ES|QL now has a one-line fix: SET unmapped_fields="load"
That's it. Every unmapped field in _source becomes queryable at query time. No reindex. No pipeline change. Works retroactively against data you ingested months ago.
The trade-off: unmapped fields skip the inverted index, so filters on them are slower than the mapped fast path. But "slower and accessible right now" beats "fast and doesn't exist" when you're debugging at 2am.
Pair it with JSON_EXTRACT for surgical extraction from raw JSON strings or flattened fields where dot notation can't reach.
Mapped fields stay fast. Unmapped fields stop being invisible. You pick per field, per query.
Read more: go.es.io/3PnJfkZ
4
151
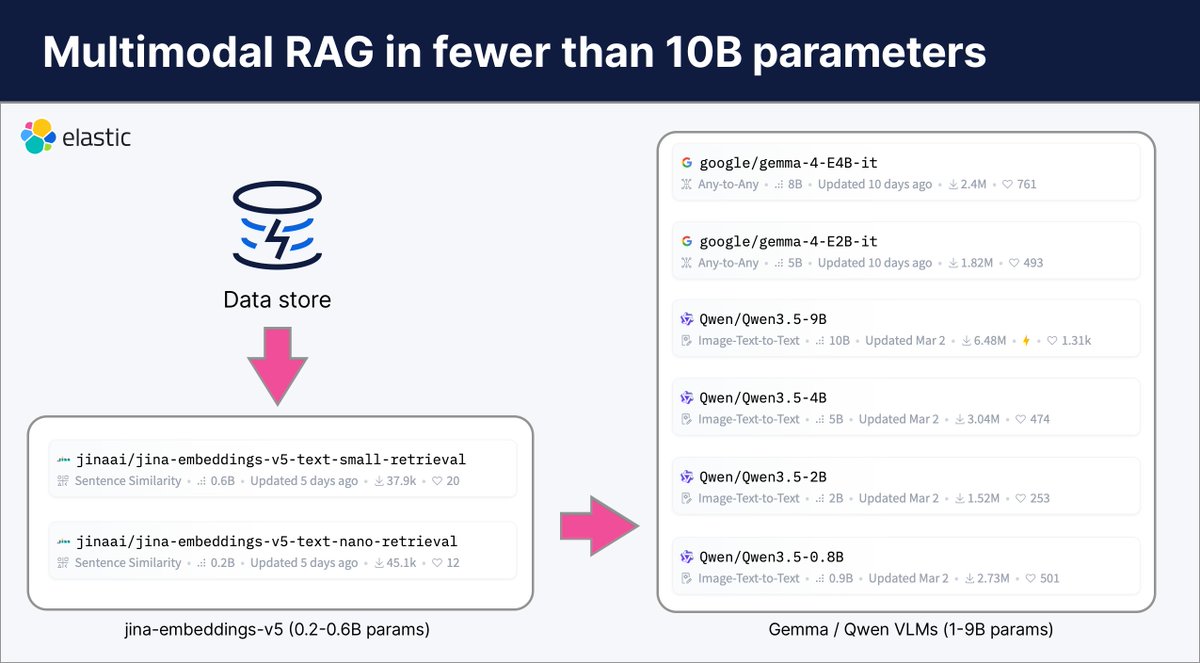
🧵 A competent RAG pipeline with a billion parameters? It’s no longer just a pipe dream.
The recent release of Gemma and Qwen models give developers access to models as small as under 1B parameters that can run on not just your computer, but edge devices.

2
6
23
1,728