
27 Photos and videos

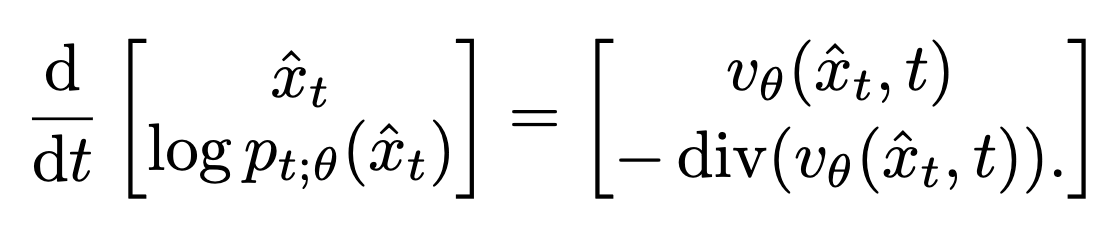






Yutong (Kelly) He retweeted

Jun 10
Our team just released DiffusionGemma: a new state-of-the-art open diffusion LLM 🚀
Pushing the RL research for DiffusionGemma has been fascinating. RL doesn't just boost performance, it unlocks blistering speedups (>1000 tok/s on a single H100) ⚡️
Jun 10

DiffusionGemma is our new experimental open model with up to 4x faster output on dedicated GPUs.
Instead of predicting word-by-word, it generates entire blocks of text simultaneously. This lets the model self-correct and format complex markdown in real time.

ALT Intelligence vs Latency chart showing DiffusionGemma 26B A4B is much faster than Gemma 4 models with high intelligence.
5
10
47
2,728
Yutong (Kelly) He retweeted

Jun 10
DiffusionGemma is our new experimental open model with up to 4x faster output on dedicated GPUs.
Instead of predicting word-by-word, it generates entire blocks of text simultaneously. This lets the model self-correct and format complex markdown in real time.
ALT Intelligence vs Latency chart showing DiffusionGemma 26B A4B is much faster than Gemma 4 models with high intelligence.
108
261
2,364
180,836
Yutong (Kelly) He retweeted

Jun 9
An annoyingly common question I get as an AI PhD student is “When can you get the ChatGPT AI to do something useful? It can’t even work on my phone yet. Siri is pretty dumb.”
To be fair, I think their criticism is correct. I personally wished that AI was better integrated on my phone. LLMs can solve IMO problems, so shouldn’t it be a cakewalk for it to remind me of the text I forgot to respond to last week? Obviously not, since it doesn’t exist in my pocket yet. Or maybe Apple’s new update yesterday fixed this and my research project is obsolete.
We are releasing iOSWorld (iosworld.io), a dynamic iPhone benchmark with 26 newly created apps grounded in personal context. Each of the 26 apps is centrally seeded around one persona, Jordan Avery, and the apps interact together in a realistic ecosystem that reflect real app interactions. We create 133 personalized mobile agent tasks to test in this environment, and the best model, even with privileged information, only scores 51%.

4
14
30
14,071
Yutong (Kelly) He retweeted

Jun 5
Scaling laws describe how loss changes with scale. Do neurons inside models change predictably too?
We study vision and language models up to 30B params and find systematic scaling in neuron universality, specialization, and selectivity.
Paper code: avdravid.github.io/rosetta-n…
1/n
13
83
416
202,373
Yutong (Kelly) He retweeted

We're presenting "Anchored Generation: Controllable Scene Variation via 3D-Aware Object Latents" at the #CVPR 4th Workshop on Generative Models for Computer Vision today!
This is preliminary work on modeling the distribution of controllable scene latents rather than pixels directly. I think this is a promising direction for generative modeling. Here, the generator predicts structured 3D latents instead of 2D layouts, allowing the model to better resolve ambiguity in object de-occlusion and replacement.
We’d be happy to discuss the work, so feel free to stop by!
🕐 Time: 1:00–2:00 PM MDT
📍 Place: Room 205, 4th Workshop on Generative Models for Computer Vision (generative-vision.github.io/…)
I’m also happy to connect with people attending CVPR. Feel free to DM or email me if you’d like to chat!

4
18
1,356
Yutong (Kelly) He retweeted

May 18
As LLMs saturate benchmarks, evaluating their five-nines reliability is crucial, but prohibitively expensive. We cut the inference cost by 5-20x on average (up to 156×) by exploiting a key insight: LLM failures are not random.
🧵[1/n]

2
12
74
7,415
Yutong (Kelly) He retweeted

Apr 29
One of the things I’m most excited about this year is building agents that can work productively for hours, days, or weeks. Coding agents are starting to become very competent at this, but what about computer use agents?
Our new benchmark, Odysseys (co-led with @JangLawrenceK) is a set of 200 new tasks derived from real world browsing behavior that measure long horizon web navigation capabilities (potentially up to hours of web browsing work). Interestingly, we find that frontier CUAs are already surprisingly good at working productively for up to an hour on these tasks, but there’s a lot of work to be done in making them even more efficient.
Like every other AI researcher, my real dream is to open a cafe once we solve ASI. So, here’s Opus 4.6 doing some market research for me ("I want to do market research on the most popular cafes in Singapore. Analyse the menus of the top 10 cafes in Singapore (by Google reviews/ratings), and make sure we include at least 1 from the North/South/East/West/Central regions of Singapore. Keep the relevant pages of each cafe open, and summarise their pricing, menu offerings, unique selling points, making sure to reference which tab is opened for each cafe. For each cafe, also help me figure out how long it would take to get to it from Tampines MRT, and include this in your final summary.").
I was very impressed to see Opus 4.6 complete this task after working for 52 mins, satisfying all 7 rubrics that corresponded to this task. It provided a very nice markdown summary at the end that gave me all the information I asked for!
12
26
126
49,255
Yutong (Kelly) He retweeted

Apr 22
Foresight will be the defining frontier on the path to AGI.
I am excited to start Sooth Labs with my amazing co-founders: Yaser Sheikh @subail, Chuck Hoover @chuckjhoover, David LaRose, and Shih-En Wei.
Deeply grateful to Aydin Senkut @asenkut and Feyza Haskaraman @FHaskaraman at @felicis for leading the round, alongside an exceptional group of partners.
bloomberg.com/news/articles/…

22
31
281
76,660

Diffusion planners are great for offline RL. But they need many steps to work well! Way too slow for real-time decision making!
Presenting RACTD at #ICLR2026: reward-aware distillation that plans in ONE step
🇧🇷 Today (4/23) P4-#4618 3:15-5:45 PM
arxiv.org/abs/2506.07822 1/
2
19
96
8,399
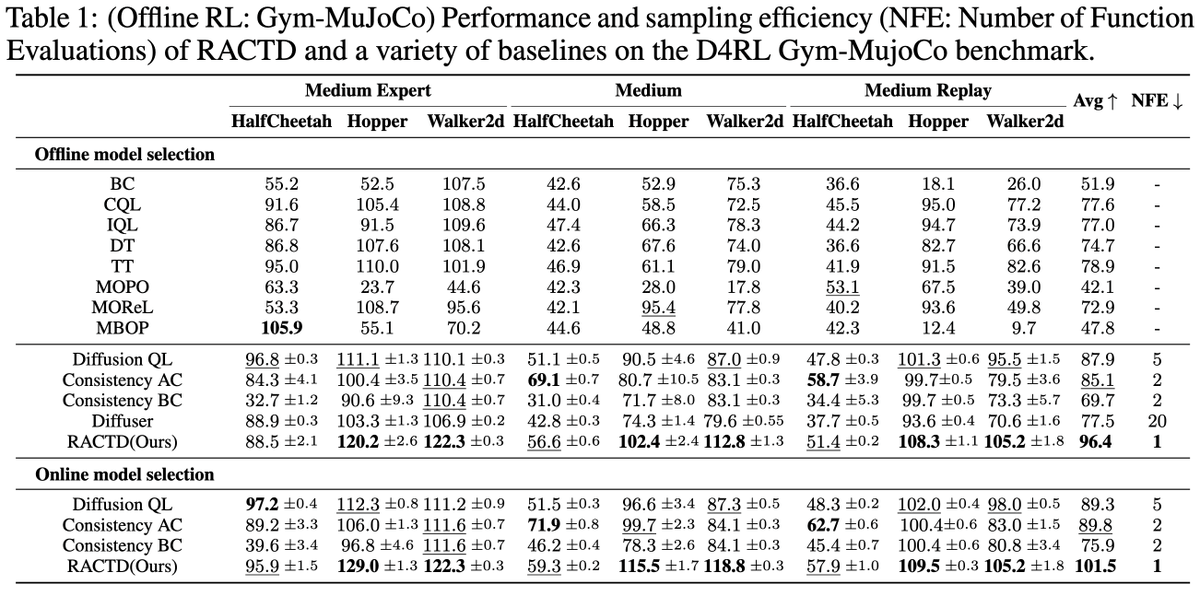
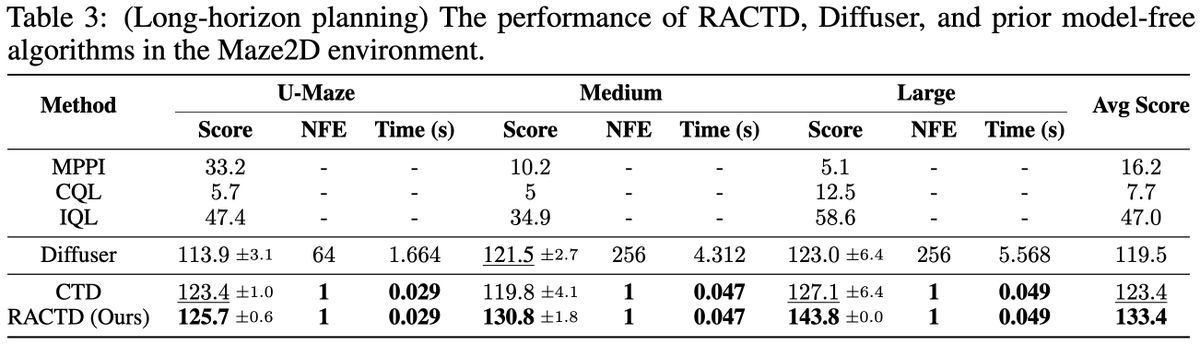
RACTD improves over previous SOTA by 9.7% on D4RL Gym-MuJoCo and outperforms Diffuser on long-horizon Maze2D planning
All with a SINGLE denoising step, achieving up to 142x speedup over diffusion counterparts 🚀🚀🚀
1
1
3
534
Joint work with the amazing @x_duan9296 (the best master's student at CMU), @FahimTajwar10, @rsalakhu, @zicokolter, and Jeff Schneider. Come chat with us today at 3:15 PM!
Paper: arxiv.org/abs/2506.07822
Code: github.com/Ddduanxt/RACTD
3
9
3,111
Yutong (Kelly) He retweeted

Apr 22
How can visual planning agents 𝙨𝙚𝙡𝙛-𝙞𝙢𝙥𝙧𝙤𝙫𝙚 from their own collected experience?
We present 𝗦𝗜𝗟𝗩𝗥🩶, a framework that combines offline data with online experience for concurrent zero-shot generalization and sample-efficient self-improvement capabilities!#ICLR2026
1
20
106
18,915
💎
Apr 22

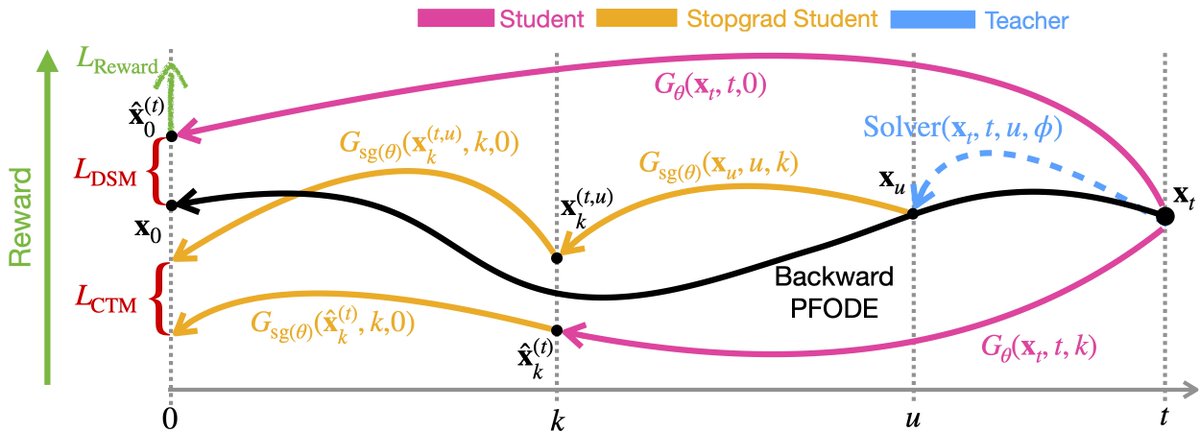
We release Diamond Maps💎 unlocking accurate and efficient guidance for diffusion models. Our experiments show that our methods scale incredibly well. Excited to see what people will build with this!
Accurate guidance has been a notoriously hard problem, but in this work, we’re bringing TWO (!) solutions to the table. The recipe for success:
1️⃣ Speed: Use distilled models (flow maps, mean flows, consistency models).
2️⃣ Exploration: Inject stochasticity to properly explore your search space.
Because this fundamentally improves anything using flow matching and diffusion, we see a lot of potential for applications across audio, robotics, molecules, and beyond.
Paper: arxiv.org/abs/2602.05993
Code: github.com/PeterHolderrieth/…
Huge thanks to an amazing team: Douglas Chen, @LucaEyring, @ishin_shah, Giri Anantharaman, @electronickale, @zeynepakata, Tommi Jaakkola, @nmboffi, and @max_simchowitz. It was awesome bringing this to life together!
10
2,803
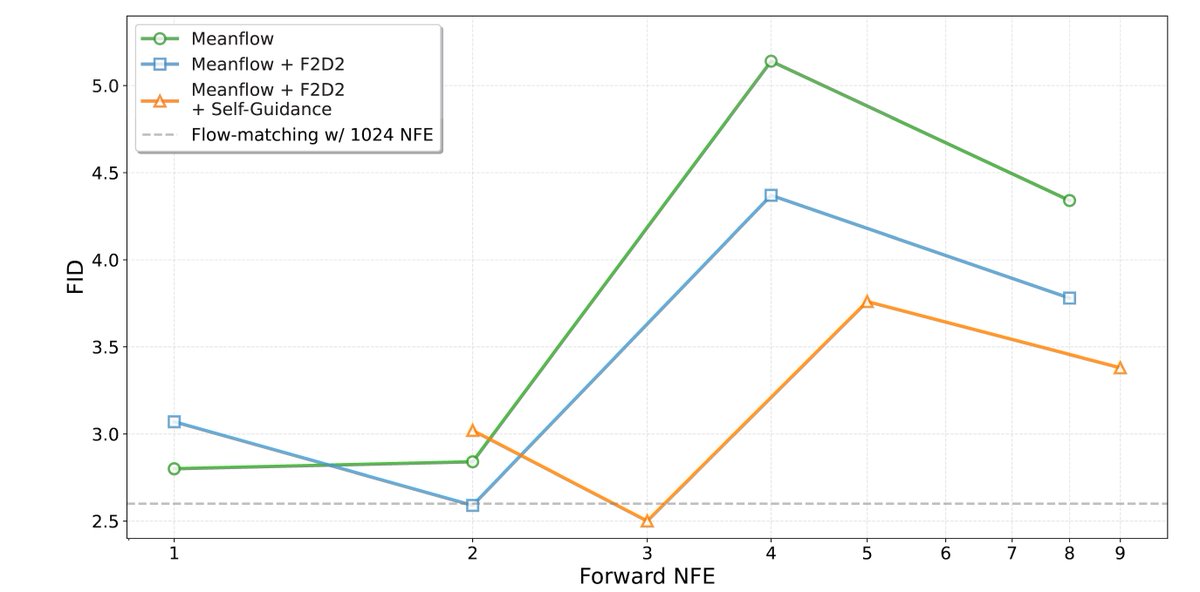
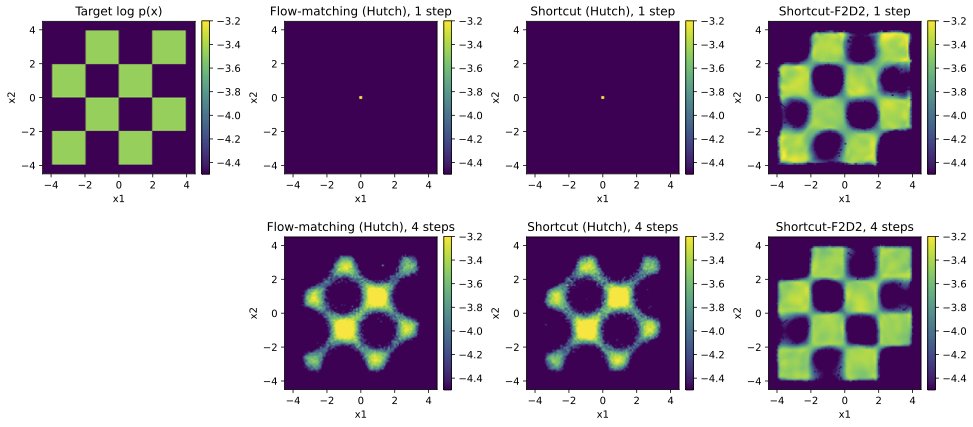
F2D2 is accepted at #ICLR2026 ! To celebrate, we have added a new JAX codebase & new results w/ Lagrangian self-distillation in camera-ready! Check them out on our project page: kellyyutonghe.github.io/f2d2…
P.S. I will present F2D2 Apr 23 10:30 AM – 1:00 PM P3-#1911, see yall in Rio🇧🇷
10 Dec 2025

Diffusion/Flow-based models can sample in 1-2 steps now 👍 But likelihood? Still requires 100-1000 NFEs (even for these fast models) 😭
We fix this! Introducing F2D2: simultaneous fast sampling AND fast likelihood via joint flow map distillation.
arxiv.org/abs/2512.02636
1/🧵
1
10
106
11,429
🐍
Mar 17

The newest model in the Mamba series is finally here 🐍
Hybrid models have become increasingly popular, raising the importance of designing the next generation of linear models.
We've introduced several SSM-centric ideas to significantly increase Mamba-2's modeling capabilities without compromising on speed. The resulting Mamba-3 model has noticeable performance gains over the most popular previous linear models (such as Mamba-2 and Gated DeltaNet) at all sizes.
This is the first Mamba that was student led: all credit to @aakash_lahoti @kevinyli_ @_berlinchen @caitWW9, and of course @tri_dao!
1
17
2,404
5 days into my trip to the Bay Area I’ve already upgraded my Claude subscription to max 🙂
3
31
2,917
Yutong (Kelly) He retweeted

Mar 4
Train Beyond Language. We bet on the visual world as the critical next step alongside and beyond language modeling. So, we studied building foundation models from scratch with vision.
We share our exploration: visual representations, data, world modeling, architecture, and scaling behavior! [1/9]

35
221
1,053
217,723