
Carefully crafting bugs and features @linear.
Joined June 2008
- Tweets 19,382
- Following 443
- Followers 2,405
- Likes 8,559
900 Photos and videos












Andreas Eldh retweeted

Excited to share the first pre-print from our lab led by @SMZ_0001!
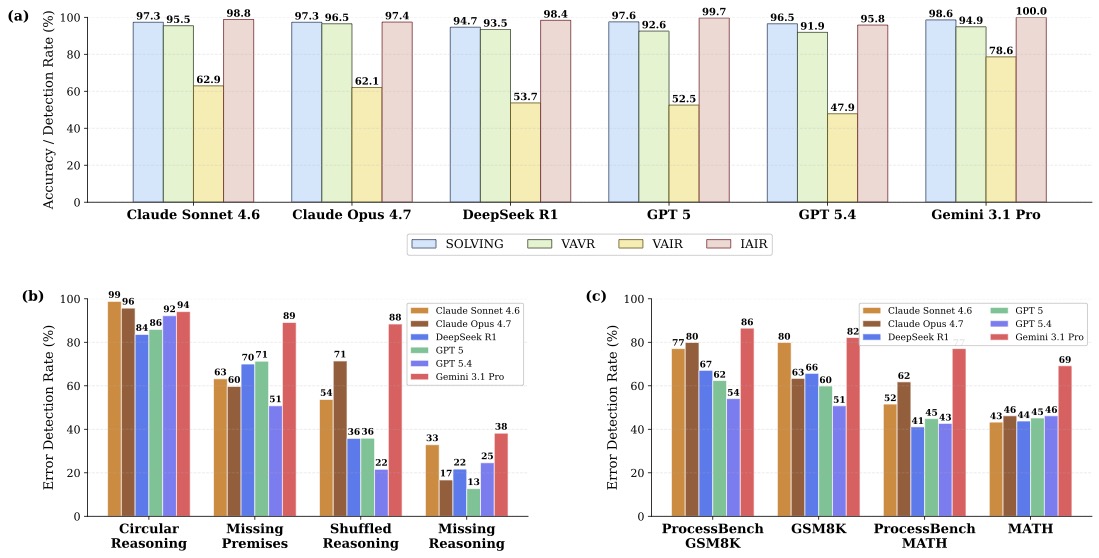
In "An Enigma of Artificial Reason", we find that reasoning-trained LMs excel at *producing* reasoning, but struggle to *evaluate* reasoning that reaches valid answers for invalid reasons, scoring as low as 48%.
Jun 14

🚨 Frontier reasoning models have achieved many remarkable feats this year, including solving open problems in research mathematics — but we just ran them on our new evaluation built on elementary and high school math, and they get things wrong up to 52% of the time! Even Claude Fable 5 — Anthropic's newest model — has an error rate of 16.4%*.
Why are frontier models still stumbling on grade-school math reasoning when they can already solve complex research-level math?
👉 As it turns out, while reasoning models excel at producing solutions to reasoning problems, we find that still struggle to evaluate solutions, even for grade-school math — we call this the Production-Evaluation Gap.
🚀 In our new paper, An Enigma of Artificial Reason, we study a question that has received insufficient attention thus far: Can Large Reasoning Models (LRMs) reliably evaluate reasoning, or are they just really good at producing it? 🚀
To find out, we built the Valid-Answer-Invalid-Reasoning (VAIR) dataset. We derived this benchmark from GSM8K and MATH — math datasets that LLMs saturated long ago in terms of solution accuracy. Yet, on our reasoning evaluation benchmark, frontier models exhibit sharp drops in accuracy: . Claude Opus 4.7, GPT 5.4, DeepSeek R1, and Gemini 3.1 Pro all score 95–99% when producing solutions, but their accuracy collapses to 48–79% when asked to evaluate flawed reasoning.
6
12
57
6,097

Jun 12
Team really cooked

Introducing coding sessions.
Linear Agent can now triage issues, investigate the cause, write the fix, open a PR, and bring the code back for review.
All shared with your team in Linear.
11
503


Andreas Eldh retweeted

The Siri/EU situation is a regulatory masterpiece.
Apple cannot launch Apple Intelligence in the EU.
Why? Because under the DMA, if Siri gets deep system access, every other AI assistant must get the exact same. Anything less would be unfair competition. A gatekeeper privileging its own service.
So either Siri ships and every Shenzhen startup, Cyprus shell company, and nephew hackathon project gets identical root access to 450 million Europeans’ digital lives or nothing ships.
Apple proposed a “Trusted System Agent”: a security intermediary so third-party assistants get capabilities without ripping the phone wide open.
The EU rejected it.
Magnificent.
Apple’s response: fine, then no developer APIs either. No Apple Intelligence, no third-party integrations, no foundation model access for EU developers. The entire layer simply does not exist on this continent.
Excellent.
This is the path. Why depend on American AI when we can build the entire stack ourselves? A European foundation model, trained on a European GPU cluster, running on a European OS, on a European phone, manufactured in a European fab, powered by European nuclear plants we have spent fifteen years closing.
Estimated time to ship: 2047.
Estimated cost: the GDP of three member states.
Estimated outcome: a chatbot that requires a cookie banner before each response.
Worth it.
In the meantime, European users are protected from Apple processing data Apple already holds by ensuring nobody processes anything at all.
Not a bug. The intended outcome.
Regulatory product design with a sledgehammer, swung with precision.
🇪🇺

252
568
3,127
354,186

Jun 9
Is there a German word for the feeling of shame you get after accidentally hitting yourself in the face with a badminton racket?
7
9
867
Jun 8
Agents need to stop adding tests to everything unless explicitly told to doo so. Looking specifically at you, codex.
5
10
992
Jun 9
Claude just added tests for the temporary console logs I asked it to add…
2
263
Andreas Eldh retweeted

May 29
@birch_js opened day 2 of our conf with some great news! Say hi to @expo Desktop – React Native development is getting more and more powerful! 🚀
github.com/shirakaba/expo-de…

8
48
2,514
May 28
The team has worked a LONG time on this. Seeing it grow into what it is today has been fascinating. It's really good.
I've just been watching from the sidelines, but then something happened…
Code review, but faster.
Introducing Diffs. A new way to review PRs, directly inside Linear.
• Realtime updates
• Guided reviews with Al (beta)
• Focused notifications
• Iterate with coding agents
• Threaded comments
1
19
1,811
May 28
When we got home, me and @dizaytsev started trying to make what was a good demo, a good feature.
We changed the name to "Guided reviews", made tons of tweaks, fixes and improvements. And now it's available for everyone.
1
3
206
May 28
I think this is a pretty great use of AI. Perhaps surprisingly, the guides don't need to be perfect. They just need to tell a story that mostly makes sense, in order to be useful. And reviewing code this way feels MUCH better than what we were used to. Try it. You won't go back.
1
2
105
May 28
Team really cooked.
Code review, but faster.
Introducing Diffs. A new way to review PRs, directly inside Linear.
• Realtime updates
• Guided reviews with Al (beta)
• Focused notifications
• Iterate with coding agents
• Threaded comments
8
624
May 27
The job of reviewing code is changing. Used to be a lot about finding bugs & problems in the code. Now becoming more about figuring out if the proposed code should even exist. AI is already better at finding bugs.
1
3
212
